基于排队搜索的最优实验设计方法及系统
文献发布时间:2024-01-17 01:27:33
技术领域
本公开涉及统计实验设计相关技术领域,具体的说,是涉及一种基于排队搜索的最优实验设计方法及系统。
背景技术
本部分的陈述仅仅是提供了与本公开相关的背景技术信息,并不必然构成在先技术。
最优实验设计的主要目标是用最少的实验次数,以较低的成本来安排实验,以获得理想的实验结果并得出科学结论,确保实验以高效和有效的方式进行。在科学和工程的许多领域,寻找最优实验设计是一项具有挑战性的任务,WJ Welch证明了它是一个NP-hard问题。在这项研究中,重点是通过利用新的优化技术来有效地解决最优实验设计问题,目的是在参数的约束和名义值的情况下获得最佳设计。
发明人在研究中发现,最优实验设计的智能方法包括采用基于梯度的算法和启发式算法等。目前基于梯度的算法,如费德洛夫-韦恩(Fedorov-Wynn)算法和乘性算法(MA)通常用于寻找最优实验设计,最近又提出了鸡尾酒算法和随机交换算法,在计算效率上与旧算法相比有了显著的提高,但是,对于更复杂的多因素和多参数模型,当试图在合理的时间框架内找到最优设计时,基于梯度的算法在为复杂环境下的实验寻找最优设计方面,存在计算速度过慢,在计算时间有限的情况下可行解的质量低下的问题。
近年来,启发式算法被越来越多地应用于解决各种复杂的优化问题。如粒子群优化(PSO)和差分进化(DE)最近被用于解决各种最优实验设计问题。然而,启发式算法可能会过早收敛,导致局部最优解。
发明内容
本公开为了解决上述问题,提出了一种基于排队搜索的最优实验设计方法及系统,采用基于排队搜索算法(QSA),提高了可行解的质量,并加入了基于梯度的乘法算子,以改进种群在迭代过程中的优化能力,减少了迭代次数,并解决传统的最优实验设计构造方法过早收敛、陷入局部最优解的问题。
为了实现上述目的,本公开采用如下技术方案:
一个或多个实施例提供了基于排队搜索的最优实验设计方法,包括如下步骤:
获取待设计实验的基本实验信息,随机生成实验设计作为初始种群;
增加基于梯度的乘法算子在排队搜索过程中对实验设计进行更新,改进排队搜索策略;
采用基于乘法算子改进后的排队搜索策略,将种群中的实验设计根据适度值进行排队和更新,迭代搜索优化种群中的实验设计;
满足排队搜索迭代的终止条件,输出种群中适度值最高的实验设计为最优实验设计。
一个或多个实施例提供了上述基于排队搜索的最优实验设计方法在模型构造实验设计的应用。
一个或多个实施例提供了基于排队搜索的最优实验设计系统,包括:
种群生成模块:被配置为获取待设计实验的基本实验信息,随机生成实验设计作为初始种群;
改进模块:被配置为增加基于梯度的乘法算子在排队搜索过程中对实验设计进行更新,改进排队搜索策略;
排队搜索模块:被配置为采用基于乘法算子改进后的排队搜索策略,将种群中的实验设计根据适度值进行排队和更新,迭代搜索优化种群中的实验设计;
最优实验设计输出模块:被配置为满足排队搜索迭代的终止条件,输出种群中适度值最高的实验设计为最优实验设计。
一种电子设备,包括存储器和处理器以及存储在存储器上并在处理器上运行的计算机指令,所述计算机指令被处理器运行时,完成上述方法所述的步骤。
与现有技术相比,本公开的有益效果为:
本公开中,提供了基于排队搜索的最优实验设计构造方法,解决了基于梯度的实验设计构造方法计算速度过慢,在计算时间有限的情况下可行解的质量低下的问题。同时,使用基于梯度的乘法算子改进了排队搜索策略,解决了使用启发式算法构造最优实验设计时,容易过早收敛、产生局部最优解问题。
本公开的优点以及附加方面的优点将在下面的具体实施例中进行详细说明。
附图说明
