一种基于形态判别网络的中药饮片图像数据清洗方法及系统
文献发布时间:2023-06-19 11:49:09
技术领域
本发明涉及图像分类和数据清洗领域,特别涉及一种基于形态判别网络的中药饮片图像数据清洗方法及系统。
背景技术
近年来,随着社会的不断发展,人们越来越重视中医药的地位。中医药是中华民族的宝贵财富,为中华民族做出了巨大贡献。传统医学的治疗理念正逐渐为世界所接受,传统医药受到国际社会越来越多的关注,世界范围内对中医药的需求日益增长,这为中医药的发展提供了广阔的空间。中药饮片是中草药等经过炮制加工而成可直接入药的原料,中药饮片超过上千种,常见的也有几百种,普通人难以区分不同的中药饮片。
深度学习等技术的出现却为这种难题带来了解决方案,使用深度学习识别中药饮片需要采集大量的中药饮片图像。人工采集图片成本较大,而互联网上有很多的中药饮片图像可以供我们使用,如果通过搜索引擎收集这些公开的中药饮片的图像,再对数据进行清洗,就可以用较低成本制作成深度学习所需要的数据集。目前常见的图像搜索引擎包括百度图片、搜狗图片、谷歌图片和必应图片,从这些搜索引擎搜索中药饮片名称往往会出现错误图像,甚至掺杂了很多与中药饮片不相关的图片,在某些中药饮片上尤其明显,掺杂的噪声数据主要包括3种类型:
1.与中医药相关的图像,如人物、地点、药材包装等;
2.中草药的植株图像;
3.中药饮片图像,但内容与标签不一致的图像。
直接使用网上获取的带有噪声的图像数据用作训练,训练效果往往不尽人意,难以满足需求;如果人工对数据逐个进行筛选,则会耗费很大的人力成本。
专利号CN201880001364.8的《数据清洗系统和方法》使用了多次的阈值判断对人脸数据进行清洗,其用意侧重于人脸和数据库的的匹配,而本发明则使用预训练的形态判别网络清洗网上批量获取的原生数据,旨在提高制作数据集的效率。
发明内容
本发明要克服网络采集的中药饮片图像数据噪声过大造成深度学习模型正确率过低情况的不足,提供一种基于形态判别网络的中药饮片图像数据清洗方法及系统。
本发明将常见的中药饮片按照形状进行分类,分为段状饮片、片状饮片、块状饮片和丝状饮片,并加入负样本以此作为中药饮片的形态类别。通过预训练形态判别网络自动对采集的中药饮片图像数据进行判别,保留符合形态特征结果的数据,从而达到数据清洗的目的。
本发明实现上述发明目的所采用的技术方案如下:
一种基于形态判别网络的中药饮片爬虫数据清洗方法,其特征在于,包括以下步骤:
S1:在常见的图像搜索引擎中,获取常见的中药饮片图像数据,按照形态分类保存,同时,获取与中药饮片无关的负样本图像数据;
S2:对中药饮片数据进行筛选,删去不符合要求的图片,并统一图像的大小;
S3:使用图像旋转和镜像等操作对各类别图像数据进行扩充,并在负样本数据中添加随机噪声生成的图片;
S4:使用形态分类数据训练形态判别网络;
S5:从互联网按照中药饮片名称逐类获取中药饮片数据;
S6:利用形态判别器对获取的中药饮片图像数据进行清洗
如此一来,中药饮片图像数据集中的不符合要求的数据就被清洗掉了。
进一步的,所述步骤S1具体包括:
S1.1:主流的图像搜索引擎包括百度图片、搜狗图片、必应图片和谷歌图片;
S1.2:中药饮片按照外形分为四大类:块状类、段状类、片状类和丝状类,分别记为KData、DData、Pdata和Sdata;
S1.3:无关中药饮片的关键词包括人物、风景、美食等,其数据记为NagtiveData。
