信息处理方法、信息处理系统和计算机可读记录介质
文献发布时间:2023-06-19 12:27:31
技术领域
本文讨论的实施方式涉及信息处理方法、信息处理系统和记录介质。
背景技术
现代社会的各个领域存在组合优化问题。例如,在诸如制造、分配和销售的领域中搜索用于使成本最小化的元素的组合。然而,组合优化问题的计算时间随着与元素相对应的变量的数量增加而指数地增加,并且因此,组合优化问题被认为是难以用冯诺依曼计算机求解的问题。
存在作为求解组合优化问题的方法的如下方法:该方法通过用伊辛模型替换计算目标的组合优化问题来执行计算,伊辛模型是表示磁性物质的自旋(spin)行为的模型。例如,马尔可夫链蒙特卡洛方法例如模拟退火(SA)和副本交换方法被用来搜索使伊辛能量函数的值最小化或最大化的变量的值的组合。使能量函数的值最小化或最大化的变量的值的组合对应于基态或最优解。利用马尔可夫链蒙特卡洛方法,可以在合理量的时间内获得组合优化问题的最优解或者接近最优解的近似解。
例如,已经提出了一种用于搜索离散优化问题的最优解的搜索方法。所提出的搜索方法包括:如果许多改进的解可能在当前解的附近,则关注在当前解的附近的搜索,如果改进的解不太可能在当前解的附近,则执行宽范围的搜索以避免解被困在局部解处。
已经提出了一种信息处理设备,其基于遗传算法,通过对具有与相似试验处理相对应的基因的成组个体执行交叉、变异和选择来创建新基因。所提出的信息处理设备基于试验处理过程中的时间点处的特征,对在试验处理过程中可能涉及相似现象的个体进行分组。这保证了由于组内的选择而存活的组中的代表性个体的多样性。作为结果,新生成的个体的多样性得以保持。
例如,在日本公开特许公报第2001-117773号和日本公开特许公报第2016-12285号中公开了相关技术。
当通过SA等搜索到的解被困在局部解处时,脱离处于局部解附近的状态是困难的,并且因此可能无法获得最优解。
例如,用于搜索更多状态以获得更好的解的可能解决方案可以包括:将向计算机等提供随机确定的初始状态并通过SA等获得解的处理重复预定次数;以及选择由此获得的解中的最佳解。然而,该方法不一定会导致达到最优解的可能性充分增加。
实施方式的一个方面的目的是,提供能够增加达到最优解的可能性的信息处理设备、程序、信息处理方法和信息处理系统。
发明内容
根据实施方式的一方面,一种信息处理系统,包括:处理单元,用于:获取多个解,每个解由包括在能量函数中的多个变量的值表示;基于多个解和分别与多个解对应的能量函数的值,针对多个变量中的变量和所述变量的候选值的多个集合中的每个集合来计算指标,所述指标指示与特定变量相对应的特定候选值被包括在比当前获得的解更好的解中或者被包括在最优解中的概率;以及基于针对多个集合中的每个集合计算出的指标从多个集合中选择一个集合;以及输出单元,用于输出在包括在所选择的一个集合中的变量被固定至对应候选值的情况下执行对其他解的其他搜索的指令。
一个方面可以增加达到最优解的可能性。
附图说明
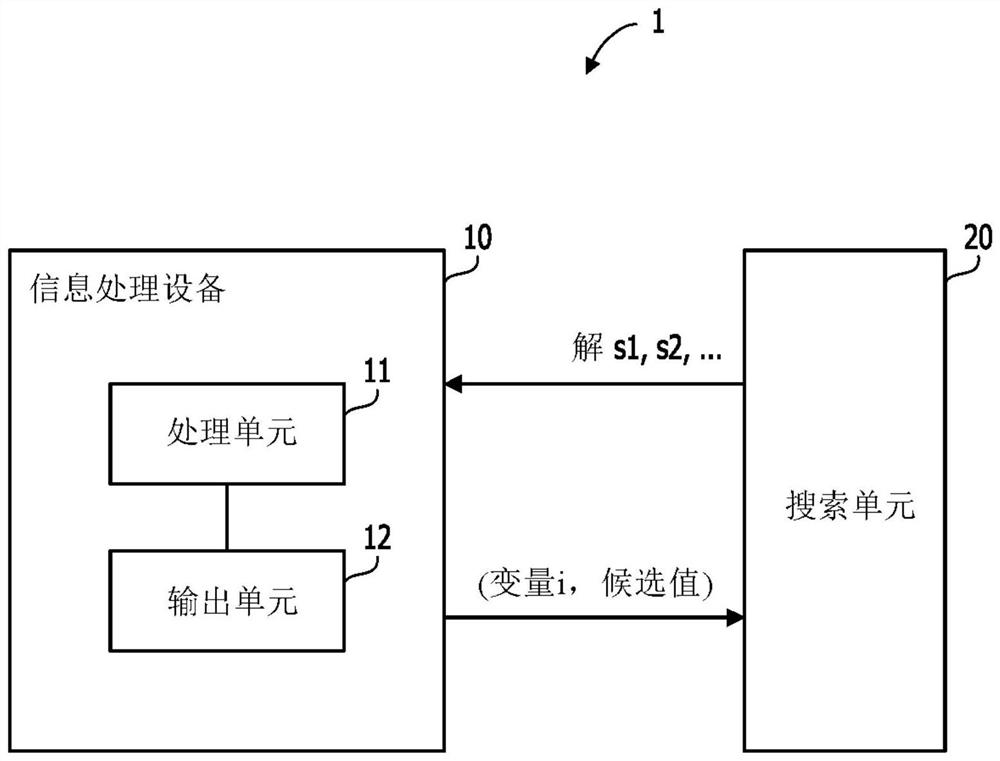
图1是示出根据第一实施方式的信息处理设备的处理的示例的图;
图2是示出根据第二实施方式的信息处理系统的硬件示例的图;
图3是示出信息处理设备的功能的示例的图;
图4是示出初始设置表的示例的图;
图5是示出变量固定控制表的第一示例的图;
图6是示出变量固定控制表的第二示例的图;
图7是示出信息处理设备的处理的示例的流程图;
图8是示出权重与偏置之间的关系的示例的图;以及
图9是示出比较例的流程图。
具体实施方式
在下文中,将参照附图描述实施方式。
[第一实施方式]
将描述第一实施方式。
图1是示出根据第一实施方式的信息处理设备的处理的示例的图。
信息处理系统1包括信息处理设备10和搜索单元20。信息处理设备10耦接至搜索单元20。基于通过公式化组合优化问题获得的伊辛能量函数,搜索单元20使用马尔可夫链蒙特卡洛方法例如SA或副本交换方法来搜索由包括在能量函数中的多个变量的值所表示的最优解。变量是二进制值或更高阶离散值。能量函数表示由多个变量的值表示的伊辛模型的状态的能量值,并且能量函数也被称为评价函数或目标函数。搜索单元20输出作为搜索结果的解。所述解包括多个变量的值。可以存在多个搜索单元20。
信息处理设备10包括处理单元11和输出单元12。
处理单元11从搜索单元20获取多个解。基于多个解和与多个解对应的能量函数的值,处理单元11针对变量和候选值的每个集合,计算指示特定变量的特定候选值包括在解中的概率的指标。处理单元11将计算出的指标存储在信息处理设备10中所包括的存储单元(未示出)例如存储器中。
“指示特定变量的特定候选值被包括在解中的概率的指标”中的“解”指示按照预定评价尺度比当前获得的解更好的解。针对使能量值最小化的问题,例如,这样的解是具有较小能量函数值的解。“指示特定变量的特定候选值被包括在解中的概率的指标”中的“解”可以是组合优化问题的最优解。
基于针对变量和候选值的每个集合的指标,处理单元11选择固定至候选值的变量和候选值。例如,用于基于上述指标选择固定至候选值的变量和候选值的可能方法如下。
