产生一对话状态追踪模型的装置及方法
文献发布时间:2023-06-19 10:38:35
技术领域
本发明系关于一种产生一对话状态追踪模型的装置及方法。具体而言,本发明系关于一种基于对话记录产生一对话状态追踪模型的装置及方法。
背景技术
目前已有许多企业导入以人工智能(Artificial Intelligence;AI)为基础的对话式服务,例如:采用对话机器人提供客户服务。这类对话式服务涉及自然语言理解、对话管理及自然语言生成等三个面向的技术。对话管理技术中的对话状态追踪系用以判读对话中的关键资讯,为对话式服务能否正确地达成任务(例如:协助使用者办理车祸理赔、协助使用者购票)的重要关键。
某些习知的对话管理技术为规则式的。概要而言,这类技术先对使用者所输入/所说出的句子进行语意理解,再基于语意理解的结果以预定的规则回复。这类技术极度仰赖语意理解的准确度,若未能准确地理解使用者所输入/所说出的句子的语意,则基于预定规则所决定出来的回复也会不准确。此外,由于这类技术受限于预定的规则,因此缺乏弹性。基于前述各种缺点,采用这类技术,一旦发生误判,往往会导致连续的错误,而无法完成任务。
目前已有一些学习式的对话管理技术,其系利用特征来训练神经网络模型,再以经过训练的神经网络模型作为对话状态追踪模型。然而,这类技术能否准确地进行对话状态追踪,进而完成任务,取决于训练神经网络模型时所使用的特征,以及如何以这些特征训练神经网络模型。尽管学习式的对话管理技术优于规则式的对话管理技术,但相较于由人类直接提供服务,仍有相当大的改善空间。有鉴于此,针对学习式的对话管理技术,如何提供适当的特征(例如:含有语意及各种语句关联的特征) 来训练神经网络模型作为对话状态追踪模型,以及如何利用这些特征训练该模型,乃业界亟需努力的目标。
发明内容
本发明的一目的在于提供一种产生一对话状态追踪模型的装置。该装置包含一储存器及一处理器,其中该处理器电性连接至该储存器。该储存器储存一数据库。该处理器根据一询问消息所对应的一询问栏位自该数据库撷取该询问栏位所对应的一栏位特征量,自该数据库撷取该询问栏位所对应的至少一候选词各自对应的一候选词特征量,且将该至少一候选词特征量整合为一整合特征量。该处理器还产生与该询问消息对应的一回复消息的至少一关联子句,根据该至少一关联子句产生一语句关联特征量,且根据该栏位特征量、该整合特征量及该语句关联特征量产生一询问栏位相关特征。该处理器还根据该询问栏位相关特征训练该对话状态追踪模型。
本发明的又一目的在于提供一种产生一对话状态追踪模型的方法,其系适用于一电子装置。该电子装置储存一数据库。该方法包含下列步骤:(a)根据一询问消息所对应的一询问栏位自该数据库撷取该询问栏位所对应的一栏位特征量,(b)自该数据库撷取该询问栏位所对应的至少一候选词各自对应的一候选词特征量,(c)将该至少一候选词特征量整合为一整合特征量,(d)产生与该询问消息对应的一回复消息的至少一关联子句,(e)根据该至少一关联子句产生一语句关联特征量,(f)根据该栏位特征量、该整合特征量及该语句关联特征量产生一询问栏位相关特征,以及(g)根据该询问栏位相关特征训练该对话状态追踪模型。
本发明所提供的产生一对话状态追踪模型的技术(至少包含装置及方法) 会根据一轮对话中的询问消息所对应的询问栏位,自数据库撷取出不同的特征量(包含询问栏位本身所对应的栏位特征量及候选词所对应的候选词特征量)。此外,本发明会找出该轮对话中的回复消息的关联子句,且据以产生语句关联特征量。本发明再根据自数据库撷取出的特征量及语句关联特征量产生用以训练一对话状态追踪模型的询问栏位相关特征,且以询问栏位相关特征来训练该对话状态追踪模型。
