一种用于语义分割的无源数据无监督领域自适应方法
文献发布时间:2023-06-19 18:30:43
技术领域
本发明涉及无监督领域自适应技术领域,更具体的说是涉及一种用于语义分割的无源数据无监督领域自适应方法。
背景技术
语义分割的目的是为图像中的每个像素分配语义标签。近年来,基于卷积神经网络的分割模型取得了显著进展,在计算机视觉领域,如自动驾驶、机器人和疾病诊断领域得到了广泛的应用。然而,当前语义分割方法的显著性能通常依赖于手工标注的大规模像素级数据集。为避免费时费力的人工标记注释,许多无监督领域自适应(UDA)方法已经提出了将在计算机生成的注释图像上训练的模型用于未标记的真实图像。用于语义分割的无监督域自适应(UDA)可以将从合成数据(源域)中获得的知识(具有低成本注释)转移到真实图像(目标域)中。目前所有的UDA方法都会将目标域的分布与源域的分布明确对齐,以进行可行的调整。因此,这些方法通常基于可访问源域标记的数据的假设,这将它们的应用程序限制在某些存在隐私,存储或传输问题的实际情况下。例如,用户或公司不希望其数据泄漏给其他人,并且某些源域数据太大而无法快速传输到云中。
因此,如何提供一种安全性能高,无需访问原始源域数据的无监督领域自适应方法是本领域技术人员亟需解决的问题。
发明内容
有鉴于此,本发明提供了一种用于语义分割的无源数据无监督领域自适应方法,无需访问原始源域数据,仅需要预训练好的源域预测模型和未标记的目标域数据,能够保护用户隐私。
为了实现上述目的,本发明采用如下技术方案:
一种用于语义分割的无源数据无监督领域自适应方法,包括以下步骤:
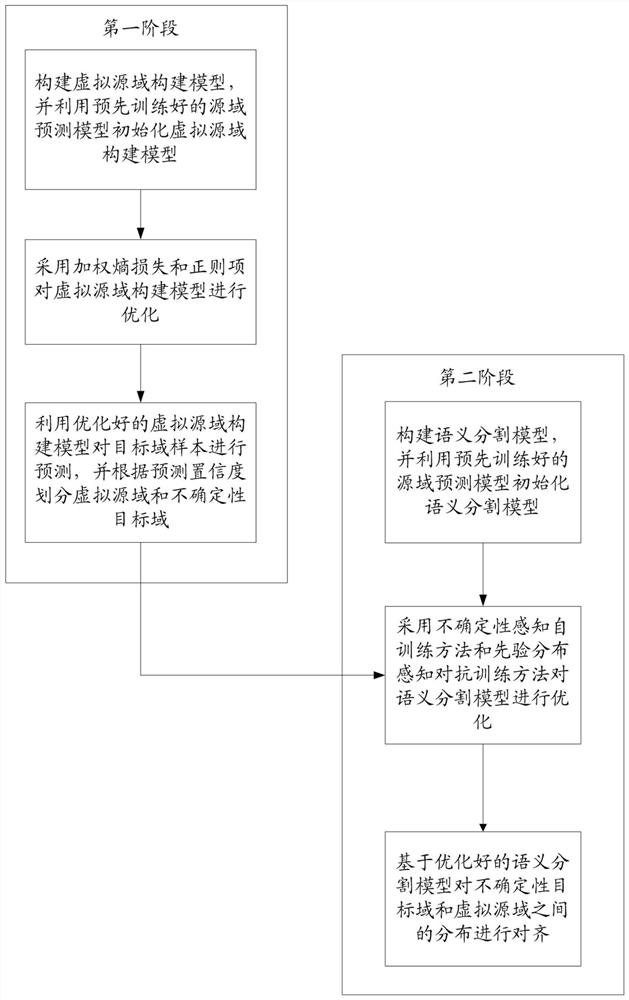
构建虚拟源域构建模型,并利用预先训练好的源域预测模型初始化虚拟源域构建模型;
采用加权熵损失和正则项对虚拟源域构建模型进行优化;
利用优化好的虚拟源域构建模型对目标域样本进行预测,并根据预测置信度划分虚拟源域和不确定性目标域;
构建语义分割模型,并利用预先训练好的源域预测模型初始化语义分割模型;
采用不确定性感知自训练方法和先验分布感知对抗训练方法对语义分割模型进行优化;
基于优化好的语义分割模型对不确定性目标域和虚拟源域之间的分布进行对齐。
优选的,在上述一种用于语义分割的无源数据无监督领域自适应方法中,所述源域预测模型是采用真实源域的数据训练收敛而成;所述虚拟源域构建模型的参数采用训练好的源域预测模型的参数。
优选的,在上述一种用于语义分割的无源数据无监督领域自适应方法中,采用加权熵损失对虚拟源域输出模型输出的高于预设置信度的目标样本进行熵最小化优化,对虚拟源域输出模型输出的低于预设置信度的目标样本的熵值保持不变;采用下式对虚拟源域构建模型进行加权熵最小化优化:
其中,
上式中,
优选的,在上述一种用于语义分割的无源数据无监督领域自适应方法中,利用下式计算源域预测模型的预测与虚拟域构建模型的预测之间的一致性正则化损失:
其中,
优选的,在上述一种用于语义分割的无源数据无监督领域自适应方法中,虚拟源域和不确定性目标域的划分方法为:
利用优化好的虚拟源域构建模型预测计算目标域样本中某一张目标域图片的平均熵;
将目标域样本中所有目标域图片的平均熵按照从小到大排列,取前66%的目标域图片作为虚拟源域,取剩余的34%的目标域图片作为不确定目标域。
优选的,在上述一种用于语义分割的无源数据无监督领域自适应方法中,利用下式计算优化好的虚拟源域构建模型的损失,用以表征虚拟源域与真实源域之间的分布差异;
其中,
优选的,在上述一种用于语义分割的无源数据无监督领域自适应方法中,所述不确定性感知自训练方法包括以下步骤:
定义一组带有dropout的虚拟源域构建模型
对虚拟源域和不确定性目标域中的每一张图片X
利用下式得到预测输出中的伪标签;
上式中,
利用下式对得到的伪标签做选择;
B(X
利用下式确定不确定性自我训练阶段的损失;