首先,处理单元11向搜索单元20设置对应于组合优化问题的实例信息,并使搜索单元20执行解搜索。实例信息可以包括诸如能量函数中包括的变量之间的权重、变量的偏置和常数项的信息。任何适当的状态可以被设置为搜索开始时的初始状态。例如,处理单元11可以随机地确定初始状态下的每个变量的值。然而,如稍后所述,处理单元11可以指示搜索单元20将特定变量固定至初始状态下的特定值。
处理单元11获取由搜索单元20所获得的解s1、s2……。解s1、s2……是例如针对不同初始状态所获得的解。当存在多个搜索单元20时,处理单元11可以向多个搜索单元提供不同的初始状态,使多个搜索单元并行地执行解搜索,并从多个搜索单元获取解s1、s2……。此外,在以下描述的解搜索中,处理单元11可以类似地使用多个搜索单元。在并行使用多个搜索单元的情况下,可以迅速地获取解s1、s2……。
处理单元11获取对应于解s1、s2……中的各解的能量值。处理单元11可以通过将解s1、s2……中的每个解代入能量函数来计算与解对应的能量值,或者可以从搜索单元20获取能量值以及解s1、s2……中的每个解。
处理单元11针对变量和变量的值的每个集合,获取与包括特定变量的值的解之中的最佳解相对应的能量值。针对使能量值最小化的问题,该“与包括特定变量的值的解之中的最佳解相对应的能量值”是其中对应变量具有对应值的解的能量值中的最小能量值。相比之下,针对使能量值最大化的问题,该能量值是其中对应变量具有对应值的解的能量值中的最大能量值。
基于针对变量和变量的值的每个集合获取的与最佳解对应的能量值与针对每个集合获取的最佳解的能量值之中的最差能量值的比率,处理单元11计算指示对应变量的对应值包括在比当前获得的解更好的解中的概率的指标。
例如,在使能量值最小化的问题中,Emax被假设为针对变量和变量的值的各个集合获取的最小能量值中的最大值(最差值),E被假设为针对相应变量和相应变量的相应值获取的最小能量值。在这种状况下,处理单元11如P=1-E/Emax那样获得指示相应变量的相应值被包括在比当前获得的解更好的解中的概率的指标P。
可替选地,在使能量值最大化的问题中,Emin被假设为针对变量和变量的值的各个集合获取的最大能量值中的最小值(最差值),E被假设为针对相应变量和相应变量的相应值获取的最大能量值。在这种状况下,处理单元11如P=1-Emin/E那样获得指示相应变量的相应值被包括在比当前获得的解更好的解中的概率的指标P。
在这种情况下,指标P表示作为将相应变量设置为相应值的结果的解相对于针对变量和变量的值的各个集合的解中的最差解的改善水平。对于较大的指标P,例如,较高的解改善水平,预期相应变量的相应值在比当前获得的解更好的解中的概率较高。
用于计算指示相应变量的相应值被包括在更好的解中的概率的指标的方法不限于上述方法,并且可以使用各种方法。例如,处理单元11可以获得指标,其中,较小的指标值导致:预期相应变量的相应值被包括在比当前获得的解更好的解中的概率较高。
处理单元11基于针对变量和变量的值的每个集合获得的指标,选择要固定至特定候选值的变量和候选值。例如,处理单元11优先选择具有大指标P的变量和变量的值的集合。处理单元11可以按照指标P的降序选择变量和变量的值的集合。
输出单元12向搜索单元20输出用于在将由处理单元11选择的变量固定至所选择的候选值的情况下执行搜索的指令。例如,输出单元12将所选择的变量的标识信息i和候选值输出至搜索单元20。
输出单元12可以将用于在整个搜索时段中将对应变量固定至对应候选值的情况下执行搜索的指令输出至搜索单元20,或者可以将用于在搜索时段的一部分中将对应变量固定至对应候选值的情况下执行搜索的指令输出至搜索单元20。在后一种情况下,例如,输出单元12可以向搜索单元20输出用于在等于或长于整个搜索时段的预定百分比的时段内将对应变量固定至对应候选值的情况下执行搜索的指令。
搜索单元20根据从信息处理设备10接收到的指令,确定下次解搜索的初始状态,并开始下次解搜索。搜索单元20在将包括在指示集合中的变量固定至候选值的情况下执行解搜索。例如,搜索单元20针对被执行多次的解搜索中的每个解搜索从信息处理设备10获取被固定至候选值的变量和候选值的不同集合,从而生成与各集合对应的解。因此,搜索单元20生成与多个相应集合相对应的多个解。
处理单元11从搜索单元20获取多个解,并通过与上述过程相同的过程来更新指示变量和变量的值的每个集合被包括在解中的概率的指标。处理单元11可以获得针对两个或更多个变量和两个或更多个变量的值的集合的指标。例如,处理单元11可以基于指标选择第一变量、第一变量的第一候选值、第二变量和第二变量的第二候选值的集合。在这种情况下,输出单元12向搜索单元20输出用于在第一变量被固定至第一候选值并且第二变量被固定至第二候选值的情况下执行搜索的指令。搜索单元20在第一变量和第二变量被分别且同时固定至第一候选值和第二候选值的情况下执行搜索。
信息处理设备10和搜索单元20重复上述过程,并且当满足预定终止条件时终止处理。例如,当从初始解搜索开始起经过了特定时间段时,当获得与比特定能量值更好的能量值相对应的解时等,满足终止条件。处理单元11获取在一系列过程中获取的解中的最佳解作为最终解,并且向用户通知作为最终解的最佳解。
