基于外耳的位移的虚拟传声器校准
文献发布时间:2024-04-18 19:52:40
技术领域
本公开总体上涉及头戴式设备(headset)中的音频系统,并且具体地,涉及基于头戴式设备的用户的外耳的位移的虚拟传声器校准。
背景技术
头戴式设备可以向用户提供音频内容。常规地,为了校准头戴式设备以向用户提供空间化声音,将传声器放置在用户的耳道中(通常在耳道入口处)。由传声器采集到的声音用于校准和均衡系统的输出,然后,使用头相关传递函数(head-related transferfunction,HRTF)来递送3D空间化声音。该设备可以使用HRTF来生成音频内容,该音频内容经由一个或多个扬声器来呈现,以提供空间化音频内容。为了确保高再现质量,可以在采集HRTF的同一点处均衡一个或多个扬声器。然而,使用耳朵内的传声器来校准头戴式设备并不总是实用的或理想的。
发明内容
因此,本发明涉及根据所附权利要求的方法、系统和计算机可读非暂态存储介质。
本文描述了一种音频系统。该音频系统被配置为基于用户的一只或两只耳朵的位移来校准虚拟传声器。对于用户的耳朵,音频系统(例如,经由换能器)生成校准信号,并且(例如,经由位移传感器)测量可能部分地由于校准信号而引起的耳朵的一部分的位移。音频系统将位移信息作为输入提供给模型,该模型被配置为输出所估计的耳朵的耳道入口处的声压。因此,音频系统可以模拟在耳道入口处的虚拟传声器将如何检测音频内容。在一些实施例中,音频系统的一个或多个位移传感器被集成到该音频系统的一个或多个换能器中。例如,结合到用户的耳朵的软骨传导换能器(例如,被配置为经由软骨传导来呈现音频内容)可以包括位移传感器和/或耦接到位移传感器,该位移传感器在软骨传导换能器振动耳朵时测量耳朵的位移。
经由一个或多个换能器向用户呈现音频内容。一个或多个传感器监测用户的耳廓的至少一部分的位移,所述位移部分地是由所呈现的音频内容引起的。基于耳廓的一部分的位移来估计用户的耳道入口处的声压。使用经远程估计的耳道入口处的声压来生成换能器的声音滤波器,并且使用所生成的滤波器来调整音频内容。随后,换能器向用户呈现调整后的音频内容。
在一些实施例中,公开了一种校准虚拟传声器的音频系统。音频系统包括换能器、一个或多个传感器以及控制器。换能器被配置为测量用户的耳廓的一部分的位移,所述位移是由所呈现的音频内容引起的。控制器被配置为基于所监测的耳廓的一部分的位移来估计用户的耳道入口处的声压,使用所估计的声压来生成用于换能器的声音滤波器,并且使用所生成的滤波器来调整音频内容。控制器指示换能器向用户呈现调整后的音频内容。
在根据本发明的音频系统的一些实施例中,换能器可以是被配置为呈现音频内容的软骨传导换能器。一个或多个传感器中的一者可以是软骨传导换能器。另外,该系统还可以被配置为通过测量软骨传导换能器的预载荷量(preload)来监测用户的耳廓的一部分的位移。
在根据本发明的音频系统的一些实施例中,一个或多个传感器还可以包括加速度传感器和光学位移传感器中的至少一者。
在根据本发明的音频系统的一些实施例中,换能器可以是被配置为经由空气传导而向用户呈现音频内容的扬声器。
在根据本发明的音频系统的一些实施例中,估计耳道入口处的声压还可以包括:控制器被配置为将所监测的耳廓的一部分的位移作为输入提供给模型,该模型被配置为基于耳廓的位移输出耳道入口处的声压。另外,模型可以包括卷积神经网络、线性模型和数值模拟中的至少一者。替代地或另外地,模型可以被配置为接收用户的耳朵的几何形状作为输入,该几何形状包括根据用户的耳朵的一幅或多幅图像确定的测量结果。
在根据本发明的音频系统的一些实施例中,调整后的音频内容具有目标幅度的频率响应。
本发明还涉及一种基于用户的一只或两只耳朵的位移来校准虚拟传声器的方法。经由一个或多个换能器向用户呈现音频内容。一个或多个传感器监测用户的至少一部分耳廓的位移,所述位移部分地是由所呈现的音频内容引起的。基于耳廓的一部分的位移来估计用户的耳道入口处的声压。使用在经远程估计的耳道入口处的声压来生成换能器的声音滤波器,并且使用所生成的滤波器来调整音频内容。随后,换能器向用户呈现调整后的音频内容。
在根据本发明的方法的一些实施例中,换能器可以是被配置为呈现音频内容的软骨传导换能器。一个或多个传感器中的一者可以是软骨传导换能器。此外,该方法还可以包括通过测量软骨传导换能器的预载荷量来监测用户的耳廓的一部分的位移。
在根据本发明的方法的一些实施例中,一个或多个传感器还可以包括加速度传感器和光学位移传感器中的至少一者。
在根据本发明的方法的一些实施例中,换能器可以是被配置为经由空气传导而向用户呈现音频内容的扬声器。
在根据本发明的方法的一些实施例中,估计耳道入口处的声压还可以包括:将所监测的耳廓的一部分的位移作为输入提供给模型,该模型被配置为基于耳廓的位移输出耳道入口处的声压。另外,该模型可以包括卷积神经网络、线性模型和数值模拟中的至少一者。替代地或另外地,该模型可以被配置为接收用户的耳朵的几何形状作为输入,该几何形状包括根据用户的耳朵的一幅或多幅图像确定的测量结果。
在根据本发明的方法的一些实施例中,调整后的音频内容具有目标幅度的频率响应。
附图说明
图1A为根据一个或多个实施例的被实现为眼镜设备的头戴式设备的立体图,该头戴式设备被配置为校准虚拟传声器。
图1B为根据一个或多个实施例的被实现为头戴式显示器的头戴式设备的立体图,该头戴式设备被配置为校准虚拟传声器。
图2为根据一个或多个实施例的被配置为校准虚拟传声器的头戴式设备的一部分的侧视图。
图3A为根据一个或多个实施例的软骨传导换能器的框图,该软骨传导换能器被配置为利用电容式位移传感器来监测用户耳朵的位移。
图3B为根据一个或多个实施例的软骨传导换能器的框图,该软骨传导换能器被配置为利用光学编码器来监测用户耳朵的位移。
图4为根据一个或多个实施例的音频系统的框图。
图5为根据一个或多个实施例的用于校准虚拟传声器的过程的流程图。
图6为根据一个或多个实施例的示例人工现实系统环境的框图。
这些附图仅出于例示目的而描绘了各种实施例。本领域的技术人员将从以下讨论容易地认识到,在不脱离本文描述的原理的情况下,可以采用本文所例示的结构和方法的替代实施例。
具体实施方式
音频系统对位于用户耳朵的耳道入口处的“虚拟传声器”进行校准。实际上,虚拟传声器是通过表征如何在耳道入口处检测到声音,而在耳道入口处模拟传声器的存在。音频系统经由换能器播放校准信号,并且随后测量部分地由校准信号引起的用户用户的至少一部分的位移。音频系统将位移信息作为输入提供给模型,该模型输出所估计的用户耳朵的耳道入口处的声压。在一些实施例中,音频系统为用户的两只耳朵校准虚拟传声器。音频系统可以使用所估计的耳道入口处的声压来生成声音滤波器,并且使用所述声音滤波器调整用户的音频内容。
头戴式设备可以向用户呈现音频内容。为了改善用户的听觉体验,常规音频系统需要用户在耳朵的耳道入口处放置一目标传声器。因此,音频系统表征了如何在耳道入口处感知声音。然而,这种常规校准技术对于用户来说通常是不实用或不舒服的。相比之下,本文中所描述的音频系统消除了对常规校准技术的需求,即校准用户的一只耳朵或两只耳朵的耳道入口处的虚拟传声器。
本发明的实施例可以包括人工现实系统或者结合人工现实系统来实现。人工现实是在呈现给用户之前已经以某种方式进行了调整的现实形式,该人工现实可以包括例如虚拟现实(virtual reality,VR)、增强现实(augmented reality,AR)、混合现实(mixedreality,MR)、混合现实(hybrid reality)或它们的某种组合和/或衍生型。人工现实内容可以包括完全生成的内容或与采集到的(例如,真实世界)内容进行组合而生成的内容。人工现实内容可以包括视频、音频、触觉反馈或它们的某种组合,并且以上任何一种都可以以单通道或多通道(例如,为观看者带来三维效果的立体视频)来呈现。此外,在一些实施例中,人工现实还可以与应用程序、产品、附件、服务或它们的某种组合相关联,这些应用程序、产品、附件、服务或它们的某种组合用于在人工现实中创建内容,和/或以其它方式用于人工现实中(例如,在人工现实中执行活动)。提供人工现实内容的人工现实系统可以在各种平台上实现,这些平台包括连接到主控计算机系统的头戴式设备(例如,头戴式显示器(head-mounted display,HMD)和/或近眼显示器(near-eye display,NED))、独立头戴式设备、移动设备或计算系统、或能够向一位或多位观看者提供人工现实内容的任何其它硬件平台。