进一步的,所述步骤S2具体包括:
S2.1:保留各类中药饮片中清晰且正确的图像,删除模糊、重复和内容与名称不符的图像;
S2.2:把KData、DData、Pdata、Sdata和NagtiveData的图像分辨率调整为224×224大小,必要时对图像进行剪裁。
进一步的,所述步骤S3具体包括:
S3.1:对各类别的图像使用旋转和镜像的操作进行数据扩充;
S3.2:因负样本量远低于其他类别,使用opencv生成随机噪声图片,添加到NagtiveData,保证各类别数据量大致相同,随机噪声图像的生成公式如下:
pix表示像素,x,y分别表示像素的横纵坐标,z=1,2,3分别表示像素的红绿蓝通道,rand(0,1)表示一个0-1之间的随机数。
进一步的,所述步骤S4具体包括:
S4.1:形态判别网络,输入为224×224,输出为5个类别:KData、DData、Pdata、Sdata和NagtiveData;
S4.2:形态判别网络训练的损失函数如下:
K是种类数量,y是标签,即如果类别是i,则y=1,否则等于0,p是神经网络的输出,也就是指类别是i的概率。
进一步的,所述步骤S5具体包括:
S5.1:分别从主流搜索引擎逐类获取各种中药饮片;
S5.2:每获取设定数量的图像,执行步骤S6。
进一步的,所述步骤S6具体包括:
S6.1:将获取的中药饮片数据使用形态判别器筛选,同一种的中药饮片的形态判别结果相同且不属于NagtiveData,保留符合中药饮片形态的图像数据;
S6.2:统计形态判别网络错判的图像所占比例,若高于设定阈值,返回步骤S3,则将错判的数据扩充到形态判别网络训练集,重新训练形态判别网络。
本发明还公开了一种基于形态判别网络的中药饮片图像数据清洗系统,包括依次连接的数据获取模块,数据筛选模块,数据扩充模块,形态判别网络训练模块和数据判别模块;
所述数据获取模块,在常见的图像搜索引擎中,获取常见的中药饮片及其负样本的图像数据,并按照所需类别自动分类保存图像数据;
所述数据筛选模块,检查数据获取模块获取的图像数据,从获取的中药图像数据中筛选出清洗正确的图像;
所述数据扩充模块,把筛选后的的数据通过旋转、镜像和剪裁等操作来对数据集进行扩充,同时使用opencv生成噪声图像来保持各类别的均衡;
所述形态判别网络训练模块,将数据扩充模块的数据划分为训练集和验证集,分批输入到形态判别网络中,对模型进行训练,多次迭代后直到模型训练达到稳定,保存模型;
所述数据判别模块,将从网上获取的某类中药饮片图像,分批量输入到形态判别网络中,保留符合中药饮片形态的图像,清洗掉不符合饮片形态的图像。
本发明的技术构思为:繁多的中药饮片按照形态可以分为片状饮片、段状饮片、块状饮片和丝状饮片,利用卷积神经网络来学习中药饮片的形态特征,进一步对爬虫采集的中药饮片掺杂的噪声图像进行判别,可以达到对爬取的每一类中药饮片数据判别和筛选的目的。
本发明的有益效果为:使用形态判别网络判别中药饮片图像数据是否是噪声图像,利用了中药饮片的形态特征去除爬取的中药饮片图像中的噪声数据,本发明大大降低了清洗中药饮片图像数据所花费的人力和时间成本,而且拥有较好的数据清洗效果,而且清洗后的数据再用于深度学习模型的训练效果会提升很多。
附图说明
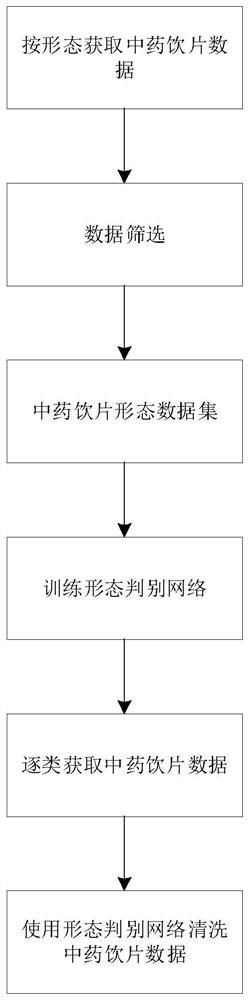
图1为本发明的基本构思流程图。
