基于数据管道模型的网络爬虫方法及系统
文献发布时间:2023-06-19 11:29:13
技术领域
本发明涉及互联网应用技术领域,具体涉及一种基于数据管道模型的网络爬虫方法及系统。
背景技术
网络爬虫是一种可以按规则自动采集互联网信息的程序或脚本,程序开发者针对不同的网页结构和特点构造网络爬虫程序,实现对网络站点的大规模数据采集。使用网络爬虫可以更加高效、实时和准确的从互联网中采集大规模数据。随着大数据时代的来临,对网络爬虫的需求也日益增加。为满足增长的数据需求,程序开发者使用异步采集、多线程采集、分布式等手段,不断提高采集效率。爬虫技术的进步虽然提高了数据采集的效率,但在采集数据到业务应用的过程仍存在一些问题。
当爬虫将解析出的结构化数据存储至数据库后,业务系统使用这些数据仍需要定期从数据库提取数据,完成数据预处理和数据清洗后存入业务数据库。爬虫采集的数据难以直接为业务系统所用,采集的数据需要通过软件、编码等方式进行再加工,采集数据到数据应用过程不连贯。这些问题都增加了数据采集到数据应用的实际成本。现阶段通常采用编写数据清洗转存的程序来实现与业务系统的数据对接,但随着采集数据源的不断增加,数据清洗转存程序的开发维护成本也随之增加。在网络爬虫的数据采集流程中插入对数据清洗、处理和输出的环节不灵活,网络爬虫与业务系统数据流转成本高。
发明内容
本发明要解决的技术问题是提供一种整合数据清洗、处理和输出环节与数据采集流程,且保证爬虫系统的通用性,支撑数据清洗、应用处理的灵活配置。的基于数据管道模型的网络爬虫方法及系统。
为解决上述技术问题,本发明提供了一种基于数据管道模型的网络爬虫方法,包括以下步骤:
进行管道模型初始化配置,所述管道模型初始化包括数据采集规则的配置、数据清洗规则的配置、数据应用规则的配置和数据存储与服务规则的配置;
爬虫系统根据所述数据采集规则开启数据采集工程并采集数据,将爬取到的数据存储至缓存数据库;
根据用户需要选择进行数据清洗或数据应用,将数据从缓存数据库中提取出来并进行数据清洗或数据应用的处理;
根据用户需要将处理后的数据存储至指定业务数据库或爬虫数据库。
进一步地,所述数据采集规则的配置包括:
配置页面初始URL和遍历方式构建任务队列,用于使爬虫系统从队列中逐个取出URL并进行数据采集;
配置数据解析规则,用于使爬虫系统根据使用者需求解析网页元素或从数据接口中提取所需字段;
设置采集频率、并发数量、最大重试次数、代理IP池和User-Agent池,用于控制爬虫系统运行时的状态,在遵守Reboot协议的基础上控制数据采集的速度和持续采集时间。
进一步地,所述数据清洗规则的配置为:
通过系统接口规范将相应的清洗功能加入数据清洗规则,所述清洗功能包括格式校验、缺失值处理、数据一致化处理、异常值处理和编码统一。
进一步地,所述数据应用规则的配置为:
通过系统接口规范将相应的应用功能加入数据应用规则,所述应用功能包括图文分离、地名解析、情感倾向识别、音视频压缩、正文重编码、附件下载和图片压缩裁剪。
进一步地,所述数据存储与服务规则的配置为:
指定数据存储结构和数据存储地址,将上游数据存储至指定业务数据库或爬虫数据库,进行数据缓存服务和数据检索服务的配置。
进一步地,所述将数据从缓存数据库中提取出来并进行数据清洗或数据应用的处理后,根据用户需求选择进行数据推送服务,将处理后的数据以消息形式推送,推送后的数据不再进行存储。
进一步地,所述根据用户需要将处理后的数据存储至指定业务数据库或爬虫数据库,当处理后的数据存储至所述爬虫数据库时自动构建数据缓存服务和数据检索服务。
