基于虚拟现实的实时交互方法、装置、设备及存储介质
文献发布时间:2023-06-19 09:55:50
技术领域
本发明涉及虚拟现实技术领域,尤其涉及一种基于虚拟现实的实时交互方法、装置、设备及存储介质。
背景技术
随着虚拟现实技术的发展,越来越多的领域开始采用虚拟现实技术进行模型交互,比如科技馆的全息交互展览台、虚拟现实游戏(即VR游戏)等,然而现有技术中在基于虚拟现实技术进行模型交互时,大多都存在穿模现象,沉浸感较差,且模型交互的延迟感明显,极大地影响了用户体验,因此,如何提高基于虚拟现实的实时交互体验和沉浸感,成为一个亟待解决的问题。
上述内容仅用于辅助理解本发明的技术方案,并不代表承认上述内容是现有技术。
发明内容
本发明的主要目的在于提供了一种基于虚拟现实的实时交互方法、装置、设备及存储介质,旨在解决如何提高基于虚拟现实的实时交互体验和沉浸感的技术问题。
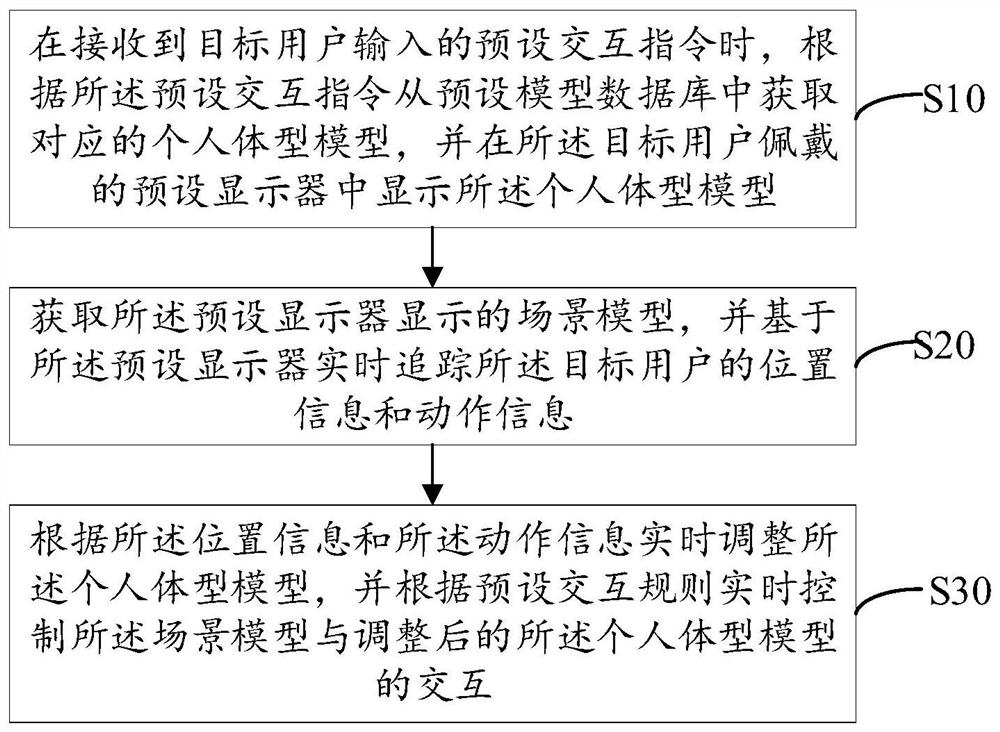
为实现上述目的,本发明提供了一种基于虚拟现实的实时交互方法,所述方法包括以下步骤:
在接收到目标用户输入的预设交互指令时,根据所述预设交互指令从预设模型数据库中获取对应的个人体型模型,并在所述目标用户佩戴的预设显示器中显示所述个人体型模型;
获取所述预设显示器显示的场景模型,并基于所述预设显示器实时追踪所述目标用户的位置信息和动作信息;
根据所述位置信息和所述动作信息实时调整所述个人体型模型,并根据预设交互规则实时控制调整后的所述个人体型模型与所述场景模型的交互。
优选地,所述在接收到目标用户输入的预设交互指令时,根据所述预设交互指令从预设模型数据库中获取对应的个人体型模型,并在所述目标用户佩戴的预设显示器中显示所述个人体型模型的步骤之前,还包括:
扫描目标用户的个人体型数据,并基于所述个人体型数据建立初阶几何模型;
基于所述初阶几何模型建立个人骨架模型,并基于所述个人骨架模型建立用于交互的第一交互层和用于防穿模的第二交互层;
基于所述第一交互层、所述第二交互层以及所述个人骨架模型生成个人体型模型。
优选地,所述根据所述位置信息和所述动作信息实时调整所述个人体型模型,并根据预设交互规则实时控制调整后的所述个人体型模型与所述场景模型的交互的步骤,具体包括:
根据所述位置信息和所述动作信息实时调整所述个人体型模型;
获取所述场景模型的场景基础层,计算所述场景基础层与调整后的所述个人体型模型的第二交互层之间的相对距离;
获取所述场景模型的场景种类,根据所述场景种类获取所述场景模型的压力反馈值;
根据所述压力反馈值和所述相对距离实时控制调整后的所述个人体型模型的第一交互层与所述场景模型的交互。
优选地,所述在接收到目标用户输入的预设交互指令时,根据所述预设交互指令从预设模型数据库中获取对应的个人体型模型的步骤,具体包括:
在接收到目标用户输入的预设交互指令时,获取所述预设交互指令的指令类型;
在所述指令类型为第三视角交互指令时,根据所述预设交互指令从预设模型数据库中获取对应的个人体型模型。
优选地,所述获取所述预设显示器显示的场景模型,并基于所述预设显示器实时追踪所述目标用户的位置信息和动作信息的步骤,具体包括:
获取所述预设显示器显示的场景模型,并基于所述预设显示器实时追踪所述目标用户的位置信息和动作信息;
在检测到所述场景模型中存在预设反射模型时,实时追踪所述目标用户的面部表情信息;
相应地,所述根据所述位置信息和所述动作信息实时调整所述个人体型模型,并根据预设交互规则实时控制调整后的所述个人体型模型与所述场景模型的交互的步骤,具体包括:
根据所述位置信息、所述动作信息以及所述面部表情信息实时调整所述个人体型模型,并根据预设交互规则实时控制调整后的所述个人体型模型与所述场景模型的交互。
优选地,所述在接收到目标用户输入的预设交互指令时,获取所述预设交互指令的指令类型的步骤之后,还包括:
在所述指令类型为第一视角交互指令时,根据所述预设交互指令从所述预设模型数据库中获取对应的个人手部模型;
对所述个人手部模型进行预设细化处理,获得目标手部模型,并将所述目标手部模型作为所述个人体型模型。
优选地,所述在接收到目标用户输入的预设交互指令时,根据所述预设交互指令获取所述目标用户存储在预设模型数据库中对应的个人体型模型,并在所述目标用户佩戴的预设显示器中显示所述个人体型模型的步骤之前,还包括:
在接收到目标用户输入的自改模指令时,在预设显示器显示预设标准模型;
接收所述目标用户基于所述预设标准模型输入的模型修改指令,基于所述模型修改指令对所述预设标准模型进行修改,生成个人体型模型。