在某些实施态样中,本发明还可利用该回复消息从数据库撷取出其他的特征量,而这些其他的特征量与关联资讯及语意资讯相关。本发明还可利用这些其他的特征量,产生其他用以训练该对话状态追踪模型的特征(例如:进阶关联特征、语意理解特征),再以询问栏位相关特征与进阶关联特征或/及语意理解特征一起来训练对话状态追踪模型。
本发明在产生用来训练对话状态追踪模型的各种特征时,考量了与询问消息及回复消息相关的多种特征量,考量了回复消息的各种关联子句及语意,且考量了这些特征量、关联子句与语意彼此的交互影响,因此以本发明所产生的特征训练出来的对话状态追踪模型能大幅度地提高对话状态追踪的准确度,进而提高完成任务的比例。
以下结合附图阐述本发明的详细技术及实施方式,俾使本领域技术人员能理解所请求保护的发明的特征。
附图说明
图1A描绘第一实施方式的产生模型装置1的架构示意图;
图1B描绘对话记录的一具体范例;
图1C描绘产生询问栏位相关特征tf1的示意图;
图1D描绘产生询问栏位相关特征tf1的另一示意图;
图1E描绘产生进阶关联特征tf2的示意图;
图1F描绘产生语意理解特征tf3的示意图;
图2A描绘第二实施方式的产生模型方法的流程图;
图2B描绘某些实施方式的产生模型方法的流程图;
图2C描绘某些实施方式的产生模型方法的部分流程图;以及
图2D描绘某些实施方式的产生模型方法的部分流程图。
具体实施方式
以下将通过实施方式来解释本发明所提供的产生一对话状态追踪模型的装置及方法。然而,这些实施方式并非用以限制本发明需在如这些实施方式所述的任何环境、应用或方式方能实施。因此,关于以下实施方式的说明仅在于阐释本发明的目的,而非用以限制本发明的范围。应理解,在以下实施方式及附图中,与本发明非直接相关的元件已省略而未绘示,且图附图式中各元件的尺寸以及元件间的尺寸比例仅为便于绘示及说明,而非用以限制本发明的范围。
本发明的第一实施方式为一种产生一对话状态追踪模型10的装置(下称「模型产生装置」)1,其架构示意图系描绘于图1A。模型产生装置1包含一储存器 11及一处理器13,且二者电性连接。储存器11可为一硬盘(Hard Disk Drive;HDD)、一通用串行总线(Universal Serial Bus;USB)盘、一光盘(Compact Disk;CD)或本领域技术人员所知的任何其他具有相同功能的非暂态储存媒体或装置。处理器13可为各种处理器、中央处理单元(Central Processing Unit;CPU)、微处理器(Microprocessor Unit;MPU)、数字信号处理器(Digital Signal Processor;DSP)或本领域技术人员所知的任何其他具有相同功能的计算装置。
于本实施方式中,模型产生装置1的储存器11储存一数据库15,且数据库15包含某一任务(例如:保险理赔、售票系统,但不以此为限)的对话常用的多个词汇、各词汇的一特征量以及词汇间的对应关系(例如:哪些词汇之间彼此具有关联)。各词汇的特征量可为一特征向量。举例而言,这些特征量可为将这些词汇经由一词转向量(word to vector)演算法转换至一向量空间后所得到的多个词向量。
于本实施方式中,储存器11还储存一人机对话系统(例如:一对话机器人) 与一使用者间的一对话记录D。对话记录D包含至少一轮对话,各轮对话包含一询问消息及一回复消息,且同一轮对话中的询问消息及回复消息彼此对应。一轮对话中的询问消息为人机对话系统所提出的问题,而一轮对话中的回复消息为使用者针对该询问消息的回复。为便于理解,请参图1B所示的一具体范例,但其非用以限制本发明的范围。于该具体范例中,一对话记录包含三轮对话D1、D2、D3,其中对话D1包含彼此对应的询问消息Q1及回复消息R1,对话D2包含彼此对应的询问消息Q2及回复消息R2,且对话D3包含彼此对应的询问消息Q3及回复消息R3。
