应用字符资源同步方法、系统及计算机可读存储介质
文献发布时间:2023-06-19 10:35:20
技术领域
本发明涉及应用开发领域,尤其涉及一种应用字符资源同步方法、系统及计算机可读存储介质。
背景技术
在国际化的应用项目中,应用需要针对每个不同语种的国家对应显示其官方语种的语种译文,例如在中文中显示为“好”,而英文中则显示为“OK”。
在应用开发过程中,应用代码内部需要设置有每个国家对应的XML译文文件。在系统设置为对应的国家时,底层会根据当前系统语种从所有XML译文文件中查找到该语种对应的XML译文文件,获取到该语种对应的译文,并将译文显示在应用的UI界面中。
在应用发布范围较为广泛时,为了支持数十上百个国家对应的译文,开发人员维护这些XML译文文件所耗费的时间和人力成本都十分巨大,并且在开发人员编辑XML译文文件的过程中,还会因人为修改出错而导致译文显示错误。
发明内容
本发明的主要目的在于提供一种应用字符资源同步方法、系统及计算机可读存储介质,旨在解决维护应用中大量语种的译文文件时工作量较大且容易编辑出错的问题。
为实现上述目的,本发明提供一种应用字符资源同步方法,包括以下步骤:
读取应用的第一语种模板文件,从所述第一语种模板文件中获取所有字符串标识;
查询每个字符串标识分别对应每个语种时的语种译文;
根据所有字符串标识及其分别对应的语种译文生成每个语种分别对应的译文模板文件。
可选地,所述查询每个字符串标识分别对应每个语种时的语种译文的步骤包括:
从预设数据库中获取可翻译的语种,并生成相应的语种列表;
遍历所述语种列表,查询每个字符串标识分别对应每个可翻译的语种时的语种译文。
可选地,每个字符串标识包括名称和文本;所述查询每个字符串标识分别对应每个语种时的语种译文的步骤包括:
从所述第一语种模板文件中遍历所有字符串标识的名称,以得到每个字符串标识的文本;
查询每个字符串标识的文本分别对应每个语种时的语种译文文本。
可选地,所述根据所有字符串标识及其分别对应的语种译文生成每个语种分别对应的译文模板文件的步骤包括:
将所述第一语种模板文件中每个字符串标识的文本分别替换为对应每个语种时的语种译文文本,以生成每个语种分别对应的译文模板文件。
可选地,所述根据所有字符串标识及其分别对应的语种译文生成每个语种分别对应的译文模板文件的步骤之后,还包括:
生成每个译文模板文件的第一摘要,并在接收到应用发布指令时对所有第一摘要进行校验,以根据校验结果发布应用。
可选地,所述生成每个译文模板文件的第一摘要,并在接收到应用发布指令时对所有第一摘要进行校验,以根据校验结果发布应用的步骤包括:
针对每个译文模板文件,生成每个译文模板文件对应的第一摘要,并将每个第一摘要写入对应的译文模板文件;
在接收到应用发布指令时,从每个译文模板文件中获取对应的第一摘要,并计算生成每个译文模板文件对应的第二摘要;
判断每个译文模板文件的第一摘要与第二摘要是否均一致;
在每个译文模板文件的第一摘要与第二摘要均一致时,发布应用;
在至少一个译文模板文件的第一摘要与第二摘要不一致时,提示应用发布失败。
可选地,所述针对每个译文模板文件,生成每个译文模板文件对应的第一摘要的步骤包括:
对每个译文模板文件的数据进行填充;
设置初始化变量,并对每个译文模板文件填充后的数据进行分组;
根据所述初始化变量依次对每个分组的数据进行循环计算,以得到最终变量,并将所述最终变量作为每个译文模板文件对应的第一摘要。
可选地,所述在接收到应用发布指令时,从每个译文模板文件中获取对应的第一摘要,并计算生成每个译文模板文件对应的第二摘要的步骤之前,还包括:
通过非对称加密算法对写入第一摘要后的每个译文模板文件进行非对称加密,并将非对称加密的私钥进行唯一存储;
所述从每个译文模板文件中获取对应的第一摘要的步骤包括:
通过所述私钥对每个加密后的译文模板文件进行解密,以获得每个译文模板文件对应的第一摘要。