系统概述
图1A为根据一个或多个实施例的被实现为眼镜设备的头戴式设备100的立体图,该头戴式设备100被配置为校准虚拟传声器。在一些实施例中,眼镜设备是近眼显示器(NED)。通常,头戴式设备100可以被佩戴在用户的面部上,使得内容(例如,媒体内容)是使用显示组件和/或音频系统来呈现的。然而,头戴式设备100还可以以这样的方式使用:即以不同的方式向用户呈现媒体内容。由头戴式设备100呈现的媒体内容的示例包括一幅或多幅图像、视频、音频或它们的某种组合。头戴式设备100包含镜框,并且可以包括显示组件(该显示组件包括一个或多个显示元件120)、深度摄像头组件(depth camera assembly,DCA)以及音频系统等其他部件。尽管图1A示出了头戴式设备100的部件位于头戴式设备100上的示例位置,但是这些部件可以位于头戴式设备100上的其它位置,位于与头戴式设备100配对的外围设备上,或者它们的某种组合。类似地,头戴式设备100上可以存在比图1A中示出的部件更多或更少的部件。
镜框110保持头戴式设备100的其它部件。镜框110包括:保持一个或多个显示元件120的前部,以及附接到用户头部的端件(例如,镜腿)。镜框110的前部跨过用户鼻子的顶部。端件的长度可以是可调整的(例如,可调整的镜腿长度)以适合不同的用户。端件还可以包括在用户的耳朵后面弯曲的部分(例如,腿套、眼镜脚)。
一个或多个显示元件120向正佩戴着头戴式设备100的用户提供光。如所示出的,对于用户的每只眼睛,头戴式设备包括一显示元件120。在一些实施例中,显示元件120生成图像光,该图像光被提供到头戴式设备100的适眼区(eyebox)。适眼区是用户在佩戴头戴式设备100时的眼睛所占据的空间中的位置。例如,显示元件120可以是波导显示器。波导显示器包括光源(例如,二维源、一个或多个线源、一个或多个点源等)和一个或多个波导。来自光源的光被内耦合到一个或多个波导中,该一个或多个波导以使得在头戴式设备100的适眼区中存在瞳孔复制的方式输出光。光的内耦合和/或光从一个或多个波导的外耦合可以使用一个或多个衍射光栅来完成。在一些实施例中,波导显示器包括扫描元件(例如,波导、反射镜等),该扫描元件在来自光源的光被内耦合到一个或多个波导中时对该光进行扫描。注意,在一些实施例中,两个显示元件120中的一者或两者是不透明的,并且不透射来自头戴式设备100周围的局部区域的光。该局部区域是头戴式设备100周围的区域。例如,该局部区域可以是正佩戴着头戴式设备100的用户处于其内部的房间,或者正佩戴着头戴式设备100的用户可能在外部并且该局部区域是户外区域。在这种背景下,头戴式设备100生成VR内容。替代地,在一些实施例中,两个显示元件120中的一者或两者是至少部分透明的,使得来自局部区域的光可以与来自该一个或多个显示元件的光组合,以生成AR内容和/或MR内容。
在一些实施例中,显示元件120不生成图像光,而是改用将来自局部区域的光传输到适眼区的透镜(lens)。例如,两个显示元件120中的一者或两者可以是未矫正(非处方用)的透镜或处方用透镜(例如,单光透镜、双焦和三焦透镜或渐变透镜),以有助于矫正用户的视力缺陷。在一些实施例中,显示元件120可以是偏光的和/或有色的,以保护用户的眼睛免受太阳影响。
在一些实施例中,显示元件120可以包括附加的光学器件块(optics block)(未示出)。光学器件块可以包括将来自显示元件120的光引导到适眼区的一个或多个光学元件(例如,透镜、菲涅耳透镜等)。光学器件块可以例如校正一些或全部图像内容中的像差、放大一些或全部图像或它们的某种组合。
DCA确定头戴式设备100周围的局部区域的一部分的深度信息。DCA包括一个或多个成像设备130和DCA控制器(图1A中未示出),并且还可以包括照明器140。在一些实施例中,照明器140利用光来照亮局部区域的一部分。该光可以是例如红外(infrared,IR)结构光(例如,点状图案结构光、条形结构光等)、用于飞行时间(time-of-flight)的IR闪光灯等。在一些实施例中,该一个或多个成像设备130采集局部区域中包括来自照明器140的光的部分的图像。如所示出的,图1A示出了单个照明器140和两个成像设备130。在替代实施例中,不存在照明器140且存在至少两个成像设备130。
DCA控制器使用采集到的图像和一种或多种深度确定技术,来计算局部区域的一部分的深度信息。深度确定技术可以是例如直接飞行时间(time-of-flight,ToF)深度感测、间接ToF深度感测、结构光、被动式立体分析、主动式立体分析(使用通过来自照明器140的光而添加到场景中的纹理)、用于确定场景的深度的某种其它技术或它们的某种组合。在一些实施例中,头戴式设备100可以针对头戴式设备100的位置以及局部区域的模型的更新而提供同步定位与地图构建(simultaneous localization and mapping,SLAM)。例如,头戴式设备100可以包括生成彩色图像数据的无源摄像头组件(passive camera assembly,PCA)。PCA可以包括采集局部区域中的一些或全部部分的图像的一个或多个RGB摄像头。在一些实施例中,DCA中的一些或全部成像设备130也可以用作PCA。由PCA采集的图像和由DCA确定的深度信息可以用于确定局部区域的参数、生成局部区域的模型、更新局部区域的模型或它们的某种组合。在一些实施例中,传感器阵列(如以下讨论的)响应于头戴式设备100的运动而生成测量信号,并且追踪头戴式设备100在房间内的定位(例如,位置和姿态)。
音频系统向用户呈现音频内容。音频系统包括换能器阵列、传感器阵列和音频控制器160。然而,在其它实施例中,音频系统可以包括不同的部件和/或附加的部件。类似地,在一些情况下,参考音频系统中的部件描述的功能可以按照与本文描述的方式不同的方式分布在这些部件之中。例如,该控制器的一些或全部功能可以由远程服务器执行。
换能器阵列向用户呈现声音。换能器阵列包括一个或多个换能器,该一个或多个换能器包括一个或多个组织传导换能器170和一个或多个空气传导换能器180。在一些实施例中,该换能器阵列中的一个或多个换能器被装在镜框110内。在一些实施例中,头戴式设备100包括沿着镜框110的每条镜腿的一个或多个换能器和/或在镜框110的每条镜腿的端部处的一个或多个换能器。因此,多个换能器可以改善所呈现的音频内容的方向性。
一个或多个组织传导换能器170经由组织传导生成声音。每个组织传导换能器170可以是例如软骨传导换能器和/或骨传导换能器。组织传导换能器170结合到用户的组织(例如,骨和/或软骨)并且直接振动用户的组织,以生成由用户的至少一只内耳感知的声波。由此,用户将该声波感知为声音。每个组织传导换能器170被定位成接近和/或接触用户耳朵的组织(例如,在耳廓的背面)。在一些实施例中,头戴式设备100在用户的每只耳朵处包括至少一个组织传导换能器170。组织传导换能器170的数量和/或位置可以与图1A中示出的数量和/或位置不同。
一个或多个空气传导换能器180经由空气传导生成声音。空气传导换能器180可以是例如扬声器,该扬声器生成由用户的至少一只内耳感知为声音的声波。在一些实施例中,多个空气传导换能器180被定位在头戴式设备100的镜框110上和/或沿着头戴式设备100的镜框110定位。空气传导换能器180的数量和/或位置可以与图1A中示出的数量和/或位置不同。
