一种面向网络分类模型的数据增强方法
文献发布时间:2023-06-19 10:35:20
技术领域
本发明涉及网络分类图像数据增强技术领域,特别是涉及一种面 向网络分类模型的数据增强方法。
背景技术
网络分类是网络科学中重要的学习任务,被广泛应用于生物化学 和网络科学领域。不同于节点层面的任务,网络分类需要关注网络的 全局信息,这既包含了网络的结构信息,也包含各个节点的属性信息。 给定多个网络,以及每个网络对应的类标,网络分类任务需要通过学 习得到一个由网络到对应类标的网络分类模型,模型的重点在于如何 通过学习得到一个优秀的网络表示向量。虽然近年来,基于核、嵌入 以及图神经网络的网络分类方法得到了极大的发展,但数据规模的限 制使得这些模型容易陷入过拟合和弱泛化的问题,由于网络数据的特 殊性质,将传统的图像数据增强技术直接应用到网络数据上面临着诸 多挑战,如:传统数据增强技术无法对不规则的网络数据进行几何变 换,且传统数据增强技术处理的样本符合机器学习算法的样本独立同 分布假设,这与网络的结构依赖性相悖。
发明内容
本发明要克服上述现有技术存在的问题,提供一种面向网络分类 模型的数据增强方法,从实际需求和应用的角度出发,设计出一个完 整的面向网络分类模型的数据增强方案。
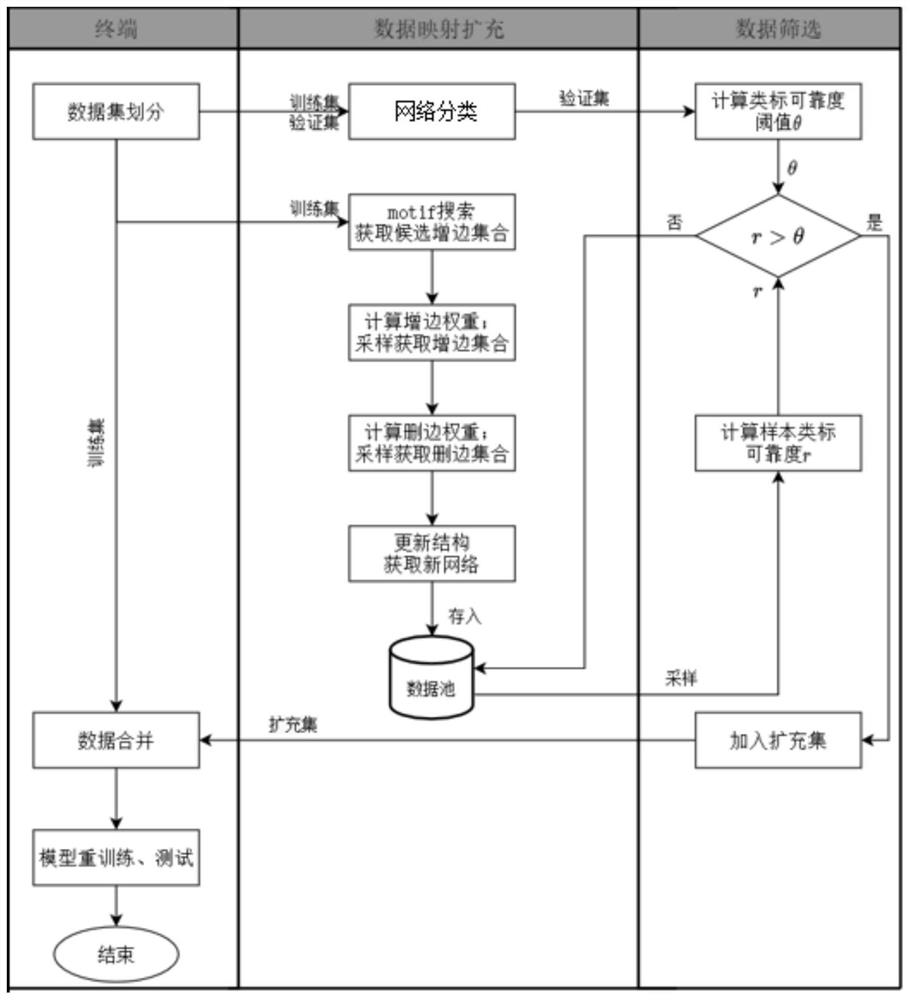
本发明提供一种面向网络分类模型的数据增强方法,包括如下步 骤:
S1:加载化合物网络数据集,构建图核模型与传统机器学习模型; 具体包括:
加载包含t个网络的化合物网络数据集D={(G
S2:将图核模型与传统机器学习模型组合,得到网络分类模型;
S3:将化合物网络数据集划分为训练集D
S3-1:将验证集D
S3-2:通过验证集的所有样本预测概率向量p
Ω
S3-3:对k类标签的平均概率向量q
Q=[q
概率混淆矩阵Q的大小为|Y|×|Y|,概率混淆矩阵中的元素q
S3-4:验证集的样本类标可靠度r
S3-5:基于优化方程对所有验证集样本的类标可靠度r
其中,
S4:针对训练集中的每一个原始网络,使用数据映射策略扩充生 成新网络,将扩充生成的新网络存入数据池D
S4-1:获取候选增边集合:给定任意原始网络G,在任意原始网 络G中寻找长度为2的路径模体motif,通过邻接矩阵的乘方进行路 径搜索,寻找模体motif,A
候选增边集合中包含了所有模体motif的头尾节点对;
S4-2:利用资源分配指标计算候选增边集合
其中,Γ(i)表示节点v
在计算
S4-3:根据增边权重集合W
其中,β为采样比例,m为原始网络G的边数,βm为两者的乘积取 整,表示增加的边的数量,e
S4-4:根据增边集合E
通过加权随机采样的方式选择候选边进行删除,候选边e的权重
删边权重集合W
S4-5:根据增边集合E
G'=(V,(E∪E
S5:提取数据池D
S5-1:通过公式
S5-2:新的训练集由初始训练集D