可选地,所述将每个第一摘要写入对应的译文模板文件的步骤包括:
将每个第一摘要写入对应的译文模板文件的注释部分;
所述计算生成每个译文模板文件对应的第二摘要的步骤包括:
对每个译文模板文件中除注释部分以外的其他内容进行摘要计算,以生成每个译文模板文件对应的第二摘要。
可选地,所述针对每个译文模板文件,生成每个译文模板文件对应的第一摘要的步骤包括:
获取预设的转换字符串;
将所述转换字符串加入每个译文模板文件中进行拼接,并在拼接后计算生成每个译文模板文件的第一摘要。
此外,为实现上述目的,本发明还提供一种应用字符资源同步系统,所述应用字符资源同步系统包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的应用字符资源同步程序,其中:所述应用字符资源同步程序被所述处理器执行时实现如上所述的应用字符资源同步方法的步骤。
此外,为实现上述目的,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有应用字符资源同步程序,所述应用字符资源同步程序被处理器执行时实现如上所述的应用字符资源同步方法的步骤。
本发明实施例提出的一种应用字符资源同步方法、系统及计算机可读存储介质,通过读取第一语种模板文件并获取所有的字符串标识,能够针对每个语种查询字符串标识所对应的语种译文。根据每个语种的字符串标识及其对应的语种译文即可生成该语种所对应的译文模板文件,从而得到各个语种的译文模板文件。通过对第一语种模板文件进行修改即可对其他的译文模板文件进行同步修改调整,降低了开发人员在应用开发与更新时的工作量,减少了开发成本,以及避免了在开发过程中人为修改模板文件而可能引发的应用显示错误。
附图说明
图1是本发明实施例方案涉及的硬件运行环境的装置结构示意图;
图2为本发明应用字符资源同步方法第一实施例的流程示意图;
图3为本发明应用字符资源同步方法第二实施例的流程示意图;
图4为本发明应用字符资源同步方法第三实施例的流程示意图;
图5为本发明应用字符资源同步方法第四实施例的流程示意图;
图6为本发明应用字符资源同步方法第五实施例的流程示意图;
图7为本发明应用字符资源同步方法第六实施例的流程示意图;
图8为本发明应用字符资源同步方法第七实施例的流程示意图;
图9为本发明应用字符资源同步方法第八实施例的流程示意图;
图10为本发明应用字符资源同步方法第九实施例的流程示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
如图1所示,图1是本发明实施例方案涉及的硬件运行环境的装置结构示意图。
本发明实施例终端可以是PC,也可以是智能手机、平板电脑、电子书阅读器、MP3(Moving Picture Experts Group Audio Layer III,动态影像专家压缩标准音频层面3)播放器、MP4(Moving Picture Experts Group Audio Layer IV,动态影像专家压缩标准音频层面4)播放器、便携计算机等终端设备。
如图1所示,该终端可以包括:处理器1001,例如CPU,通信总线1002,用户接口1003,网络接口1004,存储器1005。其中,通信总线1002用于实现这些组件之间的连接通信。用户接口1003可以包括显示屏(Display)、输入单元比如键盘(Keyboard),可选的用户接口1003还可以包括标准的有线接口、无线接口。网络接口1004可选的可以包括标准的有线接口、无线接口(如WI-FI接口)。存储器1005可以是高速RAM存储器,也可以是稳定的存储器(non-volatile memory),例如磁盘存储器。存储器1005可选的还可以是独立于前述处理器1001的存储装置。