此外,为实现上述目的,本发明还提出一种基于虚拟现实的实时交互装置,所述装置包括:
模型获取模块,用于在接收到目标用户输入的预设交互指令时,根据所述预设交互指令从预设模型数据库中获取对应的个人体型模型,并在所述目标用户佩戴的预设显示器中显示所述个人体型模型;
实时追踪模块,用于获取所述预设显示器显示的场景模型,并基于所述预设显示器实时追踪所述目标用户的位置信息和动作信息;
交互控制模块,用于根据所述位置信息和所述动作信息实时调整所述个人体型模型,并根据预设交互规则实时控制调整后的所述个人体型模型与所述场景模型的交互。
此外,为实现上述目的,本发明还提出一种基于虚拟现实的实时交互设备,所述设备包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的基于虚拟现实的实时交互程序,所述基于虚拟现实的实时交互程序配置为实现如上文所述的基于虚拟现实的实时交互方法的步骤。
此外,为实现上述目的,本发明还提出一种存储介质,所述存储介质上存储有基于虚拟现实的实时交互程序,所述基于虚拟现实的实时交互程序被处理器执行时实现如上文所述的基于虚拟现实的实时交互方法的步骤。
本发明在接收到目标用户输入的预设交互指令时,根据所述预设交互指令从预设模型数据库中获取对应的个人体型模型,并在所述目标用户佩戴的预设显示器中显示所述个人体型模型,获取所述预设显示器显示的场景模型,并基于所述预设显示器实时追踪所述目标用户的位置信息和动作信息,根据所述位置信息和所述动作信息实时调整所述个人体型模型,并根据预设交互规则实时控制所述场景模型与调整后的所述个人体型模型的交互。通过根据目标用户输入的预设交互指令获取对应的个人体型模型而不是直接获取预设的模型进行后续交互,以提高目标用户的参与感和沉浸感,通过实时追踪目标用户的位置信息和动作信息,并根据所述位置信息和所述动作信息实时调整所述个人体型模型以实现实时根据目标用户的自身运动情况控制个人体型模型的运动,提高目标用户的实时交互体验,通过根据预设交互规则实时控制调整后的所述个人体型模型与所述场景模型的交互以实现实时与所见场景的交互,提高目标用户的沉浸感。
附图说明
图1是本发明实施例方案涉及的硬件运行环境的基于虚拟现实的实时交互设备的结构示意图;
图2为本发明基于虚拟现实的实时交互方法第一实施例的流程示意图;
图3为本发明基于虚拟现实的实时交互方法第二实施例的流程示意图;
图4为本发明基于虚拟现实的实时交互装置第一实施例的结构框图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
参照图1,图1为本发明实施例方案涉及的硬件运行环境的基于虚拟现实的实时交互设备结构示意图。
如图1所示,该基于虚拟现实的实时交互设备可以包括:处理器1001,例如中央处理器(Central Processing Unit,CPU),通信总线1002、用户接口1003,网络接口1004,存储器1005。其中,通信总线1002用于实现这些组件之间的连接通信。用户接口1003可以包括显示屏(Display)、输入单元比如键盘(Keyboard),可选用户接口1003还可以包括标准的有线接口、无线接口。网络接口1004可选的可以包括标准的有线接口、无线接口(如无线保真(WIreless-FIdelity,WI-FI)接口)。存储器1005可以是高速的随机存取存储器(RandomAccess Memory,RAM)存储器,也可以是稳定的非易失性存储器(Non-Volatile Memory,NVM),例如磁盘存储器。存储器1005可选的还可以是独立于前述处理器1001的存储装置。
本领域技术人员可以理解,图1中示出的结构并不构成对基于虚拟现实的实时交互设备的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
如图1所示,作为一种存储介质的存储器1005中可以包括操作系统、数据存储模块、网络通信模块、用户接口模块以及基于虚拟现实的实时交互程序。
在图1所示的基于虚拟现实的实时交互设备中,网络接口1004主要用于与网络服务器进行数据通信;用户接口1003主要用于与用户进行数据交互;本发明基于虚拟现实的实时交互设备中的处理器1001、存储器1005可以设置在基于虚拟现实的实时交互设备中,所述基于虚拟现实的实时交互设备通过处理器1001调用存储器1005中存储的基于虚拟现实的实时交互程序,并执行本发明实施例提供的基于虚拟现实的实时交互方法。
