一种通顺模型训练方法及辅助语音识别方法
文献发布时间:2023-06-19 11:49:09
技术领域
本发明属于自然语言处理领域,尤其涉及对话系统中辅助语音识别的通顺模型方法及辅助语音识别方法。
背景技术
N-gram是自然语言处理领域中的一个较为重要的语言模型,应用于判断句子是否合理,句子矫正,模糊查询等。该模型通常与预设的阈值做比对来判断一个句子是否合理。评估语音信息的得分,若该得分小于或等于预设的阈值得分,则判定句子是不合理的。若该得分大于预设的阈值得分,则判定句子是合理的并且句子通顺。
人工智能分为三大学派:行为主义,符号主义,连接主义。其中连接主义认为人工智能源于仿生学,特别是对人脑模型的研究,研究的主要代表为神经网络模型。学习是神经网络一种最重要也最令人注目的特点。在神经网络的发展进程中,学习算法的研究有着十分重要的地位。目前,人们所提出的神经网络模型都是和学习算法相应的。
中国专利CN202010600771.X公开了一种文本通顺度确定方法、装置、设备及介质,对目标文本进行划分,得到至少一个文本片段,对该至少一个文本片段中的每个文本片段进行划分,得到该每个文本片段对应的多个分词;通过获取目标文本中的每个文本片段的通顺度,以及获取目标文本中的每个分词的通顺度,并基于目标文本中的每个文本片段的通顺度和目标文本中的每个分词的通顺度确定目标文本的通顺度,即从不同维度对文本的通顺度进行判断,因此可以提高判断文本通顺度的准确性。该方法主要采用第一通顺度和第二通顺度结合的方法来判断语言是否通顺,但方法过于复杂,训练时间长,难以满足较大数据量的处理需求。
约翰·霍普金斯大学、波兰波兹南工业大学、弗罗茨瓦夫科技大学以及初创公司Avaya的研究人员研究表明,某些语音识别系统错误率较高,如果直接使用这些语音识别系统会严重影响自然语音处理的下游任务。
发明内容
针对上述技术问题,本发明公开了一种辅助语音识别的通顺模型方法,将语音识别识别合理的通顺语句顺利进入到自然语言处理的下游任务,若语音识别出不规则和不合理的语句时,对此进行过滤。
为达到上述目的,本发明采用的技术方案为:一种通顺模型训练方法,详细步骤如下:
步骤1,生成字数为2和3的统计词频的字典:使用预先准备的通顺数据生成统计词频个数为2以及词频个数为3的字典;通顺数据集是由通顺语句组成的数据库,例如百度百科常识知识库。
步骤2,非通顺数据集预处理:通顺数据集中的句子通过分词生成基于词的列表;
步骤3,非通顺数据集生成:将词的列表打乱,生成非通顺数据集;
步骤4,数据集向量化:使用3-gram技术,使用字数为2和3的统计词频的字典,将非通顺和通顺数据集向量化,同时分别给通顺数据集和非通顺数据集打上0,1标签;
步骤5,模型准备:搭建textcnn神经网络模型;
步骤6,通顺模型训练:将非通顺数据、通顺数据的向量,求其向量的平均值,标准差,方差,最大值,最小值,重新生成维度为5的向量,保证维度的统一,然后输入到textcnn模型中进行训练,获得通顺模型。
优选的,步骤1后进一步包括如下步骤:使用同义词替换、回译的方式对通顺数据集进行数据集增广。
进一步的,步骤3词的列表打乱方法为:将词的列表通过交换,删除,同义词插入的方式进行打乱,生成非通顺数据集。
本发明还公开一种使用上述通顺模型辅助语音识别的方法。包括以下步骤:
步骤11,获取语音信息,将语音信息转成文本;
步骤12,使用通顺模型判断语言是否通顺:文本输入到通顺模型中,判断文本是否通顺;如果文本通顺,则进入到下游的自然语言处理阶段;如果文本不通顺,则过滤文本。
作为优选的,步骤11后还包括如下步骤111:当文本的字数大于等于3个字,让文本进入通顺模型;当中文文本的字数小于3个字,通过规则的方式进行过滤。