S6:利用得到的新的训练集重新训练网络分类模型,得到新的网 络分类模型C'。
优选地,步骤S1所述化合物网络数据集为PTC_MR网络数据集(公 鼠致癌物数据集),该数据集信息为:344个网络,2类,平均节点14.29,平均边14.69。
优选地,所述S3中通过所述测试集,评价预训练网络分类模型训 练的效果,得到的平均分类精度为47.1%。
优选地,步骤S3-3中,得到分类模型的概率混淆矩阵为:
步骤S3-4中,得到的分类模型的类标可靠度阈值为θ=0.4657611247:
优选地,步骤S5中,最终筛选得到的扩充新样本个数为198。
优选地,步骤S6中利用得到的新训练集重训练网络分类模型, 得到新的网络分类模型C',新模型在测试集上的精度为51.4%,模型 的分类性能得到了显著的提升。
本发明能有效提升小型标准化合物网络数据集的数据规模,提升 数据质量,实现网络数据增强;更进一步,扩充后的数据集用于重训 练网络分类模型,能有效提升模型的分类性能,本发明时间复杂度较 低,运算速度快。
附图说明
图1是本发明方法的流程图;
图2是本发明方法的总体架构;
图3是本发明方法的开放式三角链式motif示意图;
图4是本发明方法的motif的边修改过程示意图;
图5是本发明方法的面向SF网络分类模型的mutag数据增强流 程图。
具体实施方式
下面将结合本实施例中的附图,对本发明实施例中的技术方法进 行清楚:完整地描述,显然,所描述的实施例仅仅是本发明一部分实 施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技 术人员在没有付出创造性劳动前提下所获得的所有其他实施例,都属 于本发明保护的范围。
参照图1-5所示,本发明提供一种面向网络分类模型的数据增强 方法,包括以下步骤;
S1:加载包含t个网络的化合物网络数据集D={(G
S2:将图核模型与传统机器学习模型组合,得到网络分类模型;
S3:将数据集按比例划分为训练集D
S3-1:将验证集D
S3-2:通过验证集的所有样本预测概率向量p
Ω
S3-3:对k类标签的平均概率向量q
Q=[q
概率混淆矩阵Q的大小为|Y|×|Y|,概率混淆矩阵中的元素q
S3-4:验证集的样本类标可靠度r
S3-5:基于优化方程对所有验证集样本的类标可靠度r
其中,
S4:针对训练集D
S4-1:获取候选增边集合:给定任意原始网络G,在任意原始网 络G中寻找长度为2的路径模体motif,通过邻接矩阵的乘方进行路 径搜索,寻找模体motif,A
候选增边集合中包含了所有模体motif的头尾节点对;
S4-2:利用资源分配指标计算候选增边集合
其中,Γ(i)表示节点v
在计算
S4-3:根据增边权重集合W
其中,β为采样比例,m为原始网络G的边数,βm为两者的乘积取 整,表示增加的边的数量,e
S4-4:根据增边集合E
通过加权随机采样的方式选择候选边进行删除,候选边e的权重