本发明实施例提供了一种基于虚拟现实的实时交互方法,参照图2,图2为本发明基于虚拟现实的实时交互方法第一实施例的流程示意图。
本实施例中,所述基于虚拟现实的实时交互方法包括以下步骤:
步骤S10:在接收到目标用户输入的预设交互指令时,根据所述预设交互指令从预设模型数据库中获取对应的个人体型模型,并在所述目标用户佩戴的预设显示器中显示所述个人体型模型;
易于理解的是,在接收到目标用户输入的预设交互指令时,可根据所述预设交互指令从预设模型数据库中获取对应的个人体型模型,所述预设交互指令主要用来判断交互种类,所述交互种类可为以第一视角交互、以第三视角交互等,所谓以第一视角交互,即只显示个人体型模型中手部区域(也可包含预设长度的手臂区域,所述预设长度可根据实际需求而定,在具体实现中,若目标用户未对预设长度进行设置,可直接根据预设模型数据库中目标用户设定次数最多的目标预设长度作为默认的预设长度)对应的手部模型,然后通过手部模型与场景模型进行实时交互;所谓以第三视角进行交互,即显示目标用户对应的完整的个人体型模型(可理解为从头到脚的人物模型),然后通过个人人体模型与场景模型进行实时交互。
相应地,在接收到目标用户输入的预设交互指令时,可获取所述预设交互指令的指令类型,所述指令类型可分为第一视角交互指令和第三视角交互指令,所谓第一视角交互指令即基于上述以第一视角交互的交互种类确定的指令类型,所述第三视角交互指令即基于上述以第一视角交互的交互种类确定的指令类型。然后,根据确定的指令类型从预设模型数据库中获取对应的个人体型模型,若所述指令种类为第三视角交互指令,则根据所述预设交互指令从预设模型数据库中获取对应的个人体型模型;若所述指令种类为第一视角交互指令,则根据所述预设交互指令从预设模型数据库中获取对应的个人手部模型,再对所述个人手部模型进行预设细化处理,获得目标手部模型,并将所述目标手部模型作为所述个人体型模型,所述预设细化处理可为获取所述个人手部模型对应的三维坐标,并校验所述三维坐标的坐标精度,直至所述坐标精度大于预设坐标精度,所述预设坐标精度可基于历史校验精度确定,也可根据目标用户的指令进行校验,如在校验坐标精度到符合历史校验精度后,发出预设提示信息用以提示目标用户是否需要继续进行细化处理,若用户选择“是”对应的指令,则继续进行预设细化处理,若用户选择“否”对应的指令,则停止当前的预设细化处理,并输出当前的手部模型,作为个人体型模型。在具体实现中,除通过坐标校验来提高所述手部模型的模型精度外,还可通过平滑滤波技术(如,通过高斯滤波器进行平滑滤波,通过中值滤波器进行平滑滤波等)滤掉所述手部模型中不符合预设光滑标准的过渡区域来避免手部模型发生形变而产生的不平整现象,所述预设光滑标准可根据历史光滑标准确定,也可根据用户需求进行设置,本实施例在此不加以限制。高精度的手部模型的获得,提高了第一视角下目标用户的观感,也提高后续基于所述手部模型进行交互时的交互体验和沉浸感。进一步地,在根据所述预设交互指令从预设模型数据库中获得对应的个人体型模型后,可在所述目标用户佩戴的预设显示器中实时渲染所述个人体型模型并进行展示。
在具体实现中,为了提高个人体型模型的多样性以丰富目标用户的交互体验,在接收到目标用户输入的预设交互指令,根据所述预设交互指令获取所述目标用户存储在预设模型数据库中对应的个人体型模型之前,可先发出是否需要进行基于预设标准模型进行自行改动所对应的提示信息,然后接收目标用户基于所述提示信息输入的自改模指令,并在所述预设显示器显示预设标准模型,所述自改模指令即为用户不需要基于自身的个人体型数据建立个人体型模型,选择基于预设模型数据库中已存储的预设标准模型进行更改以生成个人体型模型,然后接收所述目标用户基于所述预设标准模型输入的模型修改指令,所述预设标准模型可为标准成女模型、标准成男模型、标准少女模型、标准少年模型、动物模型(如兔子、松鼠、鹿)等,基于所述模型修改指令对所述预设标准模型进行模型修改,所述模型修改可为身高修改、胖瘦修改、肤色修改、五官修改、体型细节修改(如臂围修改、腿围修改、腰围修改)等,生成个人体型模型。