头戴式设备100的传感器阵列测量各种参数。传感器阵列包括一个或多个声学传感器185和一个或多个位移传感器190。在一些实施例中,除了本文中所描述的那些传感器之外和/或代替本文中所描述的那些传感器,传感器阵列还包括附加的传感器。
一个或多个声学传感器185检测头戴式设备100的局部区域内的声音。声学传感器185采集从局部区域(例如,房间)中包括换能器阵列的一个或多个声源发出的声音。由声学传感器185检测到的声音用于校准用户的耳道入口处的“虚拟”传声器。虚拟传声器不是物理设备,而改为是虚拟设备,该虚拟传声器模拟传声器的存在,并因此可以被头戴式设备100使用以表征如何在虚拟传声器的模拟位置处感知声音。例如,头戴式设备100能够基于在耳道入口处的经校准的虚拟传声器来更好地呈现空间化音频内容。
每个声学传感器被配置为检测声音并将检测到的声音转换为电子格式(模拟或数字)。声学传感器185可以是声波传感器、传声器、声音换能器或适于检测声音的类似传感器。在一些实施例中,声学传感器185可以被放置在头戴式设备100的外表面上、被放置在头戴式设备100的内表面上、与头戴式设备100分开(例如,是某种其他设备的一部分)或它们的某种组合。声学传感器185的数量和/或位置可以与图1A中示出的数量和/或位置不同。例如,可以增加声学检测位置的数量,以增加收集到的音频信息量以及该信息的灵敏度和/或准确度。声学检测位置可以被定向为使得虚拟传声器被校准以考虑正佩戴着头戴式设备100的用户周围的宽范围方向上的声音。
一个或多个位移传感器190测量用户的耳朵的多个部分的位移。例如,位移传感器190可以各自结合到用户的一只耳朵。在由一个或多个换能器生成音频内容之后,耳朵的每个部分可以部分地由于该音频内容而振动。因此,位移传感器190测量部分地由于部分耳朵的振动引起的位移。在一些实施例中,头戴式设备100可以为用户的每只耳朵指定一个以上的位移传感器190。各个位移传感器190可以被配置为测量用户耳朵的各个部分的位移。位移传感器190可以是光学位移传感器、惯性测量单元、加速度计、速度计、陀螺仪或检测运动的另一合适类型的传感器或它们的某种组合。
位移传感器190可以被定位在除了图1A中示出的那些位置之外的其他位置中。在一些实施例中,位移传感器190测量由于振动而引起的用户的面部组织的一部分的位移。例如,位移传感器190可以测量用户的太阳穴、前额等的一部分的位移。在一些实施例中,上述位移传感器190中的一者或更多者可以耦接到头戴式设备100中的与用户的鼻子接触的部分。因此,这些位移传感器190测量由用户语音的骨传导引起的面部组织的位移。
在一些实施例中,至少一个位移传感器190是组织传导换能器的一部分,并且位于组织传导换能器内部。例如,位移传感器190可以测量用户耳朵中的结合到组织传导换能器的部分的位移。关于图3A和图3B,对包括位移传感器的软骨传导换能器的实施例进行了更详细地描述。
音频控制器160处理来自传感器阵列的信息,并指示换能器阵列呈现音频内容。在一些实施例中,音频控制器160基于位移传感器190的测量结果,来校准用户的耳道入口处的虚拟传声器。音频控制器160可以为用户的一只耳朵或两只耳朵(例如,在耳道的每个入口处)校准虚拟传声器。对于给定的耳朵,音频控制器160将该耳朵的至少一部分的位移的测量结果作为输入。由音频控制器160执行的模型使用所测量的位移信息到所估计的耳朵的耳道入口处的声压的函数映射,来将所测量的位移信息与所估计的声压相关联。因此,音频控制器160输出所估计的耳道入口处的声压,基于所估计的声压,音频控制器160可以生成声音滤波器,并将声音滤波器应用于音频内容。例如,声音滤波器可以更好地空间化音频内容,防止声音泄漏(例如,通过放大和/或衰减音频内容的一些或全部频率),并且改善音频内容的清晰度(例如,通过对用户可能以其他方式误听的频率进行增强)。另外,用户可以体验经改善的音频质量,并且更自然地感知音频内容。音频控制器160指示换能器阵列呈现所得到的经滤波的音频内容。在一些实施例中,音频控制器160可以包括处理器和计算机可读存储介质。另外,音频控制器160可以被配置为生成波达方向(direction of arrival,DOA)估计结果、生成声学传递函数(例如,阵列传递函数和/或头相关传递函数)、追踪声源的位置、在声源的方向上形成波束、对声源进行分类或它们的某种组合。
图1B为根据一个或多个实施例的被实现为头戴式显示器的头戴式设备的立体图,该头戴式设备被配置为校准虚拟传声器。在描述AR系统和/或MR系统的实施例中,HMD的正面的多个部分对于可见波段(~380nm(纳米)至750nm)是至少部分透明的,并且HMD中的位于HMD正面与用户眼睛之间的多个部分是至少部分透明的(例如,部分透明的电子显示器)。HMD包括前部刚性体115和带195。头戴式设备105包括与上面参考图1A描述的部件相同的一些部件,但是这些部件被修改为与HMD形状因子(form factor)结合。例如,HMD包括显示组件、DCA和音频系统。图1B示出了多个成像设备130、照明器140、音频控制器160、组织传导换能器170、空气传导换能器180、声学传感器185和位移传感器190。不同的部件可以位于各种位置,例如,被耦接到带195(如所示出的)、被耦接到前部刚性体115、或者可以被配置为插入用户的耳道内。
用于校准虚拟传声器的头戴式设备
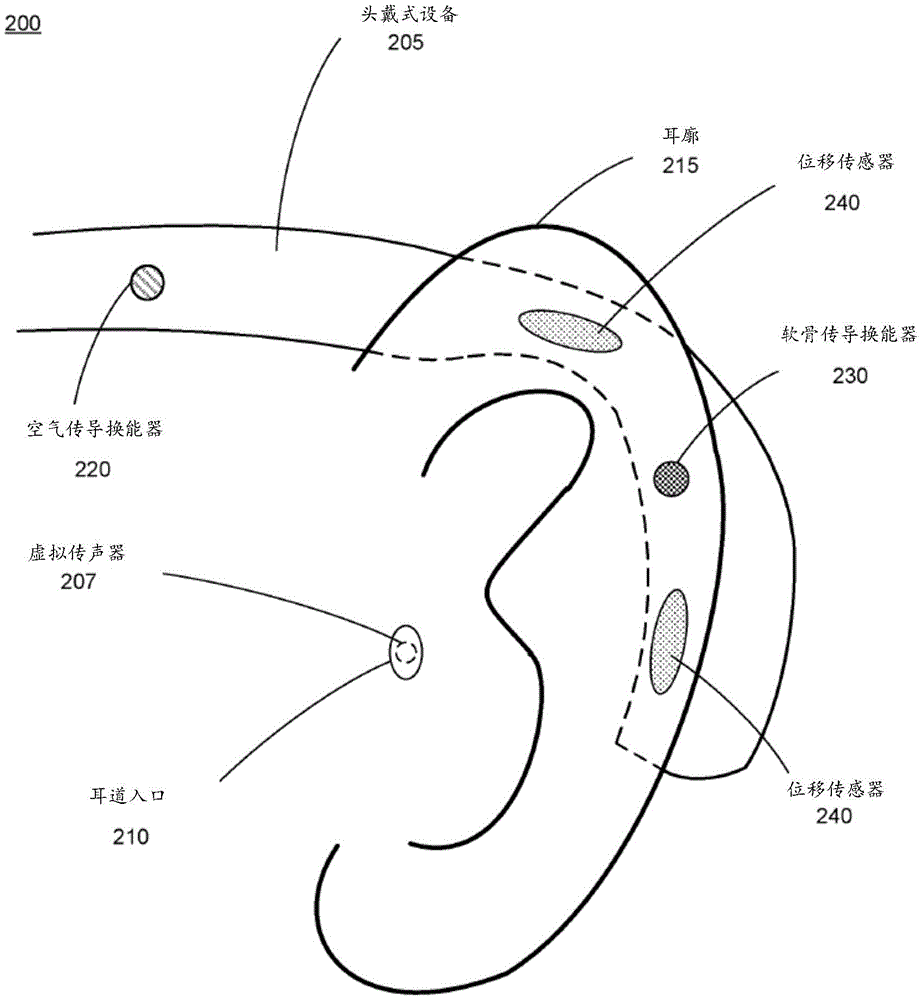
图2为根据一个或多个实施例的被配置为校准虚拟传声器207的头戴式设备205的一部分的侧视图。头戴式设备205模拟在用户耳朵的耳道入口210处的虚拟传声器207的存在。虚拟传声器207用于表征如何在耳道入口210处感知音频内容。在图2中示出的头戴式设备205的一部分包括空气传导换能器220、软骨传导换能器230以及一个或多个位移传感器240。头戴式设备205可以是图1A的头戴式设备100的实施例,并且因此,还可以包括除了本文中所示出的那些部件之外的部件。例如,头戴式设备205可以包括控制器、显示器组件等。
空气传导换能器220可以向用户呈现音频内容。空气传导换能器220可以是经由空气传导呈现音频内容的扬声器。在一些实施例中,空气传导换能器220是头戴式设备205的换能器阵列中的部件。在一些实施例中,换能器阵列包括被配置为向用户的一只耳朵或两只耳朵提供音频内容的多个空气传导换能器。
软骨传导换能器230可以经由软骨传导向用户呈现音频内容。软骨传导换能器230可以被直接地和/或间接地定位成与耳朵的组织接触和/或接近耳朵。软骨传导换能器230使耳朵中的与之接触的部分振动,从而生成一系列声压波,这些声压波被用户的内耳的耳蜗(图2中未示出)检测为声音。在图2中,当用户佩戴头戴式设备205时,软骨传导换能器230与耳廓210接触。在其它实施例中,软骨传导换能器230可以被定位成与耳朵的耳屏、耳朵的耳垂、耳朵的某一其它部分或它们的某种组合接触。在一些实施例中,软骨传导换能器230是头戴式设备205的换能器阵列中的部件。在一些实施例中,换能器阵列包括被配置为向用户的一只耳朵或两只耳朵提供音频内容的多个软骨传导换能器。
位移传感器240测量耳廓210的一部分的位移。在一些实施例中,多个位移传感器240中的一者被结合到耳廓210的背面的一部分。在其它实施例中,多个位移传感器340中的至少一者被结合到耳廓210的顶部。当耳廓210由于换能器220生成的音频内容和/或软骨传导换能器230的软骨传导而振动时,位移传感器240测量耳廓210的位移。位移传感器240可以是加速度传感器、光学位移传感器或它们的某种组合。在一些实施例中,位移传感器240被集成到软骨传导换能器230中和/或被耦接到软骨传导换能器230。例如,位移传感器240可以测量用户耳朵中的结合到组织传导换能器的部分的位移。关于图3A至图3B进行更详细地描述。
