一种评论高频词定向爬虫方法
文献发布时间:2024-04-18 20:01:55
技术领域
本发明属于网络数据挖掘和数据分析技术领域,具体涉及一种评论高频词定向爬虫方法。
背景技术
现有高频词爬虫方法在稳定性、加密机制解析和滑块验证处理方面存在缺陷,需要进一步优化和改进。其中一些现有技术方案可能通过设置随机代理IP和User-Agent来规避封禁,但由于加密机制不断更新,仍然存在被检测的风险,导致频繁被封禁或失效,爬取数据的稳定性较差。同时,平台(如抖音)采用了复杂的json加密方式,现有部分爬虫方法在解析评论数据时遇到困难,无法准确提取所需信息。而且,由于平台的滑块验证机制,现有的爬虫方法需要手动处理验证,影响了爬取的自动化程度和效率。现有的爬虫工具和库可以用于抓取评论数据,但它们的效率和稳定性有待改进。另外,由于滑块验证需要手动处理,现有方案仍然需要人工干预,影响了爬取的自动化程度和效率。
发明内容
发明目的:为了解决自媒体评论数据获取和分析过程中的效率低下、稳定性差以及滑块验证等问题。针对现有高频词爬虫方法存在的缺陷,本发明旨在提供一种高效、稳定且自动化的评论高频词定向爬虫方法,以便在社会热点事件分析和舆情研究中,能够快速、准确地获取大众对问题的看法和观点,从而为舆论监测和信息传播提供有力支持。
技术方案:为实现本发明的目的,本发明所采用的技术方案是:一种评论高频词定向爬虫方法,包括以下步骤:
步骤1:进行去自动化标志设置;后台运行Chrome浏览器并禁用GPU加速,配置浏览器选项用于隐藏自动化标志,最后通过执行Chrome DevTools Protocol命令将浏览器的navigator.webdriver属性设为undefined,用于规避对自动化工具的监测;
步骤2:进行登录等待;使用Selenium自动化工具打开浏览器并进入官网,通过二维码登录,等待用户登录;
步骤3:进行内容爬取;通过调用detection()函数进行滑块检测,然后使用execute_script方法获取当前页面的滚动高度,并定位评论部分滚动页面加载评论信息;通过检测滚动高度的变化,判断评论是否加载完成;
步骤4:进行数据分析;对爬取到的评论数据进行词频统计和分词处理,使用jieba分词工具生成高频词词云图;通过数据分析,提取争议热点事件舆论倾向的高频词,实现对评论信息的定向爬取和分析。
进一步的,步骤3中,完成对视频的所有评论信息进行爬取,过程如下:
首先调用detection()函数进行滑块检测,然后进入循环操作,通过check_height变量使用execute_script方法获取当前页面的滚动高度;
根据网页源代码,使用Xpath()方法定位.//span[@class="Nu66P_ba"]得到评论部分;
使用execute_script方法将页面滚动到底部加载评论信息,同时在滚动到底部后,通过window.scrollBy(0,-200)控制页面向上滚动若干个像素的距离,循环操作后持续滚动直到没有评论可加载为止;
此时通过check_height1变量再次使用execute_script方法获取滚动操作后页面的滚动高度;
再比较滚动高度:将check_height和check_height1进行比较,如果两者相等,则说明没有更多的评论需要加载,跳出循环;
最后将得到的评论数据表格化,进行存储。
进一步的,爬取采用深度优先,按照最新时间排序,爬取最新的相关数据,同时设置向上滚动,自动化模拟用户操作。
有益效果:与现有技术相比,本发明的评论高频词定向爬虫方法具有以下有益效果:
1.高效稳定的数据获取:通过去自动化标志设置和滑块检测方法,本发明能够稳定地抓取评论数据,避免了频繁封禁和失效的情况,提高了数据获取的效率和稳定性。相较于传统手动检索和收集数据的方式,本发明的自动化爬虫方法能够在较短的时间内收集大量评论数据,为后续舆论分析提供了更充分的数据支持。
2.自动化处理与准确分析:本发明采用Selenium自动化工具进行登录等待和滚动操作,实现了对评论数据的自动化爬取,减少了人工干预,提高了数据爬取的自动化程度。此外,通过jieba分词工具对评论数据进行高频词提取,能够更准确地分析用户观点和舆论倾向,为社会热点事件分析和舆情研究提供更可靠的数据支持。