优选的,在上述一种用于语义分割的无源数据无监督领域自适应方法中,所述先验分布感知对抗训练方法在对虚拟源域和不确定性目标域之间的分布进行对齐的过程中,对虚拟源域和不确定性目标域之间的对象类别不匹配性、类别不平衡性和预测的不确定性因素进行改善;其中,对虚拟源域和不确定性目标域之间的对象类别不匹配性因素进行改善的过程为:
利用下式分别计算虚拟源域和不确定性目标域的类别概率
其中,
引入阈值θ选择虚拟源域和不确定目标域中的领域共享类别,并排除领域特定类别;选择公式如下:
上式表示,
利用类别权重对虚拟源域和不确定性目标域之间的类别不平衡性进行改善,类别权重的计算公式为:
其中,
利用不确定性权值对虚拟源域和不确定性目标域的预测的不确定性因素进行改善,不确定性权值
其中,
优选的,在上述一种用于语义分割的无源数据无监督领域自适应方法中,先验分布感知对抗训练方法阶段的损失计算方法为:
其中,
优选的,在上述一种用于语义分割的无源数据无监督领域自适应方法中,利用下式计算优化好的语义分割模型的损失,用以表征虚拟源域与真实源域之间的数据不确定性和先验分布差异;
其中,λ
经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种用于语义分割的无源数据无监督领域自适应方法,首先构造一组源域虚拟数据,以通过识别由预先训练好的源域预测模型预测的目标域高置信度样本来模拟源域分布。然后,通过分析跨域语义分割任务中的数据属性,采用不确定性感知自训练方法和先验分布感知对抗训练方法,以将虚拟源域和目标域与自我训练和对抗性学习策略对齐。实现改善不同领域之间的对象类别不匹配、类别不平衡和预测不确定性等因素,可直接从嘈杂的伪标签中学习目标域分布。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
图1附图为本发明提供的用于语义分割的无源数据无监督领域自适应方法的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,本发明实施例公开了一种用于语义分割的无源数据无监督领域自适应方法,包括以下步骤:
构建虚拟源域构建模型,并利用预先训练好的源域预测模型初始化虚拟源域构建模型;
采用加权熵损失和正则项对虚拟源域构建模型进行优化;
利用优化好的虚拟源域构建模型对目标域样本进行预测,并根据预测置信度划分虚拟源域和不确定性目标域;
构建语义分割模型,并利用预先训练好的源域预测模型初始化语义分割模型;
采用不确定性感知自训练方法和先验分布感知对抗训练方法对语义分割模型进行优化;
基于优化好的语义分割模型对不确定性目标域和虚拟源域之间的分布进行对齐。
本发明算法共包含两个阶段,即1)虚拟源域构建,以及2)不确定性和先验分布感知域适应。
在第一阶段,建议通过选择高度自信的目标域样本来构建虚拟源域,以模仿源域分布;然后通过提出的加权熵最小化方法,进一步减小虚拟源域和真实源域之间的域间隙;间隙指虚拟源域和真实源域之间的分布差距。
高度自信表示模型的预测概率,当模型对该样本的预测概率高时,我们简称该样本的置信度高,模型对于自己做出的预测比较自信。高度自信即置信度比较高。
加权熵最小化方法表示指最小化加权熵损失和一致性正则化损失。
在第二阶段,通过考虑数据不确定性和先验分布差异,提出了一种经过精心设计的加权机制,用于目标域和虚拟源域之间的分布对齐。此外,提出了一种新的不确定性感知自训练方法,该方法可以通过考虑模型不确定性而直接从嘈杂的伪标签中学习目标域分布。
下面,对上述各步骤进行进一步描述。
1.虚拟源域的构建
源域预测模型是使用源域数据预先训练收敛的模型,使用源域的图片和标签训练而成。源域预测模型训练收敛以后保持其参数不变,定义为源域预训练模型
1)加权熵损失:对低熵(即高置信度)的目标样本进行熵最小化优化,对低预测置信度的高熵样本保持不变。
