一种基于机器学习模型的异构数据解析方法、设备及介质
文献发布时间:2023-06-19 12:22:51
技术领域
本申请涉及企业信息化技术领域,尤其涉及一种基于机器学习模型的异构数据解析方法、设备及介质。
背景技术
随着新型互联网技术和大数据技术的广泛应用,企业的信息化发展越来越重视数据资产管理。企业在进行信息化建设时,首要任务就是建立自己的数据管理系统,而数据管理系统的建设,往往涉及各业务系统数据的汇聚。在日常生产经营过程中,企业往往包括多源异构业务系统,例如:人力资源系统(HR)、财务管理系统(FM)、企业资源管理系统(ERP)、产品生命周期管理系统(PLM)、产品数据管理系统(PDM)、供应链管理系统(SCM)、客户关系管理系统(CRM)、制造执行系统(MES)等。
但是,由于管理的数据对象不同,各业务系统的类型、存储格式、数据通讯协议差异较大。例如,这些系统分别存储了外网爬虫数据、内部传感器数据、各系统数据等。为了使这些数据发挥价值,传统的数据抽取在整合多源异构业务系统的过程中,只能对数据进行增减筛选过滤等操作,而机器学习方法只能通过数据科学家编写代码的形式将数据模型和数据进行整合,两端无法更好的融合。并且,由于缺少成熟的工具,在将不同的业务数据进行有效的整合时,需要大量的人力手动逐一排查、分析,造成海量人力成本的产生。
发明内容
本申请实施例提供了一种基于机器学习模型的异构数据解析方法及设备,用以解决现有的机器学习模型无法直接应用于ETL中,因此无法统一多源异构系统中的数据的技术问题。
本申请实施例采用下述技术方案:
一方面,本申请实施例提供了一种基于机器学习模型的异构数据解析方法,包括:将机器学习模型部署至服务器;通过预测模型标记语言,将所述机器学习模型解析为标准格式,并将解析后的机器学习模型按照数据流的方式输出;基于所述解析后的机器学习模型,对待处理异构数据分别进行解析;输出所述待处理异构数据的解析结果。
在本申请的一种实现方式中,将机器学习模型部署至服务器,具体包括:根据数据解析目的,确定待处理异构数据对应的机器学习模型;将所述待处理异构数据对应的机器学习模型部署至服务器。
在本申请的一种实现方式中,所述数据解析目的为数据清洗;基于所述解析后的机器学习模型,对待处理异构数据分别进行解析,具体包括:基于所述解析后的机器学习模型,对待处理异构数据分别进行数据清洗,以去除所述待处理异构数据中的冗余数据。
在本申请的一种实现方式中,基于所述解析后的机器学习模型,对待处理异构数据分别进行解析之前,还包括:确定不同业务分别对应的多个异构系统;从所述多个异构系统的数据源中,分别获取对应的待处理数据,构成待处理异构数据。
在本申请的一种实现方式中,通过预测模型标记语言,将所述机器学习模型解析为标准格式,并将解析后的机器学习模型按照数据流的方式输出,具体包括:基于JAVA的预测模型标记语言,将所述机器学习模型中的参数、字段、算法解析为JSON格式,并将所述JSON格式的机器学习模型按照数据流的方式输出。
在本申请的一种实现方式中,基于所述解析后的机器学习模型,对待处理异构数据分别进行解析,具体包括:设置数据解析组件;基于所述数据解析组件,将所述JSON格式的机器学习模型以异步的方式预置到模型评估器中;通过所述模型评估器,对待处理异构数据分别进行解析。
在本申请的一种实现方式中,基于所述解析后的机器学习模型,对待处理异构数据分别进行解析,具体包括:基于所述解析后的机器学习模型中的映射关系,对待处理异构数据分别进行相应的处理;将处理后的不同格式的所述待处理异构数据,统一为逗号分隔值格式。
在本申请的一种实现方式中,输出所述待处理异构数据的解析结果之后,还包括:根据所述待处理异构数据的解析结果,删除对应异构系统的数据源中的冗余数据。
另一方面,本申请实施例还提供了一种基于机器学习模型的异构数据解析设备,设备包括:处理器;及存储器,其上存储有可执行代码,当可执行代码被执行时,使得处理器执行如上述的一种基于机器学习模型的异构数据解析方法。