利用信息处理设备10,可以增加达到最优解的可能性。
当使用SA、副本交换方法等搜索到的解被困在局部解处时,脱离处于局部解附近的状态是困难的,并且因此可能无法获得最优解。
鉴于此,例如,用于搜索更多状态以获得更好的解的可能解决方案可以包括:重复向搜索单元20提供随机确定的初始状态以获得解的处理;以及选择由此获得的解中的最佳解。不幸的是,即使当通过被提供了随机确定的初始状态的搜索单元20重复获得解时,达到最优解的可能性也未必充分增加。原因如下。
对由能量函数获得的能量值的影响的大小在变量之间变化。例如,作为将特定变量设置为特定值的结果的能量值的变化可能大于作为将另一变量设置为特定值的结果的变化。变量之间的影响的大小的差异在问题之间变化。这将用背包问题进行例示。
背包问题是获得放入背包中的物品的组合中产生最大总价值的组合的问题,所述背包具有关于内容物的重量或体积等的容量上限C。存在多个物品。假设w
例如,使用w
作为一个示例,考虑如下情况:在所有物品之间价值是相同的,例如,v
取决于问题,如上述背包问题的示例中那样,由于将不包括在最优解中的变量的特定值,因此由被提供了随机确定的初始状态的搜索单元20重复获得的解相对可能被困在局部解处,并且脱离局部解可能是困难的。
信息处理设备10对指示变量和变量的候选值的每个集合被包括在较好的解中的概率的指标进行评价,并且基于该指标,向搜索单元20指定其候选值被优先于其他值而设置的变量和该候选值。这导致在反映——被预期具有相对高的包括在较好的解中的可能性的——变量和候选值的集合的状态下执行搜索单元20的搜索的可能性更高,由此可以增加达到最优解的可能性。
如上所述,处理单元11可以指示搜索单元20在初始状态下使特定变量固定至特定值,以求解当前组合优化问题。例如,可能存在这样的情况:基于关于与当前组合优化问题的领域类型相同的领域的知识、过去对属于类似类型的领域的问题的解搜索的结果等,通过用户分析预先认识到的是,特定变量可能具有在当前问题的最优解中的特定值。可替选地,处理单元11可以基于各变量的值对能量函数施加的影响的程度预先认识到,特定变量可能具有在当前问题的最优解中的特定值。
处理单元11可以通过接收用户输入的特定变量和特定值,或者通过经由处理单元11的分析获取特定变量和特定值,来向搜索单元20指定在初始状态下将特定变量固定至的特定值。此后,处理单元11重复第一实施方式中例示的过程,从而更新指示该特定变量的特定值被包括在更好的解中的概率的指标。
处理单元11由集成电路例如中央处理单元(CPU)、数字信号处理器(DSP)、专用集成电路(ASIC)、现场可编程门阵列(FPGA)来实现。处理单元11可以是执行程序的处理器。本文中涉及的“处理器”可以包括多个处理器的集合(多处理器)。
搜索单元20可以由通过使用数字电路执行SA、副本交换方法等的硬件来实现,或者可以由执行量子退火的硬件来实现。执行SA、副本交换方法或量子退火的硬件可以被称为优化设备。搜索单元20可以由处理器例如信息处理设备10的CPU实现,或者可以由与处理器例如信息处理设备10的CPU不同的处理器实现。
输出单元12由IO接口实现,该IO接口进行去往/来自搜索单元20内的存储器或者搜索单元20参照的信息处理设备10内的存储器的输入/输出(IO)。在搜索单元20由经由网络耦接的其他装置实现的情况下,输出单元12可以由诸如网络接口卡(NIC)的通信接口实现。
[第二实施方式]
接下来将描述第二实施方式。
图2是示出根据第二实施方式的信息处理系统的硬件示例的图。
信息处理系统50包括信息处理设备100和优化设备200。
信息处理设备100包括CPU 101、随机存取存储器(RAM)102、硬盘驱动器(HDD)103、IO接口104、图像信号处理单元105、输入信号处理单元106、介质读取器107和NIC 108。CPU101对应于根据第一实施方式的处理单元11。IO接口104与根据第一实施方式的输出单元12相对应。
CPU 101是执行程序的命令的处理器。CPU 101将存储在HDD 103中的程序或数据的至少一部分加载到RAM 102中并且执行该程序。CPU 101可以包括多个处理器核。信息处理设备100可以包括多个处理器。在一些情况下,多个处理器的集合将被称为“多处理器”或者仅被称为“处理器”。
RAM 102是易失性半导体存储器,其暂时存储由CPU 101执行的程序和用于由CPU101进行的操作的数据。信息处理设备100可以包括除了RAM以外的多种类型的存储器,并且可以包括多个存储器。
HDD 103是存储数据以及诸如操作系统(OS)、中间件和应用软件的软件程序的非易失性存储装置。信息处理设备100可以包括诸如闪速存储器和固态驱动器(SSD)的其他类型的存储装置,并且可以包括多个非易失性存储装置。
IO接口104耦接至优化设备200,并且根据来自CPU 101的指令向优化设备200输入数据和从优化设备200输出数据。例如,IO接口104根据来自CPU 101的指令,将RAM 102中的数据写入优化设备200的寄存器或存储器,以及从优化设备200读取数据并将数据写入RAM102。例如,使用高速外围部件互连(PCI-e)等作为IO接口104。