在一些实施例(未示出)中,一个或多个位移传感器测量用户面部的位移和/或耳朵的其它部分的位移,这些部分响应于换能器220生成的音频内容和/或软骨传导换能器230而移动和/或振动。例如,位移传感器可以与用户面部的太阳穴、前额等的一部分接触并测量该部分的位移。
经由软骨传导换能器监测耳朵的位移
图3A为根据一个或多个实施例的软骨传导换能器300的框图,该软骨传导换能器300被配置为利用电容式位移传感器310监测用户的耳朵的位移。软骨传导换能器300经由软骨传导向用户呈现音频内容,并且被配置为测量用户耳朵的一部分的位移。软骨传导换能器300可以是头戴式设备(例如,头戴式设备205)的部件,并且是与位移传感器240耦接的软骨传导换能器230的实施例。软骨传导换能器300包括磁体320A和320B(统称为磁体320)、移动线圈330、接触垫340、预加载弹簧350和电容式位移传感器310。软骨传导换能器300可以包括除了图3A中所示出的这些部件之外的其他部件。
磁体320生成使移动线圈330振动的磁场。磁体320包括软磁体和/或硬磁体。例如,磁体320A可以是软磁体且磁体320B可以是硬磁体。软磁体可以由钢和/或镀镍制成,而硬磁体可以是钕磁体和/或镀锌。软骨传导换能器300可以包括除了图3A和图3B中所示出的这些磁体之外的磁体。
移动线圈330响应于输入信号并且由于磁体320生成的磁场而振动。当电流通过时,移动线圈330经历洛伦兹力,该洛伦兹力使得移动线圈330按照输入信号中指定的频率振动。移动线圈330可以是印刷电路板(printed circuit board,PCB),或者可以是具有足够刚性以接收洛伦兹力的另一结构。在一些实施例中,移动线圈330可以包括柔性印刷电路。
接触垫340被结合到用户的耳朵的组织。为了经由软骨传导呈现音频内容,软骨传导换能器300使用户的耳朵处的和/或在用户的耳朵附近的组织(例如,耳廓)振动。接触垫340与该组织直接接触和/或间接接触,该组织随着移动线圈330的移动而振动。
预加载弹簧350将软骨传导换能器300定位为与用户耳朵的组织接触。当用户佩戴包括软骨传导换能器300的头戴式设备时,预加载弹簧350被配置为将软骨传导换能器300定位为在标称位置与用户的耳朵接触。当软骨传导换能器300处于标称位置时,预加载弹簧350在抵靠用户耳朵的组织而振动时可以具有可预测的响应。当被测量时,预加载弹簧350的位移表征从软骨传导换能器300到耳朵的组织的接触力。在一些实施例中,预加载弹簧350可以用作错误检测机构。例如,当预加载弹簧350的预载荷量超过阈值量,使得软骨传导换能器300可能不与用户耳朵的组织接触时,可以通知用户头戴式设备需要重新定位。
电容式位移传感器310测量接触垫340的位移。当软骨传导换能器300经由软骨传导呈现音频内容时,位移可以部分地归因于移动线圈330的振动。电容式位移传感器310相应地测量耳朵中的接触垫340所结合到的并因此是软骨传导换能器300所结合到的一部分的位移。例如,软骨传导换能器300可以(例如,从头戴式设备的控制器)接收指令以呈现音频内容。移动线圈330在呈现音频内容时振动,使得该移动线圈330从其静止位置移位。移动线圈330的位移使电容式位移传感器310检测到的电容值变化。在一些实施例中,电容式位移传感器310确定由空气传导换能器(例如,换能器220)呈现的音频内容引起的耳廓210的位移。在一些实施例中,电容式位移传感器310以这种方式构造:该电容式位移传感器310包括两个相距一定距离的电极从而形成电容器。当移动线圈330振动时,电容式位移传感器310的两个电极之间的距离变化,从而改变电容。在其他实施例中,电容式位移传感器310被构造为与本文中所描述的电容式位移传感器不同。
图3B为根据一个或多个实施例的软骨传导换能器350的框图,软骨传导换能器350被配置为利用光学编码器370监测用户耳朵的位移。该软骨传导换能器350在结构上和功能上与软骨传导换能器300类似,不同之处在于该软骨传导换能器350包括用于测量用户耳朵的位移的光学编码器370而非电容式位移传感器310。光学编码器370可以具有较高敏感度,并且因此可以用于测量用户耳朵的较小位移量值。在一些实施例中,软骨传导换能器350在结构上和/或功能上与软骨传导换能器300不同。
当软骨传导换能器350经由软骨传导呈现音频内容时,光学编码器370测量由于移动线圈330的振动而引起的接触垫340的位移。类似于电容式位移传感器310,光学编码器370可以用于确定由软骨传导换能器350和/或空气传导换能器引起的用户耳朵的组织的一部分的位移。例如,光学编码器370可以用于确定耳廓210的位移。在一些实施例中,光学编码器370包括光源(例如,LED)以及在移动线圈330正在振动时使该光源所发射出的光移动的机构(例如,轴)。因此,光学编码器370监测由于移动线圈330而引起的光的位置,从而测量耳朵中的软骨传导换能器350所结合到的部分的位移。
音频系统概述
图4为根据一个或多个实施例的音频系统400的框图。音频系统400向用户提供音频内容。在一些实施例中,音频系统400校准:(1)定位在用户左耳的耳道入口(例如,耳道入口215)处的虚拟传声器;(2)定位在用户右耳的耳道入口处的虚拟传声器,或(3)定位在右耳和左耳的相应耳道入口处的虚拟传声器。音频系统可以部分地基于经校准的虚拟传声器来调整用户的音频内容。音频系统400可以是头戴式设备(例如,头戴式设备100、105)中的部件和/或被耦接到头戴式设备(例如,头戴式设备100、105)。音频系统400包括换能器阵列410、传感器阵列420和控制器430。在一些实施例中,音频系统400包括附加的部件。
换能器阵列410根据来自控制器430的指令向用户呈现音频内容。换能器阵列410包括一个或多个经由空气传导呈现音频内容的换能器(例如,空气传导换能器220)和/或一个或多个经由组织传导呈现音频内容的换能器(例如,软骨传导换能器230)。换能器阵列410可以被配置为在诸如20Hz(赫兹)至20kHz(千赫兹)的频率范围上呈现音频内容,该频率范围通常在人类的平均听力范围附近。在一些实施例中,换能器阵列410呈现调整后的(例如,经滤波的、经增强的、经放大的或经衰减的)音频内容。
传感器阵列420测量与头戴式设备相关的各种参数。传感器阵列420包括一个或多个声学传感器(例如,声学传感器185)和/或一个或多个位移传感器(例如,位移传感器240)。声学传感器检测来自局部区域的声音,该声音被用于为用户的一只耳朵或两只耳朵生成一个或多个虚拟传声器。位移传感器通过测量用户耳朵的一部分(例如,耳廓210)的位移来校准所生成的虚拟传声器。该用户耳朵的一部分可以由于换能器阵列410所生成的音频内容而振动和/或移位,该振动和/或移位由传感器阵列420中的位移传感器测量。在一些实施例中,多个位移传感器中的至少一者被集成到换能器阵列410的软骨传导换能器中。位移传感器可以是光学位移传感器、惯性测量单元、加速度计、陀螺仪或检测运动的另一合适类型的传感器或它们的某种组合。
在一些实施例中,传感器阵列420还包括一个或多个被配置为检测声音的声学传感器(例如,声学传感器185)。声学传感器可以被配置为检测来自用户周围的局部区域中的声音的声压波,并且将所检测的声压波转换为模拟格式和/或数字格式。声学传感器可以是例如传声器、加速度计、检测声压波的另一传感器或它们的某种组合。
控制器430对从传感器阵列420接收到的数据进行处理,并且指示换能器组件410呈现音频内容,从而使得音频系统400能够校准用户的耳道入口处的虚拟传声器。图1的音频控制器160是控制器430的实施例。控制器430包括数据存储区(data store)435、波达方向(DOA)估计模块440、传递函数模块450、追踪模块460、波束成形模块470、声压估计模块480和声音滤波器模块490。在一些实施例中,控制器430包括除了本文中所描述的这些模块和/或部件之外的其他模块和/或部件。