再一方面,本申请实施例还提供了一种基于机器学习模型的异构数据解析的非易失性计算机存储介质,存储有计算机可执行指令,计算机可执行指令设置为:如上述任一项的一种基于机器学习模型的异构数据解析方法。
本申请实施例提供了一种基于机器学习模型的异构数据解析方法、设备及介质,至少包括以下有益效果:根据数据解析的目的,确定出待处理异构数据对应的机器学习模型,并将确定出的机器学习模型部署到服务器上,从而提高待处理异构数据的解析效率。基于JAVA的预测模型标记语言,将机器学习模型中的参数、字段和算法解析成JSON格式,以异步的方式预置到模型评估器中,并以数据流的方式输出,以使解析后的机器学习模型对各种结构的数据都能进行解析处理,避免了现有的机器学习模型需要通过人为编写代码,才能将机器学习模型与异构数据整合的问题,从而降低了人力成本。同时,将处理好的异构数据统一为逗号分隔值格式,使统一后的异构数据通用性更强。此外,本申请还可以根据待处理异构数据的解析结果,将异构系统的数据源中的冗余数据删除,从而节省了冗余数据对应异构系统的存储空间。
附图说明
此处所说明的附图用来提供对本申请的进一步理解,构成本申请的一部分,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
图1为本申请实施例提供的一种基于机器学习模型的异构数据解析方法流程图;
图2为本申请实施例提供的一种机器学习模型输入图;
图3为本申请实施例提供的另一种基于机器学习模型的异构数据解析方法流程图;
图4为本申请实施例提供的一种具体的基于机器学习模型的异构数据解析方法流程图;
图5为本申请实施例提供的一种基于机器学习模型的异构数据解析设备内部结构示意图。
具体实施方式
为使本申请的目的、技术方案和优点更加清楚,下面将结合本申请具体实施例及相应的附图对本申请技术方案进行清楚、完整地描述。显然,所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
本申请实施例提供了一种基于机器学习模型的异构数据解析方法、设备及介质,根据数据解析目的,确定出待处理异构数据对应的机器学习模型后,基于JAVA的预测模型标记语言,将确定出的机器学习模型中的参数、字段、算法解析为标准格式,以数据流的方式输出,并且基于解析后的机器学习模型,对待处理异构数据进行清洗,以去除待处理异构数据中的冗余数据,同时,还将处理好的异构数据统一为逗号分隔值格式,用以解决现有的机器学习模型无法直接应用于数据仓库技术(ExtractTransformLoad,ETL)中,因此无法统一多源异构系统中的数据的技术问题。
下面通过附图对本申请实施例提出的技术方案进行详细的说明。
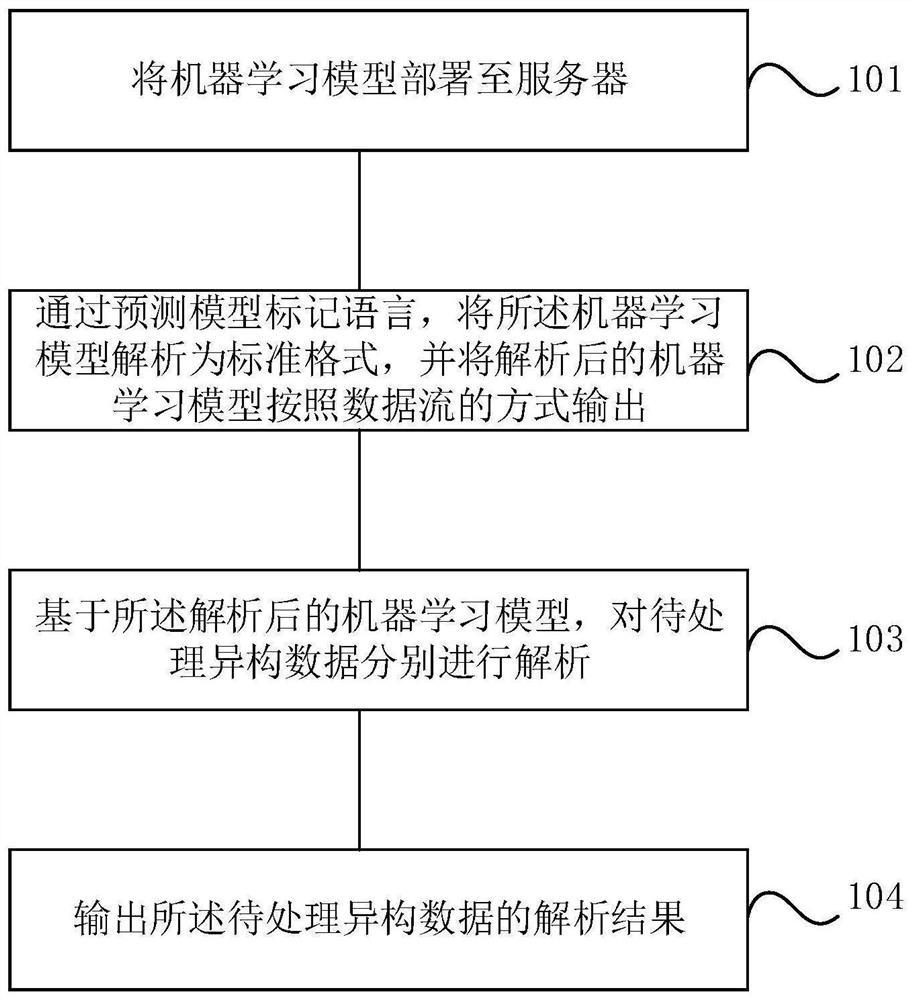
图1为本申请实施例提供的一种基于机器学习模型的异构数据解析方法流程图。如图1所示,本申请实施例提供的基于机器学习模型的异构数据解析方法主要包括以下步骤:
S101、将机器学习模型部署至服务器。
服务器将待处理异构数据对应的机器学习模型部署至服务器,以便执行后续步骤。
在本申请的一个实施例中,服务器在确定好需要进行处理的异构数据之后,根据数据解析的目的,确定出处理当前待处理异构数据所需的机器学习模型,并将确定出来的待处理异构数据对应的机器学习模型部署到服务器上,以便于执行后续的异构数据解析操作。本申请根据待处理异构数据的解析目的,确定出待处理异构数据对应的机器学习模型,以便于在进行异构数据解析操作时,可以提高数据解析的准确率。
图2为本申请实施例提供的一种机器学习模型输入图。如图2所示,服务器根据待处理的异构数据,确定出待处理异构数据对应的机器学习模型的分类,然后从本地的众多机器学习模型中确定出待处理异构数据对应的机器学习模型的文件,将其输入并部署至服务器上。
S102、通过预测模型标记语言,将所述机器学习模型解析为标准格式,并将解析后的机器学习模型按照数据流的方式输出。
服务器通过预测模型标记语言(Predictive Model Markup Language,PMML),将服务器上部署的机器学习模型解析为当前待处理异构数据对应的标准格式,并且将解析后的机器学习模型按照数据流的方式输出。