图像信号处理单元105根据来自CPU 101的命令将图像输出至与信息处理设备100耦接的显示器111。可以使用任何类型的显示器(例如阴极射线管(CRT)显示器、液晶显示器(LCD)、等离子显示器或有机电致发光(OEL)显示器)作为显示器111。
输入信号处理单元106从耦接至信息处理设备100的输入装置112获取输入信号,并且将输入信号输出至CPU 101。可以使用定点装置(例如,鼠标、触摸面板、触摸板或轨迹球、键盘、远程控制器、按钮开关等)作为输入装置112。多种类型的输入装置可以耦接至信息处理设备100。
介质读取器107是读取记录在记录介质113中的程序和数据的读取装置。可以使用例如磁盘、光盘、磁光盘(MO)、半导体存储器等作为记录介质113。磁盘包括软盘(FD)或HDD。光盘包括致密盘(CD)或数字多功能盘(DVD)。
介质读取器107例如将从记录介质113读取的程序和数据复制到另一记录介质例如RAM 102或HDD 103。通过例如CPU 101执行读取的程序。记录介质113可以是便携式记录介质,或者可以用于分发程序或数据。记录介质113和HDD 103可以被称为计算机可读记录介质。
NIC 108耦接至网络60,并且是经由网络60与另一计算机进行通信的接口。例如,NIC 108利用线缆耦接至网络60中包括的通信装置,例如,交换机或路由器。
优化设备200是加速器,该加速器基于通过公式化组合优化问题而获得的能量函数,利用硬件执行使用SA或副本交换方法的基态搜索。优化设备200通过使用例如半导体集成电路例如FPGA来实现。优化设备200可以被称为伊辛机、伊辛优化设备等。优化设备200可以是使用量子退火执行基态搜索的硬件。优化设备200可以由与信息处理设备100具有相同的配置的另一信息处理设备来实现。
优化设备200包括搜索单元210、211、212……。搜索单元210、211、212……使用SA、副本交换方法等来搜索基态。优化设备200还可以包括控制单元,其控制搜索单元210、211、212……的基态搜索的执行以及与信息处理设备100的通信。
替代优化设备200,CPU 101可以执行预定软件以实现执行SA、副本交换方法、模拟量子退火(SQA)等的搜索单元20的功能。
图3是示出信息处理设备的功能的示例的图。
信息处理设备100包括存储单元120、概率更新单元130和变量固定控制单元140。使用RAM 102或HDD 103的存储区域作为存储单元120。概率更新单元130和变量固定控制单元140由程序实现。
存储单元120存储用于由概率更新单元130和变量固定控制单元140执行的处理的数据。存储单元120存储初始设置表和变量固定控制表。
初始设置表是登记有指示候选变量和候选值的组合被包括在最优解中的概率的指标的初始值的表。指标可以被称为得分。“候选变量”是能量函数中所包括的多个变量中作为被优先设置了特定值的候选的变量。候选值是用作要优先设置给候选变量的候选的特定值。
在第二实施方式中,为了方便起见,“指示候选变量和候选值的组合被包括在最优解中的概率的指标”被称为“概率”。
基于关于当前要求解的组合优化问题的信息来预先确定候选变量和候选值。例如,基于有关相关问题所属的领域的知识、关于如何求解问题的技术诀窍(know-how)或启发式分析、或这些的组合来确定候选变量和候选值。问题所属的领域的示例包括:制造/配送方面的拣选路线和仓库的库存管理的优化;物流方面的配送计划的优化;金融方面的投资组合的优化;药物发现方面的分子相似度搜索;等等。在一个可能的示例中,预先针对每个变量评价对从与问题相对应的能量函数获得的能量值的影响的大小,按照影响的大小的降序将预定数量的变量设置为候选变量,并且可以将变量的可能值设置为候选值。每个变量对能量值的影响的大小可以通过针对各变量的非线性函数突出,并被评价。
候选变量和候选值的确定可以由信息处理设备100执行,或者可以基于用户针对问题预先执行的分析来执行。
变量固定控制表是用于管理针对候选变量和候选值的集合的更新概率的表。
概率更新单元130基于由搜索单元210、211、212……获得的多个解和与多个解对应的多个能量值,更新候选变量和候选值的集合包括在最优解中的概率。例如,概率更新单元130提取各自包括任何候选变量和候选变量的候选值的多个解中的最差解。概率更新单元130计算与感兴趣的候选变量和候选值的集合对应的最佳解相对于所提取的最差解对能量值的改善水平。获得所计算的水平作为针对感兴趣的候选变量和候选值的集合的新概率。
例如,在使能量值最小化的问题中,感兴趣的候选变量具有候选值的多个解中的最小能量值被假设为E1。针对任何候选变量和候选值获得的多个解中的最大能量值被假设为Emax。在这些状况下,概率更新单元130例如获得1-E1/Emax作为新概率。
这样计算的概率表示:通过候选变量被设置为候选值的解实现的相对于最差解的改善水平。因此,具有较高概率(例如,较高的解改善水平)的候选变量和候选值的集合被预期具有较高的包括在最优解中的可能性。
概率更新单元130将这样获得的新概率登记在存储单元120中存储的变量固定控制表中。
