一种基于语义图网络的医疗预测方法及系统
文献发布时间:2023-06-19 11:35:49
技术领域
本发明属于计算机技术领域,特别是涉及一种基于语义图网络的医疗预测方法及系统。
背景技术
慢性病是威胁人类生命的主要一类疾病,但由于大多数慢性病都是可预防、可治疗的,因此通过早期的干预能够有效的降低慢性病加重的概率,通过建立预测模型分析患者的现状进而预测患者未来的病情发展是预防保健以及减轻慢性病对个体负担的重要前提。
随着电子病历的广泛使用,基于语义分析的疾病预测模型取得了一定发展。目前基于电子病历构建预测模型的方法主要分为两类:(1) 基于假设驱动的方法,其原理是从临床专家根据观察和临床经验提出的假设开始,再从医疗数据中找出事实,用演绎推理来验证假设的真实性。并且预测模型是由一组验证的假设推导出来的。一般来说,假设驱动的方法不能充分利用医疗数据中包含的有价值的信息。(2)基于数据驱动的方法。其原理是使用充分标记的医疗数据集训练机器学习模型,实现疾病预测。但传统的机器学习模型需要领域专家以特殊的方式指定临床特征,而最终的预测模型的成功很大程度上依赖于手工设计的特征选择的复杂监督,例如,Senthilkmar Mohan等人在2019 年发表的EffectiveHeart Disease Prediction Using Hybrid Machine Learning Techniques提出了一种线性混合随机森林模型用于心脏病预测。深度学习能够减少传统机器学习特征选择的复杂性从数据中自动的学到更深层次的特征,如今已经成为了预测模型的主要方法。
基于深度学习的疾病预测方法通常采用词或概念向量做为医疗文本的主要特征表达,例如,由Guangkai Li,Songmao Zhang等人发表在SmartCom 2018的AugmentingEmbedding with Domain Knowledge for Oral Disease Diagnosis Prediction文章,从领域本体中学习症状与诊断相关的概念并采用神经网络学习电子病历中的概念特征,构建口腔疾病预测模型。然而,在电子病历中,许多实体或词之间是通过语义关系来表达疾病相关的信息,例如“患者3 年前运动后出现胸闷、喘息,在我院诊断为慢性阻塞性肺疾病”,如果不考虑属性-值“COPD-3年前”很难区分COPD是既往史还是现病史。又如“患者应用舒利迭改善喘息症状”,如果只考虑实体特征而不考虑实体关系无法挖掘句子中表达的真实含义,此外,大多数临床医疗决策是基于检查-检查结果决定的。
因此,寻找一种基于语义图网络的医疗预测方法及系统成为研究人员关注的问题。
发明内容
为了解决上述技术问题,本发明提供一种基于语义图网络的医疗预测方法及系统,用于疾病分型。基于领域识别电子病历中的实体,并采用双向门控循环单元学习文本的序列特征。其次,为了细粒度的提取电子病历中的语义关系,本发明定义两种类型的子图,基于知识的图表示和基于文本的图表示,并采用图卷积神经网络(Graph ConvolutionNetwork,GCN)和图注意力网络(Graph Attention Network,GAT)提取语义关系特征,其中基于文本的图表示允许提取实体或词与其自身的关系,用于表示实体或词特征。针对属性-值特征,本发明在提取电子病历中的数值或类别型特征之后,利用双向门控循环单元(bi-directional gate recurrent unit,Bi-GRU)提取他们对应的实体,构建属性-值得图表示。最后,将语义关系和属性- 值进行融合训练疾病的等级预测模型。