构成本公开的一部分的说明书附图用来提供对本公开的进一步理解,本公开的示意性实施例及其说明用于解释本公开,并不构成对本公开的限定。
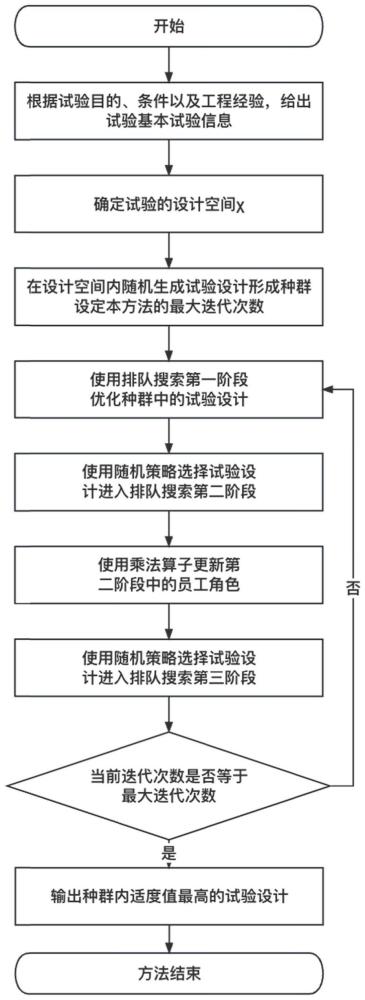
图1是本公开实施例1的最优实验设计方法流程图;
图2是本公开实施例2的条件下,使用实施例1中的方法与已有的PSO、DE、GA、SaDE和原始版本QSA对logistic模型在参数为θ
图3本公开实施例2的条件下,使用实施例1中的方法与已有的PSO、DE、GA、SaDE和原始版本QSA对logistic模型在参数为θ
图4本公开实施例3的条件下,使用实施例1中的方法与已有的PSO、DE、GA、SaDE和原始版本QSA对Poisson模型在参数为θ
图5本公开实施例3的条件下,使用实施例1中的方法与已有的PSO、DE、GA、SaDE和原始版本QSA对Poisson模型在参数为θ
具体实施方式
下面结合附图与实施例对本公开作进一步说明。
应该指出,以下详细说明都是示例性的,旨在对本公开提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本公开所属技术领域的普通技术人员通常理解的相同含义。
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本公开的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。需要说明的是,在不冲突的情况下,本公开中的各个实施例及实施例中的特征可以相互组合。下面将结合附图对实施例进行详细描述。
实施例1
在一个或多个实施方式公开的技术方案中,如图1所示,一种基于排队搜索的最优实验设计方法,包括如下步骤:
步骤1、获取待设计实验的基本实验信息,确定实验响应与实验因素之间的关系模型,根据各实验因素取值范围确定的实验设计空间中,随机生成N个实验设计作为初始种群;
步骤2、增加基于梯度的乘法算子在排队搜索过程中对实验设计进行更新,改进排队搜索策略;
采用基于乘法算子改进后的排队搜索策略,将种群中的实验设计根据适度值进行排队和更新,迭代搜索优化种群中的实验设计;
步骤3、满足排队搜索迭代的终止条件,输出种群中适度值最高的实验设计为最优实验设计。
本实施例中,提供了基于排队搜索的最优实验设计构造方法,解决了基于梯度的实验设计构造方法计算速度过慢,在计算时间有限的情况下可行解质量低下的问题。同时,使用基于梯度的乘法算子改进了排队搜索策略,解决了使用启发式算法构造最优实验设计时,容易过早收敛、产生局部最优解问题。
在一些实施例中,步骤1中,初始种群的构建,包括如下步骤:
步骤11、根据获取的实验目的、条件以及经验,得到实验基本实验信息;
可选的,实验基本实验信息包括实验响应、影响因素及其取值范围和各影响因素的水平数,各影响因素之间的约束关系,以及确定响应与因素之间的关系模型;
其中,实验响应即所关注的质量特性。
可选的,响应与因素之间的关系模型,具体确定方法如下:
基于实验影响因素与实验响应等实验基本信息,采用数学模型的形式给出响应与因素之间的关系模型,记为:
y=η(X,θ)+ε
其中,y为实验响应;X=(x
步骤12:根据各实验影响因素取值范围χ
步骤13:在设计空间内随机生成N个实验设计,记为ξ
实验设计ξ
作为一种可实现的实施方式,步骤2中,排队搜索策略在每次迭代过程中包括多个阶段,本实施例中设置有3个阶段,具体如下:
步骤21、设定最优函数为适度函数,计算种群中所有实验设计的适度值,并按照适度值将种群中实验设计排序;
具体的,本实施例中设置的适度函数可以采用A-最优准则和D-最优准则。