变量固定控制单元140在针对通过概率更新单元130选择的候选变量将相应候选值设置为相对于其他值具有优先级的情况下,指示搜索单元210、211、212……执行搜索。例如,变量固定控制单元140向搜索单元210、211、212……指定候选变量和候选值的集合,并且使搜索单元在候选变量被固定至候选值的情况下执行解搜索。
在第二实施方式的示例中,变量固定控制单元140控制搜索单元210、211、212……,以在整个解搜索时段内,例如在所有迭代内,使候选变量固定至候选值。单次迭代指示改变变量值的单次尝试。然而,变量固定控制单元140可以控制搜索单元210、211、212……,以在作为整个解搜索时段的预定百分比的时段内(例如在迭代的预定百分比或更大百分比内),使候选变量固定至候选值,而不是使候选变量完全固定至候选值。在这种情况下,预定百分比可以是任何百分比例如50%或80%。百分比可以响应于用户的指定而偏置可调。
变量固定控制单元140使用例如贪婪算法来选择指定给搜索单元210、211、212……的候选变量和候选值。例如,变量固定控制单元140指示搜索单元210、211、212……在从被确定为对能量值的改善具有最大影响的变量开始逐一地将变量固定至候选值的情况下执行搜索。在该示例中,如上所述,被包括在最优解中的概率较高的候选变量和候选值的集合被预期更有可能改善与解相对应的能量值。因此,在优先选择概率较高的集合的情况下,更迅速地达到最优解的可能性增大。
变量固定控制单元140可以向搜索单元210、211、212……指定候选变量和候选值的不同集合,以使得搜索单元210、211、212……在不同候选变量被固定至不同候选值的情况下并行执行对解的搜索。
搜索单元210、211、212……中的每一个基于能量函数使用SA、副本交换方法等搜索基态。
伊辛能量函数E(x)例如由下面的等式(1)定义。在该等式中,由多个状态变量或状态向量表示的状态由不带后缀的“x”表示。状态变量是具有值“0”或“1”的二进制变量。多个状态变量可以被组合以表达三进制或更高阶变量。下面将描述能量值被最小化的情况。针对能量值被最大化的情况,符号可以被反转。
等式(1)右侧的第一项是通过以下操作获得的:针对可以从所有状态变量中选择的两个状态变量的所有组合,在没有遗漏和重复的情况下对两个状态变量的值与耦合系数的乘积进行合并。x
等式(1)右侧的第二项是所有状态变量的相应偏置值与状态变量的值的乘积之和。b
例如,伊辛模型中的自旋“-1”对应于状态变量的值“0”。伊辛模型中的自旋“+1”对应于状态变量的值“1”。
在状态变量x
h
在状态变量x
优化设备200在优化设备200的存储器或寄存器中保持局部字段h
例如,梯度下降可以用于搜索基态,以使能量E最小化。然而,利用梯度下降,一旦解被困在局部解处,就不可能脱离局部解。
鉴于此,在优化设备200中,在基态的搜索中使用Metropolis方法或Gibbs方法来确定是否允许能量变化成为ΔE
这里,逆温度β是温度T(T>0)的倒数(β=1/T)。min运算符指示获取参数(argument)的最小值。因此,例如,在使用Metropolis方法并且能量变化ΔE满足针对均匀随机数u(0<u≤1)的等式(6)的情况下,允许状态变量的值的变化。
ln(u)×T≤-ΔE (6)
图4是示出初始设置表的示例的图。
初始设置表121预先存储在存储单元120中。初始设置表121包括包含候选变量、候选值和被包括在最优解中的概率的项。
关于候选变量的标识信息被登记在候选变量的项上。在候选值的项上登记候选值。对应候选变量的对应候选值被包括在最优解中的概率的初始值被登记在被包括在最优解中的概率的项上。
例如,登记在初始设置表121中的记录包括候选变量“c1”、候选值“v3”和被包括在最优解中的概率“0.4”。该记录指示:候选变量c1=候选值v3被包括在最优解中的概率(例如,候选变量c1的候选值v3在最优解中的概率)的初始值是“0.4”。
登记在初始设置表121中的记录包括候选变量“c1”、候选值“v6”和被包括在最优解中的概率“0.3”。该记录指示:候选变量c1的候选值v6在最优解中的概率的初始值是“0.3”。
登记在初始设置表121中的记录包括候选变量“c2”、候选值“v2”和被包括在最优解中的概率“0.1”。该记录指示:候选变量c2的候选值v2在最优解中的概率的初始值是“0.1”。
在初始设置表121的示例中,针对候选变量c2和候选值v3的集合、以及候选变量c2和候选值v5的集合,相似地登记了被包括在最优解中的概率的初始值。
图5是示出变量固定控制表的第一示例的图。
变量固定控制表122存储在存储单元120中。通过概率更新单元130更新变量固定控制表122。变量固定控制表122包括包含候选变量、候选值、执行结果和被包括在最优解中的概率的项。
关于候选变量的标识信息被登记在候选变量的项上。在候选值的项上登记候选值。在执行结果的项上登记与其中对应候选变量具有对应候选值的解中的最佳解相对应的能量值。在该示例中,考虑使能量函数最小化的问题。因此,与其中对应候选变量具有对应候选值的解中的最佳解相对应的能量值是其中对应候选变量具有对应候选值的解中的最小能量值。对应候选变量的对应候选值被包括在最优解中的概率登记在被包括在最优解中的概率的项上。概率是基于当前执行结果更新的新概率。