可选地,终端还可以包括摄像头、RF(Radio Frequency,射频)电路,传感器、音频电路、WiFi模块等等。其中,传感器比如光传感器、运动传感器以及其他传感器。当然,硬件设备还可配置陀螺仪、气压计、湿度计、温度计、红外线传感器等其他传感器,在此不再赘述。
本领域技术人员可以理解,图1中示出的终端结构并不构成对终端的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
如图1所示,作为一种计算机存储介质的存储器1005中可以包括操作系统、网络通信模块、用户接口模块以及应用字符资源同步程序。
在图1所示的终端中,网络接口1004主要用于连接后台服务器,与后台服务器进行数据通信;用户接口1003主要用于连接客户端(用户端),与客户端进行数据通信;而处理器1001可以用于调用存储器1005中存储的应用字符资源同步程序,并执行以下操作:
读取应用的第一语种模板文件,从所述第一语种模板文件中获取所有字符串标识;
查询每个字符串标识分别对应每个语种时的语种译文;
根据所有字符串标识及其分别对应的语种译文生成每个语种分别对应的译文模板文件。
进一步地,处理器1001可以调用存储器1005中存储的应用字符资源同步程序,还执行以下操作:
从预设数据库中获取可翻译的语种,并生成相应的语种列表;
遍历所述语种列表,查询每个字符串标识分别对应每个可翻译的语种时的语种译文。
进一步地,处理器1001可以调用存储器1005中存储的应用字符资源同步程序,还执行以下操作:
从所述第一语种模板文件中遍历所有字符串标识的名称,以得到每个字符串标识的文本;
查询每个字符串标识的文本分别对应每个语种时的语种译文文本。
进一步地,处理器1001可以调用存储器1005中存储的应用字符资源同步程序,还执行以下操作:
将所述第一语种模板文件中每个字符串标识的文本分别替换为对应每个语种时的语种译文文本,以生成每个语种分别对应的译文模板文件。
进一步地,处理器1001可以调用存储器1005中存储的应用字符资源同步程序,还执行以下操作:
生成每个译文模板文件的第一摘要,并在接收到应用发布指令时对所有第一摘要进行校验,以根据校验结果发布应用。
进一步地,处理器1001可以调用存储器1005中存储的应用字符资源同步程序,还执行以下操作:
针对每个译文模板文件,生成每个译文模板文件对应的第一摘要,并将每个第一摘要写入对应的译文模板文件;
在接收到应用发布指令时,从每个译文模板文件中获取对应的第一摘要,并计算生成每个译文模板文件对应的第二摘要;
判断每个译文模板文件的第一摘要与第二摘要是否均一致;
在每个译文模板文件的第一摘要与第二摘要均一致时,发布应用;
在至少一个译文模板文件的第一摘要与第二摘要不一致时,提示应用发布失败。
进一步地,处理器1001可以调用存储器1005中存储的应用字符资源同步程序,还执行以下操作:
对每个译文模板文件的数据进行填充;
设置初始化变量,并对每个译文模板文件填充后的数据进行分组;
根据所述初始化变量依次对每个分组的数据进行循环计算,以得到最终变量,并将所述最终变量作为每个译文模板文件对应的第一摘要。
进一步地,处理器1001可以调用存储器1005中存储的应用字符资源同步程序,还执行以下操作:
通过非对称加密算法对写入第一摘要后的每个译文模板文件进行非对称加密,并将非对称加密的私钥进行唯一存储;
所述从每个译文模板文件中获取对应的第一摘要的步骤包括:
通过所述私钥对每个加密后的译文模板文件进行解密,以获得每个译文模板文件对应的第一摘要。
进一步地,处理器1001可以调用存储器1005中存储的应用字符资源同步程序,还执行以下操作:
将每个第一摘要写入对应的译文模板文件的注释部分;
所述计算生成每个译文模板文件对应的第二摘要的步骤包括:
对每个译文模板文件中除注释部分以外的其他内容进行摘要计算,以生成每个译文模板文件对应的第二摘要。