3.提高舆情研究效率:由于平台用户规模庞大,评论数量巨大,传统的人工分析难以满足分析的需要。本发明的高频词定向爬虫方法能够自动抓取评论数据并快速提取高频词,大大缩短了舆情分析的时间,帮助用户快速了解大众对于热点事件的观点和情感倾向。
4.支持社会舆论监测:重要的信息传播平台上,大量用户的评论信息反映了社会舆论的动态和变化。本发明的方法能够实时、准确地提取评论数据,支持社会舆论监测机构和媒体进行实时舆情监测和分析,为社会舆论的引导和调控提供有力支持。
综上所述,本发明的自媒体评论高频词定向爬虫方法通过自动化处理、高效稳定的数据获取和准确分析,能够提高舆情研究效率,支持社会舆论监测,为社会热点事件分析和舆情研究提供更可靠的数据支持。
附图说明
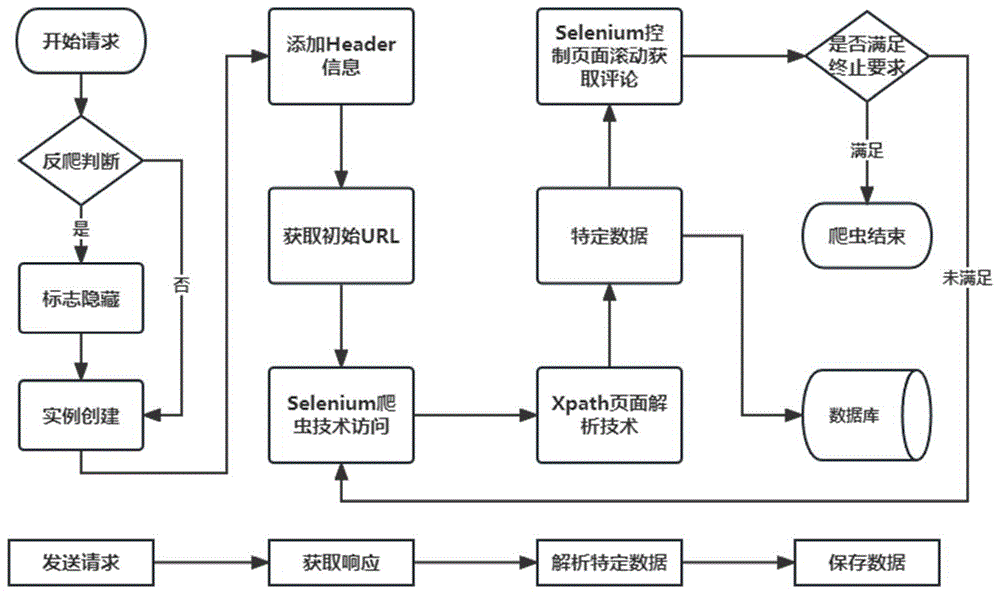
图1是基于Selenium的爬虫流程图;
图2是爬虫程序抓取后存储的CSV文件;
图3是对评论内容进行jieba分词后生成的CSV文件;
图4是评论高频词词云。
具体实施方式
下面结合附图和实施例对本发明的技术方案作进一步的说明。
本发明所述的一种评论高频词定向爬虫方法,通过定向爬虫方法,针对自媒体评论数据,实现评论高频词的抓取和分析。该领域涉及了网络爬虫、数据获取、数据处理和数据分析等相关技术,旨在从评论中提取出高频词,进而分析舆论倾向或热点事件的关键词,为舆情研究和社会舆论监测提供有力的支持和参考。流程如图1,具体实现包括以下步骤:
一、开始请求:
反爬判断:开发者经过观察网页源码发现,网页会检测浏览器的用户代理(User-Agent),以及浏览器启动时的特定标志或选项,经过测试后发现需要进行设置标志隐藏去绕过的反爬措施。
标志隐藏:基于对网页源代码和实际测试后发现,大部分网页对于用户代理都会经过测试去判断是否有特殊情况。所以可以统一作标志隐藏操作,设置无头模式和禁用自动化化控制,同时禁用了自动化工具,自动化扩展和CDP命令以防止网站检测到测试或爬虫行为。
实例创建:最后使用指定的路径和浏览器对象创建一个实例化的WebDriver,并传入标志隐藏部分创建并设置好的浏览器选项,通过上述操作,可以更好地控制浏览器的行为。
二、获取响应:
添加Header信息:在发送请求之前,程序会添加一些自定义的HTTP头部信息,例如用户代理(User-Agent)、授权信息等。这样做是为了模拟浏览器发送请求的行为,使请求看起来更像是由真实用户发出的。
获取初始URL:程序会获取初始的URL,即要开始爬取的页面的URL。这个URL通常是用户指定的入口链接或者是根据之前的操作从数据库或其他来源获取的。
使用Selenium爬虫技术访问:程序会利用Selenium库来模拟浏览器的行为,自动打开目标网页并发送HTTP请求。Selenium可以模拟用户在浏览器中的操作,如点击、填写表单等。通过Selenium,程序可以获取完整的网页内容,包括HTML、JavaScript和CSS等。
同时本发明引入并设置了去自动化标签,滑块检测、类人化滚动加载评论信息,提供了爬取成功的三重保证,提高了爬取的稳定性。
三、解析特定数据阶段:
使用Xpath页面解析技术:Xpath是一种用于在XML和HTML文档中进行导航和查找元素的语言。在这一步,程序会使用Xpath技术来解析页面,定位到包含评论数据的元素。
转到特定数据:通过Xpath表达式,程序会找到包含评论数据的页面元素,并提取所需的评论数据。
使用Selenium控制页面滚动获取URL:有时,网页的内容可能需要通过滚动页面来动态加载。在这一步,程序会使用Selenium来模拟页面的滚动行为,以获取更多的URL。
四、数据保存:
将特定数据存入数据库:程序会将提取到的特定数据存储到数据库中,以便后续的处理和分析。数据库可以是关系型数据库(如MySQL、PostgreSQL)或非关系型数据库(如MongoDB)。
判断是否满足终止要求:在滚动获取URL后,程序会判断是否满足终止要求,即是否已经获取到了足够的数据或达到了预定设置的滑动到页面底端没有更多评论的条件。如果满足终止要求,程序将结束执行。如果未满足终止要求,程序将继续使用Selenium进行页面访问,并回到获取响应的开始继续循环。
Step1:去自动化标志