例如,登记在变量固定控制表122中的记录包括候选变量“c1”、候选值“v3”、执行结果“1000”和被包括在最优解中的概率“0.2”。该记录指示:对应于候选变量c1=候选值v3的最佳解的能量值是1000,并且候选变量c1的候选值v3在最优解中的概率是“0.2”。
考虑上述新概率的等式,在变量固定控制表122的示例中,E1=1000且Emax=1300。因此,针对候选变量c1和候选值v3的集合的新概率p是p=1-1000/1300=1-0.7692...=0.2307...≈0.2。
在变量固定控制表122的示例中,还针对候选变量c1和候选值v6的集合、候选变量v2和候选值v2的集合、候选变量c2和候选值v3的集合、以及候选变量c2和候选值v5的集合,登记执行结果和被包括在最优解中的概率。
接下来,将描述作为更新变量固定控制表122的结果的变量固定控制表的示例。
图6是示出变量固定控制表的第二示例的图。
变量固定控制表123存储在存储单元120中。变量固定控制表123是作为更新变量固定控制表122的结果的变量固定控制表。
变量固定控制表123中包括的项与变量固定控制表122中的项相同,且因此省略其描述。
例如,登记在变量固定控制表123中的记录包括候选变量“c1,c2”、候选值“v6,v5”、执行结果“700”和被包括在最优解中的概率“0.3”。该记录指示,与候选变量c1具有候选值v6且候选变量c2具有候选值v5的最佳解相对应的能量值是700,并且候选变量c1的候选值v6和候选变量c2的候选值v5在最优解中的概率是“0.3”。
在变量固定控制表123的示例中,还针对候选变量的集合与候选值的多个集合中的每一个之间的组合,例如候选变量(c1,c2)=(v6,v5),(v6,v3),....,来登记执行结果和被包括在最优解中的概率。
在上述示例中,例示了两个候选变量,诸如候选变量c1和c2,但是候选变量的数量可以是三个或更多个。例如,在作为更新变量固定控制表123的结果的变量固定控制表中,可以登记针对具有作为元素的三个或更多个候选变量的集合的候选值的集合、执行结果和被包括在最优解中的概率。例如,概率更新单元130可以在每次获得执行结果时增加包括在将成为概率计算目标的集合中的候选变量的数量。
包括在将成为概率计算目标的集合中的候选变量的数量被称为“组合大小”。例如,当组合大小是“1”时,概率更新单元130将包括在将成为概率计算目标的集合中的候选变量的数量设置为“1”。当组合大小是“2”时,概率更新单元130将包括在将成为概率计算目标的集合中的候选变量的数量设置为“2”。例如,关于组合大小的信息被存储在存储单元120中。
接下来,将描述信息处理设备100中的处理过程。在执行以下过程之前,信息处理设备100将关于问题的实例信息设置给优化设备200。实例信息包括在SA和副本交换方法中使用的各种参数例如温度信息以及指示能量函数的信息。指示能量函数的信息包括关于权重因子、偏置值和常数项的信息。
图7是示出信息处理设备的处理的示例的流程图。
(S1)变量固定控制单元140按照被包括在最优解中的概率的降序将候选变量固定至候选值,并使搜索单元210、211、212……开始搜索。当针对当前问题第一次执行步骤S1时,变量固定控制单元140基于初始设置表121选择候选变量和候选值的集合。当针对当前问题第二次或此后执行步骤S1时,如在稍后描述的步骤S7中那样,变量固定控制单元140基于最新的变量固定控制表选择候选变量和候选值的集合。可以在存储单元120中预先设置要针对第一搜索、第二搜索以及此后的搜索中的每一个选择的候选变量和候选值的集合的数量。变量固定控制单元140优选地选择分别被指示给搜索单元210、211、212……的候选变量和候选值的不同集合,使得没有集合被冗余地选择。例如,变量固定控制单元140可以随机地向除了要被固定的候选变量之外的变量提供初始值。
(S2)概率更新单元130确定搜索单元210、211、212……中的任何一个是否已经达到能量值等于或小于阈值的解。当达到能量值等于或小于阈值的解时,概率更新单元130终止处理。当尚未达到能量值等于或小于阈值的解时,概率更新单元130使处理前进至步骤S3。
例如,概率更新单元130可以预先向搜索单元210、211、212……设置阈值。当任何一个搜索单元已经获得了能量值等于或小于阈值的解时,概率更新单元130可以被通知已经从对应的搜索单元获得了能量值等于或小于阈值的解的事实,并且确定步骤S2中为是。
(S3)概率更新单元130确定搜索单元210、211、212……的搜索是否超时,例如,在搜索开始后是否经过了预定时间段。当搜索超时时,概率更新单元130终止处理。当搜索没有超时时,概率更新单元130使处理前进至步骤S4。
