一种基于随机森林的县域碳排放的预测方法
文献发布时间:2023-06-19 12:10:19
技术领域
本发明涉及人工智能应用领域,更具体地,涉及在县域多要素优化后将利用特征数据进行模型训练以实现对县域碳排放量预测。
背景技术
当前,我国对于碳排放预测研究仍然十分匮乏,无法有效地预防某一区域的过度排放,失去区域之间碳排放量的平衡。随着人工智能的发展,可以通过分析影响碳排放的因素,利用特征工程构建碳排放特征,从特征的角度预测县域的碳排放量,从而提高碳排放预测的准确率。通过对年鉴分析,可以将经济发展、交通出行、居民生活和生态绿化相关指标作为直接碳排放特征,将规模结构和能源效率相关指标作为间接碳排放特征,通过随机森林算法将直接碳排放特征和间接碳排放特征结合,有效预测县域碳排放量。
发明内容
为了解决上述问题,本发明提供了一种基于随机森林算法的县域碳排放预测方法,该方法包括:
一种基于随机森林的县域碳排放的预测方法,其中预测模型中的数据依据县域下生产、居民生活、以及道路交通三个维度的数据进行其特征提取,基于所述三个维度的数据进行所述碳排放的预测,其特征在于,所述预测方法包括:
步骤1:通过对县域数据进行筛选,形成训练模型所需的初始数据集,形成初始县域城镇碳排放指标要素,分为三类:生产类、生活类和交通类;
步骤2:对数据进行数据清洗和标准化的数据预处理;
步骤3:形成训练数据集,在所述生产类、所述生活类和所述交通类的每个类别中,并通过采用Bootstrap方法生成训练子集和决策树,在所述决策树每个节点分裂时,随机在N个属性中的选取n个碳排放影响指标作为当前节点分裂的子集,需满足n<<N;分裂结束后的各个决策树组合在一起,构成随机森林;
步骤4:将预测集中的参数向量feature输入到训练好的模型中,每颗决策树T
进一步地,碳排放指标要素中的所述生产类、所述生活类和所述交通类的指标要素分别作为N个输入变量,将实际测得的当年碳排放量作为输出变量,输入变量和输出变量共同组成训练数据集D。
进一步地,所述数据清洗包括采用均值代替法对所述初始数据集进行清洗,步骤包括:清洗缺失值、清洗格式内容、清洗逻辑错误和清洗废需求数据;所述标准化的数据预处理包括采用min-max标准化,若集合中有t个元素,对集合元素x
进一步地,所述采用Bootstrap方法生成训练子集和决策树包括对训练样本进行有放回的随机抽样,重复m次后将获得的m个训练样本共同形成训练数据集D的训练数据子集D
进一步地,所述决策树的每个所述节点分裂包括通过采用分类与回归树方法,在分裂子集中根据“平方误差最小准则”,选择最优结果的1个碳排放影响指标X
进一步地,预测集中的参数向量feature根据收集到的影响县域第t年碳排放量的特征指标,按所述生产类、所述生活类和所述交通类可定义为:
其中,n
其中β为未知参数,ε为随机误差,f为算法模型致力于求解的最佳函数,即β
本发明提出了考虑多特征的随机森林模型来训练和预测县域中的碳排放量,它能够综合提取县域内的多维度特征,并且不用在众多县域特征中进行选择。由于随机森林模型中决策树之间是独立的,面对县域的大数据量可以实现并行训练操作,训练速度快,且实现简单。此外,在用随机森林模型训练完成后,可以得到每种特性影响碳排放的重要程度,从而使企业和政府可以更好地控制碳排放量,实现碳排放污染有效治理。
附图说明
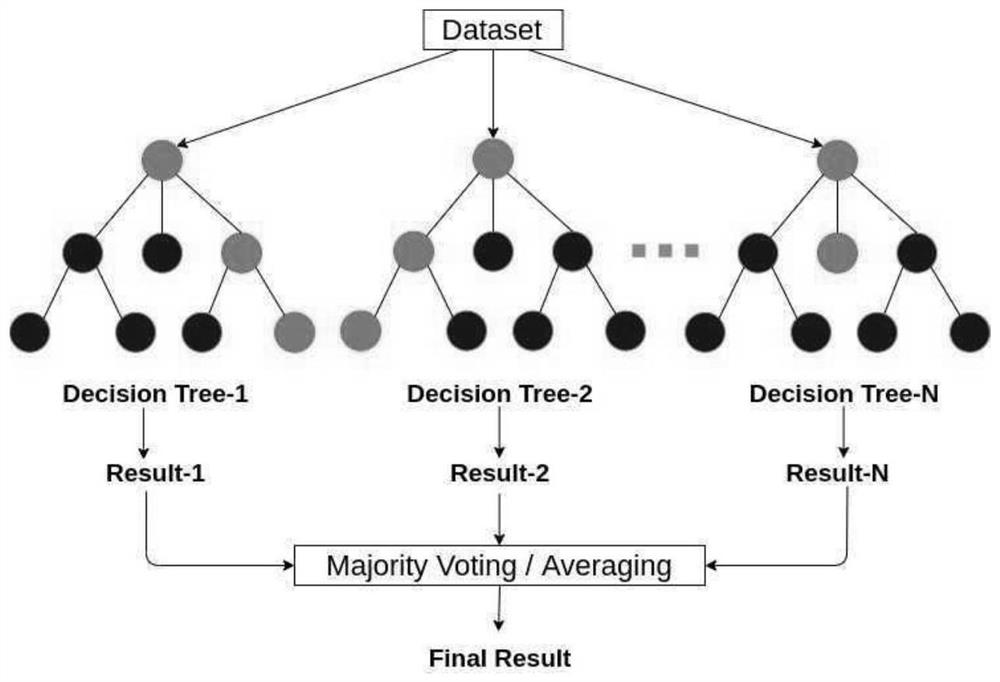
图1示出了随机森林(Random Forest,RF)算法的算法过程。
图2示出了本发明RF算法与LR算法、LASSO算法、SVR算法关于县域生活类碳排放预测的对比结果。