在具体实现中,为了提高基于虚拟现实技术的个人体型模型的模型立体度和用户的交互体验,在对所述个人体型模型进行渲染时,可先获取所述个人体型模型的属性信息(如性别、物种、年龄等),再根据所述属性信息渲染所述个人体型模型的模型表面的光源效果和材质,还可对所述个人体型模型进行三维环境光源方向、影子处理等。进一步地,还可对经上述处理后的个人体型模型进行预设比例调整和差异处理,所述预设比例调整可为对经上述处理后的个人体型模型进行比例调整以达到符合预设成像比例规则,所述预设成像比例规则可为符合历史渲染数据库中个人体型模型所对应的比例参数,也可为符合预设比例关系映射表中个人体型模型所对应的比例系数。接着,还可根据目标用户的左右眼的成像差异,对个人体型模型在预设显示器中的显示画面进行对应的差异处理以进一步提升个人体型模型的立体度。
步骤S20:获取所述预设显示器显示的场景模型,并基于所述预设显示器实时追踪所述目标用户的位置信息和动作信息;
需要说明的是,在根据预设交互指令从预设模型数据库中获取对应的个人体型模型,并在所述目标用户佩戴的预设显示器中显示所述个人体型模型后,还可获取所述预设显示器显示的场景模型,并基于所述预设显示器实时追踪所述目标用户的位置信息和动作信息,所述位置信息和动作信息是结合起来的,用以表达目标用户的肢体移动情况,在具体实现中,可结合动作捕捉(Motion capture)技术对目标用户的肢体移动情况进行实时追踪,具体动作捕捉方式可采用机械式运动捕捉、声学式运动捕捉、电磁式运动捕捉、光学式运动捕捉、惯性导航式动作捕捉等,本实施例为了降低交互时的延迟感,提高对目标用户的位置信息和动作信息的追踪效率,也提高目标用户的交互体验,优先选择光学式运动捕捉。
在具体实现中,除了需要对目标用户的位置信息和动作信息进行实时追踪以提高目标用户的实时交互体验外,还可通过预设图像采集装置(如双目摄像机)追踪目标用户的面部表情信息,易于理解的是,上文所获取到的完整的个人体型模型中是包含目标用户的面部数据的,则此处获取到面部表情信息可在个人体型模型的面部数据的基础上进行面部表情捕捉,以提高面部表情信息的追踪效率,进一步地,也提高了用户的交互体验。
在具体实现中,为了降低运算量,也为了降低交互延迟感,提高目标用户的实时交互体验,可在仅检测到所述场景模型中存在预设反射模型时,实时追踪所述目标用户的面部表情信息,所述预设反射模型,即设置有反射功能(能实时显示目标用户的个人体型模型)的模型,如水域模型,镜子模型。
步骤S30:根据所述位置信息和所述动作信息实时调整所述个人体型模型,并根据预设交互规则实时控制所述场景模型与调整后的所述个人体型模型的交互。
易于理解的是,在获得所述位置信息和所述动作信息后,可根据所述动作信息和所述位置信息实时调整所述个人体型模型,并根据预设交互规则实时控制调整后的个人体型模型与所述场景模型的交互,所述预设交互规则可为在获得所述场景模型的场景种类后,根据所述场景种类确定所述场景模型对应的压力反馈值,然后根据所述压力反馈值实时控制与个人体型模型的交互,所述压力反馈值可理解为场景模型在与个人体型模型交互后产生的形变所对应的模型调控参数,如弯曲度、压缩度等,然后根据所述压力反馈值控制所述场景模型的形变,相应地,也可根据场景模型的形变控制个人体型模型的形变,更具体的关于上述交互方式的说明可参见本发明基于虚拟现实的实时交互方法第二实施例,本实施例在此不予赘述。
在具体实现中,如上文所述的在检测到所述场景模型中存在预设反射模型时,实时追踪所述目标用户的面部表情信息后,为了丰富目标用户的实时交互体验,提高实时交互的沉浸感,相应地,可根据位置信息、动作信息以及面部表情信息实时调整个人体型模型,并根据预设交互规则实时控制调整后的所述个人体型模型与所述场景模型的交互,如,在镜子模型中实时显示当前的个人体型模型(包括当前面部表情)。
本实施例在接收到目标用户输入的预设交互指令时,根据所述预设交互指令从预设模型数据库中获取对应的个人体型模型,并在所述目标用户佩戴的预设显示器中显示所述个人体型模型,获取所述预设显示器显示的场景模型,并基于所述预设显示器实时追踪所述目标用户的位置信息和动作信息,根据所述位置信息和所述动作信息实时调整所述个人体型模型,并根据预设交互规则实时控制所述场景模型与调整后的所述个人体型模型的交互。通过根据目标用户输入的预设交互指令获取对应的个人体型模型而不是直接获取预设的模型进行后续交互,以提高目标用户的参与感和沉浸感,通过实时追踪目标用户的位置信息和动作信息,并根据所述位置信息和所述动作信息实时调整所述个人体型模型以实现实时根据目标用户的自身运动情况控制个人体型模型的运动,提高目标用户的实时交互体验,通过根据预设交互规则实时控制调整后的所述个人体型模型与所述场景模型的交互以实现实时与所见场景的交互,提高目标用户的沉浸感。
参考图3,图3为本发明基于虚拟现实的实时交互方法第二实施例的流程示意图。