进一步地,处理器1001可以调用存储器1005中存储的应用字符资源同步程序,还执行以下操作:
获取预设的转换字符串;
将所述转换字符串加入每个译文模板文件中进行拼接,并在拼接后计算生成每个译文模板文件的第一摘要。
本发明应用于应用字符资源同步系统的具体实施例与下述应用于应用字符资源同步方法的各实施例基本相同,在此不作赘述。
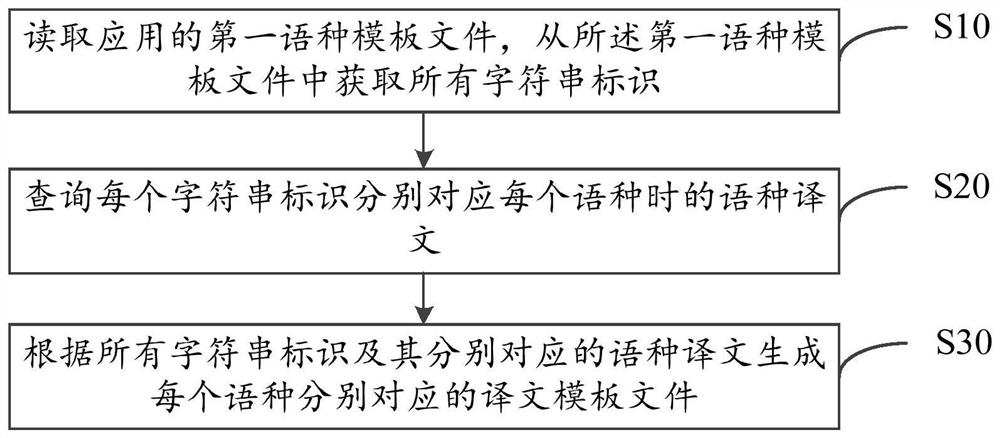
请参照图2,图2为本发明应用字符资源同步方法第一实施例的流程示意图,其中,所述应用字符资源同步方法包括如下步骤:
步骤S10,读取应用的第一语种模板文件,从所述第一语种模板文件中获取所有字符串标识;
在国际化的应用项目中,应用本地可以预先存储有第一语种模板文件,该第一语种模板文件中包括有所有字符串标识在第一语种下对应的译文。例如,该第一语种模板文件可以为英文模板文件,包括有所有字符串标识对应的英语译文。在读取第一语种模板文件后,即可获取到应用在对应的UI界面中所要显示内容的英语译文。
步骤S20,查询每个字符串标识分别对应每个语种时的语种译文;
在从第一语种模板文件中获取到所有字符串标识后,可以对每个字符串标识进行译文查询,以得到每个字符串标识分别对应每个语种时的语种译文。例如,在第一语种模板文件中存在有11个字符串标识,且除第一语种外的其他语种共有12个时,通过查询可以得到每个字符串标识分别对应12个语种的12个语种译文,则11个字符串标识可以通过查询得到对应的132个语种译文。
步骤S30,根据所有字符串标识及其分别对应的语种译文生成每个语种分别对应的译文模板文件;
在获取到所有字符串标识分别对应每个语种的语种译文后,可以将同一语种下的所有字符串标识及其对应的语种译文写入到同一个新的译文模板文件中,以得到该语种所对应的译文模板文件。在将每个语种的所有字符串标识及其对应的语种译文分别写入到对应的译文模板文件后,即可得到每个语种分别对应的译文模板文件。其中,新增的译文模板文件的数量与除第一语种以外的其他语种的数量相同,且每个语种分别对应一个译文模板文件。
可以理解的是,应用在显示UI界面时,若检测到设置的语言为某一语种,则可以从多个译文模板文件中选择该语种对应的译文模板文件,并读取该译文模板文件以在应用的UI界面中显示该语种的译文。
开发人员在开发应用或更新应用时,若需要对UI界面需要显示的字符串标识进行编辑,仅需要对第一语种模板文件进行编辑修改,例如在第一语种模板文件中对字符串标识进行增删查改等操作。在根据应用的实际需求对应调整第一语种模板文件后,通过上述同步步骤即可根据第一语种模板文件生成其他语种分别对应的译文模板文件,确保应用开发或更新后各个国家各个语种的UI界面所显示的文本或译文的内容一致。
在本实施例中,通过读取第一语种模板文件并获取所有的字符串标识,能够针对每个语种查询字符串标识所对应的语种译文。根据每个语种的字符串标识及其对应的语种译文即可生成该语种所对应的译文模板文件,从而得到各个语种的译文模板文件。通过对第一语种模板文件进行修改即可对其他的译文模板文件进行同步修改调整,降低了开发人员在应用开发与更新时的工作量,减少了开发成本,以及避免了在开发过程中人为修改模板文件而可能引发的应用显示错误。
进一步的,参照图3,图3为本发明应用字符资源同步方法第二实施例的流程示意图,基于上述图2所示的实施例,所述步骤S20,查询每个字符串标识分别对应每个语种时的语种译文的步骤包括:
步骤S21,从预设数据库中获取可翻译的语种,并生成相应的语种列表;
步骤S22,遍历所述语种列表,查询每个字符串标识分别对应每个可翻译的语种时的语种译文。
