一种基于SSA-BP算法的燃煤二氧化碳排放量确定方法及确定系统
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及燃煤电厂二氧化碳排放研究,具体是涉及一种基于SSA-BP算法的燃煤二氧化碳排放量确定方法及确定系统。
背景技术
电力行业是煤炭主要二氧化碳排放行业之一,2020年中国碳排放总量约99亿吨,煤电机组碳排放约43亿吨,占总量40%以上,降低燃煤电厂的碳排放量目标举足轻重。降低燃煤电厂碳排放量的前提是准确、科学地计算燃煤电厂二氧化碳排放总量,从而更好地规划火电厂运行。
现有的CO
式中E为煤炭燃烧所产生的二氧化碳排放量,单位为kg;AD
通过获取煤炭元素分析数据,采用煤炭收到基元素分析含碳量计算燃煤电厂二氧化碳排放简单可靠,适应性强,但是因为元素分析过程仪器硬件要求高、操作复杂且耗时长,大部分燃煤火力发电厂并不开展元素分析项目。
发明内容
发明目的:针对以上缺点,本发明提供一种准确性高的基于SSA-BP算法的燃煤二氧化碳排放量确定方法及确定系统。
技术方案:为解决上述问题,本发明采用一种基于SSA-BP算法的燃煤二氧化碳排放量确定方法,包括以下步骤:
步骤1:获取燃煤样本,对燃煤样本进行工业分析和元素分析,得到工业分析数据和含碳量,所述燃煤工业分析数据包括煤炭挥发分含量、固定碳含量、煤炭低位发热量和煤炭灰分含量;
步骤2:通过以工业分析数据为输入,含碳量为输出对改进的BP神经网络进行训练,构建基于SSA-BP算法的燃煤含碳量预测模型;
步骤3:获取实际燃煤的工业分析数据,并根据燃煤含碳量预测模型得到燃煤的实际含碳量;
步骤4:获取实际燃煤的燃烧数据,所述燃烧数据包括所耗原煤量、煤炭收到基灰分、锅炉灰渣平均含碳量;
步骤5:通过燃煤的燃烧数据和实际含碳量确定燃煤燃烧的二氧化碳排放量。
进一步的,所述步骤1中根据煤炭挥发分含量将煤炭分类为无烟煤、贫煤、烟煤、褐煤,所述步骤2中根据不同种类煤炭的工业分析数据与含碳量构建不同的燃煤含碳量预测模型。
进一步的,所述步骤3中对采用多煤种混煤燃烧的燃煤火电厂,根据对应煤种的燃煤含碳量预测模型得到对应的实际含碳量。
进一步的,对于采用多煤种混煤燃烧的燃煤火电厂,燃煤燃烧的二氧化碳排放量E
其中,W
进一步的,所述步骤5中还包括脱硫工艺中二氧化碳的排放,通过石灰石消耗量、石灰石中碳酸钙含量计算脱硫工艺碳中的二氧化碳排放量,通过燃煤燃烧的二氧化碳排放量和脱硫工艺碳中的二氧化碳排放量计算得到燃煤电厂总二氧化碳排放量。
进一步的,脱硫工艺碳中的二氧化碳排放量E
其中,W
进一步的,所述的改进的BP神经网络包括输入层、中间层和输出层,通过麻雀搜索算法SSA优化BP神经网络超参数,输入层的神经元个数为5,输出层神经元个数为1;输入的参数为:煤炭水分、煤炭挥发分含量、固定碳含量、煤炭低位发热量、煤炭灰分含量;输出参数为:含碳量;隐藏层的神经元个数由经验公式确定,经验公式如下:
其中,b为输入层节点个数,c为输出层节点个数,a取1-10之间的整数。
通过经验公式对比使用不同隐藏层数情况下的模型预测的均方误差,取最小的均方根误差所对应的神经网络作为获得最优的隐藏层神经元数的神经网络结构。