图3示出了本发明RF算法与LR算法、LASSO算法、SVR算法关于县域生产类碳排放预测的对比结果。
图4示出了本发明RF算法与LR算法、LASSO算法、SVR算法关于县域交通类碳排放预测的对比结果。
具体实施方式
下面的实施例可以使本领域技术人员更全面地理解本发明,但不以任何方式限制本发明。
本发明主要利用的是随机森林(Random Forest,RF)算法,其中随机森林是指利用多棵树对样本进行训练并预测的一种分类器,而RF算法是一种采用集成学习中bagging思想的学习方法,由多个决策树组成的模型,并且各个决策树之间没有关联。算法过程如图1所示。在RF算法过程中,首先采用bootstrap的方法,即有放回的随机抽样方法,从数据集中抽取n个样本作为一个训练集,通过每个训练集训练一颗决策树,重复实验直到构造出m棵决策树。然后,将随机森林的每棵决策树的预测结果取平均值作为最整体的预测结果,从而进行整体的预测。利用随机森林进行预测的准确性高,可以有效地运行在大数据集上,不容易过拟合。另外,由于由多个决策树组成,模型可以进行并行训练,提高训练速度,并且随机森林对训练集中的噪声不敏感,多个决策树的综合决策比单个决策树算法更稳健。
基于此,本发明通过综合提取县域下生产、居民生活、以及道路交通三个维度的数据特征建立一个多特征随机森林模型来预测县域中的碳排放量,从而具有更精准的预测性能。
问题描述
首先,将县域碳排放量预测假设为一个回归预测过程,将收集到的影响县域在t年下的特征分为生产(production)、生活(life)、交通(traffic)三类。设一个县域i在t年下的总碳排放量为C
根据收集到的影响县域第t年碳排放量的特征指标,按生产、生活和交通可定义为:
其中,n
通过Pearson相关分析法得到每个指标的平均影响系数,可确定特征与碳排放的具有线性相关性,可以将碳排放预测任务归结为一个多元线性回归问题,即:
其中β为未知参数,ε为随机误差。f为本发明的算法模型致力于求解的最佳函数,即β
最终预测的碳排放量
损失函数采用均方误差(Mean Squared Error,MSE),其定义为:
其中,m为观测数量。
求解方法
基于随机森林,本发明提出了考虑县域内的生产、居民生活、以及道路交通组成的碳排放结构对碳排放进行预测。而预测方法的具体步骤为:
步骤1:数据获取
根据统计年鉴得到N个县域的数据,其中N=1814。首先,获取N个县域的元素集合。通过对县域数据进行筛选,形成训练模型所需的初始数据集,形成初始县域城镇碳排放指标要素。其中,要素包括建成区面积、土地城镇化率、人口规模、县域人口规模、建成区人口密度、GDP、人均GDP、第一产业增加值、第二产业增加值、全社会固定资产投资总额、燃气供应覆盖率、供热管道密度、供热容积率、居住密度、道路密度、每万人公共交通工具拥有量、人均机动车保有量、每万人拥有公园数量、医疗设施配置率、社会福利设施配置率和步行道面积占道路面积比重。
其次,为提高模型的准确性和鲁棒性,将集合元素进行分类。将元素分为三类:生产类、生活类和交通类。其中,生产类包括建成区面积、土地城镇化率、人口规模、县域人口规模、建成区人口密度、GDP、人均GDP、第一产业增加值和第二产业增加值;生活类包括建成区面积、土地城镇化率、人口规模、县域人口规模、GDP、人均GDP、第一产业增加值、第二产业增加值、燃气供应覆盖率、供热管道密度、供热容积率和居住密度;交通类包括建成区面积、人口规模、县域人口规模、GDP、人均GDP、第一产业增加值、第二产业增加值、道路密度、每万人公共交通工具拥有量、人均机动车保有量、每万人拥有公园数量、医疗设施配置率、社会福利设施配置率和步行道面积占道路面积比重。