数据存储区435存储与音频系统400相关的数据。例如,该数据包括测量到的用户的一只耳朵或两只耳朵的位移信息、校准信号、训练模型的数据、所生成的声音滤波器、音频系统400的一些其他信息或它们的某种组合。此外,数据存储区435中的数据可以包括在音频系统400的局部区域中录制的声音、音频内容、头相关传递函数(HRTF)、一个或多个传感器的传递函数、一个或多个声学传感器的阵列传递函数(array transfer function,ATF)、声源位置、局部区域的虚拟模型、波达方向估计结果、声音滤波器、以及与音频系统400的使用相关的其他数据或它们的任意组合。
DOA估计模块440被配置为部分地基于来自传感器阵列420的信息,来定位局部区域中的声源。定位是确定声源相对于音频系统400的用户所处的位置的过程。DOA估计模块440执行DOA分析,以定位局部区域内的一个或多个声源。DOA分析可以包括:分析每个声音在传感器阵列420处的强度、频谱和/或到达时间,以确定声音的起源方向。在一些情况下,DOA分析可以包括用于分析音频系统400所处的周围声学环境的任何合适的算法。
例如,DOA分析可以被设计为接收来自传感器阵列420的输入信号,并且将数字信号处理算法应用于这些输入信号以估计波达方向。这些算法可以包括例如延迟求和算法,在该延迟求和算法中,对输入信号进行采样,并且对得到的采样信号的加权和延迟版本一起进行平均以确定DOA。也可以实现最小均方(least mean squared,LMS)算法来创建自适应滤波器。然后,该自适应滤波器可以用于识别例如信号强度的差或到达时间的差。然后,这些差可以用于估计DOA。在另一实施例中,可以通过将输入信号转换到频域并且选择时频(time-frequency,TF)域内的特定频率间隔(bin)进行处理来确定DOA。可以对每个所选择的TF频率间隔进行处理,以确定该频率间隔是否包括音频频谱中具有直接路径音频信号的部分。然后,可以对具有直接路径信号的部分的那些频率间隔进行分析,以识别传感器阵列420接收到该直接路径音频信号时所处的角度。然后,所确定的角度可以用于识别接收到的输入信号的DOA。以上未列出的其它算法也可以单独使用或与以上算法组合使用来确定DOA。
在一些实施例中,DOA估计模块440也可以确定与音频系统400在局部区域内的绝对位置有关的DOA。可以从外部系统(例如,头戴式设备的某个其他部件、人工现实控制台、地图构建服务器(mapping server)、位置传感器等)接收传感器阵列420的位置。外部系统可以创建局部区域的虚拟模型,在该虚拟模型中映射音频系统400的局部区域和位置。接收到的位置信息可以包括音频系统400的一些部分或全部部分(例如,传感器阵列420)的位置和/或定向。DOA估计模块440可以基于接收到的位置信息来更新所估计的DOA。
传递函数模块450被配置为生成一个或多个声学传递函数。通常,传递函数是针对每个可能的输入值给出相应的输出值的数学函数。基于检测到的声音的参数,传递函数模块450生成与音频系统相关联的一个或多个声学传递函数。声学传递函数可以是阵列传递函数(TF)、头相关传递函数(HRTF)、其它类型的声学传递函数或它们的某种组合。ATF表征传声器如何接收来自空间中的点的声音。
ATF包括多个传递函数,这些传递函数表征一声源与传感器阵列420中的多个声学传感器接收到的对应的声音之间的关系。因此,针对一个声源,对于传感器阵列420中的每个声学传感器均存在对应的传递函数。并且该组传递函数被统称为ATF。因此,对于每个声源,均存在对应的ATF。要注意的是,该声源可以例如是在局部区域中生成声音的某人或某物、用户或换能器阵列410中的一个或多个换能器。由于人的生理结构(例如,耳朵形状、肩膀等)在声音向人耳行进时会影响该声音,所以相对于传感器阵列420的特定声源位置的ATF可能因用户的不同而有所区别。因此,传感器阵列420的这些ATF对于音频系统200的每个用户是个性化的。
在一些实施例中,传递函数模块450确定音频系统400的用户的一个或多个HRTF。HRTF表征耳朵如何接收来自空间中的点的声音。由于人的生理结构(例如,耳朵形状、肩膀等)在声音向人耳行进时会影响该声音,所以相对于人的特定声源位置的HRTF对于这个人的每只耳朵是独特的(unique)(从而对于这个人是独特的)。在一些实施例中,传递函数模块450可以使用校准过程来确定用户的HRTF。在一些实施例中,传递函数模块450可以向远程系统提供关于用户的信息。用户可以调整隐私设置,以允许或防止传递函数模块450向任何远程系统提供关于用户的信息。远程系统使用例如机器学习来确定为用户定制的一组HRTF,并且将定制的该组HRTF提供给音频系统400。
追踪模块460被配置为追踪一个或多个声源的位置。追踪模块460可以将多个当前DOA估计结果进行比较,并且将它们与先前DOA估计结果的存储历史进行比较。在一些实施例中,音频系统400可以按照周期性时间表(例如,每秒一次或每毫秒一次)来重新计算DOA估计结果。追踪模块可以将当前DOA估计结果与先前DOA估计结果进行比较,并且响应于声源的DOA估计结果的变化,追踪模块460可以确定声源移动。在一些实施例中,追踪模块460可以基于从头戴式设备或某种其它外部源接收到的视觉信息来检测位置的改变。追踪模块460可以追踪一个或多个声源随时间的移动。追踪模块460可以存储声源的数量值以及每个声源在每个时间点的位置。响应于声源的数量值或位置的变化,追踪模块460可以确定声源移动。追踪模块460可以计算局域方差(localization variance)的估计结果。局域方差可以用作每次确定移动变化的置信水平。
波束成形模块470被配置为对一个或多个ATF进行处理,以选择性地强调来自某个区域内的声源的声音,同时不强调来自其他区域的声音。在对传感器阵列420检测到的声音进行分析时,波束成形模块470可以组合来自不同声学传感器的信息,以强调与局部区域的特定区相关联的声音,同时不强调来自该区之外的声音。波束成形模块470可以基于例如来自DOA估计模块440和追踪模块460的不同DOA估计结果,将与来自特定声源的声音相关联的音频信号与局部区域中的其它声源隔离开。波束成形模块470因此可以对局部区域中的离散声源进行选择性地分析。在一些实施例中,波束成形模块470可以增强来自声源的信号。例如,波束成形模块470可以应用声音滤波器,该声音滤波器消除高于某些频率、低于某些频率或在某些频率之间的信号。信号增强用于相对于由传感器阵列420检测到的其它声音来增强与给定的所识别的声源相关联的声音。
当播放音频内容时,声压估计模块480估计耳道入口处的声压。声压估计模块480使用模型来表征如何在耳道入口处感知音频内容(例如,预测耳道入口处的双耳传声器将响应于音频内容而检测到什么),从而模拟虚拟传声器。声压估计模块480可以指示换能器阵列410以通过空气传导和/或组织传导来播放校准信号。校准信号可以是生成用户可感知的声波的音频内容,例如,播放一段时间的音调、一段音乐等。声压估计模块480使用来自传感器阵列420的、耳朵的一部分(例如,耳廓)的位移信息(例如,如由传感器阵列420中的一个或多个位移传感器测量的)。所述耳朵的一部分的位移至少部分是由于校准信号而产生的。
声压估计模块480使用模型来估计耳道入口处的声压。该模型可以被配置为将测量到的耳朵的一部分的位移信息作为输入,并且相应地输出所估计的耳道入口处的声压。在一些实施例中,当输出所估计的耳道入口处的声压时,该模型被配置为将用户耳朵的几何形状(例如,对用户耳朵的特征的测量结果)考虑在内。可以根据用户的图像和/或视频来确定用户耳朵的几何形状。该模型可以例如是机器学习模型,该机器学习模型例如卷积神经网络、线性模型、数值模拟或它们的某种组合。可以在数据集上训练和/或构建该模型,该数据集包括来自多个其他用户的数据。对于多个其他用户中的每一者,该数据将所测量的耳朵的一部分的位移信息与耳朵的耳道入口处的声压(例如,由双耳传声器测量的)相关联。在一些实施例中,该模型可以基于下式将用户耳朵的一部分的位移信息与耳道入口处的声压相关联。
