一种基于参数初始化调优的机器翻译系统的构建方法
文献发布时间:2023-06-19 18:30:43
技术领域
本发明涉及一种机器翻译技术,具体为基于参数初始化调优的机器翻译系统的构建方法。
背景技术
近些年来,随着机器学习领域的快速发展,神经网络被大量的使用在了自然语言处理领域,尤其是当计算机算力的飞速发展使得训练神经网络的难度大大降低之后,使用神经网络处理机器学习任务成了一种主流思想,即深度学习。深度学习给自然语言处理领域带来了翻天覆地的变化,使用神经网络解决自然语言处理任务也成了一种新的标准。
为了获得性能更强的神经机器翻译模型,研究人员从不同的角度进行研究。其中,通过更改网络结构和采用适当的初始化策略能够有效提高模型性能。更改网络结构指的不仅仅是堆叠基础神经网络模型,还可以修改神经网络的层结构和计算策略。初始化策略指的是,在进行训练模型之前,对模型具有的参数进行初始化,使其保持某种特征,保证输入与输出的方差一致性,并在后续的训练过程中利用该特征使得模型取得理想的效果。
深层网络是一个相对的概念,对于某一种基础神经网络模型来说,层数翻一倍或几倍就会被称为深层网络。深层网络的天生优势就是有更多的模型参数,可以更全面地抽象数据模型,使得模型的表达能力增强。但是深层网络在训练过程中会出现由于网络模型深度的增加而导致梯度消失、梯度爆炸、模型不收敛、模型不稳定等一系列问题,从而使得深层网络的表现效果变差。
更大的模型容量使得深层网络的表达能力增强很多,但同时深层网络的深层特点也使得其在训练过程中会面临上述不稳定的问题。深层网络由于其深层的特性,导致训练过程花费时间较长。因为深层网络的性能较强,如果能够克服深层网络的问题,将会大大提升机器翻译的性能。
发明内容
针对深层网络存在训练困难的特点,本发明将参数初始化方法与深层网络相结合,即在深层网络的基础上使用更优的初始化办法,以此取得更有效的模型,从而提出一种基于参数初始化调优的机器翻译系统的构建方法,通过结合深层网络模型结构和参数初始化方法使得深层网络表现更加优秀,实现表达能力更强,效果更好的深层网络。
本发明提供一种基于参数初始化调优的机器翻译系统的构建方法,包括以下步骤:
1)从互联网中获取数据规模可用于机器翻译模型训练的双语数据;
2)对获取的双语数据进行数据清洗、数据选择与划分、分子词处理以及构建词表,完成数据预处理;
3)基于Fairseq开源系统,将参数初始化方法应用在深层网络模型上,完成神经机器翻译模型的设计与搭建;
4)使用预处理后的双语数据,在基于Fairseq开源系统设计的神经机器翻译模型上进行训练;
5)将训练完的高性能神经网络机器翻译模型进行封装,部署到服务器上,完成机器翻译系统的搭建。
步骤2)中对获取的双语数据依据预定的数据处理策略进行处理,步骤为:
201)进行数据清洗,针对不同的双语数据集使用相应的预处理脚本进行处理,去除杂质数据;
202)将步骤201)得到的清洗后的多个数据集进行选择与划分,获得后续实验所需要的训练数据集、验证数据集和测试数据集;
203)利用分子词工具,针对步骤202)处理后的双语数据集使用相应方式进行处理并创建一个共享的词表;
204)使用Fairseq的预处理文件,将双语训练数据集、验证数据集以及测试数据集转变成Fairseq的对应的二进制文件。
步骤3)中将参数初始化策略应用于深层网络模型,具体如下:
301)移除深层网络模型中的所有层标准化LN,其中层标准化LN是在多头自注意力子层和前馈神经网络相邻出现的神经网络,并且在训练深层网络模型时取消Warmup学习率预热策略;
302)对深层网络模型中除词嵌入层的权重W
