一种基于深度学习的电磁调制信号去噪方法及系统
文献发布时间:2023-06-19 11:49:09
技术领域
本发明涉及电磁信号的无监督学习领域,特别是涉及一种基于深度学习的电磁调制信号去噪方法及系统。
背景技术
电磁信号指的是在自由空间中传播的电磁波,例如无线电信号。在信号处理中,对于任何信号类型,噪声的存在都是一个常见的问题。神经网络是一种基于学习的信号去噪的方法,不需要对信号和噪声的精确建模,也不需要最优参数调整。这种方法在基于学习的图像领域特别受欢迎。同样地,在音频和语音处理方面,深度神经网络也取得了较好的成果。相反,基于学习的方法对低维信号(如调制信号)的影响相当有限。对于低维信号,之前的去噪工作主要使用滤波、小波变换和经验模态分解等非学习方法。线性去噪方法依赖于滤波,但是当信号和噪声共享相同的频谱时,它们就显示出了局限性。在小波变换中,其性能取决于对预定义基函数的选择,这些基函数可能不能反映信号的性质。经验模态分解是一种数据驱动的方法,但是难以将信号分解成独特的频率分量。
已有论文:在2020年EUSIPCO(2020年第28届欧洲信号处理会议)上接受的论文《Adversarial Signal Denoising with Encoder-Decoder Networks》,提出了一种编码器-解码器结构来去除信号的噪声,将去噪任务视为干净信号和有噪信号之间的分布对齐,信号由一系列测量值表示。其目标是给定的两个信号通过编码器对齐干净和噪声信号潜在表示。但是该方法没有对调制信号进行研究,并且未考虑将不基于学习的滤波去噪方法和基于学习的方法结合,从而提升信号去噪效果。
已有专利:申请号为CN201710614277.7的专利所公开的技术方案,基于生成对抗网络的物体检测方法及装置,该方法将输入的原始图像进行尺寸变换得到第一图像,并对所述第一图像进行滤波去噪处理得到第二图像;将所述第二图像输入到生成对抗网络中。此方法针对的是图像领域物体识别,利用图像上的滤波去噪和生成对抗网络相结合提高物体识别率,未涉及信号领域,并且所用的具体网络结构和损失函数都和本发明不同。
发明内容
本发明要克服现有技术的上述缺点,提供一种基于深度学习的电磁调制信号去噪方法及系统,能对电磁调制信号进行去噪,提高信号的信噪比。
为实现上述目的,本发明提供了如下方案:
本发明提供一种基于深度学习的电磁调制信号去噪方法及系统,其方法包括以下步骤:
S1,将公开数据集中的18dB的9种调制类型数据作为目标信号,再向目标信号中加入定量的高斯噪声,得到对应的12dB的噪声信号;
S2,将S1中噪声信号输入低通滤波器中,输出为滤波后信号,将S1中的目标信号和新得到的滤波后信号,对应组成数据对,然后利用信号增强方法将数据量扩大十倍;
S3,构建生成对抗网络模型,并分别定义生成器和判别器的损失函数,将S2中数据对作为判别器的输入,滤波后信号作为生成器的输入,通过对抗训练,最小化生成信号和目标信号之间的差异,从而获得实现信号去噪的生成器;
S4,提取训练好的生成器,输入滤波后信号,输出去噪信号。
进一步地,所述S1具体包括:
S1.1,采用公开数据集RML2016.10a,提取其中信噪比为18dB,调制类型为8PSK、BPSK、CPFSK、GFSK、PAM4、QAM16、QAM64、QPSK、WBFM的数据作为目标信号,共8910个数据;
S1.2,在提取的目标信号数据中添加定量的高斯噪声,得到对应的12dB的噪声信号数据。