在上面示出的式(1)中,p表示声压,a表示加速度,并且F表示p与a之间的函数映射。如果在时域中p与a之间或者在频域中P(例如,p的复频响应)与A(例如,a的复频响应)之间存在高相干性,则该模型假设加速度与声压之间存在强线性关系。如果p被认为是a的时不变函数,则可以根据下式用a来描述p:
p(t)=a(t)*h(t)(2)
上式描述时域卷积,或:
P(f)=A(f)H(f)(3)
式(3)描述频域中的频谱倍增,其中,h(t)或H(f)表征外耳振动与对应的声压之间的传递函数。考虑到外耳加速度a与耳道入口处的声压p之间的线性时不变(linear timeinvariant,LTI)关系,随后可以通过校准式(2)和式(3)的右侧来校准耳道入口处的压力。
声压估计模块280也区分由于换能器阵列410所呈现的音频内容而引起的耳廓的位移以及由其它噪声而引起的位移。声压估计模块280使用相关模型来测量由换能器阵列410输出的音频内容与由传感器阵列420中的位移传感器测量到的位移之间的相关性。高相关性可以指示位移在很大程度上是由于换能器阵列410所呈现的音频内容而产生的。
声音滤波器模块490基于所估计的耳道入口处的声压,为用户生成一个或多个声音滤波器。所估计的耳道入口处的声压指示用户如何在耳道的入口处感知音频内容,并且声音滤波器模块490生成声音滤波器以相应地调整音频内容。声音滤波器的示例包括低通滤波器、高通滤波器、带通滤波器等。当应用于音频内容时,声音滤波器对音频内容进行调整,以改善用户的听觉体验。例如,用户可以将调整后的音频内容感知为经滤波的、经增强的、经放大的、经衰减的或它们的某种组合。在一些实施例中,声音滤波器得到调整后的音频内容,所述调整后的音频内容具有目标量值的频率响应(例如,平坦的频率响应)。在其他实施例中,声音滤波器可以以特定的频率范围为目标,从而帮助听力丧失的用户在那些频率范围内听得更清楚。在使用声音滤波器对音频内容进行调整之后,声音滤波器模块490指示换能器阵列410向用户呈现调整后的音频内容。在一些实施例中,用户向音频系统400提供关于调整后的音频内容的反馈,该反馈可以被合并到如下数据集中:声压估计模块480使用该数据集来训练和/或构建模型。
在一些实施例中,音频系统300可以使用声音滤波器来空间化音频内容,使得音频内容听起来源自局部区域内的目标区域。声音滤波器模块490可以使用HRTF和/或声学参数来生成声音滤波器。声学参数描述局部区域的声学特性。声学参数可以包括例如混响时间、混响水平、房间脉冲响应等。在一些实施例中,声音滤波器模块490计算这些声学参数中的一个或多个声学参数。在一些实施例中,声音滤波器模块490从地图构建服务器(例如,如以下关于图6描述的)请求声学参数。
图5为根据一个或多个实施例的用于校准虚拟传声器的过程500的流程图。可以由音频系统(例如,音频系统400)的部件来执行该过程500。在一些实施例中,音频系统是头戴式设备(例如,头戴式设备205)中的部件,该音频系统被配置为通过执行过程500来校准用户耳朵的耳道入口处的虚拟传声器。在一些实施例中,音频系统为用户的一只耳朵或两只耳朵执行过程500。在其它实施例中,其它实体可以执行图5中的一些或全部步骤。实施例可以包括不同的步骤和/或附加的步骤,或者以不同的次序执行这些步骤。
音频系统经由一个或多个换能器(例如,换能器阵列410中的换能器)向用户呈现510音频内容。换能器可以基于来自音频系统400的控制器(例如,控制器430)的指令来生成音频内容。该音频内容可以是校准信号。换能器可以是空气传导换能器(例如,空气传导换能器180)、组织传导换能器(例如,组织传导换能器170)或它们的某种组合。
音频系统经由一个或多个传感器(例如,传感器阵列420中的传感器)监测520用户的一只耳朵或两只耳朵的耳廓(例如,耳廓210)的位移。一个耳廓或两个耳廓的位移可以部分地是由于音频内容引起的振动而产生的。在一些实施例中,监测一个耳廓或两个耳廓的位移的传感器可以与音频系统的一个或多个换能器集成和/或被耦接到音频系统的一个或多个换能器。例如,对于给定耳廓,传感器可以监测由结合到耳廓的软骨传导换能器引起的耳廓的位移。上述传感器中的一者或更多者可以是位移传感器(例如,位移传感器240)和/或光学传声器。
音频系统基于所监测的位移来估计530耳朵的耳道入口(例如,耳道入口215)处的声压。例如,音频系统可以将所监测的位移作为输入提供给模型,该模型被配置为输出所估计的耳道入口处的声压。基于所估计的耳道入口处的声压,音频系统表征如何在耳道入口处感知音频内容,从而校准耳道入口处的虚拟传声器。在一些实施例中,音频系统估计两个耳道入口处的声压。
音频系统基于所估计的声压生成540用于换能器的一个或多个声音滤波器。声音滤波器可以放大、衰减和/或增强某些频率。在一些实施例中,声音滤波器被配置为空间化来自局部区域的、由音频系统的传感器检测到的声音。
音频系统使用所生成的声音滤波器来调整550音频内容。在一些实施例中,使用所生成的声音滤波器来调整音频内容包括:应用增益、滤除某些频率等等。在一些实施例中,被调整的音频内容是来自局部区域的声音。在其他实施例中,被调整的音频内容被配置为是人工现实和/或混合现实体验的组成部分。
音频系统经由一个或多个换能器向用户呈现560调整后的音频内容。调整后的音频内容可以为用户带来经改善的听觉体验。例如,调整后的音频内容可以保留空间线索、为听力受损用户放大某些频率、增强来自用户周围的局部区域的声音以用于人工现实和/或混合现实应用程序等。
人工现实系统环境
图6为根据一个或多个实施例的示例人工现实系统环境600的框图。系统600可以在人工现实环境(例如,虚拟现实环境、增强现实环境、混合现实环境或它们的某种组合)中运行。图6所示的系统600包括头戴式设备605、耦接到控制台615的输入/输出(input/output,I/O)接口610、网络620以及地图构建服务器625。在一些实施例中,头戴式设备605可以是图1A的头戴式设备100或图1B的头戴式设备105,并且被配置为校准用户耳朵的耳道入口处的虚拟传声器。
尽管图6示出了示例系统600包括一个头戴式设备605和一个I/O接口610,但是在其他实施例中,系统600可以包括任意数量的这些部件。例如,可以存在多个头戴式设备,每个头戴式设备具有相关联的I/O接口610,其中,每个头戴式设备和I/O接口610与控制台615通信。在替代配置中,系统600可以包括不同的和/或附加的部件。另外,在一些实施例中,结合图6中示出的一个或多个部件描述的功能可以按照与结合图6描述的方式不同的方式分布在部件之中。例如,控制台615的一些或全部功能可以由头戴式设备605来提供。
头戴式设备605包括显示组件630、光学器件块635、一个或多个位置传感器640以及DCA 645。头戴式设备605的一些实施例具有与结合图6描述的这些部件不同的部件。另外,结合图6描述的各种部件所提供的功能可以在其它实施例中以不同方式分布在头戴式设备605的部件之中,或者在远离头戴式设备605的单独组件中体现。
显示组件630根据从控制台615接收到的数据向用户显示内容。显示组件630使用一个或多个显示元件(例如,显示元件120)来显示内容。显示元件可以是例如电子显示器。在各个实施例中,显示组件630包括单个显示元件或多个显示元件(例如,对于用户的每只眼睛一个显示器)。电子显示器的示例包括:液晶显示器(liquid crystal display,LCD)、有机发光二极管(organic light emitting diode,OLED)显示器、有源矩阵有机发光二极管显示器(active-matrix organic light-emitting diode display,AMOLED)、波导显示器、某种其它显示器或它们的某种组合。应注意,在一些实施例中,显示元件120还可以包括光学器件块635的一些或全部功能。