需说明的是,于某些实施方式中,对话记录D可不储存于储存器11,而是由模型产生装置1所包括的一接收接口(例如:一通用串行总线接口、一网络接口,但不以此为限)接收。在这些实施方式中,该接收接口与处理器13电性连接。
于本实施方式中,模型产生装置1的处理器13会根据对话记录D中的某一轮对话的询问消息Qm及回复消息Rm产生用来训练一对话状态追踪模型10的询问栏位相关特征tf1,再利用询问栏位相关特征tf1来训练对话状态追踪模型10。
询问消息Qm为人机对话系统所提出的问题,因此询问消息Qm预设地对应至一询问栏位(未绘示)。询问消息Qm所对应的询问栏位代表人机对话系统期望从使用者得到的资讯。举例而言,若询问消息Qm的内容为「请问您的生日?」,则其对应的询问栏位可为「生日」,代表人机对话系统期望得知使用者的生日。某些询问消息 Qm则预设地对应至一询问栏位及一栏位回复(未绘示)。询问消息Qm所对应的询问栏位及栏位回复,代表人机对话系统期望使用者确认某一资讯的正确性。举例而言,若询问消息Qm的内容为「请问您的生日是3月3日吗?」,则其对应的询问栏位及栏位回复可分别为「生日」及「3月3日」,代表人机对话系统希望使用者确认其生日是否为3月3日。
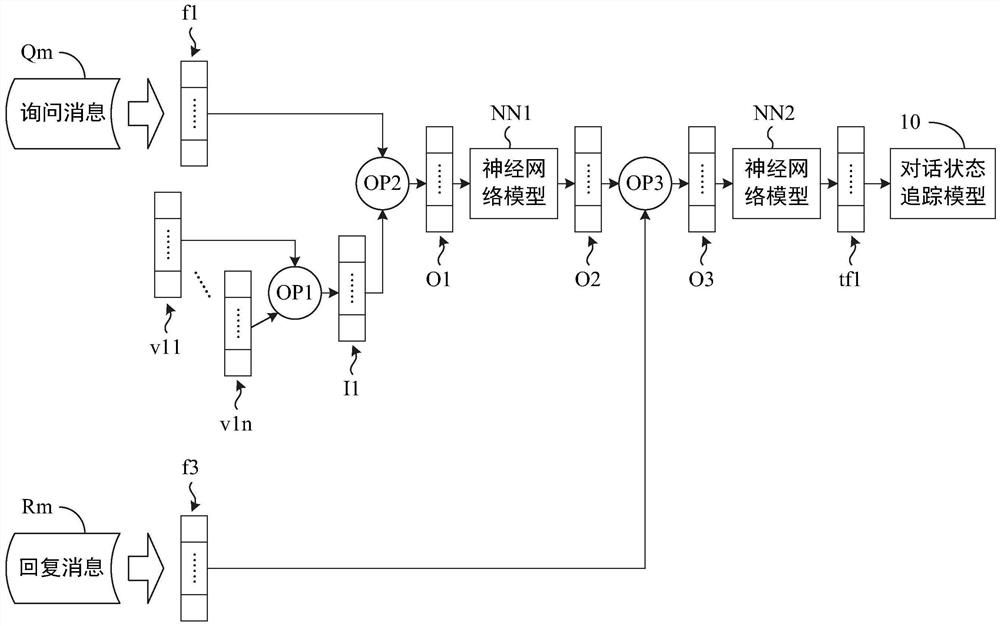
请参图1C。兹先说明询问消息Qm对应至一询问栏位时处理器13所执行的运作。处理器13根据询问消息Qm所对应的询问栏位(例如:生日)自数据库15 撷取询问栏位所对应的一栏位特征量f1。具体而言,处理器13系从数据库15中找出与询问栏位相同的词汇,并以该词汇对应的特征量作为栏位特征量f1。此外,处理器 13还自数据库15撷取询问栏位所对应的至少一候选词(未绘示)各自对应的一候选词特征量。具体而言,处理器13根据数据库15所储存的词汇间的对应关系,找出询问栏位此一词汇所对应的词汇作为候选词,再撷取出各候选词的特征量作为候选词特征量。为便于后续说明,兹假设处理器13经前述处理后得到候选词特征量v11、……、 v1n。之后,处理器13以一运作OP1(例如:加总、串接(concatenate)、内积,但不以此为限)将候选词特征量v11、……、v1n整合为一整合特征量I1。举例而言,处理器13可将候选词特征量v11、……、v1n加总,且以加总后的结果作为整合特征量I1。
另外,处理器13针对与询问消息Qm对应的回复消息Rm分析,找出回复消息Rm的各种关联子句,再根据回复消息Rm的关联子句产生一语句关联特征量f3。举例而言,处理器13可将回复消息Rm断词并标注词性,再采用中国台湾发明专利第 I666558号所揭露的技术来产生回复消息Rm的关联子句。处理器13可将各关联子句个别地输入一神经网络模型(例如:卷积神经网络(Convolutional Neural Network; CNN),但不以此为限)以产生一关联子句特征量,再将所有的关联子句特征量整合 (例如:加总、串接、内积,但不以此为限)为语句关联特征量f3。需说明的是,前述产生回复消息Rm的关联子句的技术为本领域技术人员所熟知的技术,故未赘言。
接着,处理器13根据栏位特征量f1、整合特征量I1及语句关联特征量f3 产生一询问栏位相关特征tf1。于某些实施方式中,处理器13藉由一运作OP2将栏位特征量f1及整合特征量I1整合为一输出特征量O1。举例而言,处理器13可将栏位特征量f1与整合特征量I1进行向量内积以得到输出特征量O1,将栏位特征量f1与整合特征量I1进行向量内积的用意在于找出二者间的相似度,亦可理解为找出栏位特征量f1落在询问栏位空间中的那一区块。接着,处理器13将输出特征量O1输入一神经网络模型NN1以产生一输出特征量O2。之后,处理器13以一运作OP3将输出特征量O2及语句关联特征量f3整合(例如:加总、串接、内积,但不以此为限)以产生一输出特征量O3。之后,处理器13将输出特征量O3输入一神经网络模型NN2以产生询问栏位相关特征tf1。上述神经网络模型NN1、NN2各可为一卷积神经网络、一深度神经网络(Deep Neural Network;DNN),但不以此为限。