在本申请的一个实施例中,服务器基于JAVA的预测模型标记语言,将待处理异构数据对应的机器学习模型中的参数、字段以及算法都解析为JSON格式,并将解析后JSON格式的机器学习模型按照数据流的方式输出,从而输出JSON格式的模型流,可以使机器学习模型应用于ETL中,对待处理的异构数据进行解析,从而减少了人力资源的浪费。
S103、基于所述解析后的机器学习模型,对待处理异构数据分别进行解析。
服务器基于解析后JSON格式的机器学习模型,对待处理异构数据分别进行解析,这样可以使现有的机器学习模型以JSON格式模型流的形式对待处理的异构数据进行解析,从而将异构系统中的异构数据统一,避免了机器学习模型需要通过人为编写代码,才能将机器学习模型与异构数据整合的问题,同时降低了人力成本。
在本申请的一个实施例中,数据解析的目的是数据清洗。服务器基于解析后JSON格式的机器学习模型,对待处理异构数据分别进行数据清洗,以去除当前待处理异构数据中的冗余数据,从而保证统一后的异构数据的质量,同时节省了异构数据的存储空间。
在本申请的一个实施例中,服务器确定出不同业务对应的多个异构系统,并根据处理需要,从多个异构系统的数据源中,分别获取出异构系统对应的待处理数据,从而构成了待处理异构数据。
在本申请的一个实施例中,服务器设置数据解析组件,并基于数据解析组件,通过线程异步的方式,将JSON格式的机器学习模型预置到模型评估器中,从而通过模型评估器对待处理的异构数据分别进行解析。本申请通过数据解析组件将解析后JSON格式的机器学习模型预置到模型评估器中,通过模型评估器对待处理的异构数据进行解析,从而使机器学习模型可以用于ETL中,统一异构系统的数据源中的异构数据,降低了人为调整机器学习模型时所产生的成本。
在本申请的一个实施例中,服务器基于解析后JSON格式的机器学习模型中的映射关系,对待处理异构数据分别进行相应的处理,并将处理后不同格式的异构数据统一为逗号分隔值(Comma Separated Values,CSV)格式,这样可以使统一后的异构数据通用性更强,管理起来也更加便捷。
S104、输出所述待处理异构数据的解析结果。
服务器通过数据解析组件,继续输出待处理异构数据的解析结果。
在本申请的一个实施例中,服务器根据待处理异构数据的解析结果,检查待处理异构数据对应的异构系统的数据源,并将待处理异构数据对应的异构系统的数据源中的冗余数据删除。这样,可以根据异构数据的统一过程中确定并删除的冗余数据,更快捷的找到冗余数据对应的异构系统,并将对应异构系统的数据源中的冗余删除,从而节省出冗余数据对应的异构系统的数据源的存储空间。
图3为本申请实施例提供的另一种基于机器学习模型的异构数据解析方法流程图。如图3所述,服务器从表输入2对应的异构系统的数据源中,确定出待处理的异构数据,从模型输入1对应的多种机器学习模型中,确定出当前待处理异构数据对应的机器学习模型的文件,并将确定好的机器学习模型的文件部署至服务器,然后在解析1中,通过解析后JSON格式的机器学习模型,对待处理异构数据进行解析,根据当前异构数据的解析目的,去除待处理异构数据中的冗余数据,并将去除冗余数据之后的异构数据统一为逗号分隔值格式,最后在表输出1位置通过数据解析组件输出。
图4为本申请实施例提供的一种具体的基于机器学习模型的异构数据解析方法流程图。如图4所示,基于机器学习模型的异构数据解析提供两条数据流输入,一条是通过模型上传、模型解析、模型输出三个步骤解析出来的模型流,另外一条是正常输入的待处理异构数据的数据流。当服务器开始运行时,通过异步的方式,将基于JAVA的预测模型标记语言解析为JSON格式的待处理异构数据预置到模型评估器中,通过模型评估器对待处理的异构数据分别进行清洗,将待处理异构数据中的冗余数据删除,同时,服务器将处理后的异构数据统一为CSV格式,然后,由数据解析组件将统一后的异构数据以数据流的方式输出,完后基于机器学习模型的异构数据的解析。
需要说明的是,图3、图4所示的方法与图1所示的方法本质相同,因此,图3、图4中未详述的部分,具体可参照图1中的相关描述,本申请在此不再赘述。
