一种面向警情数据的实体关系分层抽取方法
文献发布时间:2024-04-18 19:59:31
技术领域
本发明涉及自然语言处理和深度学习领域,具体涉及一种面向警情数据的实体关系分层抽取方法。
背景技术
面向警情数据的实体关系抽取是警情信息抽取技术的重要环节,是警情信息抽取领域重要的基础任务和难点问题之一。其任务是从非结构化文本中识别出相应实体以及将实体之间具有的语义关系抽出,构成关系三元组。从理论价值层面看,实体关系抽取涉及到机器学习、语言学、数据挖掘以及深度学习等多个学科的理论和方法。从应用层面看,实体关系抽取可用于大规模知识库及知识图谱的自动构建,为后续针对大数据的信息检索和自动问答系统提供数据支持。近年来,研究人员已经在关系抽取方面做出了诸多工作,尤其是基于神经网络的有监督的关系抽取方法。目前进行面向警情数据的实体关系抽取的方法主要是单独基于神经网络的有监督的关系抽取方法。然而,单独基于神经网络的有监督的关系抽取方法存在着以下几个缺点:
1、需要人工标注:单独基于神经网络的有监督方法需要一批有人工标注的数据训练,针对真实警情数据,并没有人工标注的数据做训练支撑,导致工作耗时长,可迁移性差;
2、忽视了同一段落里多种关系特征互相之间会产生对关系识别抽取的不利影响;
3、产生冗余信息,由于对识别出来的实体进行两两配对,然后再进行关系分类,那些没有关系的实体对就会带来多余信息,提升错误率。
因此,为了解决上述问题,本文提出一种面向警情数据的实体关系分层抽取方法。
发明内容
本发明的目的在于设计可以结合实际情况,快速的对不同数据进行处理,能够降低多种关系互相之间产生的负面影响和可以减少冗余信息的一种面向警情数据的实体关系分层抽取方法。
为了达到上述技术效果,本发明是通过以下技术方案实现的:一种面向警情数据的实体关系分层抽取方法,其特征在于,包括以下步骤:
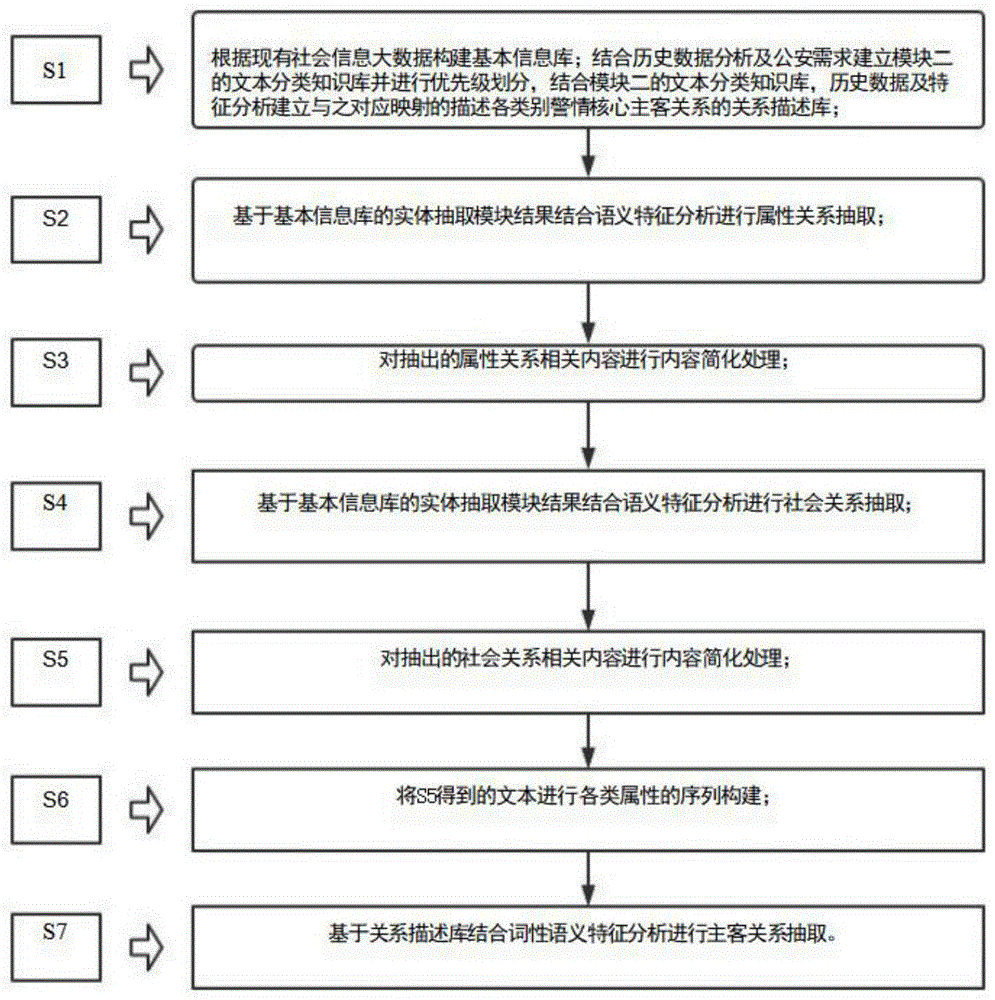
S1、根据现有社会信息大数据构建基本信息库;结合历史数据分析及公安需求建立模块二的文本分类知识库并进行优先级划分;结合模块二的文本分类知识库,历史数据及特征分析建立与之对应映射的描述各类别警情核心主客关系的关系描述库;
S2、基于基本信息库的实体抽取模块结果结合语义特征分析进行属性关系抽取;
S3、对抽出的属性关系相关内容进行内容简化处理;
S4、基于基本信息库的实体抽取模块结果结合语义特征分析进行社会关系抽取;
S5、对抽出的社会关系相关内容进行内容简化处理;
S6、将S5得到的文本进行各类属性的序列构建;
S7、基于关系描述库结合词性语义特征分析进行主客关系抽取。
进一步的,S1中,基本信息库包括地址数据库、组织机构数据库、犯罪手段数据库、角色数据库、物品数据库、车辆数据库、银行卡数据库、虚拟账号数据库和地址数据库。
进一步的,S1中,所述文本分类知识库按照重要程度划分为一级库,二级库和三级库。
进一步的,S2所述基于基本信息库的实体抽取模块结果结合语义特征分析进行属性关系抽取,包括以下步骤:
S2.1、获取基于基本信息库的实体抽取模块结果的各实体抽取结果;
S2.2、对各实体在句子中的位置进行定位;
S2.3、结合各实体在句子中的位置定位,计算实体间距离,根据距离初步缩小实体关系范围;
S2.4、对根据实体间距离进行初步筛选后的各实体间进行语义特征分析,结合出警数据的语义特征对实体间进行二轮筛除,排除掉实体间距离较近,但语义不通的实体对,留下的实体对即为抽取出的文中属性关系;
进一步的,S3中所述对抽出的属性关系相关内容进行内容简化处理具体为:对属性关系中的次要实体及描述在句子中进行搜寻定位;并将搜寻定位出的内容进行数据中的筛除简化;