光学器件块635可以放大从电子显示器接收到的图像光,校正与该图像光相关联的光学误差,并且向头戴式设备605的一个或两个适眼区呈现经校正的图像光。在各个实施例中,光学器件块635包括一个或多个光学元件。包括在光学器件块635中的示例光学元件包括:光圈、菲涅耳透镜、凸透镜、凹透镜、滤光器、反射表面或影响图像光的任意其它合适的光学元件。此外,光学器件块635可以包括不同光学元件的组合。在一些实施例中,光学器件块635中的一个或多个光学元件可以具有一个或多个涂层,例如部分反射涂层或抗反射涂层。
通过光学器件块635对图像光的放大和聚焦允许电子显示器与更大的显示器相比,在物理上更小、重量更轻并且功耗更少。另外,放大可以增大电子显示器所呈现的内容的视场。例如,所显示的内容的视场使得该显示的内容是使用几乎全部的用户视场(例如,约110度对角线)来呈现的,并且在一些情况下,该显示的内容是使用全部的用户视场来呈现的。另外,在一些实施例中,可以通过添加或移除光学元件来调整放大量。
在一些实施例中,光学器件块635可以被设计为校正一种或多种类型的光学误差。光学误差的示例包括桶形失真或枕形失真、纵向色差或横向色差。其它类型的光学误差还可以包括球面像差;色差;或由于透镜场曲、像散所引起的误差;或任何其它类型的光学误差。在一些实施例中,提供给电子显示器用于显示的内容是预失真的,并且光学器件块635在其接收到来自电子显示器的的图像光(该图像光是基于该内容而生成的)时,校正该失真。
位置传感器640是这种电子设备:该电子设备生成指示关于头戴式设备605的位置的数据。位置传感器640响应于头戴式设备605的运动而生成一个或多个测量信号。位置传感器190是位置传感器640的实施例。位置传感器640的示例包括:一个或多个IMU、一个或多个加速度计、一个或多个陀螺仪、一个或多个磁力计、检测运动的另一合适类型的传感器或它们的某种组合。位置传感器640可以包括用于测量平移运动(向前/向后、向上/向下、向左/向右)的多个加速度计和用于测量转动运动(例如,俯仰、横摆、翻滚)的多个陀螺仪。在一些实施例中,IMU快速地对测量信号进行采样,并且根据所采样的数据计算头戴式设备605的估计位置。例如,IMU随时间对从加速度计接收到的测量信号进行积分来估计速度矢量,并且随时间对速度矢量进行积分来确定头戴式设备605上的参考点的估计位置。参考点是可以用于描述头戴式设备605的位置的点。尽管参考点通常可以被定义为空间中的点,然而,该参考点实际上被定义为头戴式设备605内的点。
DCA 645生成局部区域的一部分的深度信息。DCA包括一个或多个成像设备以及DCA控制器。DCA 645还可以包括照明器。以上参考图1A对DCA 645的操作和结构进行了描述。
音频系统400向头戴式设备605的用户提供音频内容。音频系统400对定位在用户耳朵的耳道入口处的虚拟传声器进行校准,并相应地为用户调整音频内容。在一些实施例中,音频系统使用机器学习模型来校准虚拟传声器。音频系统将关于用户的耳朵的一部分的位移信息作为输入提供给模型,该模型输出所估计的耳道入口处的声压。因此,音频系统可以预测如何在耳道的入口处感知由换能器阵列生成的音频内容。在一些实施例中,音频系统针对用户的每只耳朵来校准虚拟传声器。如以上关于图4所描述的,音频系统400可以包括换能器阵列410、传感器阵列420以及控制器430。音频系统400可以包括除了本文中所描述的这些部件之外的其他部件。
除了校准用户的耳道入口处的虚拟传声器之外,音频系统400还可以执行其他功能。在一些实施例中,音频系统400可以通过网络620请求来自地图构建服务器625的声学参数。声学参数描述了局部区域的一个或多个声学特性(例如,房间脉冲响应、混响时间、混响水平等)。音频系统400可以提供例如来自DCA 645的、描述局部区域的至少一部分的信息和/或来自位置传感器640的、头戴式设备605的位置信息。音频系统400可以使用从地图构建服务器625接收到的一个或多个声学参数来生成一个或多个声音滤波器,并且使用所述声音滤波器向用户提供音频内容。
I/O接口610是这种设备:该设备允许用户向控制台615发送动作请求并从控制台615接收响应。动作请求是执行特定动作的请求。例如,动作请求可以是开始或结束采集图像或视频数据的指令,或者是在应用程序内执行特定动作的指令。I/O接口610可以包括一个或多个输入设备。示例输入设备包括:键盘、鼠标、游戏控制器或用于接收动作请求并向控制台615传送动作请求的任何其它合适的设备。由I/O接口610接收到的动作请求被传送到控制台615,该控制台615执行与该动作请求相对应的动作。在一些实施例中,I/O接口610包括采集校准数据的IMU,该校准数据指示I/O接口610相对于I/O接口610的初始位置的估计位置。在一些实施例中,I/O接口610可以根据从控制台615接收到的指令来向用户提供触觉反馈。例如,当接收到动作请求时提供触觉反馈,或者控制台615在该控制台615执行动作时向I/O接口610传送指令,从而使得I/O接口610生成触觉反馈。
控制台615根据从以下项中的一项或多项接收到的信息向头戴式设备605提供内容以供处理:DCA 645、头戴式设备605和I/O接口610。在图6示出的示例中,控制台615包括应用程序商店655、追踪模块660和引擎665。控制台615的一些实施例具有与结合图6描述的这些模块或部件不同的模块或部件。类似地,以下进一步描述的功能可以按照与结合图6描述的方式不同的方式分布在控制台615的部件之中。在一些实施例中,本文讨论的关于控制台615的功能可以在头戴式设备605或远程系统中实现。
应用程序商店655存储一个或多个应用程序以供控制台615执行。应用程序是一组指令,当这些指令被处理器执行时生成用于向用户呈现的内容。由应用程序生成的内容可以响应于经由头戴式设备605或I/O接口610的移动从用户接收到的输入。应用程序的示例包括:游戏应用程序、会议应用程序、视频播放应用程序或其它合适的应用程序。
追踪模块660使用来自DCA 645、一个或多个位置传感器640或它们的某种组合的信息,来追踪头戴式设备605或I/O接口610的移动。例如,追踪模块660基于来自头戴式设备605的信息,确定头戴式设备605的参考点在局部区域的映射中的位置。追踪模块660也可以确定对象或虚拟对象的位置。另外,在一些实施例中,追踪模块660可以使用来自位置传感器640的指示头戴式设备605的位置的数据部分以及来自DCA 645的局部区域的表示,来预测头戴式设备605的未来位置。追踪模块660向引擎665提供头戴式设备605或I/O接口610的估计的或预测的未来位置。
引擎665执行应用程序,并且从追踪模块660接收头戴式设备605的位置信息、加速度信息、速度信息、预测的未来位置或它们的某种组合。基于接收到的信息,引擎665确定将要向头戴式设备605提供的用于向用户呈现的内容。例如,如果接收到的信息指示用户已经看向左边,则引擎665生成用于头戴式设备605的内容,该内容是用户在虚拟局部区域或局部区域(使用附加内容增强了该局部区域)中的移动的镜像。另外,引擎665响应于从I/O接口610接收到的动作请求,在控制台615上执行的应用程序内执行动作,并且向用户提供该动作已被执行的反馈。已提供的反馈可以是经由头戴式设备605的视觉反馈或听觉反馈,或者是经由I/O接口610的触觉反馈。
