基于热力图、逆向工程和模型剪枝的后门攻击防御方法
文献发布时间:2023-06-19 11:49:09
技术领域
本发明涉及神经网络模型剪枝领域,更具体的说是涉及一种基于热力图、逆向工程和模型剪枝的后门攻击防御方法。
背景技术
最近,一种新型攻击方式——后门攻击(Backdoor Attacks)备受关注。攻击者使用带有后门触发器(Backdoor Trigger)的恶意数据训练模型后,模型将会被注入后门。后门模型可以将所有良性数据正确分类,但当输入带有后门触发器的数据时,将会出现误分类。后门攻击具有极强的隐蔽性,给攻击检测带来了巨大挑战,也给一些需要外包训练过程的资源受限型用户带来了不小的风险。
热力图(又称相关系数图)是数据可视化的主要方法。使用者可以根据图中不同方块颜色对应的相关系数的大小判断出变量之间的相关性的大小。相关系数越大,变量间的线性相关程度越高;相关系数越小,变量间的线性相关程度越低。攻击者可以根据目标类数据生成热力图,然后确定后门触发器的最佳位置,从而达到较好的攻击效果。
逆向工程(又称反向工程)可以通过逆向分析技术由已知的事实和结论反推出输入内容。对于攻击者而言,逆向工程可以帮助其分析目标模型或训练数据集的相关信息,达到窃取模型或数据的目的;对于防御者而言,逆向工程可以帮助其预测攻击者的行为,并进行相应的防御设计。在深度神经网络后门攻击中,防御者可以利用逆向工程的思路,通过观察输出值和激活值,反推出可能的后门触发器,从而辅助防御方案的制定。
模型剪枝是模型压缩的一种方法,指的是将神经网络中相对不重要的神经元剪除,在保证功能完整的前提下获得一个更轻量级的网络。目前主要有两种剪枝方法。第一种是利用神经元权值的大小来判断神经元的重要性,权值越小的神经元通常对神经网络的贡献越小,因此可以将每一层权值较小的神经元剪除。第二种是利用神经元激活值的大小来判断神经元的重要性,激活值越小的神经元往往对神经网络贡献越小,因此可以剪除每一层激活值较小的神经元来达到剪枝目的。
研究表明,正常数据通常使后门植入污染的神经元处于休眠状态,只有带有后门触发器的数据才能强烈激活它们。所以,可以通过模型剪枝操作来修剪掉一些休眠神经元从而实现后门攻击的防御,即输入正常的数据,激活值低的也就是后门植入污染的神经元,按激活值从低到高剪枝,直到测验数据的准确性低于阈值终止。但是,这种基于激活值的剪枝策略局限于针对随机型触发器的后门攻击,对于模型依赖型触发器(选择模型中权重较大的神经元生成触发器、选择正常数据输入下高激活值神经元生成触发器等)不起作用。
发明内容
本发明基于现有技术的不足,提出基于热力图,逆向工程和模型剪枝技术的防御深度神经网络的后门攻击方法,解决了传统方案难以防御的对于模型依赖型的后门攻击问题,弥补了相关方面的空白。
为了实现上述目的,本发明采用如下技术方案:
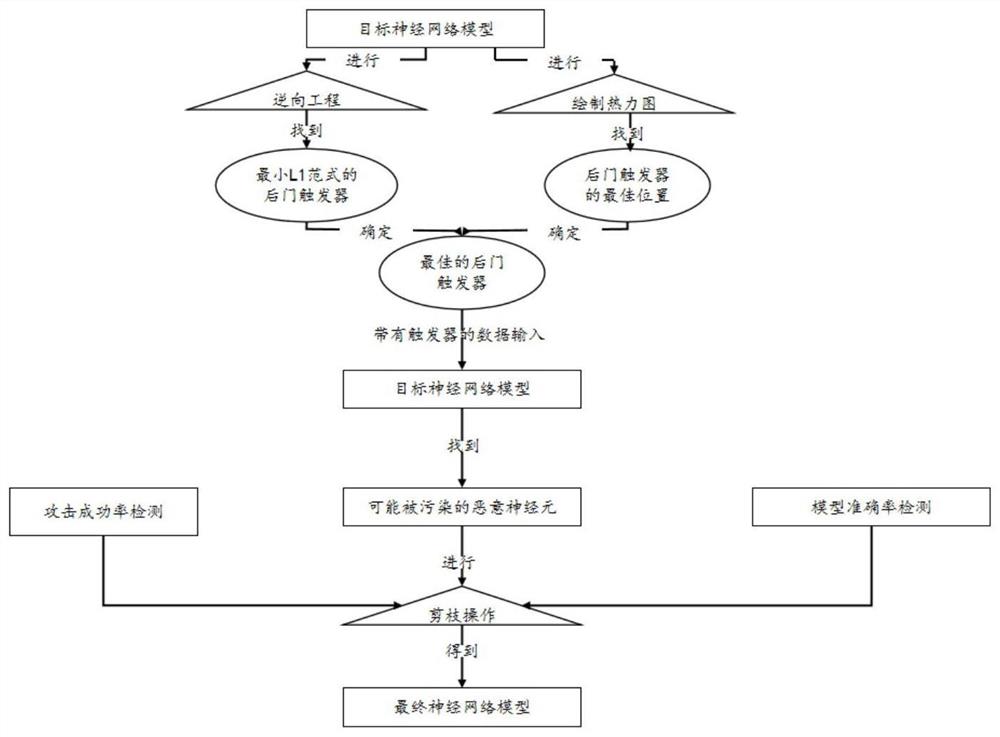
一种基于热力图、逆向工程和模型剪枝的后门攻击防御方法,包括以下步骤:
确定目标神经网络中每一类别的后门触发器,通过离群检测点算法比较所述后门触发器的L1范式,并确定目标标签,作为目标标签数据;
对所述目标神经网络的类别进行模型反演计算出相应数据集,所述数据集是所述目标神经网络的训练集,根据所述数据集绘制热力图,根据所述热力图确定所述后门触发器的最佳位置;
向所述目标神经网络依次输入目标标签数据,根据所述目标标签数据的权值、激活值,筛选出所述目标神经网络中目标神经元;
根据目标神经元,对目标神经网络进行模型剪枝。
优选的,所述目标标签根据逆向工程确定。