为实现上述目的,本发明提出一种基于语义图网络的医疗预测方法,具体包括如下步骤:
S1、对医疗文本数据进行预处理;
S2、将预处理后的医疗文本数据进行特征提取;
S3、将提取的特征进行多粒度特征融合,得到最终的文档特征;
S4、将所述最终的文档特征进行慢性疾病预测。
优选地,所述步骤S1具体为:
S11、根据需要预测的目标类别,将所述医疗文本数据进行人工标注,并载入领域本体;
S12、根据标点符号、数字和空格符,将所述医疗文本数据切分成汉字字符串,并去除停用词。
优选地,所述步骤S2中的特征提取包括:实体特征提取、词特征提取、语义关系特征提取和属性-值特征提取。
优选地,所述实体特征提取具体为:
首先,将预处理后的医疗文本数据映射到领域本体,并通过最大匹配法将所述医疗文本数据切分成语义集;然后从所述语义集中找到与之相匹配的实体集和与所述实体集相对应的实体类型集,得到实体自身特征和实体类型特征;最后将所述实体自身特征和所述实体类型特征相结合来提取实体特征。
优选地,所述词特征提取和属性-值特征提取具体为:
采用Bi-GRU来找出医疗文本数据中的词序列之间的依赖关系,并将词之间的序列信息放入图注意力网络中来识别语义关系,并提取属性-值特征。
优选地,所述语义关系特征提取具体为:
采用图卷积网络和图注意力网络来构建语义关系图,并定义基于知识的图表示和基于文本的图表示的两种类型子图;所述基于知识的图表示是利用所述领域本体中标记的实体之间的关系,并采用图卷积网络和图注意力网络来提取电子病历文本中实体关系;对于不能从领域本体中找到对应关系的实体或词,所述基于文本的图表示根据 Bi-GRU提取的上下文中词之间的依赖关系,直接采用图卷积网络和图注意力网络提取词或实体之间的关系。
优选地,所述步骤S3具体为:
将提取出来的实体特征、词特征、语义关系特征和属性-值特征进行特征融合,得到最终的文档特征。
优选地,所述步骤S4具体为:
将所述文档特征输入到softmax层进行医疗预测,并基于真实标签和预测标签的交叉熵计算损失函数,得到疾病类型的分类结果和疾病等级的预测结果。
一种基于语义图网络的医疗预测系统,包括:数据预处理模块、特征提取模块、多粒度特征融合模块、疾病类型分类器模块;
所述数据预处理模块的输出端与所述特征提取模块的输入端相连;所述特征提取模块的输出端与所述多粒度特征融合模块的输入端相连;所述多粒度特征融合模块的输出端与所述疾病类型分类器模块输入端相连;
所述数据预处理模块用于将医疗文本数据根据要预测的目标类别进行人工标注,并载入领域本体;还用于将医疗文本数据根据标点符号、数字和空格符进行汉字字符串切分,并去除停用词;
所述特征提取模块用于提取医疗文本数据中的实体特征、词特征、语义关系特征和属性-值特征;
所述多粒度特征融合模块用于将提取出来的实体特征、词特征、语义关系特征和属性-值特征进行融合作为softmax层的输入来进行疾病预测;
所述疾病类型分类器模块用于产生疾病类型的分类结果。
优选地,所述特征提取模块又包括四个子模块,分别为:实体特征提取模块、词特征提取模块、语义关系特征提取模块和属性-值特征提取模块;
所述实体特征提取模块与所述词特征提取模块相连,所述词特征提取模块与所述属性-值特征提取模块相连;所述属性-值特征提取模块与所述语义关系特征提取模块相连;
所述实体特征提取模块用于将处理后的医疗文本映射到医疗本体中,分别提取概念自身特征和概念类型特征,并将概念自身特征和概念类型特征相结合来提取概念特征;