本申请实施例提供了一种基于机器学习模型的异构数据解析方法、设备及介质,服务器根据数据解析的目的,确定出当前待处理异构数据对应的机器学习模型,并将确定出的机器学习模型部署到服务器上,从而提高待处理异构数据的解析效率。基于JAVA的预测模型标记语言,服务器将机器学习模型中的参数、字段和算法解析成JSON格式,以异步的方式预置到模型评估器中,并以数据流的方式输出,以使解析后的机器学习模型对各种结构的数据都能进行解析处理,避免了现有的机器学习模型需要通过人为编写代码,才能将机器学习模型与异构数据整合的问题,从而降低了人力成本,同时,服务器还可以将处理好的异构数据统一为逗号分隔值格式,使统一后的异构数据通用性更强。此外,服务器还可以根据待处理异构数据的解析结果,将异构系统的数据源中的冗余数据删除,从而节省了冗余数据对应异构系统的存储空间。
以上为本申请提出的方法实施例。基于同样的发明构思,本申请实施例还提供了一种基于机器学习模型的异构数据解析设备,其结构如图5所示。
图5为本申请实施例提供的一种基于机器学习模型的异构数据解析设备内部结构示意图。如图5所示,设备包括处理器501、及存储器502,其上存储有可执行代码,当可执行代码被执行时,使得处理器501执行如上的一种基于机器学习模型的异构数据解析方法。
在本申请的一个实施例中,处理器501用于将机器学习模型部署至服务器;以及用于通过预测模型标记语言,将机器学习模型解析为标准格式,并将解析后的机器学习模型按照数据流的方式输出;还用于基于解析后的机器学习模型,对待处理异构数据分别进行解析;还用于输出待处理异构数据的解析结果。
本申请实施例还提供了一种基于机器学习模型的异构数据解析的非易失性计算机存储介质,存储有计算机可执行指令,计算机可执行指令设置为:如上的一种基于机器学习模型的异构数据解析方法。
本申请中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于设备和介质实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
本申请实施例提供的设备和介质与方法是一一对应的,因此,设备和介质也具有与其对应的方法类似的有益技术效果,由于上面已经对方法的有益技术效果进行了详细说明,因此,这里不再赘述设备和介质的有益技术效果。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
在一个典型的配置中,计算设备包括一个或多个处理器(CPU)、输入/输出接口、网络接口和内存。
内存可能包括计算机可读介质中的非永久性存储器,随机存取存储器(RAM)和/或非易失性内存等形式,如只读存储器(ROM)或闪存(flash RAM)。内存是计算机可读介质的示例。
计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(PRAM)、静态随机存取存储器(SRAM)、动态随机存取存储器(DRAM)、其他类型的随机存取存储器(RAM)、只读存储器(ROM)、电可擦除可编程只读存储器(EEPROM)、快闪记忆体或其他内存技术、只读光盘只读存储器(CD-ROM)、数字多功能光盘(DVD)或其他光学存储、磁盒式磁带,磁带磁磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括暂存电脑可读媒体(transitory media),如调制的数据信号和载波。
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、商品或者设备中还存在另外的相同要素。
以上所述仅为本申请的实施例而已,并不用于限制本申请。对于本领域技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本申请的权利要求范围之内。
- 一种基于机器学习模型的异构数据解析方法、设备及介质
- 基于机器学习模型的数据处理方法、装置、设备和介质