进一步的,所述麻雀搜索优化算法具体步骤如下:
步骤(1):初始化种群;
首先对麻雀的种群初始位置和个体值进行初始化、计算每个个体的适应度;
确定最大迭代次数为N,麻雀种群大小为n,麻雀种群中发现者数量为PD,种群中感应危险的麻雀数量为SD,安全值为ST,预警值为R2;
步骤(2):种群排序;
根据麻雀的个体适应度值对个体进行降序排序,确定最佳个体的适应度值及其位置;
步骤(3):种群开始觅食、反捕食、加入行为;
步骤(4):更新新种群的适应度值;
步骤(5):重复步骤(3)与步骤(4),直到达到最大迭代次数或者满足终止准则;输出最优个体与个体值,即最优超参数数值到BP神经网络中。
进一步的,使用均方误差作为燃煤含碳量预测模型的适应函数:
均方误差的公式如下:
其中,n为样本个数,X
本发明还采用一种基于SSA-BP算法的燃煤二氧化碳排放量确定系统,包括:
数据采集模块,用于获取燃煤样本进行工业分析和元素分析后的工业分析数据和含碳量;所述燃煤工业分析数据包括煤炭挥发分含量、固定碳含量、煤炭低位发热量和煤炭灰分含量;还用于获取实际燃煤的工业分析数据和实际燃煤的燃烧数据,所述燃烧数据包括所耗原煤量、煤炭收到基灰分、锅炉灰渣平均含碳量;
模型构建模块,用于通过以工业分析数据为输入,含碳量为输出对改进的BP神经网络进行训练,构建基于SSA-BP算法的燃煤含碳量预测模型;
计算模块,用于通过燃煤含碳量预测模型根据获得的实际燃煤的工业分析数据得到燃煤的实际含碳量;还用于通过燃煤的燃烧数据和实际含碳量确定燃煤燃烧的二氧化碳排放量。
有益效果:本发明相对于现有技术,其显著优点是通过改进的BP神经网络计算燃煤碳排放的方法,采用易于测量的煤质参数(如工业分析数据)预测难以测量的煤质参数(如元素分析数据),可以快速的帮助煤炭企业更准确地掌握煤的品质,对于量化燃煤电厂二氧化碳排放具有指导意义。
附图说明
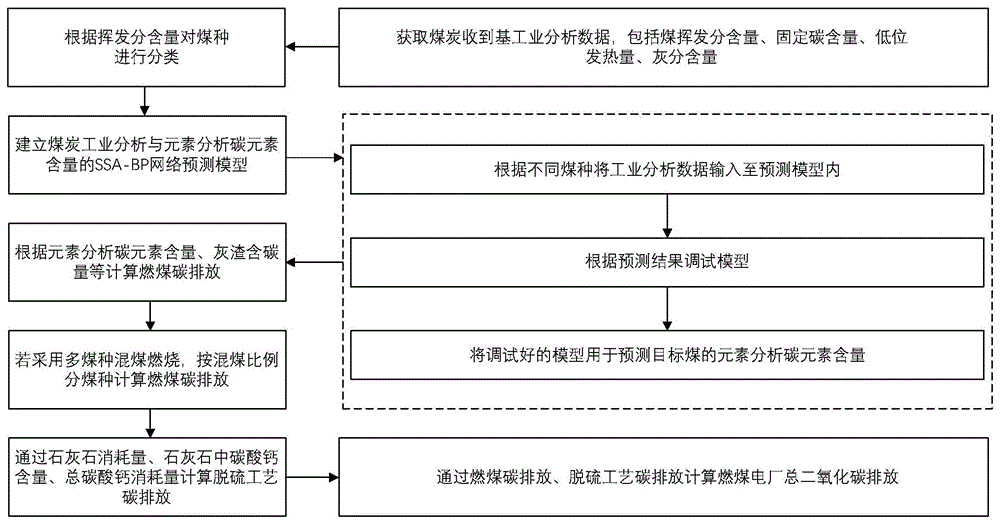
图1为本发明燃煤二氧化碳排放量确定方法的整体流程示意图;
图2为本发明燃煤二氧化碳排放量确定系统的结构框图。
具体实施方式
实施例1
如图1所示,本实施例中一种基于SSA-BP算法的燃煤二氧化碳排放量确定方法,该方法包括以下步骤:
步骤1:获取燃煤样本,对燃煤样本进行工业分析和元素分析,得到工业分析数据和含碳量,燃煤工业分析数据包括煤炭挥发分含量(VM)、固定碳含量FC、煤炭低位发热量(Q
步骤2:根据不同种类煤炭的工业分析数据与含碳量构建不同的燃煤含碳量预测模型。通过以工业分析数据为输入,含碳量为输出对改进的BP神经网络进行训练,构建基于SSA-BP算法的燃煤含碳量预测模型。
改进的BP神经网络包括输入层、中间层和输出层,通过麻雀搜索算法SSA优化BP神经网络超参数,输入层的神经元个数为5,输出层神经元个数为1;输入的参数为:煤炭水分、煤炭挥发分含量、固定碳含量、煤炭低位发热量、煤炭灰分含量;输出参数为:含碳量;隐藏层的神经元个数由经验公式确定,经验公式如下:
其中,b为输入层节点个数,c为输出层节点个数,a取1-10之间的整数。