进一步地,所述S2具体包括:
S2.1,设置低通滤波器为8阶,参数为0.2,低通滤波器的输入为S1.2中获得的噪声信号,输出即为滤波后信号;
S2.2,将滤波后信号逐个加载,然后分别通过旋转90°、旋转180°、旋转270°、上下翻转、左右翻转、添加微弱的随机噪声参数为(0,0.0005)、添加微弱的随机噪声参数为(0,0.0010)、添加微弱的随机噪声参数为(0,0.0015)、添加微弱的随机噪声参数为(0,0.0020)得到新的信号,使得数据量扩大十倍;
S2.3,利用复制功能将目标信号数据量扩大十倍并拼接,同时拼接S2.2中所提到的所有信号,利用枚举函数,将目标信号和滤波后的信号一一组成数据对,数据结构为(None,4,128)。
进一步地,所述S3具体包括:
S3.1,定义生成器模型;
S3.2,定义生成器模型的损失函数,生成器损失函数包括判别器输出损失、最小绝对值偏差、连续性差值,连续性差值(Gtv_loss)是生成器生成的I路信号(Q路信号)的前127个数据减去后127个数据的差值的绝对值的p次方的均值,体现了生成信号的点的连续性程度,数值越低,连续性越好;
生成器的损失函数(G_loss)结合三种损失函数为:
S3.3,定义判别器模型;
S3.4,定义判别器模型的损失函数;
S3.5,定义模型优化器,采用Adam优化器和衰减学习率进行模型优化;
S3.6,进行对抗训练,判别器第一次进行判别时,将相应的数据对输入到判别器中,期望判别器判别目标信号和滤波后信号的数据对为真,判别生成器生成的去噪信号和滤波后信号的数据对为假;再将滤波后信号数据输入到生成器,生成新的去噪信号,进行第二次判别器判别,新的去噪信号和滤波后信号的数据对输入到判别器期望判别为真;如此反复,使得去噪信号与目标信号的数据分布越来越像;最终,判别器对于数据对的真假判别概率都相同时,训练完成。
进一步地,所述生成器损失具体包括:判别器输出损失、最小绝对值偏差、连续性差值。
进一步地,所述S4具体包括:
S4.1,取出S3.1定义的生成器网络模型,将训练模块保存的生成器模型参数载入生成器网络模型中,得到完整的可用于去噪的生成器模型;
S4.2,将噪声信号或滤波后信号输入生成器模型中,输出去噪信号。
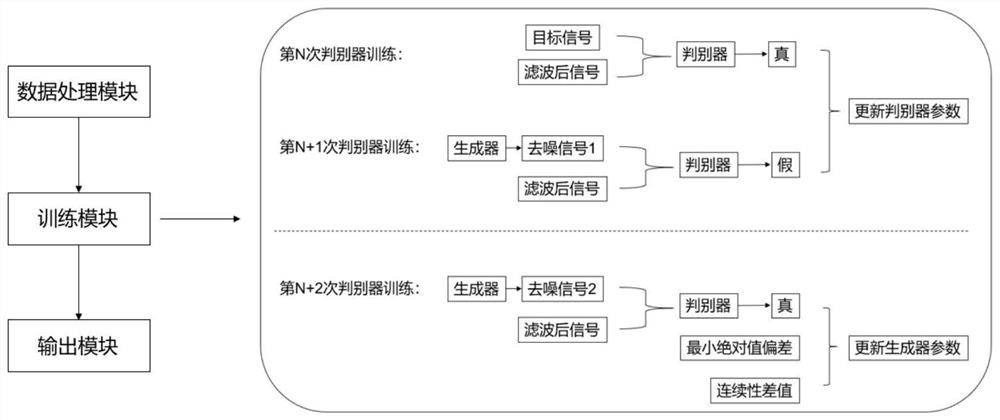
一种基于深度学习的电磁调制信号去噪的系统,包括:数据处理模块、训练模块、输出模块;
所述数据处理模块,将公开数据集中的18dB的9种调制类型数据作为目标信号,再向目标信号中加入定量的高斯噪声,得到对应的12dB的噪声信号,将噪声信号输入低通滤波器中,输出为滤波后信号,将目标信号和新得到的滤波后信号,对应组成数据对,然后利用信号增强方法将数据量扩大十倍;
所述训练模块,将所述数据处理模块中数据输入训练模块中,对生成对抗网络模型进行训练,多次迭代后直到所述生成对抗网络模型训练稳定,保存模型;
所述输出模块,载入所述训练模块保存的生成对抗网络模型中的生成器模型,将需测试的噪声信号或者滤波后信号输入所述训练模块得到的生成器模型,输出去噪信号;
所述数据处理模块、所述训练模块、所述输出模块依次链接。