进一步的,S4中,基于基本信息库的实体抽取模块结果结合语义特征分析进行社会关系抽取;包括以下步骤:
S4.1、获取基于基本信息库的实体抽取模块的角色抽取结果;
S4.2、对人名实体和角色实体在句子中的位置进行定位;
S4.3、根据实体在句子中的位置定位,计算实体间距离,根据距离初步缩小实体关系范围;
S4.4、对根据实体间距离初步筛选后的各实体间进行语义特征分析,结合处警数据的语义特征对实体间进行二轮筛除,排除掉实体间距离较近,但语义不通的实体对,留下的实体对即为抽取出的文中属性关系;
S4.5、从原数据中筛除作为人物身份描述的角色实体,简化原数据。
进一步的,S5中所述对抽出的社会关系相关内容进行内容简化处理具体为:对属性关系中的为人物身份描述的角色实体以及人物身份具体定义的人物姓名实体在句子中进行搜寻定位;并将搜寻定位出的内容进行数据中的筛除简化。
进一步的,S6中,所述对文本进行各类属性的序列构建;包括以下步骤:
S6.1、对简化后的文本进行重新分词处理,及得到分词后的各属性,例如分词后各词语内容、词性、范围等;
S6.2、对分词后的各词语以专用分隔符为界,进行词语内容与分隔符交叉插入的形式,构建成文本的内容序列;
S6.3、对分词后的各词语以专用分隔符为界,进行词语词性与分隔符交叉插入的形式,构建成文本的词性序列;
S6.4、结合历史数据及语义特征分析,筛选出高频重要特征词知识库,以知识库的特征词内容及其它词语序列构成混合内容,与专用分隔符以交叉插入的形式,构建成文本的混合序列;
S6.5、根据专用分隔符为界,对文本的内容序列,词性序列及混合序列进行互相映射。
进一步的,S7中,基于关系描述库结合词性语义特征分析进行主客关系抽取具体包括以下步骤:
S7.1、获取基于关系描述库的文本分类模块结果
S7.2、根据文本分类模块返回结果进行主客关系约束,减少在各类别警情里出现错误主客关系的概率,首先对分类结果里优先级一的分类结果进行判断及带入关系描述进行搜寻,没有搜寻到再对分类结果里的优先级二的分类结果进行判断及带入关系描述进行搜寻;最后都没搜寻到则为没有优先级一分类,当为优先级三的分类的情况时,去除该文本的关系;
S7.3、结合词性序列和语义特征分析对主客关系进行抽取,抽取成功后进行序列映射操作,得到相关内容;
S7.4、抽取出S7.3中相关内容里的双方实体,与S7.2抽取出的关系描述合并为完整的关系三元组;
S7.5、以S7.2建立的核心主客关系的关系描述库为基础,对S7.4中的关系三元组的关系描述进行关系描述库替换。
本发明的有益效果是:
相比于传统的单独基于神经网络的有监督的关系抽取方法方法,本技术方案具所述方法更能结合实际情况,快速的对不同数据进行处理,不用经过人工标注,可迁移性更好;同时,根据实体和关系的不同类别,逐步处理消解,降低了多种关系互相之间产生的负面影响;最后,结合警情分类,根据语义特征进行关系双方实体定位,避免了所有实体两两配对,减少了冗余信息。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明面向警情数据的实体关系分层抽取方法流程图;
图2是本发明基于基本信息库的实体抽取模块结果结合语义特征分析进行属性关系抽取流程图;
图3是本发明基于基本信息库的实体抽取模块结果结合语义特征分析进行社会关系抽取流程图;
图4是本发明对文本进行各类属性的序列构建流程图;
图5是本发明基于关系描述库结合词性语义特征分析进行主客关系抽取流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
