一种图片文字识别方法
文献发布时间:2023-06-19 12:19:35
技术领域
本发明涉及一种图片文字识别方法,属于计算机技术领域。
背景技术
现在已经进入了信息时代,管理数据不再是简单的在纸上记录信息,而是在计算机中录入,但是录入数据却是个费事费力的工作。尤其是和图书有关的信息,图书的信息有很多,既要拍摄图书的封面、封底、版权页、目录的图片,又要录入书名、书号、定价、作者、出版社、出版时间、中图分类、关键字、长、宽、高、印次、印张等文字信息。因此在录入这些数据时要花费大量的时间和人力。
发明内容
本发明所要解决的技术问题在于提供一种图片文字识别方法,通过识别图片中的文字信息,并且完成自动录入,缩短录入图书中有关数据的时间,节省大量的人力耗费。
为实现上述技术目的,本发明采用以下技术方案:
一种图片文字识别方法,其特征在于,包括:
100:训练图片识别模型,用来从众多图片中将图片分类,找出其中的版权页图片。
101:识别版权页图片中的文字,把文字从图片中提取出来。
102:将提取出来的文字格式化,转换为系统可识别的数据。
103:将数据与系统绑定,人工校验数据准确性,可以拖动、直接修改数据,最终保存数据。
其中较优地,所述步骤100包括:
S1:预先整理待训练模型的数据;
S2:使用整理好的数据训练图片识别模型;
S3:使用模型来识别图片类型。
其中较优地,所述S2步骤中,使用机器学习来训练模型,并且生成的模型只能来识别对应类型图片。
其中较优地,所述步骤101包括:
使用OCR技术,识别版权页中的文字,并按行输出。
其中较优地,所述步骤102包括:
格式化版权页中各项数据,并按照数据类型、数据值输出。
其中较优地,按照标题关键字识别数据类型。
其中较优地,按照不同数据的特征识别对应的值。
其中较优地,所述步骤103包括:
同屏展示图片和可以识别的数据;
图片上标记出可以匹配到系统中的数据;
可以使用鼠标拖动,将图片上没匹配到的数据绑定到系统对应的文本框中;
可以人工修改系统中各数据的结果并进行保存。
本发明具有以下技术效果:本发明提出的一种图片文字识别方法,通过识别图片中的文字信息,并且完成自动录入,与现有技术相比,缩短录入图书中有关数据的时间,节省大量的人力耗费。
附图说明
图1为根据本发明一种实施例的图片类别识别的流程示意图;
图2为根据本发明一种实施例的文字格式化流程示意图;
图3为根据本发明一种实施例的整体的架构示意图。
具体实施方式
下面结合附图和具体实施例对本发明的技术内容进行详细具体的说明。
在出版发行领域,以图书为例,如果需要录入图书的相关版权信息,需要打开实体图书,翻到版权页,再将版权页中所有文字人工录入进系统,因为录入项较多,导致人工录入效率慢并且容易出现错误。
针对上述问题,本发明充分考虑到为了减少人工成本、提高效率,提出了一种图片识别方法,同时涉及图片文字识别方法,还涉及一种文字格式化方法。
首先,对本发明各个实施例中涉及或可能涉及的名词/术语进行简单解释:
版权页:版权页是出版物的版权标志,也是版本的记录页,一般位于书名页的背面、封三或书末。在版权页中,按规定应记录书名、著译者、出版者、印刷者、发行者、版次、印次、开本、印张、印数、字数、出版年月、版权期、书号、定价等及其他有关说明事项。版权页是供读者了解图书的出版情况,也是文献著录的重要信息源之一。尤其随着文献工作标准化事业的发展,在版编目(CIP)的推行,版权页的记录内容也将有所增加,例如分类号、主题词以及反映该书的款目等。
模型:全称叫做机器学习模型,它是一个文件,在经过训练后可以识别特定类型的模式。可以对一组数据进行模型训练,为它提供一种算法,该算法可用于对这些数据进行推理并从中进行学习。对模型进行训练后,可以使用它根据之前未见过的数据进行推理,并对这些数据进行预测。