因为针对对应的浏览器自动化标志也设置了检测,所以需要提前设置在后台运行Chrome浏览器并禁用GPU加速以提高爬取稳定性,配置浏览器选项以隐藏自动化标志以减少被网站检测为爬虫的可能性,最后为了进一步隐藏自动化标志,通过执行一个ChromeDevTools Protocol(CDP)命令,将浏览器的navigator.webdriver属性的值设为undefined。建立与浏览器的会话,并最大化浏览器窗口,以便获取评论数据。
Step2:登录等待
为了增加用户量,进入页面就会弹出登录窗口,因此需要使用Selenium的过程中等待用户登录的方法。首先使用Selenium自动化工具,通过驱动自动打开谷歌并进入官网,提前设置好时间间隔,本实验设置的是10秒,利用时间间隔扫码登录,方便下面自动化提取过程。
Step3:内容爬取
至此,开始对内容进行爬取,实验目标是完成对视频的所有评论信息进行爬取。
首先调用detection()函数进行滑块检测,以确保后续滚动操作的顺利进行。然后进入循环操作,通过check_height变量使用execute_script方法获取当前页面的滚动高度。
下面就需要在页面展示更多的评论信息,根据网页源代码,使用Xpath()方法定位.//span[@class="Nu66P_ba"]得到评论部分。
使用execute_script方法将页面滚动到底部以加载更多的评论信息,同时在滚动到底部后,通过window.scrollBy(0,-200)控制页面向上滚动200像素的距离以避免滚动到底部时可能出现的加载问题,循环操作后持续滚动直到没有更多评论可加载为止。
此时用check_height1变量:再次使execute_script方法获取滚动操作后页面的滚动高度。再比较滚动高度:将check_height和check_height1进行比较,如果两者相等,则说明没有更多的评论需要加载,跳出循环。最后将得到的评论数据表格化,方便存储。
因此在视频页面,为了保证爬取的数据在后续分析中具有研究意义,本次爬取采用深度优先,按照最新时间排序,尽可能多地爬取最新的相关数据,保证分析出的数据在具有客观性的同时,具有更强的时效性。同时为了被检测出异常并减少滑块的弹出,设置了向上滚动,更好地自动化模拟了用户操作。
Step4:数据分析
在爬取到相应评论数据并生成csv文件如图2后,需要对数据进行词频统计,对数据进行分词处理,使用jieba分词工具的精确模式对数据进行分词,分词结果如图3,对前二十位高频词进行排序,并生成词云图如下图4。通过数据处理,可以发现,比如对于社会话题“月供超过月租,买房真的值吗?”可以发现公众的舆论发言倾向。同时在后续的实验中,使用了更多的对社会话题重复上述实验,最终发现公众的用语倾向。
综合运用多种技术规避反爬措施:本发明结合了去自动化标志设置、滑块检测、Selenium自动化工具等多种技术手段,有效规避了对自动化工具的监测和反爬措施,保障了数据爬取的稳定性和效率。这种综合运用多种技术的方式,使得本发明具有更高的实用性和适用性,是现有技术所不具备的创新点。
类人化滚动加载评论信息:在爬取过程中,本发明不仅仅是简单地滚动页面到底部加载评论信息,而是通过类人化的滚动方式,即在滚动到底部后,向上滚动再向下滚动,避免频繁加载和规避反爬机制。这种滚动加载方式更加接近真实用户的行为,减少了被识别为爬虫的可能性,具有创新性和实用性。
滑块检测与验证:本发明引入了滑块检测方法,通过调用detection()函数进行滑块检测,确保后续滚动操作的正常进行。这种滑块检测与验证的机制,提高了抓取过程的稳定性和成功率,对于现有技术中所缺乏的反爬虫措施进行了创新补充。
本发明提供了一种高效、稳定且自动化的评论高频词定向爬虫方法。通过去自动化标志设置、Selenium自动化工具的登录等待,以及创新的滑块检测方法,本发明能够稳定地抓取评论数据,减少被检测的风险,并提高数据获取和处理的自动化程度,从而更好地满足社会热点事件分析和舆情研究的需求。
综上所述,本发明的创造性和新颖性特征主要体现在对多种技术手段的综合运用、类人化滚动加载评论信息的实现以及滑块检测与验证的引入,这些特征使得本申请与现有技术有明显的区别和创新,具有更高的实用性和创造性。