基于上述第一实施例,在本实施例中,所述步骤S10之前,还包括:
步骤S00:扫描目标用户的个人体型数据,并基于所述个人体型数据建立初阶几何模型;
易于理解的是,为了提高个人体型模型的建模效率和建模精度,在扫描获得目标用户的个人体型数据后,可对获得个人体型数据进行聚类分析,获得边缘位置信息和特征位置信息,然后基于所述边缘位置信息和所述特征位置信息进行贴图绘制,获得初阶几何模型。
步骤S01:基于所述初阶几何模型建立个人骨架模型,并基于所述个人骨架模型建立用于交互的第一交互层和用于防穿模的第二交互层;
步骤S02:基于所述第一交互层、所述第二交互层以及所述个人骨架模型生成个人体型模型。
需要说明的是,在获得所述初阶几何模型后,为了提高个人体型模型的立体度,也为了提高个人体型模型运动时的真实感,可基于所述初阶几何模型建立个人骨架模型,即个人体型模型的“绑骨”,然后基于所述个人骨架模型建立用于交互的第一交互层和用于防穿模的第二交互层,所述第一交互层可理解为个人体型模型的“皮肤层”,在与场景模型进行交互时会对应的发生形变,所述第二交互层,可理解为个人体型模型的“阻挡层”,在与所述场景模型进行交互时,形变只会影响到第一交互层,第二交互是设置为拒绝进行模型交互的,以避免产生场景模型穿透至“阻挡层”的现象,即“穿模”现象。然后,基于所述第一交互层、所述第二交互层以及所述个人骨架模型生成初阶体型模型。在具体实现中,为了减少运算量,提高系统响应速度,降低延迟率,可将个人骨架模型、用于防穿模的第二交互层以及用于交互的第一交互层进行融合,获得初阶体型模型,但在所述初阶体型模型中会保留各自对应的功能,可理解为初阶体型模型由内到外依次是个人骨架模型、用于防穿模的第二交互层、用于交互的第一交互层。
在具体实现中,还可对获得的初阶体型模型进行预设细化处理,获得个人体型模型,以提高所述个人体型模型的精度和目标用户的观感,进一步地,也提高了目标用户通过个人体型模型进行交互时的交互体验,所述预设细化处理可为获取所述初阶体型模型对应的三维坐标,并校验所述三维坐标的坐标精度,直至所述坐标精度大于预设坐标精度,所述预设坐标精度可基于历史校验精度确定,也可根据目标用户的指令进行校验,如在校验坐标精度到符合历史校验精度后,发出预设提示信息用以提示目标用户是否需要继续进行细化处理,若用户选择“是”对应的指令,则继续进行预设细化处理,若用户选择“否”对应的指令,则停止当前的预设细化处理,并输出当前的初阶体型模型,作为个人体型模型。在具体实现中,除通过坐标校验来提高所述初阶体型模型的模型精度外,还可通过平滑滤波技术(如,通过高斯滤波器进行平滑滤波,通过中值滤波器进行平滑滤波等)滤掉所述初阶体型模型中不符合预设光滑标准的过渡区域来避免初阶体型模型发生形变而产生的不平整现象,所述预设光滑标准可根据历史光滑标准确定,也可根据用户需求进行设置,本实施例在此不加以限制。进一步地,在根据所述预设交互指令从预设模型数据库中获得对应的个人体型模型后,可在所述目标用户佩戴的预设显示器中实时渲染所述个人体型模型并进行展示。
在具体实现中,为了提高基于虚拟现实技术的个人体型模型的模型立体度和用户的交互体验,在对所述个人体型模型进行渲染时,可先获取所述个人体型模型的属性信息(如性别、物种、年龄等),再根据所述属性信息渲染所述个人体型模型的模型表面的光源效果和材质,还可对所述个人体型模型进行三维环境光源方向、影子处理等。进一步地,还可对经上述处理后的个人体型模型进行预设比例调整和差异处理,所述预设比例调整可为对经上述处理后的个人体型模型进行比例调整以达到符合预设成像比例规则,所述预设成像比例规则可为符合历史渲染数据库中个人体型模型所对应的比例参数,也可为符合预设比例关系映射表中个人体型模型所对应的比例系数。接着,还可根据目标用户的左右眼的成像差异,对个人体型模型在预设显示器中的显示画面进行对应的差异处理以进一步提升个人体型模型的立体度。
相应地,所述步骤S30可具体包括以下步骤:
步骤S301:根据所述位置信息和所述动作信息实时调整所述个人体型模型;
步骤S302:获取所述场景模型的场景基础层,计算所述场景基础层与调整后的所述个人体型模型的第二交互层之间的相对距离;
步骤S303:获取所述场景模型的场景种类,根据所述场景种类获取所述场景模型的压力反馈值;
步骤S304:根据所述压力反馈值和所述相对距离实时控制调整后的所述个人体型模型的第一交互层与所述场景模型的交互。