所述词特征提取模块用于将不能从医疗本体中找到与之相匹配的概念进行上下文中词序列特征的BiGRU学习;
所述语义关系特征提取模块用于在领域本体中找到对应关系类别的实体对和在领域本体不能找到对应关系类别的实体对;
所述属性-值特征提取模块用于提取疾病-时间和检测-检查结果之间的关系。
与现有技术相比,本发明的有益效果在于:
传统方法中,大多考虑词、字或实体向量不能充分理解医疗文本中表达的信息,许多疾病相关的信息隐藏在实体或词之间的语义关系中。而本发明不仅能够学习实体或词特征,也能够挖掘更深层次的语义关系和属性-值特征;然后,将不同粒度的特征进行融合来提升模型的语义推理能力。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明方法流程示意图;
图2为本发明系统模块示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
实施例1
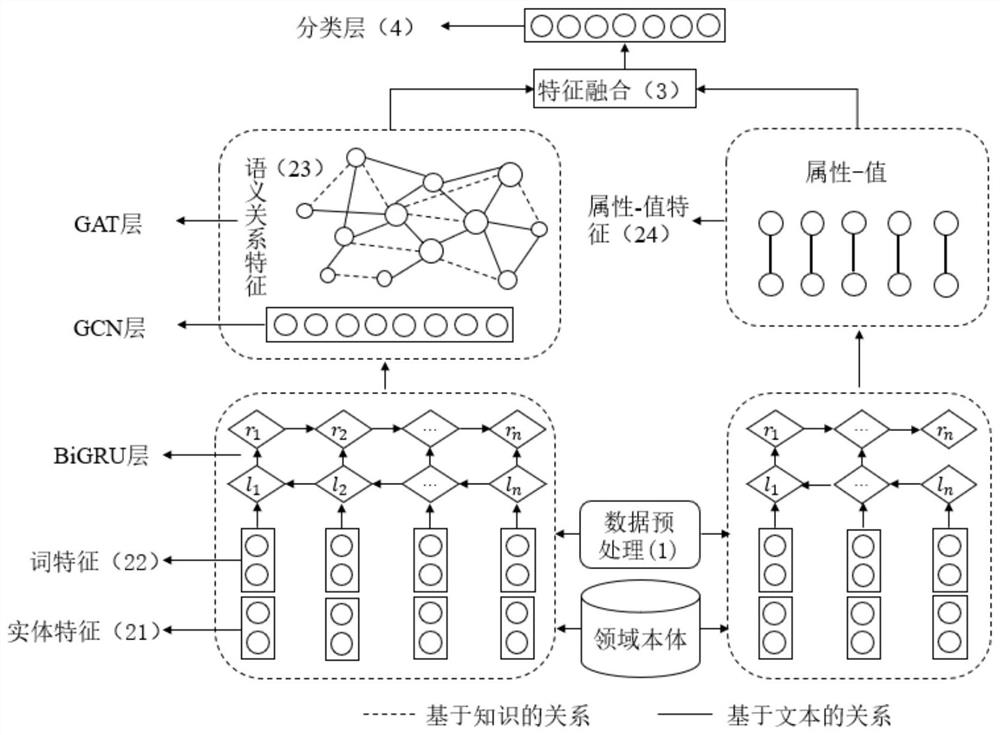
参照图1所示,本发明提出一种基于语义图网络的医疗预测方法,具体包括如下步骤:
S1、将医疗文本数据根据要预测的目标类别进行人工标注,其次载入领域本体;根据标点符号、数字和空格符将待处理的文本切分成汉字字符串,并去除停用词;
S2、将预处理后的医疗文本数据进行实体特征提取(21)、词特征提取(22)、语义关系特征提取(23)、属性-值特征提取(24)。
实体特征提取(21):实体特征包含实体自身特征和实体的类型特征。首先将预处理后的文本映射到领域本体,通过最大匹配法将文本数据切分为语义集{Y
词特征提取(22):采用Bi-GRU来捕捉词序列之间的依赖关系,提取词特征。如有词序列w
其中,θ表示GRU模型中的参数,将前向
语义关系特征提取(23):在这一步骤,本发明将采用图卷积网络和图注意力网络来构建语义关系图并定义两种类型的子图:(1)基于知识的图表示,该子图利用领域本体中标记的实体之间的关系,并采用图卷积网络和图注意力网络来提取电子病历文本中实体关系的图表示。(2)基于文本的图表示,对于不能从领域本体中找到对应关系的实体或词,根据Bi-GRU提取的上下文中词之间的依赖关系,直接采用图卷积网络和图注意力网络提取词或实体之间的关系。
(1)基于知识的图表示:首先,基于医疗本体识别出电子病历中包含的实体和实体之间的关系作为图的节点和边,分别记作V
p
其中,c
接下来定义邻接矩阵A
在得到邻接矩阵之后,本发明首先采用图卷积网络学习节点表示,如公式6-2所示:
其中,
在图卷积层之后,本发明结合领域本体中的实体关系,采用图注意力层提取基于知识的节点表示,对于给定节点,图注意力网络首先学习具有相同关系相邻节点的重要性,然后根据权重得分对其进行融合。如有节点特征h={h
其中,
其中,
(2)基于文本的图表示
对于不能从本体中找到对应关系类别的实体或词,根据Bi-GRU 提取词序列之间的依赖关系,本发明采用图卷积模型提取基于文本的图表示,G
采用图卷积网络学习节点表示如公式(12)所示:
其中,
接下来采用公式(14)来正则化相邻节点的权重得分,最后采用公式(15)计算实体或词v
其中,||表示向量拼接操作,LeakyRelu表示非线性激活函数,N