在本实施例中,预设数据库可以为设置于云端服务器的数据库,如MySQL数据库等,预设数据库内存储有各个语种所对应的语种表单。语种表单中属性enable的值可以为0或1,当enable的值为1时,表示该语种为可翻译语种,即可以根据第一语种模板文件中的字符串标识查找到该语种中所对应的语种译文。在遍历得到预设数据库内所有属性enable的值为1的语种后,可以根据这些可进行翻译的语种生成相应的语种列表。
语种列表中的每个语种均能够通过第一语种模板文件生成该语种所对应的译文模板文件。对于每个可翻译的语种,可以通过查询得到所有字符串标识分别对应的语种译文。通过遍历语种列表,即可对所有可翻译的语种进行语种译文的查询,从而生成每个语种分别对应的译文模板文件。
可以理解的是,上述语种列表中可以包含每个语种的id、name、android_short_name、description以及full_name,以分别表示语种的序号、名称、安卓系统短名称、说明以及全称。每个语种的数据可以用数据字典格式进行数据的存储,其中id为键,其余的各个字段为值。
进一步的,参照图4,图4为本发明应用字符资源同步方法第三实施例的流程示意图,基于上述图2所示的实施例,每个字符串标识包括名称和文本;所述步骤S20,查询每个字符串标识分别对应每个语种时的语种译文的步骤包括:
步骤S23,从所述第一语种模板文件中遍历所有字符串标识的名称,以得到每个字符串标识的文本;
步骤S24,查询每个字符串标识的文本分别对应每个语种时的语种译文文本。
在本实施例中,第一语种模板文件和其他语种对应的译文模板文件可以为XML格式文件。在XML格式文件中每个字符串标识的格式可以为:
其中,每个字符串标识包括名称和文本,A为每个字符串标识的名称,B为名称为A时所对应的文本。
以第一语种模板文件为例,若第一语种为英语,A为app_name、B为Gallery时,对应的字符串标识即为:
在第一语种模板文件中,包含有多个字符串标识。通过遍历第一语种模板文件中的所有字符串标识的名称,即可得到每个字符串标识的文本,并将字符串标识的名称与文本进行对应。
第一语种模板文件中的各个字符串标识即为XML文件中的各个子节点,每个子节点具有两个属性,分别是name和text,即字符串标识名称和文本。通过child.attrib[“name”]命令即可定位得到子节点的name,即字符串标识的名称;通过child.text命令则可以定位得到子节点的text,即字符串标识的文本。在遍历XML文件中的所有子节点后,即可获取到第一语种模板文件中所有字符串标识的名称以及每个名称所对应的文本。
可以理解的是,在第一语种为英语时,根据第一语种模板文件所获得的每个字符串标识的文本即为应用页面所显示内容的英语译文。根据英语译文即可通过查询得到该英语译文在其他语种下的语种译文文本。例如,字符串标识的名称为app_name所对应的英语译文为Gallery。通过查询Gallery分别对应每个语种的语种译文,即可得到其他语种的语种译文文本。例如,Gallery分别对应汉语、日语、德语、西班牙语、法语等语种的语种译文为:陈列室、ギャラリー、Galerie、Galería、Galerie。
进一步的,参照图5,图5为本发明应用字符资源同步方法第四实施例的流程示意图,基于上述图4所示的实施例,所述步骤S30,根据所有字符串标识及其分别对应的语种译文生成每个语种分别对应的译文模板文件的步骤包括:
步骤S31,将所述第一语种模板文件中每个字符串标识的文本分别替换为对应每个语种时的语种译文文本,以生成每个语种分别对应的译文模板文件。
在本实施例中,在获得每个字符串标识的文本分别对应每个语种时的语种译文文本后,可以将第一语种模板文件中每个字符串标识的文本替换为不同语种的语种译文文本,并将替换后的模板文件另行存储,该另行存储的文件即为每个语种分别对应的译文模板文件。
例如,将
在将第一语种模板文件中的所有英语译文替换为德语译文文本后,将改替换后的模板文件进行另存为即可得到德语译文模板文件。同样地,将第一语种模板文件中的所有英语译文替换为西班牙语的语种译文文本后,即可得到西班牙语译文模板文件。