需要说明的是,在获得目标用户的位置信息和所述动作信息后,可根据所述动作信息和所述位置信息实时调整所述个人体型模型,并获取所述场景模型的场景基础层,计算所述场景基础层与调整后的所述个人体型模型的第二交互层之间的相对距离,所述场景基础层与上述个人体型模型中的第一交互层和第二相互层类似,可理解为第一交互层和第二交互层的结合,即场景基础层有用于在与个人体型模型进行交互时会对应的发生形变的功能,也有在与所述个人体型模型进行交互时,拒绝进行模型交互的功能,以避免产生个人体型模型穿透至场景模型的现象,在具体实现中,可计算所述场景基础层与调整后的所述个人体型模型的第二交互层之间的相对距离,在所述相对距离大于预设距离时,则拒绝与所述个人体型模型交互,同时二者维持当前的形变状态直至个人体型模型再次发生运动,在具体实现中,还可获取所述场景模型的场景种类,并根据所述场景种类确定所述场景模型对应的压力反馈值,然后根据所述压力反馈值实时控制与个人体型模型的交互,所述压力反馈值可理解为场景模型在与个人体型模型交互后产生的形变所对应的模型调控参数,如弯曲度、压缩度等,然后根据所述压力反馈值控制所述场景模型的形变。通过根据所述位置信息和所述动作信息实时调整所述个人体型模型以实现实时根据目标用户的自身运动情况控制个人体型模型的运动,提高目标用户的实时交互体验,并通过根据场景模型的场景基础层与调整后的所述个人体型模型的第二交互层之间的相对距离、场景模型对应的压力反馈值实时控制调整后的所述个人体型模型的第一交互层与所述场景模型的交互以实现自然模拟模型交互时产生的形变,提高实时交互的真实感和沉浸感。
本实施例扫描目标用户的个人体型数据,并基于所述个人体型数据建立初阶几何模型,基于所述初阶几何模型建立个人骨架模型,并基于所述个人骨架模型建立用于交互的第一交互层和用于防穿模的第二交互层,基于所述第一交互层、所述第二交互层以及所述个人骨架模型生成个人体型模型。根据目标用户的位置信息和动作信息实时调整所述个人体型模型,获取场景模型的场景基础层,计算所述场景基础层与调整后的所述个人体型模型的第二交互层之间的相对距离,获取所述场景模型的场景种类,根据所述场景种类获取所述场景模型的压力反馈值,根据所述压力反馈值和所述相对距离实时控制调整后的所述个人体型模型的第一交互层与所述场景模型的交互。通过根据目标用户的位置信息和动作信息实时调整所述个人体型模型以实现实时根据目标用户的自身运动情况控制个人体型模型的运动,提高目标用户的实时交互体验,并通过根据场景模型的场景基础层与调整后的所述个人体型模型的第二交互层之间的相对距离、场景模型对应的压力反馈值实时控制调整后的所述个人体型模型的第一交互层与所述场景模型的交互以实现自然模拟模型交互时产生的形变,进一步提高实时交互的真实感和沉浸感。
此外,本发明实施例还提出一种存储介质,所述存储介质上存储有基于虚拟现实的实时交互程序,所述基于虚拟现实的实时交互程序被处理器执行时实现如上文所述的基于虚拟现实的实时交互方法的步骤。
参照图4,图4为本发明基于虚拟现实的实时交互装置第一实施例的结构框图。
如图4所示,本发明实施例提出的基于虚拟现实的实时交互装置包括:
模型获取模块10,用于在接收到目标用户输入的预设交互指令时,根据所述预设交互指令从预设模型数据库中获取对应的个人体型模型,并在所述目标用户佩戴的预设显示器中显示所述个人体型模型;
易于理解的是,在接收到目标用户输入的预设交互指令时,可根据所述预设交互指令从预设模型数据库中获取对应的个人体型模型,所述预设交互指令主要用来判断交互种类,所述交互种类可为以第一视角交互、以第三视角交互等,所谓以第一视角交互,即只显示个人体型模型中手部区域(也可包含预设长度的手臂区域,所述预设长度可根据实际需求而定,在具体实现中,若目标用户未对预设长度进行设置,可直接根据预设模型数据库中目标用户设定次数最多的目标预设长度作为默认的预设长度)对应的手部模型,然后通过手部模型与场景模型进行实时交互;所谓以第三视角进行交互,即显示目标用户对应的完整的个人体型模型(可理解为从头到脚的人物模型),然后通过个人人体模型与场景模型进行实时交互。