进一步地,所述将数据从缓存数据库中提取出来并进行数据清洗或数据应用的处理时,提取数据的频率与爬虫系统采集数据时的频率保持一致。
本发明还提供了一种基于数据管道模型的网络爬虫系统,包括数据采集模块、数据处理模块和数据存储与服务模块,
所述数据采集模块根据配置的数据采集规则生成爬虫采集工程并采集数据,采集到的数据存入缓存数据库;
所述数据处理模块中封装有数据清洗模块和数据应用模块,根据用户需要从缓存数据库中提取数据并执行清洗功能或应用功能的处理;
所述数据存储与服务模块在数据处理完后,根据用户需要将处理后的数据存储至指定业务数据库或爬虫数据库,并对存入爬虫数据库的数据构建数据缓存服务和数据检索服务。
进一步地,还包括用户界面,所述用户界面通过调用底层接口服务给用户提供控制平台,通过用户界面对数据采集模块、数据处理模块和数据存储与服务模块进行配置和任务执行状态的查看。
本发明将数据采集规则的配置、数据清洗规则的配置、数据应用规则的配置和数据存储与服务规则等环节视为部分组件进行灵活配置,根据不同的用户需求实现相应的数据清洗、数据应用和数据存储与服务功能,将数据采集、数据清洗、数据应用、数据存储与服务不同部分组件结合在一起,形成直达业务系统的数据管道,实现采集数据到业务系统的管道化流转,降低了数据采集到数据应用的实际成本,弥补了现有爬虫系统在数据输出和数据应用上的不足。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,并可依照说明书的内容予以实施,以下以本发明的较佳实施例并配合附图详细说明如后。
附图说明
图1是基于数据管道模型的网络爬虫方法的流程图。
图2是基于数据管道模型的网络爬虫系统的整体架构图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
在本发明的描述中,术语“包括”意图在于覆盖不排他的包含,例如包含了一系列步骤或单元的过程、方法、系统、产品或设备,没有限定于已列出的步骤或单元而是可选地还包括没有列出的步骤或单元,或可选地还包括对于这些过程、方法、产品或设备固有的其他步骤或单元。
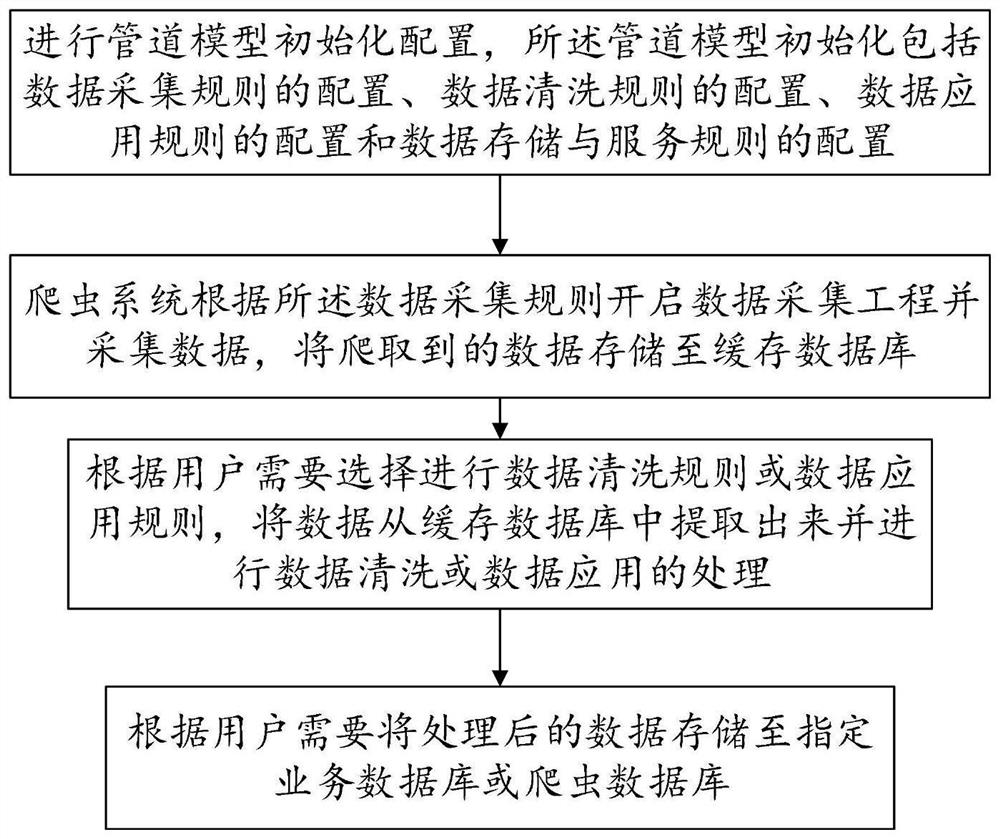
参照图1流程图所示,本发明一种基于数据管道模型的网络爬虫方法的实施例,包括以下步骤:
步骤1:进行管道模型初始化配置,所述管道模型初始化包括数据采集规则的配置、数据清洗规则的配置、数据应用规则的配置和数据存储与服务规则的配置。
步骤1-1:进行数据采集规则的配置。
步骤1-1-1:配置页面初始URL和遍历方式构建任务队列,爬虫根据初始URL按照遍历方式获取所有需要采集的页面URL并将这些URL构成任务队列,用于使爬虫系统从队列中逐个取出URL并进行数据采集。其中,遍历方式为广度遍历或深度遍历。
步骤1-1-2:配置数据解析规则,用于使爬虫系统根据使用者需求解析网页元素或从数据接口中提取所需字段。
步骤1-1-3:设置采集频率、并发数量、最大重试次数、代理IP池和User-Agent池,用于控制爬虫系统运行时的状态,在遵守Reboot协议的基础上控制数据采集的速度和持续采集时间。
步骤1-2:进行数据清洗规则的配置。通过系统接口规范将相应的清洗功能加入数据清洗规则,所述清洗功能包括格式校验、缺失值处理、数据一致化处理、异常值处理和编码统一。清洗功能可根据需求进行开发拓展,只需通过系统接口规范将相应的清洗功能加入数据清洗规则即可。清洗功能中的各个功能组件互相独立,不存在数据的前后依赖关系,相较于传统的固定清洗功能可以进行灵活的配置和管理。