本发明的技术构思:一种融合滤波去噪和生成对抗网络的深度学习信号去噪方法,首先本发明整个模型框架的训练是端到端的,在生成数据的过程中使用了信号增强的方法扩大了数据集,增加了模型优化的可靠性。其次,通过先用低通滤波器对噪声信号进行滤波,为后续深度学习去噪奠定了基础。再者,利用额外增加的连续性损失函数,提高了生成器生成的信号的联系性,使得生成对抗网络在学习信号特征时,能够更好地保留信号原有的联系特征。另外,本发明可以设置不同的训练参数,例如不同的学习率和不同的权重衰减,实验结果证实了本方法的可行性和有效性。
本发明的有益效果:
1.本方法不需要使用信号数据的各种先验知识,在信号去噪上具有较好的普适性。
2.先使用滤波器初步去噪,为后续深度去噪奠定了基础,同时利用信号增强方法扩大数据集,使得生成对抗网络模型能够得到充分训练;生成对抗网络使用自编码器结构,增加了模型学习能力。
3.生成器损失函数由三部分组成:滤波后信号和目标信号的绝对差值、生成信号的连续性损失值、判别器判别相似度值,分别对应去噪过程中数值上的优化、生成信号的数据连续性的优化以及生成信号整体上是否符合目标信号所具有的特征。
附图说明
图1为实现本发明方法及系统的流程图;
图2为数据处理流程图;
图3为生成对抗网络模型结构图。
具体实施方式
下面结合说明书附图对本发明的具体实施方式作进一步详细描述。
参照图1至图3,一种基于深度学习的电磁调制信号去噪的方法及系统,包括以下步骤:
S1,将公开数据集中的18dB的9种调制类型数据作为目标信号,再向目标信号中加入定量的高斯噪声,得到对应的12dB的噪声信号,具体步骤如下:
S1.1,采用公开数据集RML2016.10a,提取其中信噪比为18dB,调制类型为8PSK、BPSK、CPFSK、GFSK、PAM4、QAM16、QAM64、QPSK、WBFM的数据作为目标信号,共8910个数据。
S1.2,在提取的目标信号数据中添加定量的高斯噪声,得到对应的12dB的噪声信号数据。输入目标信号数据和预期添加高斯噪声后得到的低信噪比大小(SNR),通过以下公式计算即可获得12dB的低信噪比的噪声信号数据。
N
A
S2,将S1中噪声信号输入低通滤波器中,输出为滤波后信号,将S1中的目标信号和新得到的滤波后信号,对应组成数据对,然后利用信号增强方法将数据量扩大十倍,具体步骤如下:
S2.1,设置低通滤波器为8阶,参数为0.2,低通滤波器的输入为S1.2中获得的噪声信号,输出即为滤波后信号。
S2.2,将滤波后信号逐个加载,然后分别通过旋转90°、旋转180°、旋转270°、上下翻转、左右翻转、添加微弱的随机噪声参数为(0,0.0005)、添加微弱的随机噪声参数为(0,0.0010)、添加微弱的随机噪声参数为(0,0.0015)、添加微弱的随机噪声参数为(0,0.0020)得到新的信号,使得数据量扩大十倍。
S2.3,利用复制功能将目标信号数据量扩大十倍并拼接,同时拼接S2.2中所提到的所有信号,利用枚举函数,将目标信号和滤波后的信号一一组成数据对,数据结构为(None,4,128)。
S3,构建生成对抗网络模型,并分别定义生成器和判别器的损失函数,将S2中数据对作为判别器的输入,滤波后信号作为生成器的输入,通过对抗训练,最小化生成信号和目标信号之间的差异,从而获得实现信号去噪的生成器,具体步骤如下:
S3.1,定义生成器模型。编码器使用了6层一维卷积神经网络,并在每层之后使用带参数的激活函数。最终将输入数据结构由(None,2,128)变为(None,128,2)。解码器使用了6层一维逆卷积神经网络,并在每层之后使用带参数的激活函数;每层输入都为随机噪声(或上一层逆卷积输出数据)和前半部分网络对应层输出数据的结合体。最终生成器输出的数据结构仍然为(None,2,128)。
