一种基于深度学习的机器人语音控制方法
文献发布时间:2023-06-19 09:43:16
技术领域
本发明属于人工智能技术领域,具体涉及一种基于深度学习的机器人语音控制方法。
背景技术
近些年来,机器人智能水平的提高和语音识别技术研究取得重大突破,机器人语音控制技术已经成为科技发展最前沿的领域之一。
随着不同功能的移动机器人被广泛应用到各个领域中,键盘和手柄等传统的控制方式已经难以满足人与机器人协同工作的需求,人们迫切需要一种高效方便的方法实现人机交互,机器人语音控制技术能够让机器人对人的语音内容进行识别,并按照人的指令完成指定任务。
机器人语音控制可分为几个过程:语音信号的预处理、特征参数提取、语音信号的识别与控制。其中,基于神经网络的语音识别方法是目前最热门的语音识别方法之一,该方法通过建立语音信号的声学模型,有效地改善了传统方法中训练时间短和识别准确率低的缺点。目前,国内在这方面尚无十分成熟的技术。
发明内容
本发明的目的是提供一种基于深度学习的机器人语音控制方法,该方法简化了基于GMM-HMM的混合声学模型,加强了对相邻语音帧之间的联系。
本发明所采用的技术方案是一种基于深度学习的机器人语音控制方法,具体步骤如下:
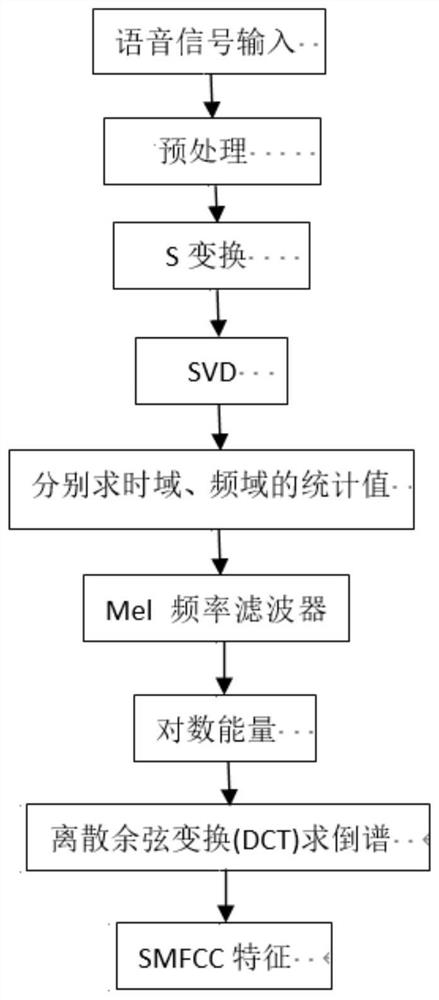
步骤1:利用SMFCC算法提取语音信号的特征;
步骤2:应用CNN网络提取更加深层的语音特征;
步骤3:经池化层处理后的语音数据送入LSTM网络进行时序特征提取;
步骤4:判断误差值是否满足预先设置的阀值,或声学模型优化的迭代次数是否已达到预设值;
若是,则训练结束输出权值;
若否,返回步骤3继续训练。
步骤5:利用CTC算法对LSTM各个节点的输出权值进行自动对齐,完成语音信号的训练和识别。
步骤6:使用python编写语音控制机器人的代码,通过ROS的通信机制将各个模块串接,完成语音控制机器人过程。
本发明的特点还在于:
步骤1中提取特征参数的具体过程为:
步骤1.1:对输入的语音信号进行预处理;
步骤1.2:对S矩阵A进行奇异值分解(SVD)计算,经降噪处理后,得到矩阵B;
步骤1.3:对矩阵B求取统计值得到2N维的统计值向量C;
步骤1.4:通过Mel滤波器组以及求对数能量,得到离散余弦变换(DCT)倒谱,经DCT倒谱得到75维的SMFCC特征。
步骤1.1中对输入的语音信号x(n)进行预处理,对一帧语音信号进行S变换,得到S矩阵A:
对语音信号x(t)进行S变换:
g(τ,f)为高斯函数:
式(1)中,τ参数为高斯窗函数中心点,f为频率。
步骤1.2中对矩阵A进行奇异值分解(SVD)计算,通过奇异值取舍对S矩阵进行降噪,得到矩阵B:
若A为一个信号矩阵,那么A的奇异值按递减的顺序排列为σ
若k
设A为m×n矩阵,秩为r(r A=UDV 步骤1.3中分别对矩阵B的行列向量求取统计值,得到2N维向量C,即同时对语音信号的频域、时域进行处理。 步骤1.4中将向量C通过Mel滤波器组以及对数能量,求离散余弦变换(DCT)倒谱,得到SMFCC特征。 对数能量进行离散余弦变换(DCT),得到语音信号特征,公式如下:
式(4)中,M表示特征维数,计算每帧语音命令信号的特征分布。 步骤3的具体过程为: 步骤3.1:通过LSTM中的三个门对输入信息进行筛选,提高识别精度; 步骤3.2:通过Dropout层防止神经网络在训练过程中过拟合。 步骤3.1中LSTM中的输入门、忘记门和输出门对输入信息和上一时刻的信息进行筛选,有效防止神经网络在训练过程中发生梯度消失的问题,从而提高识别精度。i