之后,处理器13根据询问栏位相关特征tf1训练对话状态追踪模型10。需说明的是,对话状态追踪模型10可为一卷积神经网络、一深度神经网络或其他神经网络。
请参图1D。接着说明询问消息Qm对应至一询问栏位及一栏位回复时处理器13所执行的运作。与图1C所示的情况类似,处理器13会根据询问消息Qm所对应的询问栏位,采取雷同的运作产生栏位特征量f1与整合特征量I1,兹不赘言。以下说明将着重于与图1C不同之处。
处理器13还会根据询问消息Qm所对应的栏位回复自数据库15撷取其所对应的一回复特征量f2。具体而言,处理器13系从数据库15中找出与栏位回复相同的词汇,并以该词汇对应的特征量作为回复特征量f2。举例而言,若询问消息Qm的内容为「请问您的生日是3月3日吗?」,则其对应的栏位回复可为「3月3日」,处理器13便据以撷取出对应的回复特征量f2。此外,处理器13自数据库15撷取栏位回复所对应的至少一候选词(未绘示)各自对应的一候选词特征量。具体而言,处理器13根据数据库15所储存的词汇间的对应关系,找出栏位回复(例如:3月3日) 此一词汇所对应的词汇作为候选词,再撷取出各候选词的特征量作为候选词特征量。为便于后续说明,兹假设处理器13经前述处理后得到候选词特征量v21、……、v2m。之后,处理器13以一运作OP4(例如:加总、串接、内积,但不以此为限)将候选词特征量v21、……、v2m整合为一整合特征量I2。
之后,处理器13便根据栏位特征量f1、回复特征量f2、整合特征量I1、I2 及语句关联特征量f3产生询问栏位相关特征tf1。于某些实施方式中,处理器13藉由运作OP2将栏位特征量f1及整合特征量I1整合为输出特征量O1,其已详述于前。此外,处理器13藉由一运作OP5将回复特征量f2及整合特征量I2整合为输出特征量 O4。举例而言,处理器13可将回复特征量f2与整合特征量I2进行向量内积以得到输出特征量O4,将回复特征量f2与整合特征量I2进行向量内积的用意在于找出二者间的相似度,亦可理解为找出回复特征量f2落在栏位回复空间中的那一区块。接着,处理器13将输出特征量O1、输出特征量O4及语句关联特征量f3输入一神经网络模型 NN3以产生询问栏位相关特征tf1。前述神经网络模型NN3可为一卷积神经网络、一深度神经网络,但不以此为限。之后,处理器13根据询问栏位相关特征tf1训练对话状态追踪模型10。
请参图1E。于某些实施方式中,模型产生装置1的处理器13除了产生询问栏位相关特征tf1,还会产生一进阶关联特征tf2。在这些实施方式中,处理器13系利用栏位相关特征tf1及进阶关联特征tf2训练对话状态追踪模型10。
具体而言,在这些E储存器11还储存多个预设栏位12a、……、12k,且预设栏位12a、……、12k的内容为何系取决于模型产生装置1目前所处理的对话记录 D与哪一工作任务相关。举例而言,若对话记录D与保险理赔相关,则预设栏位 12a、……、12k可包含姓名、生日、地址、出险类型等等。
在这些实施方式中,处理器13根据回复消息Rm及预设栏位12a、……、 12k,自数据库15撷取至少一候选词(未绘示)各自对应的候选词特征量。具体而言,处理器13检视回复消息Rm中是否有对应至任一预设栏位12a、……、12k的相关资讯,再根据数据库15所储存的词汇间的对应关系,找出相关资讯所对应的词汇作为候选词,再撷取出各候选词的特征量作为候选词特征量。为便于后续说明,兹假设处理器13经前述处理后得到候选词特征量v31、……、v3p。之后,处理器13以一运作 OP6(例如:加总、串接、内积,但不以此为限)将候选词特征量v31、……、v3p整合为一整合特征量I3。