图2为本发明的具体实施流程图。
图3(a)~图3(d)为四种形态的中药饮片,其中图3(a)为片状的中药饮片,图3(b)为丝状的中药饮片,图3(c)为段状的中药饮片,图3(d)为块状的中药饮片。
图4(a)~图4(d)为搜索引擎中的中药饮片徐长卿及其噪声图像,其中图4(a)为正确的饮片,图4(b)、图4(c)、图4(d)为其噪声图像。
图5为随训练次数增加形态判别网络错判率变化结果。
具体实施方式
下面结合说明书附图对本发明的具体实施方式作进一步详细描述。
参照图1~图5,一种基于形态判别网络的中药饮片图像数据清洗方法及系统,其特征在于,包括以下步骤:
S1:形态分类数据的采集:在常见的图像搜索引擎中,获取常见的中药饮片图像数据,按照形态分类保存,同时,获取与中药饮片无关的负样本图像数据;
S2:形态分类数据的清洗:对中药饮片数据进行筛选,删去不符合要求的图片,并统一图像的大小;
S3:形态分类数据集的扩充:使用图像旋转和镜像等操作对各类别图像数据进行扩充,并在NagtiveData中添加随机噪声生成的图片;
S4:训练形态判别网络:使用形态分类数据训练形态判别网络;
S5:爬取中药饮片图像:从互联网按照中药饮片名称逐类获取中药饮片数据;
S6:数据清洗:利用形态判别器对获取的中药饮片图像数据进行清洗。
所述步骤S1具体包括:
S1.1:本发明所使用的图像搜索引擎包括百度图片、搜狗图片、必应图片和谷歌图片;
S1.2:对应图2,中药饮片按照外形分为四大类:块状类、段状类、片状类和丝状类,分别记为KData、DData、Pdata和Sdata,每类采集300张图像;
S1.3:无关中药饮片的关键词包括人物、风景、美食等,其数据记为NagtiveData,每类采集100张图像。
所述步骤S2具体包括:
S2.1:检查获取的图像,保留各类中药饮片中清晰且正确的图像,删除模糊、重复和内容与名称不符的图像;
S2.2:把KData、DData、Pdata、Sdata和NagtiveData的图像分辨率调整为224×224大小,必要时对图像进行剪裁。
所述步骤S3具体包括:
S3.1:对各类别的图像使用旋转和镜像的操作进行数据扩充;
S3.2:因为负样本的数量远低于其他种类,使用opencv生成400张随机噪声图片,添加到NagtiveData,以保证各类别数据量的均衡,随机噪声图像的生成公式如下:
pix表示像素,x,y分别表示像素的横纵坐标,z=1,2,3分别表示像素的红绿蓝通道,rand(0,1)表示一个0-1之间的随机数。
所述步骤S4具体包括:
S4.1:形态判别网络基于Resnet18,输入为224×224,输出为5个类别:KData、DData、Pdata、Sdata和NagtiveData;
S4.2:形态判别网络训练的损失函数如下:
K是种类数量,y是标签,即如果类别是i,则y=1,否则等于0,p是神经网络的输出,也就是指类别是i的概率,训练形态判别网络时,将80%的数据用作训练集,20%用作测试集,学习率为0.05,学习迭代500次。
所述步骤S5具体包括:
S5.1:使用爬虫分别从主流搜索引擎逐类获取常见的各种中药饮片图像数据,并记录爬取的数量;
S5.2:每获取200张图像,停止爬虫,执行步骤S6。
所述步骤S6具体包括:
S6.1:将获取的中药饮片数据使用形态判别器筛选,同一种的中药饮片的形态判别结果相同且不属于NagtiveData,保留符合中药饮片形态的图像数据;