S3.2,定义生成器模型的损失函数。生成器损失函数包括判别器输出损失、最小绝对值偏差、连续性差值。判别器输出损失即判别器输出值(f(x
最小绝对值偏差是把生成器生成的去噪信号数据(G(x
连续性差值(Gtv_loss)是将生成器生成的I路信号(Q路信号)的前127个数据减去后127个数据的差值的绝对值的p次方的均值,体现了生成信号的点的连续性程度,数值越低,连续性越好。
生成器的损失函数(G_loss)结合采用以上三种损失函数为:
S3.3,定义判别器模型,采用了6层一维卷积神经网络,并在每层后使用了归一化和激活函数,且在第3层卷积层后加入了Dropout层。后又接有1层一维卷积神经网络、1个线性层、一个sigmoid层。最终将数据结构由输入的(None,4,128)变为输出的标量。
S3.4,定义判别器模型的损失函数。判别器主要采用最小平方误差,它是把判别器输出值(f(x
输入为目标信号和噪声信号的数据对时,目标值1为真,损失函数为:
输入为去噪信号和噪声信号的数据对时,目标值0为假,损失函数为:
S3.5,定义模型优化器,采用Adam优化器和衰减学习率进行模型优化。
S3.6,进行对抗训练,判别器第一次进行判别时,将相应的数据对输入到判别器中,期望判别器判别目标信号和滤波后信号的数据对为真,判别生成器生成的去噪信号和滤波后信号的数据对为假。再将滤波后信号数据输入到生成器,生成新的去噪信号,进行第二次判别器判别,新的去噪信号和滤波后信号的数据对输入到判别器期望判别为真。如此反复,使得去噪信号与目标信号的数据分布越来越像。最终,判别器对于数据对的真假判别概率都相同时,训练完成。
S4,提取训练好的生成器,输入滤波后信号或者噪声信号,输出去噪信号,具体步骤如下:
S4.1,取出S3.1定义的生成器网络模型,将训练模块保存的生成器模型参数载入生成器网络模型中,得到完整的可用于去噪的生成器模型;
S4.2,将噪声信号或滤波后信号输入生成器模型中,输出去噪信号。
一种基于深度学习的电磁调制信号去噪的系统,包括:数据处理模块、训练模块、输出模块;
所述数据处理模块,将公开数据集中的18dB的9种调制类型数据作为目标信号,再向目标信号中加入定量的高斯噪声,得到对应的12dB的噪声信号,将噪声信号输入低通滤波器中,输出为滤波后信号,将目标信号和新得到的滤波后信号,对应组成数据对,然后利用信号增强方法将数据量扩大十倍;具体包括:
S1.1,采用公开数据集RML2016.10a,提取其中信噪比为18dB,调制类型为8PSK、BPSK、CPFSK、GFSK、PAM4、QAM16、QAM64、QPSK、WBFM的数据作为目标信号,共8910个数据;
S1.2,在提取的目标信号数据中添加定量的高斯噪声,得到对应的12dB的噪声信号数据;输入目标信号数据和预期添加高斯噪声后得到的低信噪比大小(SNR),通过以下公式计算即可获得12dB的低信噪比的噪声信号数据;
N
A
S2.1,设置低通滤波器为8阶,参数为0.2,低通滤波器的输入为S1.2中获得的噪声信号,输出即为滤波后信号;