通过遍历所有可翻译的语种,并将第一语种模板文件中每个字符串标识的文本进行替换,即可得到每个语种分别对应的译文模板文件。
进一步的,参照图6,图6为本发明应用字符资源同步方法第五实施例的流程示意图,基于上述图2所示的实施例,所述步骤S30,根据所有字符串标识及其分别对应的语种译文生成每个语种分别对应的译文模板文件的步骤之后,还包括:
步骤S40,生成每个译文模板文件的第一摘要,并在接收到应用发布指令时对所有第一摘要进行校验,以根据校验结果发布应用。
在本实施例中,对于每个语种对应的译文模板文件,可以通过摘要算法生成该译文模板文件的第一摘要。则每个译文模板文件分别对应有一个第一摘要。在应用进入发布流程,并接收到用户所触发的应用发布指令时,可以对每个译文模板文件再次进行摘要计算,并将再次计算得到的摘要与原有的第一摘要进行对比。若再次计算得到的摘要与第一摘要完全一致,则表示该译文模板文件在生成后未被开发人员或其他人员进行修改,保证译文模板文件的数据完整性。若再次计算得到的摘要与第一摘要不一致,则表示该译文模板文件在生成后经过开发人员或其他人员修改,其译文模板文件的数据发生了改变。通过在应用发布时,对每个译文模板文件的第一摘要进行校验,能够确定译文模板文件是否被篡改。在所有的译文模板文件均未被篡改时,可以确定应用发布时的校验通过,应用可以成功发布。
进一步的,参照图7,图7为本发明应用字符资源同步方法第六实施例的流程示意图,基于上述图6所示的实施例,所述步骤S40,生成每个译文模板文件的第一摘要,并在接收到应用发布指令时对所有第一摘要进行校验,以根据校验结果发布应用的步骤包括:
步骤S41,针对每个译文模板文件,生成每个译文模板文件对应的第一摘要,并将每个第一摘要写入对应的译文模板文件;
步骤S42,在接收到应用发布指令时,从每个译文模板文件中获取对应的第一摘要,并计算生成每个译文模板文件对应的第二摘要;
步骤S43,判断每个译文模板文件的第一摘要与第二摘要是否均一致;
步骤S44,在每个译文模板文件的第一摘要与第二摘要均一致时,发布应用;
步骤S45,在至少一个译文模板文件的第一摘要与第二摘要不一致时,提示应用发布失败。
在本实施例中,预先设置有摘要算法,在得到每个语种分别对应的译文模板文件后,可以通过预设摘要算法计算生成每个译文模板文件的第一摘要。
译文模板文件在经过修改后,重新计算得到的摘要相比于第一摘要将会发生改变。在计算得到每个译文模板文件的第一摘要后,可以将该第一摘要写入对应的译文模板文件中。即,每个译文模板文件内携带有与其对应的第一摘要。
在系统接收到用户触发的应用发布指令时,译文模板文件的生成时间与应用发布指令的触发时间具有一定的时间差。在这段时间内译文模板文件可能经过开发人员编辑修改,因此在应用发布前需要对每个译文模板文件的数据完整性进行校验,以避免译文模板文件在经过修改后与第一语种模板文件不对应。
系统确认接收到应用发布指令时,可以从每个译文模板文件中获取到预先写入的第一摘要,并通过相同的摘要算法再次进行计算,以生成每个译文模板文件的第二摘要。并判断每个译文模板文件中读取的第一摘要与重新计算得到的第二摘要是否一致。对于某个译文模板文件,若其对应的第一摘要与第二摘要完全一致时,则表示该译文模板文件在生成后未被开发人员或其他人员进行修改或篡改。
系统在发布应用前,需要对所有译文模板文件均进行第一摘要与第二摘要的一致性校验,若每个译文模板文件的第一摘要与第二摘要均一致,则表示所有译文模板文件均未被修改,从而确保了译文模板文件额的数据完整性。若存在有至少一个译文模板文件的第一摘要与第二摘要不一致时,则表示校验不一致的译文模板文件被修改或篡改,此时若发布应用则可能出现应用无法在界面中正常显示译文。即检测到存在至少一个译文模板文件校验失败时,停止发布应用,并提示开发人员应用发布失败。系统还可以将校验失败的译文模板文件显示给开发人员,以便于开发人员进行维护和处理。