S6.2:统计形态判别网络错判的图像所占比例,若高于设定阈值,返回步骤S3,则将错判的数据扩充到形态判别网络训练集,重新训练形态判别网络。
一种基于形态判别网络的中药饮片图像数据清洗系统,包括依次连接的数据获取模块,数据筛选模块,数据扩充模块,形态判别网络训练模块和数据判别模块;
所述数据获取模块,在常见的图像搜索引擎中,获取常见的中药饮片及其负样本的图像数据,并按照所需类别自动分类保存图像数据;具体包括:
S1.1:主流的图像搜索引擎包括百度图片、搜狗图片、必应图片和谷歌图片;
S1.2:中药饮片按照外形分为四大类:块状类、段状类、片状类和丝状类,分别记为KData、DData、Pdata和Sdata;
S1.3:无关中药饮片的关键词包括人物、风景、美食等,其数据记为NagtiveData。
所述数据筛选模块,检查数据获取模块获取的图像数据,从获取的中药图像数据中筛选出清洗正确的图像;具体包括:
S2.1:保留各类中药饮片中清晰且正确的图像,删除模糊、重复和内容与名称不符的图像;
S2.2:把KData、DData、Pdata、Sdata和NagtiveData的图像分辨率调整为224×224大小,必要时对图像进行剪裁。
所述数据扩充模块,把筛选后的的数据通过旋转、镜像和剪裁等操作来对数据集进行扩充,同时使用opencv生成噪声图像来保持各类别的均衡;具体包括:
S3.1:对各类别的图像使用旋转和镜像的操作进行数据扩充;
S3.2:使用opencv生成400张随机噪声图片,添加到NagtiveData,保证各类别数据量大致相同,随机噪声图像的生成公式如下:
pix表示像素,x,y分别表示像素的横纵坐标,z=1,2,3分别表示像素的红绿蓝通道,rand(0,1)表示一个0-1之间的随机数。
所述形态判别网络训练模块,将数据扩充模块的数据划分为训练集和验证集,分批输入到形态判别网络中,对模型进行训练,多次迭代后直到模型训练达到稳定,保存模型;具体包括:
S4.1:形态判别网络,输入为224×224,输出为5个类别:KData、DData、Pdata、Sdata和NagtiveData;
S4.2:形态判别网络训练的损失函数如下:
K是种类数量,y是标签,即如果类别是i,则y=1,否则等于0,p是神经网络的输出,也就是指类别是i的概率。
所述数据判别模块,将从网上获取的某类中药饮片图像,分批量输入到形态判别网络中,保留符合中药饮片形态的图像,清洗掉不符合饮片形态的图像。具体包括:
S5.1:分别从主流搜索引擎逐类获取各种中药饮片,记录保存图像的数量;
S5.2:每获取设定数量的图像,执行步骤S6.1~S6.2;
S6.1:将获取的中药饮片数据使用形态判别器筛选,同一种的中药饮片的形态判别结果相同且不属于NagtiveData,保留符合中药饮片形态的图像数据;
S6.2:统计形态判别网络错判的图像所占比例,若高于设定阈值,返回步骤S3,则将错判的数据扩充到形态判别网络训练集,重新训练形态判别网络。
本说明书实施例所述的内容仅仅是对发明构思的实现形式的列举,本发明的保护范围不应当被视为仅限于实施例所陈述的具体形式,本发明的保护范围也及于本领域技术人员根据本发明构思所能够想到的等同技术手段。
- 一种基于形态判别网络的中药饮片图像数据清洗方法及系统
- 基于判别字典学习和形态成分分解的多源图像融合方法