本实施例中,将判别实验设计最优性的最优函数设定为适度函数,该最优函数可以反应实验设计的统计效率,记为Ψ(ξ),为种群中的N个实验设计计算适度值,并按适度值从大到小为种群中的实验设计排序,设定当前迭代次数为g。
可选的,采用最优函数对实验设计ξ的信息矩阵求解,信息矩阵可以反应实验设计ξ中所含有的信息量。
本步骤中的Ψ(ξ)可以展开写为:
其中,M(ξ)是实验设计ξ的信息矩阵,信息矩阵计算公式为:
其中,X
步骤22、排队搜索的第一阶段,按照适度值大小创建多个队列,设置多个更新函数,按照队列的顺序自适应选择更新函数对队列中的实验设计进行更新,采用随机策略选择实验设计进行第二阶段的搜索;
步骤22中,采用随机策略选择,可以为每一个试验设计分配一个随机数,基于随机数与实验设计的适应度排序随机选择实验设计,进行下一阶段的搜索;
可选的,排队搜索的第一阶段,可以包括如下步骤:
步骤22.1、按照适度值大小创建多个队列,队列的容量按照队列最大的适度值计算;
一种实现的方式,队列的创建过程,包括:
22-1)、选取种群中适度值最大的前K个实验设计作为员工角色,对应每个员工角色创建一个队列,共创建K个队列,Queue
22-2)、按照每条队列的容量与该队列对应的员工角色的适度值成正比,根据员工角色的适度值大小计算对应队列的容量;
可选的,Queue
其中,Ψ(A
22-3)、根据适度值排序后的实验设计顺序,依次将对应容量数量实验设计归入对应的队列。
具体的,本实施例中,一个具体的实施例,在第一阶段,可以创建三个队列,即K=3。选取种群中适度值最大的3个实验设计作为员工角色,记为A
步骤22.2、设置第一阶段的更新函数,按照队列的顺序自适应选择更新函数,对每个队列的实验设计进行更新。
可选的,本实施例中设置了两个状态更新函数更新3个队列中所有实验设计的状态,更新函数分别是:
其中,
步骤22.2中,按照队列的顺序自适应选择更新函数对队列中的实验设计进行更新,其中,更新函数自适应选择的方法,具体为对种群中的所有实验设计更新状态并评估更新后的适度值,在更新时,按照队列的顺序根据前一个实验设计状态更新后适应度变化来选择更新函数,若前一粒子适度值提升,则同样使用该更新函数,否则更换;其中,队列的第一个实验设计使用第一个更新函数。
本实施例中,采用自适应方式选择更新函数,能够增强种群中试验设计的适应度提升概率。
步骤22.3、针对更新后的实验设计ξ
本实施例为每一个试验设计都分配了一个随机数,每一个试验设计都有几率进入第二阶段,以保证本方法的随机性,适度值越小的试验设计越容易进入第二阶段。
一种具体的实现方案,可以为种群中每一个实验设计ξ
其中,概率量Pr
其中,rank(Ψ(ξ
如果rand
步骤23、排队搜索的第二阶段,按照适度值大小创建多个队列后,设置基于梯度函数的乘法算子,通过乘法算子随机更新适应度最大的前K个实验设计的权重;更新后,按照队列的顺序自适应选择更新函数对队列中的实验设计进行更新,并计算适度值,采用随机策略选择对实验设计进行选择,进入下一阶段的搜索。
可选的,排队搜索的第二阶段,可以包括如下步骤:
步骤23.1、针对第一阶段搜索后得到的实验设计构建的种群,按照适度值大小创建多个队列,队列的容量按照队列最大的适度值计算;设置基于梯度函数的乘法算子,根据乘法算子更新实验设计中适应度最大的前K个实验设计;本步骤中K=3。
该步骤方法队列的创建方法,同步骤22.1。
以创建三个队列为实施例,选取种群中适度值最大的3个实验设计作为员工角色,记为A
第二阶段中通过乘法算子值更新员工角色,更新员工角色A
其中,
g(x,ξ)为梯度函数:
其中,Mξ)是实验设计ξ的信息矩阵,如下:
其中,X