通过经验公式对比使用不同隐藏层数情况下的模型预测的均方误差,取最小的均方根误差所对应的神经网络作为获得最优的隐藏层神经元数的神经网络结构。
麻雀搜索优化算法具体步骤如下:
步骤(1):初始化种群;
首先对麻雀的种群初始位置和个体值进行初始化、计算每个个体的适应度。
确定最大迭代次数为N,麻雀种群大小为n,麻雀种群中发现者数量为PD,种群中感应危险的麻雀数量为SD,安全值为ST,预警值为R2;
步骤(2):种群排序;
根据麻雀的个体适应度值对个体进行降序排序,确定最佳个体的适应度值及其位置;
步骤(3):种群开始觅食、反捕食、加入行为;
按下述公式更新发现者位置:
式中,
按下述公式进行反捕食行为,更新麻雀种群的位置:
式中,β是服从正态分布的随机数,K是取1到-1之间的随机数,f是个体适应度值。ε是无穷小量。
按下述公式更新加入者位置:
A′
步骤(4):更新新种群的适应度值;
步骤(5):重复步骤(3)与步骤(4),直到达到最大迭代次数或者满足终止准则;输出最优个体与个体值,即最优超参数数值到BP神经网络中。
使用均方误差作为燃煤含碳量预测模型的适应函数:
均方误差的公式如下:
其中,n为样本个数,X
模型的训练过程如下:
学习训练,利用学习训练,利用已知煤种工业分析数据与元素分析含碳量对所述神经网络模块进行训练。
预测数据,使用训练好的模型分不同煤种对煤的元素分析含碳量进行预测。
模型的输入参数为煤的工业分析数据,包括且不限于煤炭水分(M)、挥发分含量(VM)、固定碳含量(FC)、煤炭低位发热量(Q
每次执行梯度下降步骤时,都会生成一组新的权重,这些新的权重用于训练和优化预测模型。
数据预测通过将不同煤种的工业分析数据输入到训练好的含碳量预测模型中获得煤的元素分析碳元素含碳量。
本实施例合理利用SSA优化BP神经网络推算煤炭碳元素含量及计算燃煤碳排放量,SSA是一种新兴的自然进化算法,其灵感来源于麻雀鸟类的觅食行为,具有自适应、全局寻优、高效率等特点。相比于其他优化算法,SSA能够更快速地找到全局最优解,且不易陷入局部最优解。其次,BP神经网络是一种经典的人工神经网络算法,具有良好的非线性映射和自适应学习能力。通过采用SSA优化BP神经网络,可以更好地调整神经网络的参数,提高模型的预测精度和稳定性,有效降低模型在测试数据集上的预测误差。最后,煤的元素分析含碳量预测是煤炭行业中的一个重要问题,对于保证煤的品质、提高燃烧效率、减少环境污染等具有重要意义。采用SSA优化BP神经网络进行含碳量预测,可以快速的帮助煤炭企业更准确地掌握煤的品质,提高生产效率和经济效益。
步骤3:获取实际燃煤的工业分析数据,并根据燃煤含碳量预测模型得到燃煤的实际含碳量。对于采用多煤种混煤燃烧的燃煤电厂,根据对应煤种的燃煤含碳量预测模型得到对应的实际含碳量。
步骤4:获取实际燃煤的燃烧数据,燃烧数据包括所耗原煤量、煤炭收到基灰分、锅炉灰渣平均含碳量;获取脱硫工艺数据,脱硫工艺数据包括石灰石消耗量(W
通过含碳量计算燃煤火电二氧化碳排放的具体计算公式如下:
其中,E
W
C
A
为灰渣平均含碳量,即灰渣中平均含碳量占燃煤灰量的百分比,单位为%;
44为二氧化碳的摩尔质量,无量纲;