实施例1
参阅图1至图5所示,一种面向警情数据的实体关系分层抽取方法,其特征在于,包括以下步骤:
S1、根据现有社会信息大数据构建基本信息库;结合历史数据分析及公安需求建立模块二的文本分类知识库并进行优先级划分;结合模块二的文本分类知识库,历史数据及特征分析建立与之对应映射的描述各类别警情核心主客关系的关系描述库;S2、基于基本信息库的实体抽取模块结果结合语义特征分析进行属性关系抽取;S3、对抽出的属性关系相关内容进行内容简化处理;S4、基于基本信息库的实体抽取模块结果结合语义特征分析进行社会关系抽取;S5、对抽出的社会关系相关内容进行内容简化处理;S6、将S5得到的文本进行各类属性的序列构建;S7、基于关系描述库结合词性语义特征分析进行主客关系抽取。
S1中,基本信息库包括地址数据库、组织机构数据库、犯罪手段数据库、角色数据库、物品数据库、车辆数据库、银行卡数据库、虚拟账号数据库和地址数据库。能够实现对警情内容所提到的姓名实体等关键词相关联的内容进行提取,实现大数据筛选,提取,提高处理效率。
S1中,所述文本分类知识库按照重要程度划分为一级库,二级库和三级库。根据各实体存在的关系紧密程度进行划分,进而可以判断警情发生者关系范围。
S2所述基于基本信息库的实体抽取模块结果结合语义特征分析进行属性关系抽取,包括以下步骤:
S2.1、获取基于基本信息库的实体抽取模块结果的各实体抽取结果;实现将警情内容中与基本信息库中显示与实体相关联的信息提取出,便于警务人员对实体信息的了解。
S2.2、对各实体在句子中的位置进行定位;便于后期对各实体间关系的确定。
S2.3、结合各实体在句子中的位置定位,计算实体间距离,根据距离初步缩小实体关系范围;可以进一步确定各实体之间的关系,减小实体间关系错乱的情况,提高准确性。
S2.4、对根据实体间距离进行初步筛选后的各实体间进行语义特征分析,结合出警数据的语义特征对实体间进行二轮筛除,排除掉实体间距离较近,但语义不通的实体对,留下的实体对即为抽取出的文中属性关系;即可得到警情内容中与警情所提实体相关联的内容;
S3中所述对抽出的属性关系相关内容进行内容简化处理具体为:对属性关系中的次要实体及描述在句子中进行搜寻定位;并将搜寻定位出的内容进行数据中的筛除简化;
S4中,基于基本信息库的实体抽取模块结果结合语义特征分析进行社会关系抽取;包括以下步骤:
S4.1、获取基于基本信息库的实体抽取模块的角色抽取结果;将警情内容中的社会关系结合基本信息库内的关系情况,将各实体间的社会关系进行提取;
S4.2、对人名实体和角色实体在句子中的位置进行定位;实现对各实体间存在的社会关系进行定位,为后续各实体间社会关系确定做准备;
S4.3、根据实体在句子中的位置定位,计算实体间距离,根据距离初步缩小实体关系范围;提高准确性;
S4.4、对根据实体间距离初步筛选后的各实体间进行语义特征分析,结合处警数据的语义特征对实体间进行二轮筛除,排除掉实体间距离较近,但语义不通的实体对,留下的实体对即为抽取出的文中属性关系;即可得到警情内容中的各实体之间的社会关系。
S4.5、从原数据中筛除作为人物身份描述的角色实体,简化原数据。便于后续内容简化做准备;
S5中所述对抽出的社会关系相关内容进行内容简化处理具体为:对属性关系中的为人物身份描述的角色实体以及人物身份具体定义的人物姓名实体在句子中进行搜寻定位;并将搜寻定位出的内容进行数据中的筛除简化。
S6中,所述对文本进行各类属性的序列构建;包括以下步骤:
S6.1、对简化后的文本进行重新分词处理,及得到分词后的各属性,例如分词后各词语内容、词性、范围等;