采用加权熵损失对虚拟源域输出模型输出的高于预设置信度的目标样本进行熵最小化优化,对虚拟源域输出模型输出的低于预设置信度的目标样本的熵值保持不变;采用下式对虚拟源域构建模型进行加权熵最小化优化:
其中,
上式中,
2)一致性正则化损失
为了避免过度自信的预测造成的错误的传播,本发明提出了原始源域预测模型的预测与虚拟域构建模型的预测之间的一致性正则化损失。一致性正则化损失的计算公式如下:
其中,
使用公式(1)和公式(2)训练虚拟源域构建模型φ
对于目标域样本中的一张图片,使用φ
利用下式计算优化好的虚拟源域构建模型的损失,用以表征虚拟源域与真实源域之间的分布差异;
其中,
2、不确定性和先验分布感知域适应
接下来本发明使用加权对抗损失间接对齐不确定性目标域和虚拟源域之间的分布,使用不确定性感知自训练方法直接从嘈杂的伪标签中学习目标域分布。
1)不确定性感知自训练
无监督领域自适应中常用的自训练方法是根据预测置信度手动设置阈值,但仍存在一些未解决的问题:(1)如果设置的阈值过高,则伪标记样本对性能改善的贡献不大;(2)如果阈值设置过低,可能会由于伪标签的噪声而对模型产生不利影响;(3)单一阈值可能不适用于所有类别和数据集,这是有效样本选择的另一个障碍。
最近的一些研究提出了贝叶斯神经网络来捕获模型的不确定性,并成功地应用于各种计算机视觉任务。贝叶斯神经网络用这些参数上的分布代替确定性的网络权值参数,并对所有可能的权值进行平均,以捕获模型的不确定性。为此,本发明利用贝叶斯深度学习的进展,获取网络可靠的预测不确定性,进行有效的自我训练。
借用dropout来近似贝叶斯神经网络中的推理。首先定义一组带有dropout的虚拟源域构建模型
上式中,
利用下式对得到的伪标签做选择;
B(X
利用下式确定不确定性自我训练阶段的损失;
2)不确定性先验分布感知对抗训练
跨领域语义分割存在一些特定的特性(如不同领域之间的对象类别不匹配、类别不平衡、预测不确定性等),需要进一步考虑。基于这些特性,本发明提出了一种加权对抗学习方法用于领域对齐。总的加权对抗目标定义为:
其中两个加权参数{β
具体来说,本发明实施例以批量大小为2为例进行说明,一个来自虚拟源域
①对于不同领域类别不匹配的问题:
由于一个图像通常很难包含所有类别,因此一批图像中的虚拟源域和目标域同时包含领域共享的和领域特定的类别。因此,不加任何考虑地对齐所有类别是次优选择。本发明实施例对虚拟源域和不确定性目标域之间的对象类别不匹配性因素进行改善的过程为:
利用下式分别计算虚拟源域和不确定性目标域的类别概率
其中,
引入阈值θ选择虚拟源域和不确定目标域中的领域共享类别,并排除领域特定类别;选择公式如下:
上式表示,
②类别不平衡性问题:
利用类别权重对虚拟源域和不确定性目标域之间的类别不平衡性进行改善,类别权重的计算公式为:
其中,
③预测不确定性问题
利用不确定性权值对虚拟源域和不确定性目标域的预测的不确定性因素进行改善,不确定性权值
其中,
w[c
利用下式计算优化好的语义分割模型的损失,用以表征虚拟源域与真实源域之间的数据不确定性和先验分布差异;
其中,λ
如表2(a)-(b)所示,比较了本发明提出的无监督领域自适应方法和最新的无监督领域自适应方法在三个跨领域语义分割任务上的差异。
表2(a)
表2(b)
可以观察到,本发明方法(即使没有源域数据)比最先进的无监督领域自适应方法(有源域数据)在GTA5到Cityscapes任务上性能好1.6%mIoU,在SYNTHIA到Cityscapes任务上好1.8%的mIoU。从Synscapes和Cityscapes,我们的方法得到mIoU为54.5%,仍然在性能上超过了进最先进的方法0.3%。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 一种用于无源电子锁具的螺线管驱动装置、螺线管驱动方法以及无源电子锁具
- 一种无监督领域自适应语义分割方法
- 基于轮廓信息的热红外语义分割无监督领域自适应方法