12为碳元素的摩尔质量,无量纲。
对于采用多煤种混煤燃烧的燃煤火电厂,按混煤比例分煤种计算煤炭固定燃烧碳排放的具体计算公式如下:
其中,E
W
C
A
为混煤灰渣平均含碳量,即混煤燃烧后灰渣中平均含碳量占燃煤灰量的百分比,单位为%;
44为二氧化碳的摩尔质量,无量纲;
12为碳元素的摩尔质量,无量纲。
通过石灰石消耗量(W
其中,E
为碳酸钙消耗量,单位为t;
W
为石灰石中碳酸钙含量,单位为%;
44为二氧化碳的摩尔质量,无量纲;
100为碳酸钙的分子量,无量纲。
步骤5:通过燃煤的燃烧数据和实际含碳量确定燃煤燃烧的二氧化碳排放量,通过石灰石消耗量、石灰石中碳酸钙含量计算脱硫工艺碳中的二氧化碳排放量。通过燃煤燃烧的二氧化碳排放量和脱硫工艺碳中的二氧化碳排放量计算得到燃煤电厂总二氧化碳排放量。
具体计算公式如下:
E=E
其中,E为燃煤电厂总二氧化碳排放,单位为t;
E
E
上述方法针对现有电厂缺少煤质元素分析的现状,利用BP神经网络通过工业分析计算煤炭元素分析碳含量,进而计算燃煤电厂碳排放量,方法可靠、误差小。有利于量化电厂碳排放,使企业对碳排放量有更准确的认知。
实施例2
本实施例中的一种基于SSA-BP算法的燃煤二氧化碳排放量确定系统,包括采集模块、分类模块、计算模块:
采集模块包括煤炭收到基工业分析数据采集模块、灰渣数据采集模块、湿法脱硫数据采集模块;分类模块包括煤种分类模块;计算模块包括煤炭收到基元素分析数据计算模块、煤炭固定燃烧碳排放计算模块、脱硫工艺碳排放计算模块、燃煤电厂总碳排放计算模块;
采集模块包括:
收到基工业分析数据采集模块,用于采集煤炭收到基工业分析数据,收到基工业分析数据包括:燃煤火电厂所耗原煤量(W
灰渣数据采集模块,用于采集锅炉灰渣数据,锅炉灰渣数据包括:锅炉灰渣平均含碳量
湿法脱硫数据采集模块,用于采集湿法脱硫工艺数据,湿法脱硫工艺数据包括:石灰石消耗量(W
分类模块包括:
煤种分类模块,用于根据煤炭挥发分含量(VM)将煤炭分类为无烟煤、贫煤、烟煤、褐煤,煤种分类模块与所述煤炭收到基工业分析数据采集模块连接。
计算模块包括:
煤炭收到基元素分析数据计算模块,用于分煤种建立基于SSA-BP算法的煤炭工业分析计算元素分析的神经网络模型,根据SSA-BP算法计算煤炭收到基含碳量(C
煤炭固定燃烧碳排放计算模块,用于根据煤炭收到基含碳量(C
脱硫工艺碳排放计算模块,用于根据石灰石消耗量(W
燃煤电厂总碳排放计算模块用于根据煤炭固定燃烧碳排放(E
煤炭工业分析数据包括:煤炭挥发分含量、煤炭固定碳含量、煤炭低位发热量、煤炭灰分含量;煤炭挥发分含量(VM)是煤样中有机质热分解的产物占煤炭质量的百分比。煤炭固定碳含量(FC)是空气干燥基下测定挥发分产率后的有机残留物占煤炭质量的百分比,其中的组成成分以碳元素为主,还有不同数量的氢、氧、氮、硫等以有机形式存在的有机元素。煤炭低位发热量(Q
- 一种基于GMDH算法的跨临界CO2系统最优排气压力特征变量的确定方法
- 一种基于不确定性优化的固体运载器总体参数确定方法及系统
- 一种铝电解过程二氧化碳排放量的确定方法及相关设备
- 用于确定菱镁矿加工过程产生的二氧化碳的排放量的方法