本发明具有以下有益效果:
本发明的架构为3-gram技术结合textcnn模型。在通顺度模型训练方法上,不同于原有技术采用较小的文本片段作为第一通顺度,将文本片段中的多个分词作为第二通顺度,结合第一和第二通顺度来进行语言是否通顺的判断的方式,而是:第一,在数据使用上,使用非通顺和通顺数据,且使用文本自动增广技术和回译的方式对语料进行扩充;第二,使用3-gram技术将每个文本转化为不同维数的向量,为统一向量维数然后再转化为五维向量,最后使用textcnn神经网络进行模型训练;第三,通顺度的计算方面,使用3-gram算法和textcnn神经网络相结合的方式计算文本是否通顺,使用3-gram的编码方式有利于判断该语句是否合理,使用textcnn模型主要因为其模型简单,训练速度快,模型效果好。
本发明使用每个文本片段的通顺度同时结合神经网络来提高通顺度模型,数据量越大神经网络泛化性越好。
附图说明
图1为本发明实施例的辅助语音识别的通顺模型方法数据预处理流程。
图2为本发明实施例的辅助语音识别的通顺模型预测。
具体实施方式
为了便于本领域技术人员的理解,下面结合实施例与附图对本发明作进一步的说明。
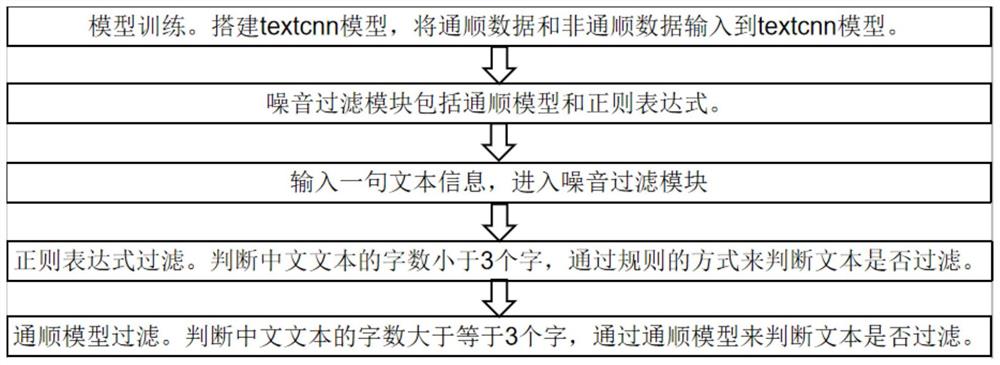
本实施例的辅助语音识别的通顺模型数据预处理过程如图1所示,包括:
步骤1:生成字数为2和3的统计词频的字典。使用百度百科常识知识库(作为预先准备的通顺数据集)训练2,3词频的字典。
步骤2:通顺数据生成。使用同义词替换、回译的方式对百度百科常识知识库进行数据集增广。
步骤3:非通顺数据集预处理。百度百科常识数据库中的每个句子通过分词生成一个基于词的列表。
步骤4:非通顺数据集生成。将词列表通过交换,删除,同义词插入的方式进行打乱,生成非通顺数据集。
步骤5:数据集向量化。使用3-gram技术使用字数为2和3的统计词频的字典,将非通顺和通顺数据集向量化,同时分别给通顺数据集和非通顺数据集打上0,1标签。
接下来进入模型训练过程:
步骤6:模型准备。搭建textcnn神经网络模型。
步骤7:通顺模型训练。使用向量化的数据对神经网络模型进行训练,从而获得通顺模型。
以下为通顺模型预测阶段:
步骤8:获取语音信息。
步骤9:语音信息转成中文文本。
步骤10:不同字数的文本处理。当中文文本的字数大于等于3个字,让文本进入通顺模型。当中文文本的字数小于3个字,通过规则的方式进行过滤。
步骤12:通顺模型判断语言是否通顺。中文文本输入到通顺模型中,判断该文本是否通顺。如果该中文文本通顺,则进入到下游的自然语言处理阶段。如果该中文文本不通顺,则过滤此中文文本。
3-gram算法的计算公式如下:
如果我们有一个n个字的句子s,w为句子中的字,句子的另一种表述形式为
s=w
我们希望该句子出现的概率为
p(w
若句子中字与字之间相互独立,则概率如下:
p(w
1-gram算法的简化公式为:
p(w
3-gram算法的简化公式为:
本实施例使用3-gram的编码方式有利于判断该语句是否合理和规则;使用3-gram和textcnn神经网络的方式计算通顺度;使用文本自动增广技术和回译的方式对语料进行扩充。数据量越大,神经网络的泛化性越好。
使用本实施例的通顺模型辅助语音识别,能够使得语音识别下游任务接收的语句通顺率更高,处理效率更好。
以上的实施例仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明保护范围之内。
- 一种通顺模型训练方法及辅助语音识别方法
- 一种远场语音识别方法、语音识别模型训练方法和服务器