步骤3.2中Dropout层以一定比例让LSTM网络中的一些隐含层的输出权重在训练中停止更新,保存到下次迭代过程时再被激活,有效防止了神经网络训练过程中的过拟合现象。 步骤5的具体过程为: 步骤5.1:经过CTC算法预测的序列结果与经LSTM进行时序特征提取的输出权重进行自动对齐; 步骤5.2:CTC算法引入blank,每个预测的分类对应语音数据被标记; 步骤5.1中CTC算法作为损失函数只需一个输入序列和一个输出序列即可训练,并直接输出序列预测的概率,与经LSTM输出的权重自动对齐。 步骤5.2中CTC算法自身引入的blank,每个预测的分类对应一整段语音数据的一个尖峰,其余位置被标记为blank,完成对语音信号的训练和识别。 步骤6的具体过程为: 步骤6.1:通过Python编写的control.py将深度学习网络输出的语音文本通过消息发布; 步骤6.2:把检测到的语音文本与语音库中的文本信息进行匹配,并发布该消息到命令相关的节点; 步骤6.3:经匹配和处理后,系统判断机器人的执行命令,并发布该消息到移动相关的节点; 步骤6.4:机器人接收到命令,实现语音控制机器人的运动。 本发明的有益效果是,本发明是一种基于深度学习的机器人语音控制方法,能够有效地改善传统方法中训练时间短和识别准确率低的缺点,简化基于GMM-HMM的混合声学模型,加强对相邻语音帧之间的联系。 附图说明 图1是本发明一种基于深度学习的机器人语音控制方法的特征提取流程图; 图2是本发明一种基于深度学习的机器人语音控制方法的训练流程图; 具体实施方式 下面结合附图和具体实施方式对本发明进行详细说明。 本发明一种基于深度学习的机器人语音控制方法,通过SMFCC方法提取语音信号特征具体包括如下步骤: 如图1所示,具体步骤如下: 步骤1:利用SMFCC算法提取语音信号的特征,主要步骤如下: 步骤1.1:对输入的语音信号进行预处理; 步骤1.2:对S矩阵A进行奇异值分解(SVD)计算,经降噪处理后,得到矩阵B; 步骤1.3:对矩阵B求取统计值得到2N维的统计值向量C; 步骤1.4:通过Mel滤波器组以及求对数能量,得到离散余弦变换(DCT)倒谱,经DCT倒谱得到75维的SMFCC特征。 如图2所示,具体步骤如下: 步骤2:应用CNN网络提取更加深层的语音特征; 步骤3:经池化层处理后的语音数据送入LSTM网络进行时序特征提取,主要步骤如下: 步骤3.1:通过LSTM中的三个门对输入信息进行筛选,提高识别精度; 步骤3.2:通过Dropout层防止神经网络在训练过程中过拟合。 步骤5:利用CTC算法对LSTM各个节点的输出权值进行自动对齐,完成语音信号的训练和识别; 步骤5.1:经过CTC算法预测的序列结果与经LSTM进行时序特征提取的输出权重进行自动对齐; 步骤5.2:CTC算法引入blank,每个预测的分类对应语音数据被标记。 步骤6:使用python编写语音控制机器人的代码,通过ROS的通信机制将各个模块串接,完成语音控制机器人过程; 步骤6.1:通过Python编写的control.py将深度学习网络输出的语音文本通过消息发布; 步骤6.2:把检测到的语音文本与语音库中的文本信息进行匹配,并发布该消息到命令相关的节点; 步骤6.3:经匹配和处理后,系统判断机器人的执行命令,并发布该消息到移动相关的节点; 步骤6.4:机器人接收到命令,实现语音控制机器人的运动。 本发明一种基于深度学习的机器人语音控制方法依据卷积神经网络(CNN)、长短期记忆模型(LSTM)、时序分类模型(CTC)相结合的一种新的语音识别模型,搭建CNN-LSTM-CTC声学模型,完成对语音信号的TEOGFCC特征参数提取,利用新的混合声学模型提取更深层的特征,经LSTM网络对语音数据进行时序特征提取,再经CTC算法完成对语音信号的训练和识别。本发明一种基于深度学习的机器人语音控制方法能够有效地改善传统方法中训练时间短和识别准确率低的缺点,使得人机交互更加高效便捷。
- 一种基于深度学习的机器人语音控制方法
- 一种基于深度学习来实现语音导航机器人的方法