进一步的,在第六实施例中,所述步骤S41,针对每个译文模板文件,生成每个译文模板文件对应的第一摘要,并将每个第一摘要写入对应的译文模板文件的步骤包括:
对每个译文模板文件的数据进行填充;
设置初始化变量,并对每个译文模板文件填充后的数据进行分组;
根据所述初始化变量依次对每个分组的数据进行循环计算,以得到最终变量,并将所述最终变量作为每个译文模板文件对应的第一摘要。
在本实施例中,系统中预先设置有相应的摘要算法,通过摘要算法能够将不同长度的明文数据转换为固定长度的密文数据,即针对各个不同的译文模板文件,生成与其对应的第一摘要。不同的译文模板文件所对应的各个第一摘要的长度相同,内容不同。
根据摘要算法可以对每个译文模板文件的数据进行填充,以使填充后的数据长度对512取模的结果为448。填充方式可以为将填充位的第一位设置为1,其他位设置为0。在数据填充完毕后可以在数据尾部添加数据长度为64位的消息长度数据,以记录未填充前译文模板文件的原始数据长度。在添加消息长度后,最终得到的数据长度即为512的整数倍。
设置四个初始化变量分别为A=0x01234567,B=0x89ABCDEF,C=0xFEDCBA98,D=0x76543210。并将最终的数据长度以每512位为一组进行分组。从第一分组开始,根据上述四个初始化变量对第一分组中的数据进行线性函数运算,将运算得到的四个新的变量作为第二分组进行线性函数运算的变量继续进行循环计算,在对最后一个分组进行计算完毕后所得到的四个最终变量即为该译文模板文件对应的第一摘要。其中,摘要算法可以为MD5(Message-Digest Algorithm,消息摘要算法)。每个译文模板文件在经过MD5算法计算得到的第一摘要为固定16字节128位的散列值。
进一步的,参照图8,图8为本发明应用字符资源同步方法第七实施例的流程示意图,基于上述图7所示的实施例,所述步骤S42,在接收到应用发布指令时,从每个译文模板文件中获取对应的第一摘要,并计算生成每个译文模板文件对应的第二摘要的步骤之前,还包括:
步骤S50,通过非对称加密算法对写入第一摘要后的每个译文模板文件进行非对称加密,并将非对称加密的私钥进行唯一存储;
所述步骤S42,在接收到应用发布指令时,从每个译文模板文件中获取对应的第一摘要,并计算生成每个译文模板文件对应的第二摘要的步骤包括:
步骤S421,在接收到应用发布指令时,通过所述私钥对每个加密后的译文模板文件进行解密,以获得每个译文模板文件对应的第一摘要,并计算生成每个译文模板文件对应的第二摘要。
在本实施例中,在对每个译文模板文件写入其对应的第一摘要后,还可以对该译文模板文件进行非对称加密,以确保译文模板文件不被篡改。系统可以预先设置非对称加密算法,如RSA算法,通过非对称加密算法可以生成一对公私密钥对,并通过公钥对每个译文模板文件进行加密。该公钥对应的私钥可以唯一存储在系统进行应用发布时的校验端内,即,加密后的译文模板文件仅能够被校验端所唯一存储的私钥进行解密。在系统接收到应用发布指令时,校验端可以通过运行自动化脚本,使用私钥对每个译文模板文件进行解密,从解密后的每个译文模板文件中获取预先写入的第一摘要,并对解密后的译文模板文件再次进行摘要计算,以生成每个译文模板文件分别对应的第二摘要。
可以理解的是,译文模板文件在经过摘要计算生成第一摘要后将第一摘要写入译文模板文件,则对解密后的译文模板文件再次进行摘要计算时,需要将写入译文模板文件中的第一摘要进行忽略,避免译文模板文件在写入第一摘要后计算得到的第二摘要与原始的第一摘要不一致。
进一步的,参照图9,图9为本发明应用字符资源同步方法第八实施例的流程示意图,基于上述图7所示的实施例,所述步骤S41,针对每个译文模板文件,生成每个译文模板文件对应的第一摘要,并将每个第一摘要写入对应的译文模板文件的步骤包括:
步骤S411,针对每个译文模板文件,生成每个译文模板文件对应的第一摘要,并将每个第一摘要写入对应的译文模板文件的注释部分;
所述步骤S42,在接收到应用发布指令时,从每个译文模板文件中获取对应的第一摘要,并计算生成每个译文模板文件对应的第二摘要的步骤包括:
所述步骤S422,在接收到应用发布指令时,从每个译文模板文件中获取对应的第一摘要,并对每个译文模板文件中除注释部分以外的其他内容进行摘要计算,以生成每个译文模板文件对应的第二摘要。
在本实施例中,在针对每个译文模板文件,生成每个译文模板文件对应的第一摘要后,可以将每个第一摘要写入其对应的译文模板文件的注释部分。在系统接收到应用发布指令时,可以从每个译文模板文件的注释部分中获取对应的第一摘要。可以理解的是,译文模板文件的注释部分不仅包括写入的第一摘要,还可能包括开发人员维护该译文模板文件时所需的内容信息,该注释部分的内容信息仅供开发维护人员阅读,不对译文模板文件的运行产生影响。因此,为了避免注释部分的改动而导致译文模板文件的前后不一致,在通过摘要算法计算每个译文模板文件的第一摘要和第二摘要时,均可以将译文模板文件中的注释部分进行忽略,仅计算注释部分以外的内容的第一摘要和第二摘要,以保证在译文模板文件的注释部分发生改动时,第一摘要和第二摘要仍保持一致。
进一步的,参照图10,图10为本发明应用字符资源同步方法第九实施例的流程示意图,基于上述图7所示的实施例,所述步骤S41,针对每个译文模板文件,生成每个译文模板文件对应的第一摘要,并将每个第一摘要写入对应的译文模板文件的步骤包括:
步骤S412,获取预设的转换字符串;
步骤S413,将所述转换字符串加入每个译文模板文件中进行拼接,并在拼接后计算生成每个译文模板文件的第一摘要,并将每个第一摘要写入对应的译文模板文件。
在本实施例中,系统在根据预设摘要算法计算每个译文模板文件的第一摘要或第二摘要时,可以获取相应的转换字符串,即hashlib串,并将该转换字符串加入每个译文模板文件中进行拼接。例如,系统可以采用二进制形式读取XML格式的译文模板文件,逐行读取每个字节。每读取一行后可以在末尾加入一个转换字符串进行拼接,直至整个译文模板文件读取完毕。通过在计算摘要的过程中加入转换字符串与原有的文件数据进行拼接,能够提升第一摘要的保密性,从而避免其他人员通过第一摘要获取到原始的译文模板文件。
此外,本发明还提出一种计算机可读存储介质,其上存储有应用字符资源同步程序。所述计算机可读存储介质可以是图1的终端中的存储器20,也可以是如ROM(Read-OnlyMemory,只读存储器)/RAM(Random Access Memory,随机存取存储器)、磁碟、光盘中的至少一种,所述计算机可读存储介质包括若干指令用以使得一台具有处理器的应用字符资源同步系统执行本发明各个实施例所述的应用字符资源同步方法。
可以理解的是,在本说明书的描述中,参考术语“一实施例”、“另一实施例”、“其他实施例”、或“第一实施例~第N实施例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者系统中还存在另外的相同要素。
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在如上所述的一个存储介质(如ROM/RAM、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,空调器,或者网络设备等)执行本发明各个实施例所述的方法。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 应用字符资源同步方法、系统及计算机可读存储介质
- 资源同步方法、装置、电子设备及计算机可读存储介质