(S4)概率更新单元130收集来自搜索单元210、211、212……的执行结果,并更新针对候选变量和候选值的每个集合的概率。概率更新单元130将从搜索单元210、211、212……收集的执行结果以及与执行结果对应的更新后的概率登记在当前变量固定控制表中。包括在作为概率计算目标的集合中的候选变量的数量取决于组合大小。组合大小的初始值是“0”。在步骤S4中,在组合大小为“0”时,概率更新单元130将包括在作为概率计算目标的候选变量和候选值的集合中的候选变量的数量设置为“1”。
(S5)概率更新单元130增大候选变量的组合大小。例如,概率更新单元130将组合大小增加一。
(S6)变量固定控制单元140确定组合大小是否大于候选变量的数量。当组合大小大于候选变量的数量时,变量固定控制单元140终止处理。当组合大小等于或小于候选变量的数量时,变量固定控制单元140使处理前进至步骤S7。
(S7)基于由概率更新单元130更新的最新的变量固定控制表,变量固定控制单元140选择要被固定至候选值的候选变量。基于最新的变量固定控制表,变量固定控制单元140按照被包括在最优解中的概率的降序选择候选变量和候选值的预定数量的集合。当组合大小是“2”或更大时,变量固定控制单元140优先选择被包括在最优解中的概率高的两个或更多个候选变量和分别被设置给两个或更多个候选变量的两个或更多个候选值的集合。变量固定控制单元140使处理前进至步骤S1。
当信息处理设备100响应于步骤S2、S3和S6中的任一个中的确定而终止图7的过程时,信息处理设备100向用户通知作为当前问题的解的由搜索单元210、211、212……获得的解中的最佳解,该最佳解是例如具有最小能量值的解。
初始设置表121可能未被提供概率的初始值。在这样的情况下,在由搜索单元210、211、212……进行的初始解搜索中,所有变量和可以被设置给变量的值被同等对待。例如,可以仅在初始设置表121中指定候选变量和候选值的一个集合。
可替选地,信息处理设备100可以不被提供初始设置表121中的任何信息,并且信息处理设备100可以将能量函数中的所有变量视为候选变量。在这种情况下,基于搜索单元210、211、212……的初始解搜索的结果,更新候选变量和候选值的每个集合的被包括在最优解中的概率。基于该概率,缩减第二解搜索以及此后的解搜索中的要被固定的候选变量和候选值的集合。
在步骤S4中,概率更新单元130可以从搜索单元210、211、212……获取多个解以及与多个解对应的多个能量值,或者可以通过将获取的解代入能量函数来获得与解对应的能量值。
已经描述了在步骤S7中变量固定控制单元140按照概率的降序选择候选变量和候选值的集合的示例。可替选地,可以基于与概率对应的随机数来选择要被固定的候选变量和候选值的集合。变量固定控制单元140可以仅选择候选变量和候选值的一个集合,所述集合的被包括在最优解中的概率等于或大于预定值。
以这种方式,信息处理设备100基于由搜索单元210、211、212……获得的多个解和与多个解对应的多个能量值,计算候选变量的候选值被包括在最优解中的概率。基于所述概率,信息处理设备100选择固定至候选值的候选变量和候选值,并且向搜索单元210、211、212……输出用于在所选择的候选变量被固定至候选值的情况下执行搜索的指令。
搜索单元210、211、212……中的每一个在由信息处理设备100指示的候选变量被固定至候选值的情况下搜索解。
这可以增加达到最优解的可能性。
当使用SA、副本交换方法等搜索到的解被困在局部解处时,脱离处于局部解附近的状态是困难的,并且因此可能无法获得最优解。
解决这个问题的可能解决方案的示例可以包括:重复向搜索单元210、211、212……提供随机确定的初始状态以获得解的处理;以及选择由此获得的解中的最佳解。不幸的是,即使当通过被提供了随机确定的初始状态的搜索单元210、211、212……重复获得解时,达到最优解的可能性也未必充分增加。
背包问题被视为是组合优化问题的示例。背包问题适用的领域范围很广。作为这样的一个示例,将描述金融或管理领域中的投资组合的优化。
背包中的内容物的重量与预算相关联,并且C表示总预算。存在多个选择候选物品,并且w
例如,如等式(7)中那样,使用w
等式(7)右侧的第一项表示所选物品的利润之和。目标是获得产生最高利润总和的物品i的组合。等式(7)右侧的第一项具有负号,这意味着在右侧的第一项最小的情况下获得最高利润总和。
此外,施加所选物品i的预算之和为C或更小的约束。等式(7)右侧的第二项是指示约束的约束项。α是预先提供的常数。y是被称为松弛变量的辅助变量,并且被引入以将不等式约束转换成等式约束。利用松弛变量y,当Σx
在等式(8)中,(-v
例如,i=1,2,3,...,50成立。v
在这种状况下,当x
图8是示出权重与偏置之间的关系的示例的图。
曲线图70示出了由等式(8)表达的权重(w
接下来,将描述信息处理设备100的处理过程的比较例。在比较例中,CPU 101执行处理。
图9是示出比较例的流程图。
(S10)CPU 101将关于问题的实例信息输入至优化设备200。如上所述,实例信息包括各种参数,例如温度、能量函数中的权重、偏置值和常数项。
(S11)CPU 101随机地设置搜索单元210、211、212……的搜索的初始状态。
(S12)CPU 101指示搜索单元210、211、212……执行解搜索。