基于梯度的乘法算子的确定方法为:基于实验设计信息矩阵,通过最优准则计算得到对应实验设计每个支撑点的梯度函数值,将实验设计梯度函数值占所有实验设计梯度函数值总和的比例,作为基于梯度的乘法算子,即为:
步骤23.2、设置第二阶段的状态更新函数,随机策略选择状态更新函数更新3个队列中所有实验设计的状态。
可选的,第二阶段状态更新函数可以设置两个,分别是:
其中,A为
第二阶段自适应选择更新函数,自适应选择方法与第一阶段相同,具体为对种群中的所有实验设计更新状态并评估更新后的适度值,在更新时,按照队列的顺序根据前一个实验设计状态更新后适应度变化来选择更新函数,若前一粒子适度值提升,则同样使用该更新函数,否则更换;其中,队列的第一个实验设计使用第一个更新函数。
步骤23.3:采用随机策略选择实验设计,进行下一阶段的搜索。
具体的,为参加第二阶段的每一个实验设计ξ
步骤24、排队搜索的第三阶段,为参加第三阶段的所有实验设计分配设定区间的随机数,通过实验设计适应度排序计算得到每个实验设计的乘法算子概率量,针对乘法算子概率量大于随机数的实验设计,通过基于梯度的乘法算子更新实验设计;然后对乘法算子概率量小于随机数的实验设计,设置第三阶段更新函数进行状态更新。
具体的,开始第三阶段,为参加第三阶段的所有实验设计ξ
使用状态更新函数,为每个参与第三阶段的实验设计中rand
其中ξ
重复步骤2中的步骤21至步骤24,直到当前迭代次数g等于最大迭代次数max
实施例2
基于实施例1,本实施例中提供实施例1方法在logistic模型构造D-最优实验设计的应用。
logistic模型为:
其中μ为线性预测器。为含有6个参数和5个因素的logistic模型构造D-最优实验设计,详细说明本方法。
步骤1:设定模型为:
步骤2:设定各因素取值范围分别为χ
步骤3:在设计空间内随机生成500个实验设计,设定最大迭代次数max
步骤4:使用实施例1中所述的排队搜索策略,优化种群中的实验设计。
步骤5:选取种群中适度值最大的实验设计,将其输出。
表1显示了参数值为θ
表1 Logistic模型参数值为θ
表2显示了参数值为θ
表2Logistic模型参数值为θ
使用已有的PSO、DE、GA、SaDE和原始版本QSA与本发明方法从实验设计优越性和构造实验设计的效率对比。
PSO算法是粒子群算法,也称粒子群优化算法或鸟群觅食算法(Particle SwarmOptimization),缩写为PSO。
DE算法:DE(Differential Evolution)差分进化算法是一种新兴的进化计算技术,通过采用浮点矢量进行编码生成种群个体。
GA算法:遗传算法(genetic algorithm)是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程算模型,是一种通过模拟自然进化过程捜索最优解的方法。
SaDE算法:是自适应差分算法,SaDE算法是对DE算法的改进。
QSA算法:是排队搜索算法,采用模拟人类排队行为的策略解决优化问题。
其中,参数值为θ
参数值为θ
图2、图3表示了在该实施例设置下,独立运行本方法Proposed Algorithm、原始版本QSA、DE、SaDE、PSO和GA各100次,得出的平均优化历史。从图中可以看出,本方法对比其他方法,取得的试验设计适度值更高,并且收敛所用的迭代步骤比DE、SaDE、GA更少。对比原始版本QSA,本方法获得的试验设计适度值有明显提升。
实施例3
基于实施例1,本实施例提供实施例1方法在Poisson模型构造D-最优实验设计的应用。
Poisson模型为E(Y|X)=
为含有7个参数和3个因素的Poisson模型构造D-最优实验设计,详细说明本方法。