属性-值特征提取(24):属性-值可以分为两种类型:疾病-时间和检查-检查结果。其中疾病-时间的值的类型只包括数值型,检查- 检查结果的值的类型包含数值型和类别型。每个属性-值包含两个元素,属性及其对应的值。不同于实体关系中尾实体通常是相对稳定的,不会因为患者的不同而改变,而在属性-值中,值会随着患者的不同而改变,例如每个患者的血压值是不同的。对于数值型,每个值可以用不同的单位表示,例如“10年”和“122/70mmHg”。对于这种类型,本发明首先提取EMR的实数值和其相应的单位符号,包括比率符号,例如“47.6%”和字符符号,例如“5年”,如有实数值D
根据医学专家的指导,在训练中对每个检查结果的数值设置量化的阈值,用于疾病推断。检查结果的数值共分为4个等级:低、正常、高和非常高。如有检查实体v
在属性-值特征的抽取过程中,本发明首先识别句子中包含的数值及类别值,然后通过Bi-GRU学习值的上下文信息,并提取与值距离最近的实体为其对应的属性特征。
S3、通过结合基于知识的图表示、基于文本的图表示和基于属性 -值的图表示来获取最后的文档特征d
其中G
S4、将文档特征d作为softmax层的输入对文档进行慢阻肺病的等级预测,并基于真实标签和预测标签的交叉熵计算损失函数,如公式(19)和公式(20)所示。
其中,W
参照图2所示,本发明提出一种基于语义图网络的医疗预测系统,包括:数据预处理模块、特征提取模块、多粒度特征融合模块、疾病类型分类器模块;
数据预处理模块的输出端与特征提取模块的输入端相连;特征提取模块的输出端与多粒度特征融合模块的输入端相连;多粒度特征融合模块的输出端与疾病类型分类器模块输入端相连;
数据预处理模块:将医疗文本数据根据要预测的目标类别进行人工标注,其次载入领域本体;根据标点符号、数字和空格符将待处理的文本切分成汉字字符串,并去除停用词;
特征提取模块:具体分为四个子模块:实体特征提取、词特征提取、语义关系特征提取、属性-值特征提取;
(1)实体特征提取模块:通过将与处理后的医疗文本映射到医疗本体中,分别提取概念自身特征和概念类型特征,并将概念自身特征和概念类型特征相结合来提取概念特征。
(2)词特征提取模块:如果不能从医疗本体中找到与之相匹配的概念就采用BiGRU学习上下文中词的序列特征。
(3)语义关系特征提取模块:语义关系包含三类:实体-实体之间的关系,实体-词之间的关系,词-词之间的关系。其中实体-实体之间的关系可以分为两种,基于知识的图表示(指在领域本体中可以找到对应关系类别的实体对)和基于文本的图表示(指在领域本体不能找到对应关系类别的实体对),词指非医疗术语但是包含的重要的语义信息的词语(例如患者基本信息),在基于文本的关系中,本方法允许提取实体或词与其自身的关系,实体或词的图表示。
(4)属性-值特征提取模块:属性-值特征包含两类:疾病-时间和检测-检查结果。属性是指步骤(21)实体特征,值可以分为数值型和类别型两类。疾病-时间中的值只包含数值类型,检测-检查结果中的值包含数值类型与类别类型,根据每个属性和其对应的值构建属性-值的图表示。
多粒度特征融合模块:将提取出来的实体特征、词特征、语义关系特征和属性-值特征进行融合作为softmax层的输入来进行疾病预测;为了防止过拟合图卷积神经网络的卷积层采用dropout操作,并采用zero padding来保持句子的有效性。
疾病类型分类器模块:将模型训练的结果放入softmax分类层中,通过softmax分类器来产生最后疾病类型的分类结果。
以上所述的实施例仅是对本发明的优选方式进行描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案做出的各种变形和改进,均应落入本发明权利要求书确定的保护范围内。
- 一种基于语义图网络的医疗预测方法及系统
- 一种基于语义感知图神经网络的小样本图像分类方法及系统