优选的,还包括对所述目标神经网络进行攻击成功率检测和模型准确率检测,多次调试完成对所述目标神经网络剪枝。
优选的,所述后门触发器应满足以下公式:
优选的,其特征在于,所述离群检测点算法满足以下三个公式:
b
M=b
上式中a
优选的,所述后门触发器包括随机型和模型依赖型。
优选的,向所述目标神经网络中输入无恶意的验证数据集D
优选的,对于剪枝后后门攻击的攻击成功率,在进行一轮剪枝后,测试带有后门触发器的数据被剪枝后的模型误分类的成功率,即所述攻击成功率。
经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种基于热力图、逆向工程和模型剪枝的后门攻击防御方法,很好地解决了基于激活值剪枝的传统方法无法防御基于模型依赖型触发器的后门攻击问题。并且,因为在模型剪枝前先逆向生成了潜在的后门触发器,减小了恶意神经元的搜索范围,有效提高了剪枝的效率。剪枝过程中同步检测模型准确率和攻击成功率,并进行适当的局部微调,在降低攻击成功率的同时也保证了模型的准确率。
经检测,本发明可以有效防御基于随机型触发器和基于模型依赖型触发器的后门攻击,并且不侵害模型的可用性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
图1附图为本发明的流程示意图;
图2附图为恢复后门触发器和目标标签的流程图;
图3附图为确定后门触发器最佳位置的流程图;
图4附图为筛选后门模型中可能存在的恶意神经元流程图;
图5附图为后门模型剪枝流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例公开了一种基于热力图、逆向工程和模型剪枝的后门攻击防御方法,如图1和图2所示,包括以下步骤:
确定目标神经网络中每一类别的后门触发器,通过离群检测点算法比较后门触发器的L1范式,并确定目标标签,作为目标标签数据;
对目标神经网络的类别进行模型反演计算出相应数据集,数据集是目标神经网络的训练集,根据数据集绘制热力图,根据热力图确定后门触发器的最佳位置;
向目标神经网络依次输入目标标签数据,根据输入目标标签数据的权值、激活值,筛选出目标神经网络中目标神经元;
根据目标神经元,对目标神经网络进行模型剪枝。
在本实施例中,步骤1:通过逆向工程技术反推出针对目标神经网络每一类别的潜在后门触发器,并且找到后门攻击的目标标签。
后门攻击的基本思路是通过构造后门触发器来让目标神经网络将带有后门触发器的非目标类别数据分类成目标类别。后门触发器应该满足两个条件:一是让带有后门触发器的良性数据被分类成目标类别,这是攻击者的基本诉求;另一个是后门触发器应该尽可能的小,这是为了避开防御者的检测。
为了达到这两个条件,后门触发器T
公式(1)中
公式(2)中
步骤1的具体步骤如下:
首先定义触发器注入的一般形式:
A(x,m,Δ)=x′ (3);
x′
公式(3)中A(·)表示将触发器应用于原始图像x的函数。Δ是触发模式,表示具有与输入图像相同尺寸的像素颜色强度三维矩阵。m是决定触发器可以覆盖的原始图像像素数量的二维矩阵。公式(4)对m进行了更进一步的解释:当特定像素(i,j)的m
接下来是生成后门触发器的目标函数:
公式(5)中f(·)是目标神经网络的预测函数。l是衡量分类误差的损失函数,也就是我们实验中的交叉熵。X是可访问的良性数据集。λ是控制后门触发器大小的权重参数。较小的λ会使后门触发器的大小变大,同时也使误分类的成功率提高。在实验中,我们在优化过程中使用Adam优化器动态调整λ以确保>99%的良性图像可以成功地被错误分类。