接着,处理器13根据语句关联特征量f3及整合特征量I3产生进阶关联特征tf2。于某些实施方式中,处理器13藉由一运作OP7(例如:加总、串接、内积,但不以此为限)将语句关联特征量f3及整合特征量I3整合为一输出特征量O5,再将输出特征量O5输入一神经网络模型NN4以产生进阶关联特征。前述神经网络模型 NN4可为一卷积神经网络、一深度神经网络,但不以此为限。之后,处理器13根据询问栏位相关特征tf1及进阶关联特征tf2训练对话状态追踪模型10。
请参图1F。于某些实施方式中,模型产生装置1的处理器13除了产生询问栏位相关特征tf1,还会产生一语意理解特征tf3。在这些实施方式中,处理器13系利用栏位相关特征tf1及语意理解特征tf3训练对话状态追踪模型10。
具体而言,处理器13对回复消息Rm进行自然语言理解(Natural LanguageUnderstanding;NLU)分析以得一语意理解栏位(未绘示)及一语意理解回复(未绘示),其目的在于透过自然语言理解的技术分析出回复消息Rm中的栏位消息以及与栏位消息对应的回复。需说明的是,本领域技术人员应熟知自然语言理解的运作方式,故不详述其运作细节。
处理器13自数据库15撷取语意理解栏位所对应的一栏位特征量f4。具体而言,处理器13系从数据库15中找出与语意理解栏位相同的词汇,并以该词汇对应的特征量作为栏位特征量f4。另外,处理器13自数据库15撷取语意理解栏位所对应的至少一候选词(未绘示)各自对应的一候选词特征量。具体而言,处理器13根据数据库15所储存的词汇间的对应关系,找出语意理解栏位此一词汇所对应的词汇作为候选词,再撷取出各候选词的特征量作为候选词特征量。为便于后续说明,兹假设处理器13经前述处理后得到候选词特征量v41、……、v4q。之后,处理器13以一运作 OP8(例如:加总、串接、内积,但不以此为限)将候选词特征量v41、……、v4q整合为一整合特征量I4。
另外,处理器13自数据库15撷取语意理解回复所对应的一回复特征量f5。具体而言,处理器13系从数据库15中找出与语意理解回复相同的词汇,并以该词汇对应的特征量作为回复特征量f5。处理器13还自数据库15撷取语意理解回复所对应的至少一候选词(未绘示)各自对应的一候选词特征量。具体而言,处理器13根据数据库15所储存的词汇间的对应关系,找出语意理解回复此一词汇所对应的词汇作为候选词,再撷取出各候选词的特征量作为候选词特征量。为便于后续说明,兹假设处理器13经前述处理后得到候选词特征量v51、……、v5s。之后,处理器13以一运作 OP9(例如:加总、串接、内积,但不以此为限)将候选词特征量v51、……、v5s整合为一整合特征量I5。
处理器13根据栏位特征量f4、整合特征量I4、回复特征量f5及整合特征量I5产生一语意理解特征tf3。于某些实施方式中,处理器13以一运作OP10(例如:加总、串接、内积,但不以此为限)将栏位特征量f4及整合特征量I4整合为一输出特征量O6,以一运作OP11(例如:加总、串接、内积,但不以此为限)将回复特征量f5及整合特征量I5整合为一输出特征量O7,且以一运作OP12(例如:加总、串接、内积,但不以此为限)将输出特征量O6及输出特征量O7整合为一输出特征量 O8。之后,处理器13将输出特征量O8输入一神经网络模型NN5以产生语意理解特征tf3。前述神经网络模型NN5可为一卷积神经网络、一深度神经网络,但不以此为限。之后,处理器13根据询问栏位相关特征tf1及进阶关联特征tf3训练对话状态追踪模型10。