步骤1-3:进行数据应用规则的配置。通过系统接口规范将相应的应用功能加入数据应用规则,所述应用功能包括图文分离、地名解析、情感倾向识别、音视频压缩、正文重编码、附件下载和图片压缩裁剪。应用功能可根据需求进行开发拓展,只需通过系统接口规范将相应的应用功能加入数据应用规则即可。应用功能中的各个功能组件互相独立,不存在数据的前后依赖关系,相较于传统的固定应用功能可以进行灵活的配置和管理。加入数据应用功能可以进一步减少业务系统与采集数据的对接工作,数据应用功能中包括在业务系统中常用的一些数据处理功能,包括图文分离、正文重编码、图片压缩,通过配置的方式可以选择开启这些功能。
步骤1-4:进行数据存储与服务规则的配置。指定数据存储结构和数据存储地址,将上游数据存储至指定业务数据库或爬虫数据库,进行数据缓存服务和数据检索服务的配置。配置的数据缓存服务和数据检索服务用户可以选择关闭。此步中还包括配置是否开启数据备份,配置是否使用数据接口的方式访问数据和配置是否直接存储至业务数据库。配置是否开启数据备份用于决定数据处理工程从缓存数据库提取数据后是否删除缓存数据。配置是否使用数据接口的方式访问数据,若开启配置系统将会对处理后的数据构建全文索引,并提供简单的查询、检索接口。配置是否直接存储至业务数据库,用于通过指定数据存储结构和业务数据库账号信息将处理后的数据直接存储至业务数据库。
步骤2:爬虫系统根据所述数据采集规则开启数据采集工程并采集数据,将爬取到的数据存储至缓存数据库。
步骤3:根据用户需要选择进行数据清洗或数据应用,将数据从缓存数据库中提取出来并进行数据清洗或数据应用的处理;若用户需要进行数据清洗则开启清洗功能,用户可选取清洗功能中的任意功能;若用户需要进行数据应用则开启应用功能,用户可选取应用功能中的任意功能;若用户需要进行数据清洗和数据应用则开启清洗功能和应用功能,用户可选取清洗功能和应用功能中的任意功能。将数据从缓存数据库中提取出来并进行数据清洗或数据应用的处理后,根据用户需求选择进行数据推送服务,将处理后的数据以消息形式推送,推送后的数据不再进行步骤4中的存储。本实施例中消息的推送形式为webhook形式。数据从缓存数据库中提取出来并进行数据清洗或数据应用的处理时,提取数据的频率与所述步骤2中爬虫系统采集数据时的频率保持一致,提取数据的频率也可以手动更改。此处通过将采集和处理工程分离的方式来兼顾爬虫效率。
步骤4:根据用户需要将处理后的数据存储至指定业务数据库或爬虫数据库。实现数据采集、清洗、应用到业务系统的管道生产。当处理后的数据存储至所述爬虫数据库时自动构建数据缓存服务和数据检索服务。
如图2整体架构图所示,本发明一种基于数据管道模型的网络爬虫系统的实施例,包括数据采集模块、数据处理模块、数据存储与服务模块和用户界面。
所述数据采集模块根据配置的数据采集规则生成爬虫采集工程并采集数据,采集到的网页或接口数据按照规则解析存入缓存数据库。数据采集模块中,用户指定需要采集的数据源、采集频率、页面遍历方式、页面/接口数据解析规则、代理IP池等采集规则。爬虫系统会在采集任务开始前根据初始网页URL,按照遍历规则生成需要采集的页面URL任务队列。从任务队列中逐个取出URL进行数据采集,默认使用URL作为任务标识,不会重复采集同一个URL。依据解析规则,从网页元素中或数据接口中,获取用户指定的结构化数据,将数据存储至缓存数据库。采集过程中的请求并发数、请求IP、请求agent、失败重试次数等参数,由用户手动配置。