S2.2,将滤波后信号逐个加载,然后分别通过旋转90°、旋转180°、旋转270°、上下翻转、左右翻转、添加微弱的随机噪声参数为(0,0.0005)、添加微弱的随机噪声参数为(0,0.0010)、添加微弱的随机噪声参数为(0,0.0015)、添加微弱的随机噪声参数为(0,0.0020)得到新的信号,使得数据量扩大十倍;
S2.3,利用复制功能将目标信号数据量扩大十倍并拼接,同时拼接S2.2中所提到的所有信号,利用枚举函数,将目标信号和滤波后的信号一一组成数据对,数据结构为(None,4,128)。
所述训练模块,将所述数据处理模块中数据输入训练模块中,对生成对抗网络模型进行训练,多次迭代后直到所述生成对抗网络模型训练稳定,保存模型;具体包括:
S3.1,定义生成器模型;编码器使用了6层一维卷积神经网络,并在每层之后使用带参数的激活函数。最终将输入数据结构由(None,2,128)变为(None,128,2)。解码器使用了6层一维逆卷积神经网络,并在每层之后使用带参数的激活函数;每层输入都为随机噪声(或上一层逆卷积输出数据)和前半部分网络对应层输出数据的结合体。最终生成器输出的数据结构仍然为(None,2,128);
S3.2,定义生成器模型的损失函数,生成器损失函数包括判别器输出损失、最小绝对值偏差、连续性差值,连续性差值(Gtv_loss)是生成器生成的I路信号(Q路信号)的前127个数据减去后127个数据的差值的绝对值的p次方的均值,体现了生成信号的点的连续性程度,数值越低,连续性越好;
生成器的损失函数(G_loss)结合三种损失函数为:
S3.3,定义判别器模型;采用了6层一维卷积神经网络,并在每层后使用了归一化和激活函数,且在第3层卷积层后加入了Dropout层;后又接有1层一维卷积神经网络、1个线性层、一个sigmoid层。最终将数据结构由输入的(None,4,128)变为输出的标量;
S3.4,定义判别器模型的损失函数;判别器主要采用最小平方误差,把判别器输出值(f(x
输入为目标信号和噪声信号的数据对时,目标值1为真,损失函数为:
输入为去噪信号和噪声信号的数据对时,目标值0为假,损失函数为:
S3.5,定义模型优化器,采用Adam优化器和衰减学习率进行模型优化;
S3.6,进行对抗训练,判别器第一次进行判别时,将相应的数据对输入到判别器中,期望判别器判别目标信号和滤波后信号的数据对为真,判别生成器生成的去噪信号和滤波后信号的数据对为假;再将滤波后信号数据输入到生成器,生成新的去噪信号,进行第二次判别器判别,新的去噪信号和滤波后信号的数据对输入到判别器期望判别为真;如此反复,使得去噪信号与目标信号的数据分布越来越像;最终,判别器对于数据对的真假判别概率都相同时,训练完成。
所述输出模块,载入所述训练模块保存的生成对抗网络模型中的生成器模型参数,将需测试的噪声信号或者滤波后信号输入所述训练模块得到的生成器模型,输出去噪信号;具体包括:
S4.1,取出S3.1定义的生成器网络模型,将训练模块保存的生成器模型参数载入生成器网络模型中,得到完整的可用于去噪的生成器模型;
S4.2,将噪声信号或者滤波后信号输入生成器模型中,输出去噪信号。
所述数据处理模块、所述训练模块、所述输出模块依次链接。
本说明书实施例所述的内容仅仅是对发明构思的实现形式的列举,本发明的保护范围不应当被视为仅限于实施例所陈述的具体形式,本发明的保护范围也及于本领域技术人员根据本发明构思所能够想到的等同技术手段。
- 一种基于深度学习的电磁调制信号去噪方法及系统
- 一种基于双树四元小波与深度学习的图像去噪方法及系统