于某些实施方式中,模型产生装置1可综合地使用前述各种技术产生多种用来训练对话状态追踪模型10的特征,再以这些特征一起来训练对话状态追踪模型 10。简言之,在这些实施方式中,处理器13会采用前述的技术产生询问栏位相关特征 tf1、进阶关联特征tf2及进阶关联特征tf3,再以询问栏位相关特征tf1、进阶关联特征 tf2及语意理解特征tf3训练对话状态追踪模型10。
如前所述,对话记录D可包含多轮对话,且各轮对话包含一询问消息及一回复消息。因此,在某些实施方式中,处理器13可基于各轮对话的询问消息及回复消息产生对应的询问栏位相关特征tf1,甚至还产生进阶关联特征tf2或/及语意理解特征tf3,再据以训练对话状态追踪模型10,兹不赘言。
综上所述,模型产生装置1会根据询问消息所对应的询问栏位,自数据库撷取不同的特征量(包含询问栏位本身所对应的栏位特征量及候选词所对应的候选词特征量)。模型产生装置1亦会找出回复消息的关联子句,且据以产生语句关联特征量。之后,模型产生装置1再根据自数据库撷取出的特征量及语句关联特征量产生用以训练一对话状态追踪模型的询问栏位相关特征,且以询问栏位相关特征来训练该对话状态追踪模型。
模型产生装置1还可进一步地从回复消息找出其他可用的关联资讯及语意资讯,据以产生进阶关联特征及语意理解特征,再利用询问栏位相关特征与进阶关联特征或/及语意理解特征来训练该对话状态追踪模型。由于模型产生装置1考量了询问消息及回复消息中的多种不同的特征量,考量了回复消息中的各种关联子句及语意,且考量了这些特征量、关联子句及语意彼此的交互影响,因此大幅度地提高对话状态追踪的准确度,进而提高完成一对话任务的比例。
本发明的第二实施方式为一种产生一对话状态追踪模型的方法(下称「模型产生方法」),其主要流程图系描绘于图2A。该模型产生方法适用于一电子装置(例如:第一实施方式中的模型产生装置1)。该电子装置储存一数据库,其中该数据库包含某一任务的对话常用的多个词汇、各词汇的一特征量以及词汇间的对应关系。该电子装置还储存一人机对话系统与一使用者间的一对话记录,且该对话记录包含至少一轮对话。各轮对话包含一询问消息及一回复消息,且同一轮对话中的询问消息及回复消息彼此对应。
模型产生方法会根据一轮对话中的一询问消息及一回复消息产生用来训练该对话状态追踪模型的询问栏位相关特征,再利用该询问栏位相关特征来训练该对话状态追踪模型。具体而言,于步骤S201,由该电子装置根据该询问消息所对应的一询问栏位(例如:生日)自该数据库撷取该询问栏位所对应的一栏位特征量。于步骤S203,由该电子装置自该数据库撷取该询问栏位所对应的至少一候选词各自对应的一候选词特征量。需说明的是,本发明未限制步骤S201及步骤S203的执行顺序;换言之,步骤S203亦可早于步骤S201执行,或者二步骤可同时执行。之后,于步骤S205,由该电子装置将该至少一候选词特征量整合(例如:加总、串接、内积,但不以此为限) 为一整合特征量。
另外,于步骤S207,由该电子装置产生该回复消息的至少一关联子句。需说明的是,本发明亦未限制步骤S201、S203及S207的执行顺序;换言之,步骤S207 亦可早于步骤S201或/及S203执行,亦可与步骤S201或/及S203同时执行。于步骤 S209,由该电子装置根据这些关联子句产生一语句关联特征量。接着,于步骤S211,由该电子装置根据该栏位特征量、该整合特征量及该语句关联特征量产生该询问栏位相关特征。之后,于步骤S213,由该电子装置根据该询问栏位相关特征训练该对话状态追踪模型。
