基于条件随机场的配电网检修单安全措施语义解析方法
文献发布时间:2023-06-19 09:32:16
技术领域
本发明属于电力技术领域,具体涉及一种基于条件随机场的配电网检修单安全措施语义解析方法。
背景技术
配电网中检修申请单安全措施文字的智能解析实质是一种对自然语言的解析过程,1956年以前,人们主要进行自然语言处理的基础性研究工作。1948年Shannon把离散马尔可夫过程的概率模型应用于描述语言的自动机;同时又把“熵”的概念引用到语言处理中。而Kleene在同一时期研究了有限自动机和正则表达式。1956年,Chomsky又提出了上下文无关语法。这些工作导致了基于规则和基于概率两种不同的自然语言处理方法的诞生,使得该领域的研究分成了采用规则方法的符号派和采用概率方法的随机派两大阵营,进而引发了数十年有关这两种方法孰优孰劣的争执。1956年,人工智能诞生以后,自然语言处理迅速融入了人工智能的研究中。1967年美国心理学家Neisser提出了认知心理学,从而把自然语言处理与人类的认知联系起来。70年代初,由于自然语言处理研究中的一些问题未能在短时间内得到解决,而新的问题又不断地涌现,自然语言处理的研究进入了低谷时期。基于隐马尔可夫模型(HMM)的统计方法和话语分析在这一时期取得了重大进展。 80年代,有限状态模型和经验主义的研究方法开始复苏。90年代以后,随着计算机的速度和存储量大幅增加,自然语言处理的物质基础大幅改善,语音和语言处理的商品化开发成为可能;同时,网络技术的发展和1994年Internet商业化使得基于自然语言的信息检索和信息抽取的需求变得更加突出。从90年代末到21世纪初,人们逐渐认识到,仅用基于规则的方法或仅用基于统计的方法都是无法成功进行自然语言处理的。基于统计、基于实例和基于规则的语料库技术在这一时期开始蓬勃发展,各种处理技术开始融合,自然语言处理的研究又开始兴旺起来。
目前随着计算机技术的不断发展,配电网检修申请单的安全措施的文本解析大多采用向量空间模型的精确词匹配方法,即精确匹配用户输入的词与向量空间中存在的词,从而实现安全措施文本的解析,但是依然存在着如下的问题:
1、纯代码实现的解析模型,通用型很差,相关技术难以推广;
2、对解析模型的定制人员的技术要求较高,在规则变化后,在修改程序时,还不能影响原有的功能,造成系统的稳定性较差
3、对历史数据的利用率较低,无法直接从历史数据中提炼解析样本。
4、局部规则的改变也需要进行程序的修改,无法通过简单的样本定制或配置修改来适应局部规则的变化。
发明内容
本发明的目的在于提供一种基于条件随机场的配电网检修单安全措施语义解析方法,采用基于条件随机场的机器学习的方式,在实现自然语义解析基本算法引擎的基础上,创建电力调控语料库,同时提炼申请单安全措施的历史文本,形成解析样本并进行训练,将训练出的模型用于申请单安全措施的文本解析,如果出现语义规则的变化,只用增加解析样本,并进行训练即可实现申请单安全措施的文本解析。
为实现上述目的,本发明的技术方案是:一种基于条件随机场的配电网检修单安全措施语义解析方法,包括如下步骤:
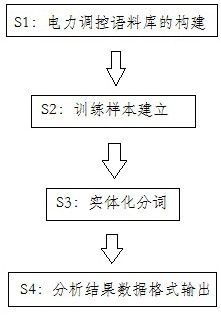
步骤S1、电力调控语料库的构建:
电力调控语料库的构建分为检修申请单样本库、物理环境库及术语库三部分语料库的构建;其中,检修申请单样本库中为检修申请单安全措施;物理环境库主题为关键词样本库,关键词样本库分为CIM类型库、动作类型库、状态类型库、功能类型库;术语库中包括单位、固定搭配、不能归类到物理环境库中的固有短语;
步骤S2、训练样本建立:
提取检修申请单安全措施的历史文本,进行分词标准设计,进而构建词性标注训练样本,词性标注训练样本采用每个字符及其词性标签占一行,句子之间以空格隔开的形式;
步骤S3、实体化分词:
根据步骤S2的分词标准,并应用基于动态规划的Viterbi算法对检修申请单样本库中的待解析检修申请单安全措施进行分词操作,而后利用物理环境库确定分词后的词语对应的唯一实体;
步骤S4、分析结果数据格式:
采用XML输出检修申请单样本库中为待解析检修申请单安全措施的文本解析结果。
相较于现有技术,本发明具有以下有益效果:
本发明采用基于条件随机场的机器学习的方式,在实现自然语义解析基本算法引擎的基础上,创建电力调控语料库,同时提炼申请单安全措施的历史文本,形成解析样本并进行训练,将训练出的模型用于申请单安全措施的文本解析,如果出现语义规则的变化,只用增加解析样本,并进行训练即可实现申请单安全措施的文本解析。
附图说明
图1为本发明方法流程示意图。
图2为本发明检修申请单样本库示例。
图3为本发明物理环境库库示例TXT形式。
图4为本发明部分词性标注训练语料样本示例。
图5为本发明实体化模型示例。
图6为检修申请单安全措施的XML解析形式示例。
图7为语义解析功能界面。
具体实施方式
下面结合附图,对本发明的技术方案进行具体说明。
如图1所示,本发明提供了一种基于条件随机场的配电网检修单安全措施语义解析方法,包括如下步骤:
步骤S1、电力调控语料库的构建:
电力调控语料库的构建分为检修申请单样本库、物理环境库及术语库三部分语料库的构建;其中,检修申请单样本库中为检修申请单安全措施;物理环境库主题为关键词样本库,关键词样本库分为CIM类型库、动作类型库、状态类型库、功能类型库;术语库中包括单位、固定搭配、不能归类到物理环境库中的固有短语;
步骤S2、训练样本建立:
提取检修申请单安全措施的历史文本,进行分词标准设计,进而构建词性标注训练样本,词性标注训练样本采用每个字符及其词性标签占一行,句子之间以空格隔开的形式;
步骤S3、实体化分词:
根据步骤S2的分词标准,并应用基于动态规划的Viterbi算法对检修申请单样本库中的待解析检修申请单安全措施进行分词操作,而后利用物理环境库确定分词后的词语对应的唯一实体;
步骤S4、分析结果数据格式:
采用XML输出检修申请单样本库中为待解析检修申请单安全措施的文本解析结果。
以下为本发明的具体实现过程。
一种基于条件随机场的配电网检修单安全措施语义解析方法,实现如下:
1、电力调控语料库的构建
语料库是后续研究的基础,针对配电网检修申请单安全措施设计出能够支撑后续语义解析工作的详实可用的语料库是本发明的关键点。由于语料库的建立要求语料范围和覆盖类型都要尽可能取得平衡,结合安全措施文本对象的特点,本发明在建立语料库的过程中将整个语料库分为检修申请单样本库、物理环境库及术语库三部分。
1.1、检修申请单样本库
检修申请单样本库中为检修申请单安全措施。在语义解析过程中样本库可用于前期方案验证、模型训练、知识体构建。检修申请单样本库示例如图2所示。
1.2物理环境库
物理环境库主题为关键词样本库,关键词样本库分为CIM类型库、动作类型库、状态类型库、功能类型库。这些库中含有电网规则下的大部分物理含义信息,可以辅助添加在通用自然语言解析之上形成电网调度得具体解析规则,进一步搭建具体的物理环境。物理环境库可用于语境识别、语义识别、规则制定等。
以CIM类型关键词样本库为例,该样本库表中包括票令中绝大多数设备名称等名词性信息,如:变电站 、电压等级、同步电机、母线、变压器、交流线、断路器、接地刀闸、刀闸、杆塔等出现率较高的关键词以及串联电容器、串联电抗器、并联电容器、并联电抗器、PT、CT、熔断器、等值负荷、避雷器、消弧线圈等出现率较低的关键词。根据实际需求,各样本库可以扩充、修改。样本库形式初步拟定为TXT文本形式(如图3所示)。表1为物理环境库库示例说明。
表1 物理环境库库示例说明:
1.3术语库
术语库中包括单位、固定搭配、不能归类到物理环境库中的固有短语等,即作为物理环境库的补充,又可以在匹配、识别、转义时起到辅助识别的作用。参见表2以某地区的部分设备名术语库为例。
表2某地区的部分设备名术语库
2、训练及测试样本设计
通过提取样本中的电力调度系统命名词,将常用命名词分析归类,形成可用的命名词表,作为分词的基础之一。通过对分析对象的总结分析形成标注规则,方便新样本的加入,提高系统的的可扩展性。
2.1 电力调度系统命名词(参见表3)
表3电力调度系统命名词表
2.2 分词标准设计
以下规则为初次分词的细分规则:尽量细分成最基本的语义单元,部分规则如表4-6所示:
2.3词性标注训练样本建立
模型采用与中文分文联合标注的方法,即同时识别词及其所属词性。通过采用中文分词标签和词性标签相连的方式产生适合于联合标注的标签集合,如:“B_D”表示数词的开始字符。