303)对解码端的两种多头自注意力机制的第三~四权重W
304)对编码端多头自注意力机制的第三~四权重W
公式(1)和(2)中的W代表未处理前的权重矩阵,而W
305)利用上述设计搭建基于参数初始化策略的深层网络模型。
步骤4)中使用步骤2)中预处理后的双语数据,针对步骤3)设计好的网络模型,在Linux系统的服务器上基于Fairseq开源系统进行模型训练,得到训练好的使用了参数初始化策略的深层神经机器翻译模型。
步骤5)中,将训练完成的神经机器翻译模型进行封装,部署到Linux系统服务器上,完成神经机器翻译系统的搭建,具体步骤为:
501)将Fairseq框架的Interactive部分单独封装成接口,供后端调用;
502)搭建Web系统前后端,后端进行神经机器翻译的核心运算,前端进行系统展示,包括与用户的信息交互、源语言与目标语言的选择与输入、翻译接口的调用并返回相应的结果操作;
503)将训练好的神经机器翻译模型部署到服务器端,通过socket建立端口和网页的连接,完成整个机器翻译系统的搭建任务。
本发明具有以下有益效果及优点:
1.本发明提供一种基于参数初始化调优的机器翻译系统的构建方法,应用参数初始化策略的深层网络模型使鲁棒性大大增加,减小了由小数据集带来的性能波动影响,同时使得Adam优化器可以更好地发挥作用。
2.本发明将参数初始化策略应用于深层网络模型,使深层网络模型的训练更为稳定,并能够带来更强大的机器翻译能力,实现了在网络结构和参数初始化策略两个方面的有机结合,提供了更为强大的机器翻译系统。
附图说明
图1为本发明中数据的处理流程图示;
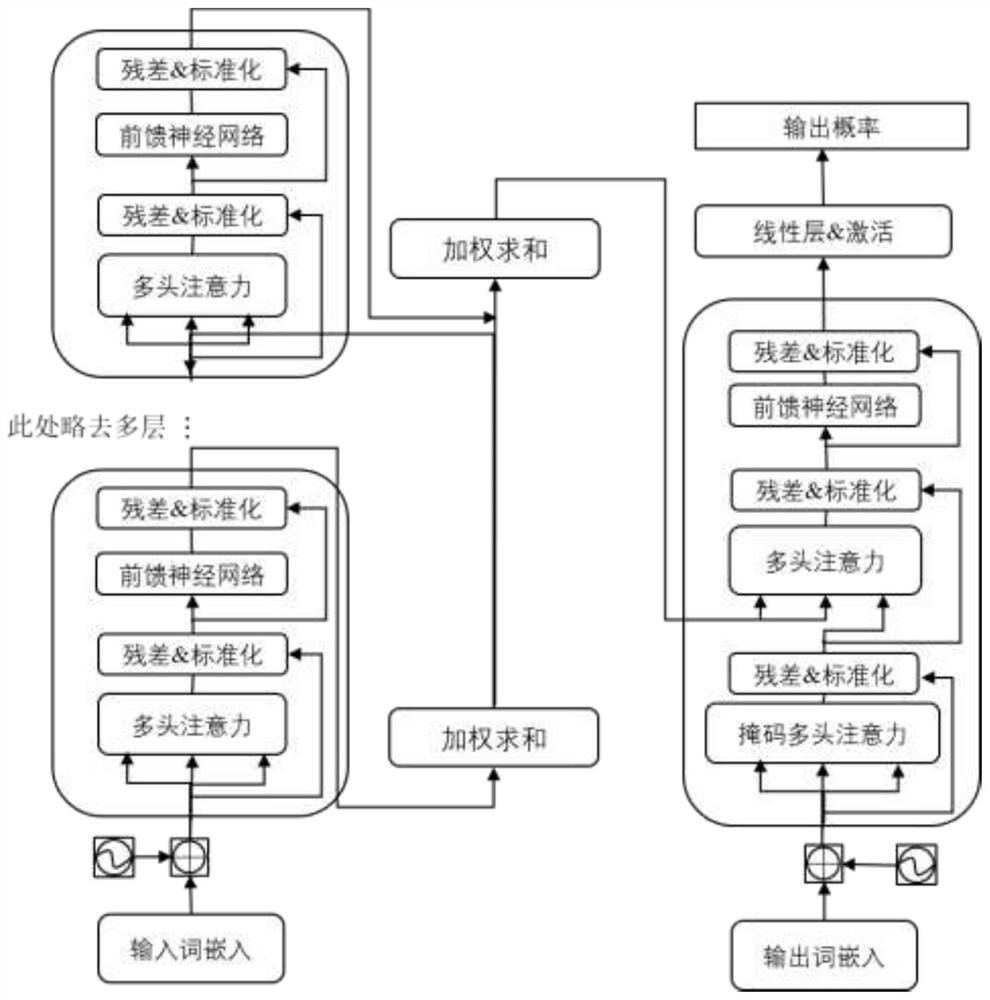
图2为本发明中将参数初始化策略应用于深层网络模型后的模型结构图;
图3为本发明中参数初始化策略在深层网络模型上参数初始化流程图示;
图4为本发明中模型训练流程图示;
图5为本发明中机器翻译流程图示。
具体实施方式
下面结合说明书附图对本发明作进一步阐述。
本发明针对深层网络存在训练困难的特点,将参数初始化方法与深层网络模型相结合,实现在深层网络的基础上使用更优的参数初始化办法,取得更有效的模型。本发明提出一种基于参数初始化调优的机器翻译系统的构建方法。通过结合深层网络模型结构和参数初始化方法使得深层网络模型表现更加优秀,表达能力更强,效果更好。
如图1~5所示,本发明提出的基于参数初始化调优的机器翻译系统的构建方法用的技术方案是:
1)从互联网中获取数据规模较大的可用于机器翻译模型训练的双语数据;
2)对获取的双语数据进行数据清洗、数据选择与划分、分子词处理以及构建词表,完成数据预处理;
3)基于Fairseq开源系统,将参数初始化方法应用在深层网络模型上,完成神经机器翻译模型的设计与搭建;
4)使用预处理后的双语数据,基于Fairseq开源系统在设计的神经机器翻译模型上进行训练;
5)将训练完的高性能神经网络机器翻译模型进行封装,部署到服务器上,完成机器翻译系统的搭建。
步骤1)从WMT和IWSLT官方网站获取进行机器翻译的标准数据集WMT14的英德数据以及IWSLT14的德英数据,制定数据处理策略。
步骤2)中对步骤1)获取的德语和英语双语数据依据预定的数据处理策略进行处理,整体流程如图1所示,具体步骤为:
201)进行数据清洗,针对WMT14数据集使用摩西数据预处理脚本,针对IWSLT14数据集使用Fairseq数据预处理脚本,去除部分杂质数据;