(S13)当由搜索单元210、211、212……进行的搜索完成时,CPU 101从搜索单元210、211、212……获取解。
(S14)CPU 101确定由搜索单元210、211、212……执行的解搜索的计数是否已经达到特定计数。当解搜索计数已经达到特定计数时,CPU 101使处理前进至步骤S15。当解搜索计数没有达到特定计数时,处理进行至步骤S11。
(S15)CPU 101输出解搜索的结果。例如,CPU 101向用户通知最终解,该最终解是从搜索单元210、211、212……获取的多个解中具有最低能量值的解。
不幸的是,关于图9所示的过程,对于如上所述的背包问题的示例中的一些问题,由于变量的特定值未被包括在最优解中,因此解相对可能被困在局部解处,并且可能难以从局部解脱离。
鉴于此,信息处理设备100评价候选变量和候选变量的候选值的每个集合的被包括在最优解中的概率,并且基于概率向搜索单元210、211、212……指定要被固定的候选变量和候选值。这导致在反映——被预期具有高的被包括在最优解中的概率的——候选变量和候选值的集合的状态下执行搜索单元210、211、212……的搜索的可能性更高,由此可以增加达到最优解的可能性。
利用信息处理设备100,根据包括在最优解中的概率来组合候选变量被固定至候选值的局部搜索,由此可以在抑制了其中最优解被预期为不可实现的状态的建立的情况下,高效地执行全局搜索。
信息处理设备100逐渐增大候选变量的组合大小,并且获得多个候选变量和多个候选值的集合的被包括在最优解中的概率,使得可以进一步增加达到最优解的可能性。搜索空间可以逐渐变窄,并且搜索的效率进一步提高。
总之,信息处理设备100具有例如以下功能。
变量固定控制单元140输出在整个搜索时段或者在部分搜索时段内将变量固定至候选值的情况下执行搜索的指令,作为将候选变量固定至候选值的指令。来自变量固定控制单元140的指令通过IO接口104被输出至搜索单元210、211、212……、优化设备200的控制单元等。
因此,可以在反映了——被预期具有高的被包括在最优解中的可能性的——候选变量和候选值的集合的状态下执行搜索,由此可以增加达到最优解的可能性。
变量固定控制单元140基于候选变量和候选值的每个集合的概率,优先选择多个集合中的被预期具有高的被包括在最优解中的可能性的变量和候选值的集合。在第二实施方式的示例中,具有较高概率的集合被预期具有较高的被包括在最优解中的可能性,并且因此,按照概率的降序来选择集合。这可以增加搜索单元210、211、212……中的任何一个迅速达到最优解的可能性。
概率更新单元130针对候选变量和候选值的每个集合,获取与候选变量具有候选值的解中的最佳解对应的能量值。概率更新单元130基于集合的最佳解的获取能量值中的最差能量值与对应于候选变量具有候选值的最佳解的能量值之间的比率来计算针对候选变量和候选值的集合的概率。因此,可以适当地评价对应候选变量的对应候选值被包括在最优解中的可能性。
针对所选择的候选变量和候选值的多个集合中的每个集合,变量固定控制单元140输出将候选变量固定至候选值的指令。概率更新单元130从搜索单元210、211、212……获取其中所选择的候选变量具有候选值的多个解,并且基于获取的多个解和与多个解对应的多个能量值来更新候选变量和候选值的每个集合的概率。
通过基于解搜索的最新结果更新候选变量和候选值的每个集合的被包括在最优解中的概率,可以在校正先前概率的情况下进一步增加达到最优解的可能性。
基于多个解和与多个解对应的多个能量值,概率更新单元130针对变量、其他变量、候选值和其他候选值的每个集合,计算候选变量的候选值和其他候选变量的其他候选值被包括在最优解中的概率。变量固定控制单元140基于每个集合的概率选择第一变量的第一候选值和第二变量的第二候选值。变量固定控制单元140输出在第一变量被固定至第一候选值并且第二变量被固定至第二候选值的情况下执行搜索的指令。
作为计算被包括在最优解中的概率的目标的集合中包括的较大数量的变量使得搜索单元210、211、212……的搜索空间能够被更有效地缩小,从而可以有效地执行搜索。
例如,在计算候选变量和候选值的每个集合的被包括在最优解中的概率之后,概率更新单元130增加作为下一次概率计算的目标的集合中包括的变量的数量。
因此,在搜索单元210、211、212……的搜索空间中预期包括最优解的范围可以从宽范围逐渐缩小至窄范围,由此可以进一步增加达到最优解的可能性。
根据第一实施方式的信息处理可以由处理单元11执行程序来实现。可以通过使CPU 101执行程序来实现根据第二实施方式的信息处理。程序可以记录在计算机可读的记录介质113中。
例如,可以通过分发记录有程序的记录介质113来传播程序。程序可以存储在另一计算机中,并且程序可以通过网络分发。例如,计算机可以将记录在记录介质113中的程序或从其他计算机接收的程序存储(安装)在存储装置例如RAM 102或HDD 103中,并且可以从存储装置读取程序以执行程序。
- 信息处理系统、信息处理方法、信息处理程序、存储信息处理程序的计算机可读记录介质、数据结构、信息处理服务器和信息处理终端
- 信息处理装置、信息处理方法、信息处理程序、信息处理系统和非瞬态计算机可读信息记录介质