词性标注训练样本采用每个字符及其标签占一行,句子之间以空格隔开的形式。分词文本来源于实际电力系统调度控制过程中实际使用的语句,实验过程中共用到样本1015 句,共计 8943个 字符。部分词性标注训练语料样本如图4所示。
3、基于语料库的实体化分词
利用2.2的分词标准,并应用基于动态规划的Viterbi算法,Viterbi算法的求解过程为给定隐马尔可夫模型和观测序列值,求解最优的状态序列值。
本发明利用Viterbi算法将词语分开,在利用物理环境库将具体的词语对应成唯一实体,需要将物理环境库转换为如图5的实体化模型。
由图5所示,电网的物理环境中有“500kV”与“5032开关”对应的多个实体,但“众兴变”和“舜耕变”对应的变电站实体却在整个电网物理环境中是唯一的。实体化子模型通过先确定变电站实体“众兴变”和“舜耕变”,来确定“500kV”和“5032开关”对应的实体。实体词词典中的属性值有“实体ID”、“容器ID”、“抽象词”、“实体词”、“唯一名称对应容器”等五个属性值。实体化子模型建立时,依据“实体ID”与“容器ID”所体现的层级关系来建立。“唯一名称对应容器”属性值的含义为在某一容器下,该词语对应的实体唯一。在图5中,“5032开关”对应实体的“容器ID”即为“500kV”对应实体的“实体ID”。“500kV”对应的实体在“变电站”这种容器下可被唯一确定。“众兴变”所对应的抽象词为“变电站”。
以文本“众兴变500kV众临线/龙兴线5032开关第一、二组控制电源消失”为例,当一个实体的实体ID唯一确定时,认为该实体是唯一确定的,由下表所示,在实体化之前,只有词语“众兴变”有唯一对应的实体ID,即认为它对应的实体能唯一确定,其它词语对应多个实体ID,即认为其它词语对应的实体ID不能唯一确定,受限于表格篇幅的影响,在实际环境中“500kV”与“5032”开关对应的实体ID不止表格中列出的三个。而经过实体化子模型后,以上词语均能在整个电网物理环境中寻找到唯一对应的实体。表7为实体化前后对比结果。
电网的物理环境中有“500kV”与“5032开关”对应的多个实体,但“众兴变”和“舜耕变”对应的变电站实体却在整个电网物理环境中是唯一的。实体化子模型通过先确定变电站实体“众兴变”和“舜耕变”,来确定“500kV”和“5032开关”对应的实体。
4、分析结果数据格式设计
采用XML用于标记电子文件使其具有结构性的标记语言,可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。 XML是标准通用标记语言(SGML) 的子集,非常适合 Web 传输。XML 提供统一的方法来描述和交换独立于应用程序或供应商的结构化数据。
目前常用的语义解析结果形式为XML形式,以指令“10kV华芳116线路由检修转运行”为例,其XML解析形式如图6所示。
上例中结点标签分别为 xml4nlp、para、sent、word、arg,其含义如表8所示:
XML是用于模块之间通信的信息模型,是模块化的具有明确物理含义的通用的对象化规则化信息表述,形式上是包含特定名词及其物理环境标注的XML结果。模型解析(转义)的可扩展性可基于物理环境库语句的增删。可设立节点标签,改变节点标签(个数、含义)进行物理环境的实例化(对象化)。通过节点标签可以实现兼容性,以应用神经网络的不同属性(形式)的数据结果。
XML形式的知识体本身是个包含语义含义的标准形式,根据预先设定的标准形成,具体是什么内容可以通过标准来设定,用户读取它形成数据结构。
5、语义解析功能实现
语义解析功能界面如图7所示,语义解析界面包括解析对象、解析方法、日志记录三部分。
解析对象部分提供了操作单位、操作厂站等待解析指令业务所属物理环境的下拉选择菜单,可用于选择相应的调控中心,以对应不同领域语料库训练得到的模型,操作内容即为待解析文本,解析方法部分包括解析申请单安全错、指令票任务、指令票步骤、操作票任务、操作票步骤等方法,可根据实际需求进行文字的解析。日志记录部分用于记录解析过程中的操作和调试信息。
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
- 基于条件随机场的配电网检修单安全措施语义解析方法
- 一种基于潜在语义分析的申请单智能解析方法