步骤2:数据预处理
通过聚类分为生产类、生活类和交通类,数据文件类型为Html和Excel,文件总共包括21个字段、7612条记录,内容涵盖了1905个县域的数据,时间跨度从2010年至2018年。原始数据集包含建成区面积、土地城镇化率、人口规模、县域人口规模等。由于年鉴中的数据会存在缺失数据、格式错误等问题,需要对数据进行数据清洗。本发明采用均值代替法对数据集进行清洗,步骤包括:清洗缺失值、清洗格式内容、清洗逻辑错误和清洗费需求数据。
对数据进行清洗后,由于各字段数据量级跨度大,有数据单位限制,需对数据进行标准化,将数据按比例进行缩放,使数据落入一个非常小的特定区间,并且转化为一个无量纲的纯数值,这样可对不同单位的指标进行加权。本发明采用min-max标准化,若集合中有t个元素,对集合元素x
步骤3:算法预测
形成训练数据集:将生产类中的建成区面积、土地城镇化率、人口规模、县域人口规模、建成区人口密度、GDP、人均GDP、第一产业增加值和第二产业增加值,生活类中的建成区面积、土地城镇化率、人口规模、县域人口规模、GDP、人均GDP、第一产业增加值、第二产业增加值、燃气供应覆盖率、供热管道密度、供热容积率和居住密度,交通类中的建成区面积、人口规模、县域人口规模、GDP、人均GDP、第一产业增加值、第二产业增加值、道路密度、每万人公共交通工具拥有量、人均机动车保有量、每万人拥有公园数量、医疗设施配置率、社会福利设施配置率和步行道面积占道路面积比重分别作为生产、生活和交通类的特征指标,即模型的输入变量,将实际测得的当年碳排放量作为输出变量,输入变量和输出变量共同组成训练数据集D。
生成训练子集和决策树:在每个类别中,通过采用Bootstrap方法对训练样本进行有放回的随机抽样,重复m次后将获得的m个训练样本共同形成训练数据集D的训练数据子集D
节点分裂:在决策树每个节点分裂时,随机在N个属性中的选取n个碳排放影响指标作为当前节点分裂的子集,需满足n<<N。通过采用分类与回归树(Classification AndRegression Tree,CART)方法,在分裂子集中根据“平方误差最小准则”,选择最优结果的1个碳排放影响指标X
生成随机森林:分裂结束后的各个决策树组合在一起,构成随机森林。
预测碳排放量:将预测集中的参数向量feature输入到训练好的模型中,每颗决策树T
本发明解决了县域下的碳排放量预测问题,不同于传统的碳排放解决方案,本发明采取的基于多特征的随机森林预测算法具有更速度、更高的准确度、更强的泛化能力的优点,能更好地预防碳排放超标问题。通过本发明,可以对碳排放高的县域进行观测,并对碳排放高的方面进行有效管理。本发明根据回归任务的相关评价函数,使用均方误差(MeanSquared Error,MSE)、平均绝对误差(Mean Absolute Error,MAE)指标来评估模型的碳排放预测能力。公式如下:
其中,O
为了验证模型的预测能力,本发明对比了逻辑回归(Logistic Regression,LR)算法、最小绝对收缩和选择算法(Least Absolute Shrinkage and Selection Operator,LASSO)算法、支持向量回归(Support Vector Regression,SVR)算法。如表1所示,实验结果表明,RF算法在MSE和MAE指标上与其他方法相比取得了最佳的效果。
表1实验结果对比
本领域技术人员应理解,以上实施例仅是示例性实施例,在不背离本申请的精神和范围的情况下,可以进行多种变化、替换以及改变。
- 一种基于随机森林的县域碳排放的预测方法
- 一种基于空间异质特征的县域尺度森林病虫害预测方法