所述数据处理模块中封装有数据清洗模块和数据应用模块,根据用户需要从缓存数据库中提取数据并执行清洗功能或应用功能的处理,用户通过图形界面可以开启相应配置。以指定频率从缓存数据库中提取采集到数据并执行数据清洗和加工的处理,数据处理完后存入爬虫源数据库或按照用户指定的表结构将处理后的数据直接存入指定的业务数据库;数据处理模块中,用户指定数据检测规则,即判断数据是否为无效值、数据格式是否一致等。指定数据预处理规则,例如为缺省值设置默认值、统一日期数据格式、标记错误数据(如数据取值不在合理范围内的数据)等。指定数据加工规则,对正文内容进行重编码、图片压缩、图片裁剪、地名分词等。系统将从缓存数据库中提取采集的数据,进行数据校验,对未通过校验的数据按照预设方式处理,不符合预设规则的不合数据将被标记。完成数据检查后,开始执行数据加工任务,完成数据加工后从清除缓存数据。整个数据加工过程与数据采集是相互分离,异步执行的,以此来兼顾爬虫采集效率。
所述数据存储与服务模块在数据处理完后,根据用户需要将处理后的数据存储至指定业务数据库或爬虫数据库,并对存入爬虫数据库的数据构建数据缓存服务和数据检索服务,支持用户以数据接口的方式访问采集数据。模块支持MySQL、PostgreSQL等主流数据库的数据操作。数据输出模块中,用户指定业务数据库名称、地址、用户信息、表结构,将处理完成后的数据,写入业务数据库。数据输出的时机由数据处理模块决定,数据处理模块按照预设的处理频率(假设为1次/小时),从缓存数据库中提取数据(本实施例中,默认每次提取1000条记录,该数值可手动指定),完成这批次数据的清洗加工后,将会触发一次数据存储。将处理后的数据存储至业务数据库,确认写入后清除对应的数据缓存。
所述用户界面通过调用底层接口服务给用户提供控制平台,通过用户界面对数据采集模块、数据处理模块和数据存储与服务模块进行配置和任务执行状态的查看。
管道模型(Pipeline)是一种通过串接不同的程序或者不同的组件组成一条直线的工作流以解决高内聚、低耦合问题的数据处理方式。管道模型下给定一个完整的输入,经过各个组件的先后协同处理,可以得到唯一的最终输出。相较于传统爬虫系统,本发明在保证爬虫系统通用性的前提下,在数据采集过程中引入了可配置的数据采集规则、数据清洗规则、数据应用规则和数据存储与服务规则,用户可以通过配置的方式对爬取的数据进行处理,使用爬虫系统提供的数据接口直接获取数据或配置存储规则将数据直接存入业务数据。通过这样的数据管道,用户可以将常用数据处理的工作纳入数据采集流程中,减少爬虫数据与业务系统的对接工作。
本发明的有益效果:本发明将数据采集规则的配置、数据清洗规则的配置、数据应用规则的配置和数据存储与服务规则等环节视为部分组件进行灵活配置,根据不同的用户需求实现相应的数据清洗、数据应用和数据存储与服务功能,将数据采集、数据清洗、数据应用、数据存储与服务不同部分组件结合在一起,形成直达业务系统的数据管道,实现采集数据到业务系统的管道化流转,降低了数据采集到数据应用的实际成本,弥补了现有爬虫系统在数据输出和数据应用上的不足。
以上所述实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的保护范围不限于此。本技术领域的技术人员在本发明基础上所作的等同替代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。
- 基于数据管道模型的网络爬虫方法及系统
- 基于网络爬虫和数据转移技术的数据采集系统及方法