在某些实施方式中,步骤S211可包含:步骤(a)将该栏位特征量及该整合特征量整合(例如:加总、串接、内积,但不以此为限)为一输出特征量,步骤(b)将步骤(a)产生的输出特征量输入一神经网络模型以产生另一输出特征量,步骤(c)将步骤(b) 产生的输出特征量及该语句关联特征量整合(例如:加总、串接、内积,但不以此为限)以产生一输出特征量,以及步骤(d)将步骤(c)所产生的输出特征量输入另一神经网络模型以产生该询问栏位相关特征。
于某些实施方式中,该询问消息除了对应至一询问栏位,还对应至一栏位回复。这些实施方式的模型产生方法可执行如图2B所示的流程。于这些实施方式中,该模型产生方法亦会执行前述步骤S201至步骤S209。另外,于步骤S231,由该电子装置根据该询问消息所对应的该栏位回复自该数据库撷取其所对应的一回复特征量。于步骤S233,由该电子装置自该数据库撷取该栏位回复所对应的至少一候选词各自对应的一候选词特征量。需说明的是,本发明亦未限制步骤S201、S203、S207、S231 及S233的执行顺序。之后,于步骤S235,由该电子装置将步骤S233所撷取的该至少一候选词特征量整合(例如:加总、串接、内积,但不以此为限)为一整合特征量。于步骤S237,由该电子装置根据该栏位特征量、该回复特征量、步骤S205所产生的整合特征量、步骤S235所产生的整合特征量及该语句关联特征量产生该询问栏位相关特征。之后,于步骤S213,由该电子装置根据该询问栏位相关特征训练该对话状态追踪模型。
于某些实施方式中,步骤S237可包含:步骤(a)将该栏位特征量及步骤S205 所产生的整合特征量整合(例如:加总、串接、内积,但不以此为限)为一输出特征量,步骤(b)将该回复特征量及步骤S235所产生的整合特征量整合(例如:加总、串接、内积,但不以此为限)为另一输出特征量,以及步骤(c)将步骤(a)产生的输出特征量、步骤(b)产生的输出特征量及该语句关联特征量输入一神经网络模型以产生该询问栏位相关特征。
于某些实施方式中,模型产生方法除了以图2A的流程或图2B的流程产生询问栏位相关特征,还会以图2C所示的流程产生一进阶关联特征。
于这些实施方式中,该电子装置储存还储存多个预设栏位。于步骤S241,由该电子装置根据该回复消息及这些预设栏位自该数据库撷取至少一候选词各自对应的一候选词特征量。举例而言,步骤S241可检视该回复消息中是否有对应至任一预设栏位的相关资讯,再根据数据库所储存的词汇间的对应关系,找出相关资讯所对应的词汇作为候选词,再撷取出各候选词的特征量作为候选词特征量。于步骤S243,由该电子装置将步骤S241所撷取出的该至少一候选词特征量整合为一整合特征量。接着,于步骤S245,由该电子装置根据该语句关联特征量及步骤S243所产生的整合特征量产生一进阶关联特征。之后,于步骤S247,由该电子装置根据该询问栏位相关特征及该进阶关联特征训练该对话状态追踪模型。
在某些实施方式中,前述步骤S245可包含:步骤(a)将该语句关联特征量及步骤S243所产生的整合特征量整合为一输出特征量,以及步骤(b)将步骤(a)所产生的输出特征量输入一神经网络模型以产生该进阶关联特征。
于某些实施方式中,模型产生方法除了以图2A的流程或图2B的流程产生询问栏位相关特征,还会以图2D所示的流程产生一语意理解特征。具体而言,于步骤S251,由该电子装置对该回复消息进行自然语言理解分析以得一语意理解栏位及一语意理解回复。于步骤S253,由该电子装置自该数据库撷取该语意理解栏位所对应的一栏位特征量。于步骤S255,由该电子装置自该数据库撷取该语意理解栏位所对应的至少一候选词各自对应的一候选词特征量。于步骤S257,由该电子装置将步骤S255 所撷取的该至少一候选词特征量整合为一整合特征量。