步骤1:设定模型为:
步骤2:设定各因素取值范围分别为χ
步骤3:在设计空间内随机生成500个实验设计,设定最大迭代次数max
步骤4:使用实施例1所述排队搜索策略,优化种群中的实验设计。
步骤5:选取种群中适度值最大的实验设计,将其输出。
表3显示了参数值为θ
表3 Poisson模型参数值为θ
表4显示了参数值为θ
表4 Poisson模型参数值为θ
使用已有的PSO、DE、GA、SaDE和原始版本QSA与本发明方法从实验设计优越性和构造实验设计的效率对比。
其中,参数值为θ
其中,参数值为θ
图4、图5表示了在该实施例设置下,独立运行本方法Proposed Algorithm、原始版本QSA、DE、SaDE、PSO和GA各100次,得出的平均优化历史。图图4和图5中可以看出,本方法的收敛使用的迭代次数对比DE、GA、SaDE更少,并且取得了更高的试验设计适度值;对比原始版本QSA取得的试验设计适度值有明显提升;对比PSO方法在试验设计适度值方面也有明显优势。
实施例4
基于实施例1,本实施例提供实施例1方法在壁碳纳米管吸附咖啡因实验的多项式模型构造D-最优实验设计中的应用。详细说明实施例1的方法。
步骤1:设定模型为:q=θ
其中,q代表咖啡因吸附能力,C代表初始咖啡因浓度,M代表壁碳纳米管质量,t代表反应时间。
此模型有3个因素和8个参数。根据相关现有技术中的相关实验设定参数猜测值为:
θ
步骤2:设定各因素取值范围,取值范围与变量信息见表5。
表5
步骤3:在设计空间内随机生成500个实验设计,设定最大迭代次数max
步骤4:使用实施例1所述排队搜索策略,优化种群中的实验设计。
步骤5:选取种群中适度值最大的实验设计,将其输出。
表6显示了本方法在此实施案例设置下,独立运行100次后,为壁碳纳米管吸附咖啡因实验取得适度值最优的实验设计结果。
表6
实施例5
基于实施例1,本实施例提供基于排队搜索的最优实验设计系统,包括:
种群生成模块:被配置为获取待设计实验的基本实验信息,随机生成实验设计作为初始种群;
改进模块:被配置为增加基于梯度的乘法算子在排队搜索过程中对实验设计进行更新,改进排队搜索策略;
排队搜索模块:被配置为采用基于乘法算子改进后的排队搜索策略,将种群中的实验设计根据适度值进行排队和更新,迭代搜索优化种群中的实验设计;
最优实验设计输出模块:被配置为满足排队搜索迭代的终止条件,输出种群中适度值最高的实验设计为最优实验设计。
此处需要说明的是,本实施例中的各个模块与实施例1中的各个步骤一一对应,其具体实施过程相同,此处不再累述。
实施例6
本实施例提供一种电子设备,包括存储器和处理器以及存储在存储器上并在处理器上运行的计算机指令,所述计算机指令被处理器运行时,完成实施例1的方法所述的步骤。
实施例7
本实施例提供一种计算机可读存储介质,用于存储计算机指令,所述计算机指令被处理器执行时,完成实施例1的方法所述的步骤。
以上所述仅为本公开的优选实施例而已,并不用于限制本公开,对于本领域的技术人员来说,本公开可以有各种更改和变化。凡在本公开的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本公开的保护范围之内。
上述虽然结合附图对本公开的具体实施方式进行了描述,但并非对本公开保护范围的限制,所属领域技术人员应该明白,在本公开的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本公开的保护范围以内。
- 基于速度时间图的最优速度搜索方法及系统
- 基于自适应罗盘搜索算法的火电厂同步发电机励磁系统最优参数整定方法