删边权重集合W
S4-5:根据增边集合E
G'=(V,(E∪E
S5:将验证集D
S5-1:通过公式
S5-2:新的训练集由初始训练集D
S6:利用得到的新训练集重新训练网络分类模型,得到新的网络 分类模型C',新模型在测试集上的精度明显提升。
本发明提供的网络分类一般应用于生物、化合物领域。比如说蛋 白质、酶等化合物的分子结构可以看成是一个网络图,其中节点表示 原子,边表示化学键。网络分类一般用于对这些化合物从结构层面进 行区分,比如说判断该种化合物是否具有致癌性、毒性、诱变性等。
本发明能有效提升小型标准网络数据集的数据规模,提升数据质 量,实现网络数据增强;能有效提升模型的分类性能,且时间复杂度 较低,运算速度快。
为了进一步验证本发明一种面向网络分类模型的数据增强方法, 本实施例使用了PTC_MR网络数据集(公鼠致癌物数据集)和NetLSD 网络分类模型对本发明进行解释;
S1:加载PTC_MR网络数据集D={(G
S2:数据集按7:2:1的比例划分为训练集D
S3:针对训练集中的每一个网络G,使用数据映射策略扩充生成 新网络,获得的新网络存入数据池D
S3-1、给定原始网络G(id=1),如图5原始网络所示,原始网 络节点数为8,边数为8,按公式
S3-2:利用公式
S3-3:根据增边权重集合W
S3-4:得到了增边集合E
S3-5:根据增边集合E
S4:针对新生成的网络的标注问题,利用数据筛选策略,选择类 标可靠度高的新网络作为扩充样本,操作步骤如下:
S4-1:将验证集D
S4-2:根据验证集的所有样本的预测概率向量,计算类标的平均 概率向量q
S4-3:该分类模型的类标可靠度阈值θ由所有验证集样本的类标 可靠度r
S4-4:按公式
S5:利用得到的新训练集重训练网络分类模型,得到新的网络分 类模型C',新模型在测试集上的精度为51.4%,模型的分类性能得到 了显著的提升。得到的新模型可以用于公鼠致癌物分类与检测,判断 一种化合物是否能诱导公鼠基因突变,诱发癌症。同时,根据训练使 用的数据集的不同,得到优化后的模型可以用于不同的场景,如药物 毒性检测,蛋白质分类等。
本发明得到的新的网络分类模型C'的具体应用点可以落到药物 分类、蛋白质分类、化合物分类等,能够应用于化合物致癌性检测、 毒性检测中;因为上述这些任务用到的数据集规模较小,训练出来的 模型会过拟合,为了缓解过拟合的问题,本发明针对网络数据提出了 数据增强方法,用来缓解过拟合问题,提高分类模型的性能,取得了 良好的效果。
以上所述的实施例仅是对本发明的优选方式进行描述,并非对本 发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普 通技术人员对本发明的技术方案做出的各种变形和改进,均应落入本 发明权利要求书确定的保护范围内。
- 一种面向网络分类模型的数据增强方法
- 一种基于模型融合和数据增强的低质图像分类增强方法