相应地,在接收到目标用户输入的预设交互指令时,可获取所述预设交互指令的指令类型,所述指令类型可分为第一视角交互指令和第三视角交互指令,所谓第一视角交互指令即基于上述以第一视角交互的交互种类确定的指令类型,所述第三视角交互指令即基于上述以第一视角交互的交互种类确定的指令类型。然后,根据确定的指令类型从预设模型数据库中获取对应的个人体型模型,若所述指令种类为第三视角交互指令,则根据所述预设交互指令从预设模型数据库中获取对应的个人体型模型;若所述指令种类为第一视角交互指令,则根据所述预设交互指令从预设模型数据库中获取对应的个人手部模型,再对所述个人手部模型进行预设细化处理,获得目标手部模型,并将所述目标手部模型作为所述个人体型模型,所述预设细化处理可为获取所述个人手部模型对应的三维坐标,并校验所述三维坐标的坐标精度,直至所述坐标精度大于预设坐标精度,所述预设坐标精度可基于历史校验精度确定,也可根据目标用户的指令进行校验,如在校验坐标精度到符合历史校验精度后,发出预设提示信息用以提示目标用户是否需要继续进行细化处理,若用户选择“是”对应的指令,则继续进行预设细化处理,若用户选择“否”对应的指令,则停止当前的预设细化处理,并输出当前的手部模型,作为个人体型模型。在具体实现中,除通过坐标校验来提高所述手部模型的模型精度外,还可通过平滑滤波技术(如,通过高斯滤波器进行平滑滤波,通过中值滤波器进行平滑滤波等)滤掉所述手部模型中不符合预设光滑标准的过渡区域来避免手部模型发生形变而产生的不平整现象,所述预设光滑标准可根据历史光滑标准确定,也可根据用户需求进行设置,本实施例在此不加以限制。高精度的手部模型的获得,提高了第一视角下目标用户的观感,也提高后续基于所述手部模型进行交互时的交互体验和沉浸感。进一步地,在根据所述预设交互指令从预设模型数据库中获得对应的个人体型模型后,可在所述目标用户佩戴的预设显示器中实时渲染所述个人体型模型并进行展示。
在具体实现中,为了提高个人体型模型的多样性以丰富目标用户的交互体验,在接收到目标用户输入的预设交互指令,根据所述预设交互指令获取所述目标用户存储在预设模型数据库中对应的个人体型模型之前,可先发出是否需要进行基于预设标准模型进行自行改动所对应的提示信息,然后接收目标用户基于所述提示信息输入的自改模指令,并在所述预设显示器显示预设标准模型,所述自改模指令即为用户不需要基于自身的个人体型数据建立个人体型模型,选择基于预设模型数据库中已存储的预设标准模型进行更改以生成个人体型模型,然后接收所述目标用户基于所述预设标准模型输入的模型修改指令,所述预设标准模型可为标准成女模型、标准成男模型、标准少女模型、标准少年模型、动物模型(如兔子、松鼠、鹿)等,基于所述模型修改指令对所述预设标准模型进行模型修改,所述模型修改可为身高修改、胖瘦修改、肤色修改、五官修改、体型细节修改(如臂围修改、腿围修改、腰围修改)等,生成个人体型模型。
在具体实现中,为了提高基于虚拟现实技术的个人体型模型的模型立体度和用户的交互体验,在对所述个人体型模型进行渲染时,可先获取所述个人体型模型的属性信息(如性别、物种、年龄等),再根据所述属性信息渲染所述个人体型模型的模型表面的光源效果和材质,还可对所述个人体型模型进行三维环境光源方向、影子处理等。进一步地,还可对经上述处理后的个人体型模型进行预设比例调整和差异处理,所述预设比例调整可为对经上述处理后的个人体型模型进行比例调整以达到符合预设成像比例规则,所述预设成像比例规则可为符合历史渲染数据库中个人体型模型所对应的比例参数,也可为符合预设比例关系映射表中个人体型模型所对应的比例系数。接着,还可根据目标用户的左右眼的成像差异,对个人体型模型在预设显示器中的显示画面进行对应的差异处理以进一步提升个人体型模型的立体度。
实时追踪模块20,用于获取所述预设显示器显示的场景模型,并基于所述预设显示器实时追踪所述目标用户的位置信息和动作信息;
需要说明的是,在根据预设交互指令从预设模型数据库中获取对应的个人体型模型,并在所述目标用户佩戴的预设显示器中显示所述个人体型模型后,还可获取所述预设显示器显示的场景模型,并基于所述预设显示器实时追踪所述目标用户的位置信息和动作信息,所述位置信息和动作信息是结合起来的,用以表达目标用户的肢体移动情况,在具体实现中,可结合动作捕捉(Motion capture)技术对目标用户的肢体移动情况进行实时追踪,具体动作捕捉方式可采用机械式运动捕捉、声学式运动捕捉、电磁式运动捕捉、光学式运动捕捉、惯性导航式动作捕捉等,本实施例为了降低交互时的延迟感,提高对目标用户的位置信息和动作信息的追踪效率,也提高目标用户的交互体验,优先选择光学式运动捕捉。
在具体实现中,除了需要对目标用户的位置信息和动作信息进行实时追踪以提高目标用户的实时交互体验外,还可通过预设图像采集装置(如双目摄像机)追踪目标用户的面部表情信息,易于理解的是,上文所获取到的完整的个人体型模型中是包含目标用户的面部数据的,则此处获取到面部表情信息可在个人体型模型的面部数据的基础上进行面部表情捕捉,以提高面部表情信息的追踪效率,进一步地,也提高了用户的交互体验。