网络620将头戴式设备605和/或控制台615耦接到地图构建服务器625。网络620可以包括使用无线通信系统和/或有线通信系统的局域网和/或广域网的任意组合。例如,网络620可以包括因特网以及移动电话网络。在一个实施例中,网络620使用标准通信技术和/或协议。因此,网络620可以包括使用如下技术的链路:例如,以太网、802.11、全球微波接入互通(worldwide interoperability for microwave access,WiMAX)、2G/3G/4G移动通信协议、数字用户线路(digital subscriber line,DSL)、异步传输模式(asynchronoustransfer mode,ATM)、无限带宽(InfiniBand)、PCI Express高级交换(PCI ExpressAdvanced Switching)等。类似地,在网络620上使用的联网协议可以包括多协议标签交换(multiprotocol label switching,MPLS)、传输控制协议/因特网协议(transmissioncontrol protocol/Internet protocol,TCP/IP)、用户数据报协议(User DatagramProtocol,UDP)、超文本传输协议(hypertext transport protocol,HTTP)、简单邮件传输协议(simple mail transfer protocol,SMTP)、文件传输协议(file transfer protocol,FTP)等。通过网络620交换的数据可以使用如下技术和/或格式来表示,这些技术和/或格式包括二进制形式的图像数据(例如,便携式网络图形(Portable Network Graphic,PNG))、超文本标记语言(hypertext markup language,HTML)、可扩展标记语言(extensiblemarkup language,XML)等。此外,可以使用常规加密技术对全部或一些链路进行加密,这些常规加密技术例如安全套接层(secure sockets layer,SSL)、传输层安全协议(transportlayer security,TLS)、虚拟专用网络(virtual private network,VPN)、互联网安全协议(Internet Protocol security,IPsec)等。
地图构建服务器625可以包括数据库,该数据库存储有描述多个空间的虚拟模型,其中,该虚拟模型中的一个位置与头戴式设备605的局部区域的当前配置相对应。地图构建服务器625经由网络620从头戴式设备605接收描述局部区域的至少一部分的信息和/或局部区域的位置信息。用户可以调整隐私设置以允许或防止头戴式设备605将信息发送到地图构建服务器625。地图构建服务器625基于接收到的信息和/或位置信息,确定该虚拟模型中与头戴式设备605的局部区域相关联的位置。地图构建服务器625部分地基于所确定的在该虚拟模型中的位置以及与所确定的位置相关联的任何声学参数,确定(例如,检索)与局部区域相关联的一个或多个声学参数。地图构建服务器625可以向头戴式设备605发送局部区域的位置以及与局部区域关联的任意声学参数值。
系统600中的一个或多个部件可以包含存储用户数据元素的一个或多个隐私设置的隐私模块。用户数据元素对用户或头戴式设备605进行了描述。例如,用户数据元素可以描述用户的身体特征、由用户执行的动作、头戴式设备605的用户的位置、头戴式设备605的位置、用户的HRTF等。可以以任何合适的方式存储用户数据元素的隐私设置(或“访问设置”),例如,与用户数据元素相关联地存储、存储在授权服务器上的索引中、以另一合适的方式存储或它们的任意合适的组合。
用户数据元素的隐私设置指定可以如何访问、存储或以其他方式使用(例如,查看、共享、修改、复制、执行、显现或识别)用户数据元素(或与用户数据元素相关联的特定信息)。在一些实施例中,用户数据元素的隐私设置可以指定可能无法访问与用户数据元素相关联的某些信息的实体的“黑名单”。与用户数据元素相关联的隐私设置可以指定许可访问或拒绝访问的任何合适的粒度。例如,一些实体可以具有查明特定用户数据元素存在的许可,一些实体可以具有查看特定用户数据元素的内容的许可,并且一些实体可以具有修改特定用户数据元素的许可。隐私设置可以允许用户允许其他实体在有限的时间段内访问或存储用户数据元素。
隐私设置可以允许用户指定可以访问用户数据元素的一个或多个地理位置。对用户数据元素的访问或拒绝访问可以取决于试图访问用户数据元素的实体的地理位置。例如,用户可以允许访问用户数据元素,并且指定仅在用户处于特定位置时用户数据元素对于实体是可访问的。如果用户离开该特定位置,则用户数据元素对于该实体可能不再是可访问的。作为另一示例,用户可以指定用户数据元素仅对于距用户阈值距离内的实体(例如与该用户相同的局部区域内的头戴式设备的另一用户)是可访问的。如果用户随后改变位置,则具有对该用户数据元素的访问权的实体可能失去访问权,而一组新实体在它们来到用户的阈值距离内时可以获得访问权。
系统600可以包括用于实施隐私设置的一个或多个授权/隐私服务器。来自实体的、针对特定用户数据元素的请求可以识别与该请求相关联的实体,并且如果授权服务器基于与该用户数据元素相关联的隐私设置确定该实体被授权访问该用户数据元素,则可以仅向该实体发送该用户数据元素。如果请求实体未被授权访问该用户数据元素,则授权服务器可以防止所请求的用户数据元素被检索或者可以防止所请求的用户数据元素被发送到该实体。尽管本公开描述了以特定方式实施隐私设置,但是本公开考虑了以任何合适的方式实施隐私设置。
附加配置信息
已经出于例示目的而呈现了实施例的以上描述,这并不旨在是详尽的,也不旨在将专利权限制为所公开的精确形式。相关领域的技术人员可以理解的是,考虑到上述公开内容,许多修改和变化是可行的。
本描述的一些部分在对信息进行操作的算法和符号表示方面描述了实施例。这些算法描述和表示通常被数据处理领域的技术人员用来向本领域的其它技术人员有效地传达其工作的实质内容。尽管在功能上、计算上或逻辑上对这些操作进行了描述,但这些操作被理解为由计算机程序或等效电路或微代码等实现。此外,事实证明,在不失一般性的情况下,有时为了方便将这些操作的布置结构称为模块。所描述的操作和它们的相关联的模块可以被实施在软件、固件、硬件或它们的任意组合中。
本文描述的任何步骤、操作或过程可以使用一个或多个硬件或软件模块单独地或者与其它设备组合地执行或实现。在一个实施例中,使用包括计算机可读介质的计算机程序产品来实现软件模块,该计算机可读介质包含计算机程序代码,该计算机程序代码可以被计算机处理器执行,以执行所描述的步骤、操作或过程中的任何或全部步骤、操作或过程。
实施例还可以涉及一种用于执行本文中的操作的装置。该装置可以为所需目的而专门构造,和/或该装置可以包括通用计算设备,该通用计算设备由存储在计算机中的计算机程序选择性地激活或重新配置。这种计算机程序可以存储在非暂态有形计算机可读存储介质中或者适合于存储电子指令的任何类型的介质中,上述介质可以耦接到计算机系统总线。此外,本说明书中提到的任何计算系统可以包括单个处理器,或者可以是采用多个处理器设计来增加计算能力的架构。
实施例还可以涉及一种由本文所描述的计算过程产生的产品。这种产品可以包括根据计算过程产生的信息,其中,该信息被存储在非暂态有形计算机可读存储介质上并且可以包括计算机程序产品的任何实施例或本文所描述的其它数据组合。
最后,本说明书中使用的语言主要是出于可读性和指导目的而选择,并且该语言可能不是为了划定或限制专利权而选择。因此,旨在专利权的范围不受本具体实施方式的限制,而是受基于本文的申请公布的任何权利要求限制。因此,实施例的公开内容旨在对专利权的范围进行例示而非限制,专利权的范围在所附权利要求中得到阐述。
- 一种基于三腔黑体辐射源的红外耳温计校准装置及方法
- 一种基于三腔黑体辐射源的红外耳温计校准装置