进行上述优化过程后,我们找到了将任意其他输入都错误分类到目标标签y
接下来将以一个离群点检测算法找到这些后门触发器中具有最小L1范式的后门触发器Δ
b
M=b
上式中a
对每个标签都进行上述计算,得到每个标签的M值,其中M值较低的标签为怀疑标签。再对这些怀疑标签进行进一步的检查,再次计算M值,其中M值明显低于其它的标签就是目标标签。
步骤2:对神经网络目标类别y
首先对于深度神经网络模型的目标标签y
用numpy的corrcoef计算反演得到的数据集的相关关系矩阵,并作为数据参数传入heatmap函数。再来设置heatmap函数的矩阵块颜色参数,矩阵块注释参数和矩阵块之间间隔及间隔线参数等参数,就可以完成热力图的绘制。颜色最高亮的位置即为对于目标类别y
步骤3:通过向神经网络输入良性数据和步骤2设计的恶意数据,筛选出目标网络中可能被污染的恶意神经元。
为了注入后门,攻击者通常使用带有后门触发器(包括随机型和模型依赖型)的恶意数据去训练深度神经网络,导致部分神经元被后门触发器污染。这些恶意神经元会在后门触发器出现时被强烈激活,表现为激活值较高或者权重较高,而在输入良性数据时权值和激活值较低。
基于以上分析,当我们向深度神经网络输入大量带有后门触发器的样本和输入大量良性数据的样本时,后门模型中被污染的神经元在输入正常样本情况下与输入带有后门触发器的样本情况下的权重差值或激活值差值将会明显大于其他正常的神经元。因此我们可以通过对神经元在两种输入情况下的权重差值或激活值差值进行检测,从而找到一系列攻击者可能污染的神经元集合。
结合图4所示,步骤3的具体实现细节如下:
首先,将带有后门触发器的数据输入至深度神经网络中,计算第一个全链接层中(后门触发器通常激活的就是这一层的神经元)每一个神经元的激活值以及权重值。对于神经元的激活值,假设神经网络的第一层由K个神经元组成,则第一层第n个神经元的激活值
其中Φ
然后,将不带后门触发器的良性数据输入至深度神经网络中,同样用如上公式计算第一个全链接层中每一个神经元的激活值
最后,将输入带有后门触发器的数据情况下得到的激活值与权重值减去输入正常数据情况下得到的激活值与权重值得到激活值差值Δa与权重值差值Δw。按激活值差值Δa和权重值差值Δw从高到低的顺序排序形成两个数据集,两个数据集中排名靠前的神经元更可能是恶意神经元。
步骤4:对带有后门的深度神经网络进行模型剪枝。
上一步中已经得到按激活值差值Δa和权重值差值Δw从高到低的顺序排序的目标神经元集合,接下来进行最后的剪枝。模型剪枝可能会造成神经网络精度的损失,所以在每次剪枝操作后要进行检测,检测的标准有两个——剪枝后模型的预测准确率和剪枝后后门攻击的攻击成功率。
对于剪枝后模型的预测准确率,我们首先设置对照组,即向原始的深度神经网络中输入无恶意的验证数据集D
对于剪枝后后门攻击的攻击成功率,在进行一轮剪枝后,测试带有后门触发器的数据被剪枝后的模型误分类的成功率,即攻击成功率。攻击成功率下降越大,则剪枝越准确。
结合图5,步骤4具体实现方法如下:
对步骤3得到的按权重值差值排序的一系列神经元
设Q
剪枝完成后,使用预先训练好的神经网络权值来初始化训练剪枝后的神经网络,再次进行微调。通过微调可以恢复(至少部分恢复)由剪枝引起的良性输入的分类精度下降。微调后,得到了最终的良性神经网络模型。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 基于热力图、逆向工程和模型剪枝的后门攻击防御方法
- 基于模型剪枝和逆向工程的深度学习后门防御方法