202)将步骤201)得到的数据集进行选择与划分,获得后续实验所需要的训练数据集、验证数据集和测试数据集。针对WMT14选择Newtest2013作为验证数据集,采用Newtest2014作为测试数据集。IWSLT14数据集的验证数据集则是将三份验证数据集进行合并得到最后的验证数据集,测试数据集用和验证数据集同样的方式进行处理,将三个测试数据集合并得到最后的测试数据集;
203)利用Bpe分词工具,针对步骤202)处理后的WMT14数据集使用摩西的方式进行处理并创建一个共享的词表,针对IWSLT14数据集使用Fairseq的BPE处理方式进行处理并得到一个共享的词表;
204)使用Fairseq的预处理文件,将WMT14和IWSLT14的训练数据集、验证数据集以及测试数据集转变成Fairseq的对应的二进制文件。
步骤3)中将参数初始化策略应用于深层网络模型,具体如下:
301)移除深层网络模型中的所有层标准化LN,其中层标准化LN是在多头自注意力子层和前馈神经网络相邻出现的神经网络,并且在训练深层网络模型时取消Warmup这种学习率预热策略;
302)对深层网络模型中除词嵌入层的权重W
303)对解码端的两种多头自注意力机制的第三~四权重W
公式(1)中的W代表未处理前的权重矩阵,而W^~代表经过缩放处理后的权重矩阵,如图2所示,解码端的掩码多头注意力、多头注意力、前馈神经网络,以及输入和输出词嵌入的相关权重矩阵都按此方法进行比例缩放;
304)对编码端多头自注意力机制的第三~四权重W
公式(2)中的W代表未处理前的权重矩阵,而W
305)利用上述设计搭建基于参数初始化策略的深层网络模型,具体的初始化流程可参考图3。
步骤4)使用步骤2)处理好的双语数据,针对步骤3)设计好的网络模型,在Linux系统的服务器上基于Fairseq开源系统进行模型训练,得到训练好的使用了特定参数初始化策略的深层神经机器翻译模型,模型训练流程如图4所示。
步骤5)中,将训练完成的神经机器翻译模型进行封装,部署到Linux系统服务器上,完成神经机器翻译系统的搭建,具体步骤为:
501)将Fairseq框架Interactive部分单独封装成接口,供Tornado后端调用;
502)通过Tornado+Html架构搭建Web系统前后端,其中Tornado负责前后端的沟通作用,Html负责前端的系统展示,包括与用户的信息交互、源语言与目标语言的选择与输入、翻译接口的调用并返回相应的结果等操作;
503)将步骤4)中训练好的神经机器翻译模型部署到服务器端,通过socket建立端口和网页的连接,完成整个系统的搭建任务,系统的运行流程如图5所示。
本发明对参数初始化策略与深层网络结合训练了多个模型,并在测试集上进行测试,在测试过程中选择BLEU评价指标作为译文质量的衡量标准,该评价指标是一种客观的评价算法。具体的评价结果如表1所示:
表1不同深度翻译模型在测试集上的BLEU的得分
表中模型层数的“-”前后两个数字分别代表模型编码端和解码端的层数,使用不同层数的编码端和解码端组合得到不同的网络模型。从实验结果上可以发现,随着模型深度的增加,模型的性能逐渐增强,且编码端加深可以带来的性能增益,而解码端加深则会使性能降低。对比模型训练的收敛轮次也可以发现,越深层的网络收敛速度越快。虽然深层网络每一轮的计算代价高于层数较少的模型,但总体上的收敛轮次减少可以很好的平衡这个问题,能够将深层网络的训练代价控制在一定的范围之内。
本发明将参数初始化策略与深层网络模型相结合,使深层网络模型的训练更为稳定,并能够带来更强大的机器翻译能力,实现了在网络结构和参数初始化策略两个方面的有机结合,提供了更为强大的机器翻译系统。
- 超参数调优、模型构建方法和装置
- 基于机器学习的文件系统参数自动调优方法及系统