一种非绿幕下的实时高分辨率戏曲人物抠图方法
文献发布时间:2023-06-19 12:10:19
技术领域
本发明属于计算机图形学处理技术领域,具体涉及一种非绿幕下的实时高分辨率戏曲人物抠图方法。
背景技术
秦腔起源于古代陕西、甘肃一带,是我国传统戏剧最具表现性的剧种之一。秦腔艺术在我国有几千年的传承历史,堪称中国戏曲的鼻祖,为中华民族戏曲的融合、发展、演变起到至关重要的作用。目前由于秦腔艺术创新性不足等原因致使秦腔这一艺术形式逐渐淡出大众视线。对于戏曲人物进行抠图便于对戏曲人物进行分析整理和二次创作,对戏曲艺术的创新发展有着积极的推动作用。
传统的非基于学习的抠图算法需要手动标记三色图,并求解三色图的未知区域中的α蒙版。目前的许多方法依赖于蒙版数据集来学习抠图,例如上下文感知抠图、索引抠图、基于采样的抠图和基于不透明度传播的抠图。这些方法的性能取决于标记的质量。对于已知自然背景(非绿幕下)的抠图已有的一个方法是预先捕获一张背景图片,通过上下文切换块构建的编码器和解码器预测α蒙版和前景层,但该方法的分辨率限制在512×512,运行速度仅为8fps。此外,还有直接从图像中解决α蒙版的方法,均存在要求抠图的图像分辨率不易过高的问题,通常无法推广。
发明内容
针对现有技术存在的不足,本发明的目在于提供一种非绿幕下的实时高分辨率戏曲人物抠图方法,实现高分辨率图像处理,能够实现更准确更精细的戏曲人物图像抠图。
为了实现上述目的,本发明采用以下技术方案予以实现:
一种非绿幕下的实时高分辨率戏曲人物抠图方法,包括以下步骤:
步骤一:输入以戏曲人物为主体的图片I以及一张提前捕获的背景图片B;
步骤二:将输入图片I和背景图B进行下采样,并将图片I和图片B的分辨率设置为同一值;
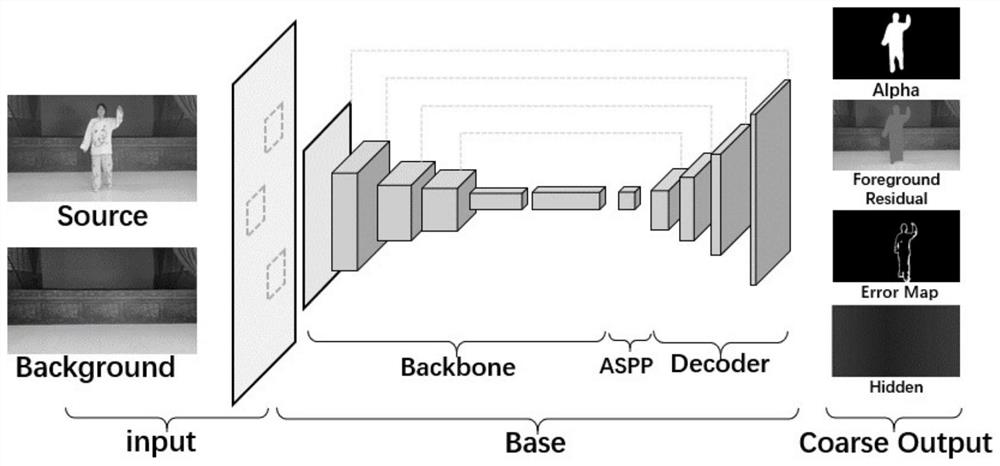
步骤三:将Base网络中的BackBone模块中的网络更改为MobileNetV3,此外将网络第一层卷积更改为图片输入通道;将下采样之后的值输入到Base网络中计算出低分辨率图像以产生粗粒度结果和误差预测图E
其中,前景残差F
F
其中,F为预测的前景图,I为输入的图像;
步骤四:将Base网络处理的粗粒度结果作为Refiner网络的输入,对预测误差最大的位置块进行细化,该Refiner网络仅对基于误差预测图E
步骤五:依据Refiner网络得到的Alpha值和前景残差F
进一步,所述步骤三中采用MobileNetV3作为Base网络的BackBone,MobileNetV3将其1×1的卷积层放在avg pooling后面,利用avg pooling将特征图维度降低,然后再利用1×1的卷积提高维度。
进一步,所述步骤三中本发明将MobileNetV3网络的第一层卷积更改为接受输入图像和背景图像的6个通道。
进一步,所述步骤四中执行两个阶段的细化,首先是原始分辨率的1/2,然后是完全分辨率。
进一步,细化时,通过两层3×3卷积、Batch Normalization和ReLU将块的维度降低到4×4,然后再将得到的中间特征上采样到8×8,之后在通过两层3×3卷积、BatchNormalization和ReLU得到4×4的α蒙版、前景残差F
进一步,所述步骤五中得到的人物抠像结果即恢复后的前景图F是通过将前景残差F
F=max(min(F
其中,F
进一步,所述Base网络的损失函数是其输入的损失的加和:
其中,
所述Refiner网络的损失为:
L
其中,L
本发明具有以下效果:
本发明公开了一种非绿幕下的实时高分辨率戏曲人物抠图方法,首先提前捕获一张背景图,然后将图片与背景图输入到Base网络中进行计算,得出低分辨率的结果,之后由Refiner网络对局部位置进行细化,对抠图内容进行完善;本发明对Base网络进行了改进,引入了MobileNetV3作为BackBone结构,同时将网络的第一层卷积层更改为接收输入图像和背景图像的6个通道;过两个网络使抠图效果更加精细,同时改进的网络提高了抠图的效率,提高了实时处理的效率,实验表明对图像的粗粒度处理速度有很大提升,极大提高了抠图的实时性。仅借助手机摄像机等便利设备拍摄的照片便可实现精细的抠图结果,解决了无法在自然背景下实现高分辨率抠图的问题。
本发明对主干网络进行了改进,Base网络由backbone、ASPP和解码器三个模块组成,采用MobileNetV3作为编码器主干。在MobileNetV2中在网络结构的最后一部分用1×1的卷积层来提高特征图的维度,但这造成了一定的延时。为提高实时性,采用了MobileNetV3在保证精度的同时提高了处理效率。MobileNetV3将该1×1的卷积层放在avgpooling后面,利用avg pooling将特征图大小由7×7降到1×1,然后再利用1×1的卷积提高维度。
本发明通过求解前景残差F
附图说明
图1是本发明的Base网络结构图;
图2是本发明的Refiner网络结构图;
图3是通过改进的抠图方法的MobileNetV3网络结构图;
图4a是本发明的输入戏曲人物图像;
图4b是本发明的输入戏曲中提前捕获的背景图;
图5是通过改进后的抠图方法的Alpha图;
图6通过改进后的抠图方法的预测误差图;
图7是通过改进后的抠图方法生成的效果图。
具体实施方式
以下结合实施例对本发明的具体内容做进一步详细解释说明。
步骤一:输入以戏曲人物为主体的图片I以及一张提前捕获的背景图片B。
步骤二:将输入图片I和背景图B进行下采样,并将图片I和图片B的分辨率设置为同一值。
步骤三:将下采样之后的值输入到Base网络中进行操作计算出低分辨率图像以产生粗粒度结果和误差预测图E
步骤四:将Base网络处理的粗粒度结果作为Refiner网络的输入,该网络仅对基于误差预测图E
如图1-3所示,在Refiner网络中,本发明首先对Base网络输出的α蒙版、前景残差F
在细化位置的选择上,我们ground-truth误差图定义为E
L
其中,L
步骤五:依据Refiner网络得到的Alpha值和前景残差F
使用F=max(min(F
如图4a和图4b所示,中将以戏曲人物为前景的图片I以及一张提前捕获的背景图片B作为输入,将输入图片I与背景图B的分辨率设置统一。由Base网络进行粗粒度处理之后可得到如图5Alpha图和图6预测误差图。之后选取预测误差最大的位置块进行细化可得到细化之后的alpha值和前景残差F
在上述步骤五中的Base网络由backbone、ASPP和解码器三个模块组成。其中backbone模块由MobileV3网络实现。ASPP模块遵循了DeepLabV3中提出的ASPP模块的原始实现。ASPP模块由多个扩张率分别为3、6和9的膨胀卷积滤波器组成。解码器网络采用双线性上采样,通过3×3卷积和RELU激活实现。
在上述步骤五中,对求得的alpha值进行损失计算,我们在α蒙版与其梯度上使用L1损失:
其中,L
在上述步骤五中求其恢复后的前景图F,对此计算损失,其中对α
L
其中,L
- 一种非绿幕下的实时高分辨率戏曲人物抠图方法
- 一种基于多任务深度学习的无绿幕人像实时抠图算法