S6.2、对分词后的各词语以专用分隔符为界,进行词语内容与分隔符交叉插入的形式,构建成文本的内容序列;
S6.3、对分词后的各词语以专用分隔符为界,进行词语词性与分隔符交叉插入的形式,构建成文本的词性序列;
S6.4、结合历史数据及语义特征分析,筛选出高频重要特征词知识库,以知识库的特征词内容及其它词语序列构成混合内容,与专用分隔符以交叉插入的形式,构建成文本的混合序列;
S6.5、根据专用分隔符为界,对文本的内容序列,词性序列及混合序列进行互相映射。
S7中,基于关系描述库结合词性语义特征分析进行主客关系抽取具体包括以下步骤:
S7.1、获取基于关系描述库的文本分类模块结果
S7.2、根据文本分类模块返回结果进行主客关系约束,减少在各类别警情里出现错误主客关系的概率,首先对分类结果里优先级一的分类结果进行判断及带入关系描述进行搜寻,没有搜寻到再对分类结果里的优先级二的分类结果进行判断及带入关系描述进行搜寻;最后都没搜寻到则为没有优先级一分类,当为优先级三的分类的情况时,去除该文本的关系;
S7.3、结合词性序列和语义特征分析对主客关系进行抽取,抽取成功后进行序列映射操作,得到相关内容;
S7.4、抽取出S7.3中相关内容里的双方实体,与S7.2抽取出的关系描述合并为完整的关系三元组;
S7.5、以S7.2建立的核心主客关系的关系描述库为基础,对S7.4中的关系三元组的关系描述进行关系描述库替换。
实施例2
本实施例对模块二的建立及关系描述库的建立做叙述,如下:
模块二和关系描述库都是“结合历史数据分析及公安需求建立”,但是数据库侧重作用不同(首先模块二是结合历史数据分析及公安需求建立的数据库,而关系描述库是在模块二的基础上,结合历史数据及特征分析对其建立映射的关系描述库;关系描述库与模块二数据库并不是一一映射,有的模块二数据库里没有与之对应的映射,有的模块二数据库里有多种分类对应的同一个映射,所以对其模块二数据库的文本分类类别进行一个优先级划分,当输入警情含有优先级1的取优先级1对应映射,其次输入警情为优先级2的取优先级2对应映射,最后输入警情为优先级3的警情类别不取映射)。模块二偏向描述整个数据的警情,基于此建立的映射主客关系库偏向描述警情内部具体的关系。两者有重叠,也有不同。
举例:“消费纠纷”文本分类警情里,存在(甲,消费纠纷,乙)的关系,两者描述重叠,在另一个“跳楼自杀”里,普遍存在(甲,报警求助,乙)的关系。
实施例3
本实施例对具体将本技术方案带入实际操作做叙述,如下所述:
(1)、根据现有社会信息大数据构建基本信息库;结合历史数据分析及公安需求建立描述各类别警情核心主客关系的关系描述库并进行优先级划分;然后输入警情内容“张三,511528XXXXXXXXXX18,殴打了妻子王五。”
(2)使用基于基本信息库的实体抽取模块结果结合语义特征分析进行属性关系抽取,抽出包含有(张三,身份证,511528XXXXXXXXXX18)的属性关系;
(3)、对已经抽出的属性关系相关内容进行内容简化处理,将原句简化为“张三,殴打了妻子王五。”;
(4)、使用基于基本信息库的实体抽取模块结果结合语义特征分析进行社会关系抽取,抽出包含有(张三,妻子,王五)的社会关系;
(5)、对已经抽出的社会关系相关内容进行内容简化处理,将句子简化为“张三,殴打了王五。”;
(6)、对文本进行各类属性的序列构建,为后续较为复杂的主客关系抽取做好预处理,例如混合序列:“张三w v u王五w”,其中w代表标点符号,v代表动词,u代表助词;
(7)、使用基于混合模型的文本分类模块结果结合词性语义特征分析进行主客关系抽取,抽出包含有(张三,殴打,王五)的主客动作关系。