接着,于步骤S259,由该电子装置自该数据库撷取该语意理解回复所对应的一回复特征量。于步骤S261,由该电子装置自该数据库撷取该语意理解回复所对应的至少一候选词各自对应的一候选词特征量。需说明的是,本发明未限制步骤S253、 S255、S259及S261的执行顺序。于步骤S263,由该电子装置将步骤S261所撷取的该至少一候选词特征量整合为一整合特征量。于步骤S265,由该电子装置根据步骤 S253所撷取的栏位特征量、步骤S257所产生的整合特征量、步骤S259所撷取的回复特征量及步骤S263所产生的整合特征量产生该语意理解特征。之后,于步骤S267,由该电子装置根据该询问栏位相关特征及该语意理解特征训练该对话状态追踪模型。
在某些实施方式中,前述步骤S265可包含:步骤(a)将步骤S253所撷取的栏位特征量及该步骤S257所产生的整合特征量整合(例如:加总、串接、内积,但不以此为限)为一输出特征量,步骤(b)将步骤S259所撷取的回复特征量及步骤S263所产生的整合特征量整合(例如:加总、串接、内积,但不以此为限)为另一输出特征量,步骤(c)将步骤(a)所产生的输出特征量及步骤(b)所产生的输出特征量整合为一输出特征量,以及步骤(d)将步骤(c)所产生的输出特征量输入一神经网络模型以产生该语意理解特征。
于某些实施方式中,该模型产生方法可综合地使用前述图2A至图2D的流程来产生用来训练对话状态追踪模型的各种特征,再以这些特征一起来训练对话状态追踪模型。本领域技术人员可直接了解如何基于上述实施方式综合地使用前述流程,故不赘述。
另外,于某些实施方式中,若一对话记录包含多轮对话且各轮对话包含一询问消息及一回复消息,则模型产生方法可基于各轮对话的询问消息及回复消息产生对应的询问栏位相关特征,甚至还可产生一进阶关联特征及一语意理解特征,再据以训练该对话状态追踪模型,兹不赘言。
除了上述步骤,第二实施方式能执行第一实施方式所描述的模型产生装置 1的所有运作及步骤,具有同样的功能,且达到同样的技术效果。本领域技术人员可直接了解第二实施方式如何基于上述第一实施方式以执行此等运作及步骤,具有同样的功能,并达到同样的技术效果,故不赘述。
需说明的是,于本案的申请专利范围中,某些用语(包含:栏位特征量、候选词、候选词特征量、整合特征量、输出特征量、回复特征量、神经网络模型等) 前被冠以「第一」、「第二」及「第三」,这些数字仅用来区分这些用语系指不同项目。
综上所述,本发明所提供的产生一对话状态追踪模型的技术(至少包含装置及方法)根据询问消息所对应的询问栏位自数据库撷取出不同的特征量(包含询问栏位本身所对应的栏位特征量及候选词所对应的候选词特征量)。此外,本发明会找出该轮对话中的回复消息的关联子句,且据以产生语句关联特征量。接着,本发明根据自数据库撷取出的特征量及语句关联特征量产生用以训练一对话状态追踪模型的询问栏位相关特征,且以询问栏位相关特征来训练该对话状态追踪模型。
本发明还可从回复消息找出其他可用的关联资讯及语意资讯,本发明可利用这些不同的特征量产生进阶关联特征及语意理解特征,且利用询问栏位相关特征与进阶关联特征或/及语意理解特征来训练该对话状态追踪模型。由此可知,本发明考量了与询问消息及回复消息相关的多种不同的特征量,考量了回复消息的各种关联子句及语意,且考量了这些特征量、关联子句与语意彼此的交互影响,因此,本发明所提供的产生一对话状态追踪模型能大幅度地提高对话状态追踪的准确度,进而提高完成任务的比例。
上述实施方式仅为例示性说明本发明的部分实施态样,以及阐释本发明的技术特征,而非用来限制本发明的保护范畴及范围。任何本领域技术人员可轻易完成的改变或均等性的安排均属于本发明所主张的范围,本发明的权利保护范围应以权利要求为准。
- 产生一对话状态追踪模型的装置及方法
- 一种对话状态追踪方法、装置、设备及存储介质