GPU:指的是图形处理器,因为设计理念和工作方式与CPU的不同,天生善于大量计算,相较于CPU,使用GPU训练模型速度会提升数十倍。
文字格式化:就是将一整段文字通过各种方法和手段,提取其中需要的内容、摒弃无用的内容,最终变成程序可以识别的信息。
正则表达式:又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。
图1是根据本发明一种图片类型的识别方法的流程示意图。参照图 1,所述方法包括:
100:整理模型训练所需要的数据。
要识别图片的类型需要一批已经分好类的图片,用这些图片来训练模型,在本实例中,就是将图片打上标记,用来指示图片是封面、封底、版权页、目录、条形码中的哪一种。用于训练的数据量越大,模型越准确,所以整理的数据越多越好。
101:使用整理好的数据进行训练
使用100步骤中整理好的数据,进行模型训练,此步骤需要进行大量计算,使用性能较高机器可以明显降低训练时间,尤其是有高性能GPU的情况下尤其明显。经过训练后会产生一个模型文件,这个文件可以预测与训练数据相似的图片类型。
102:验证训练完魔性的准确性
模型训练完成后,需要对模型的准确性进行验证,对于此实例,就是从100步骤中整理好的数据中拿出一部分图片作为输入,看模型预测的类型和实际类型是否一样,最后统计预测正确的数量占所有验证数据的占比就为模型的准确率,如果准确率较高则代表模型质量比较好可以使用,反之,就需要调整参数、增加训练数据规模来提高准确性。
103:生成最终的模型。
重复102步骤,直到准确率满意以后即可将模型保存下来,供以后识别使用。
图2是根据本发明一种实施例的文字格式化流程示意图。参照图2,所述方法包括:
100:按照标题关键字分割。
图书版权页中部分信息会有标题,可以通过标题来识别具体是哪个信息,比如,作者的标题一般为:作者、著者、著。书名的标题一般为书名、题名、标题等。通过这些关键字可以识别一部分信息。
101:处理特殊字符
通过100步骤处理后还是有些数据无法识别,这时就需要数据的特征进行识别,但是识别前需要先处理下特殊字符将格式进行统一,方便后续的识别,例如开本中宽和高两个数据有些是用乘号x有的是用的符号点.这个步骤里会把他们的格式进行统一。
102:按照数据类型特征进行匹配
在101步骤将特殊字符统一以后就可以按照不同的特征提取出对应的数据,比如开本一定是长和宽在一起,并且长、宽的单位都是毫米,中间还有x号间隔,所以可以在整个版权页文字中查找相邻的两个数字,因为书的大小需要在合理的范围内,一本书不会特别小或者特别大,所以这两个数字的大小也有一个合理的范围。根据以上种种特征,就可以在版权页中精确的找到开本。其他类型的数据也相似,都可以通过不同的特征找到对应的数据。
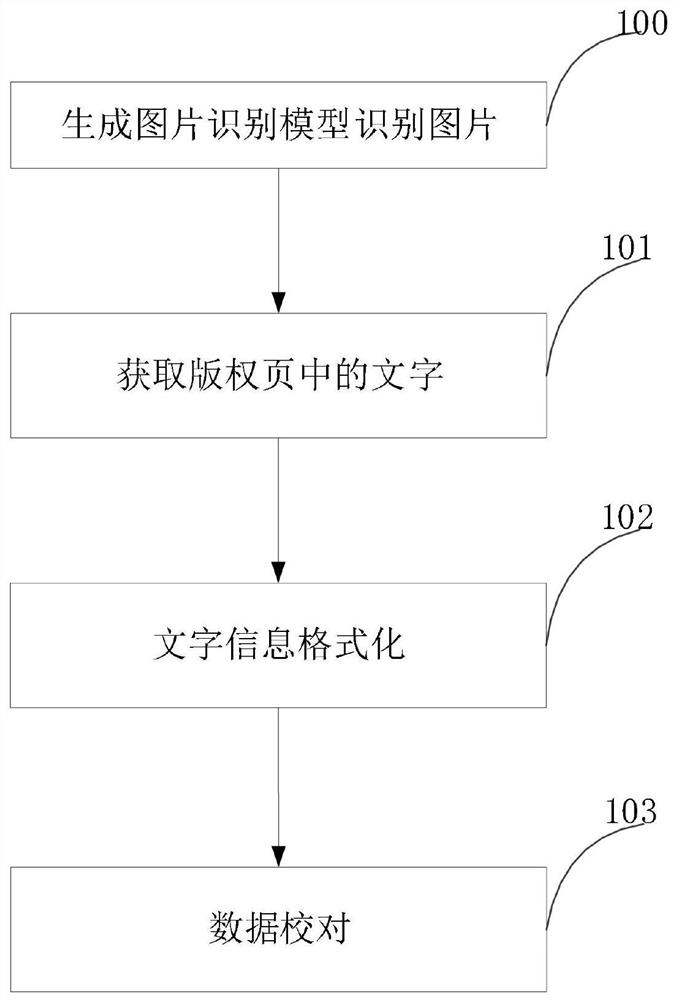
图3是根据本发明一种实施例的整体流程示意图。
100:训练图片识别模型,用来从众多图片中将图片分类,找出其中的版权页图片。
101:识别版权页图片中的文字,把文字从图片中提取出来。
102:将提取出来的文字格式化,转换为系统可识别的数据。
103:将数据与系统绑定,人工校验数据准确性,可以拖动、直接修改数据,最终保存数据。
本发明具有以下技术效果:本发明提出的一种图片文字识别方法,通过识别图片中的文字信息,并且完成自动录入,与现有技术相比,缩短录入图书中有关数据的时间,节省大量的人力耗费。
上面对本发明进行了详细的说明。对本领域的一般技术人员而言,在不背离本发明实质内容的前提下对它所做的任何显而易见的改动,都将构成对本发明专利权的侵犯,将承担相应的法律责任。
- 图片预处理方法、文字识别模型训练方法和文字识别方法
- 一种图片文字识别方法和装置