在具体实现中,为了降低运算量,也为了降低交互延迟感,提高目标用户的实时交互体验,可在仅检测到所述场景模型中存在预设反射模型时,实时追踪所述目标用户的面部表情信息,所述预设反射模型,即设置有反射功能(能实时显示目标用户的个人体型模型)的模型,如水域模型,镜子模型。
交互控制模块30,用于根据所述位置信息和所述动作信息实时调整所述个人体型模型,并根据预设交互规则实时控制调整后的所述个人体型模型与所述场景模型的交互。
易于理解的是,在获得所述位置信息和所述动作信息后,可根据所述动作信息和所述位置信息实时调整所述个人体型模型,并根据预设交互规则实时控制调整后的个人体型模型与所述场景模型的交互,所述预设交互规则可为在获得所述场景模型的场景种类后,根据所述场景种类确定所述场景模型对应的压力反馈值,然后根据所述压力反馈值实时控制与个人体型模型的交互,所述压力反馈值可理解为场景模型在与个人体型模型交互后产生的形变所对应的模型调控参数,如弯曲度、压缩度等,然后根据所述压力反馈值控制所述场景模型的形变,相应地,也可根据场景模型的形变控制个人体型模型的形变。
在具体实现中,如上文所述的在检测到所述场景模型中存在预设反射模型时,实时追踪所述目标用户的面部表情信息后,为了丰富目标用户的实时交互体验,提高实时交互的沉浸感,相应地,可根据位置信息、动作信息以及面部表情信息实时调整个人体型模型,并根据预设交互规则实时控制调整后的所述个人体型模型与所述场景模型的交互,如,在镜子模型中实时显示当前的个人体型模型(包括当前面部表情)。
本实施例在接收到目标用户输入的预设交互指令时,根据所述预设交互指令从预设模型数据库中获取对应的个人体型模型,并在所述目标用户佩戴的预设显示器中显示所述个人体型模型,获取所述预设显示器显示的场景模型,并基于所述预设显示器实时追踪所述目标用户的位置信息和动作信息,根据所述位置信息和所述动作信息实时调整所述个人体型模型,并根据预设交互规则实时控制调整后的所述个人体型模型与所述场景模型的交互。通过根据目标用户输入的预设交互指令获取对应的个人体型模型而不是直接获取预设的模型进行后续交互,以提高目标用户的参与感和沉浸感,通过实时追踪目标用户的位置信息和动作信息,并根据所述位置信息和所述动作信息实时调整所述个人体型模型以实现实时根据目标用户的自身运动情况控制个人体型模型的运动,提高目标用户的实时交互体验,通过根据预设交互规则实时控制调整后的所述个人体型模型与所述场景模型的交互以实现实时与所见场景的交互,提高目标用户的沉浸感。
基于本发明上述基于虚拟现实的实时交互装置第一实施例,提出本发明基于虚拟现实的实时交互装置的第二实施例。
在本实施例中,所述模型获取模块10,还用于扫描目标用户的个人体型数据,并基于所述个人体型数据建立初阶几何模型;
所述模型获取模块10,还用于基于所述初阶几何模型建立个人骨架模型,并基于所述个人骨架模型建立用于交互的第一交互层和用于防穿模的第二交互层;
所述模型获取模块10,还用于基于所述第一交互层、所述第二交互层以及所述个人骨架模型生成个人体型模型。
需要说明的是,在获得所述初阶几何模型后,为了提高个人体型模型的立体度,也为了提高个人体型模型运动时的真实感,可基于所述初阶几何模型建立个人骨架模型,即个人体型模型的“绑骨”,然后基于所述个人骨架模型建立用于交互的第一交互层和用于防穿模的第二交互层,所述第一交互层可理解为个人体型模型的“皮肤层”,在与场景模型进行交互时会对应的发生形变,所述第二交互层,可理解为个人体型模型的“阻挡层”,在与所述场景模型进行交互时,形变只会影响到第一交互层,第二交互是设置为拒绝进行模型交互的,以避免产生场景模型穿透至“阻挡层”的现象,即“穿模”现象。然后,基于所述第一交互层、所述第二交互层以及所述个人骨架模型生成初阶体型模型。在具体实现中,为了减少运算量,提高系统响应速度,降低延迟率,可将个人骨架模型、用于防穿模的第二交互层以及用于交互的第一交互层进行融合,获得初阶体型模型,但在所述初阶体型模型中会保留各自对应的功能,可理解为初阶体型模型由内到外依次是个人骨架模型、用于防穿模的第二交互层、用于交互的第一交互层。
在具体实现中,还可对获得的初阶体型模型进行预设细化处理,获得个人体型模型,以提高所述个人体型模型的精度和目标用户的观感,进一步地,也提高了目标用户通过个人体型模型进行交互时的交互体验,所述预设细化处理可为获取所述初阶体型模型对应的三维坐标,并校验所述三维坐标的坐标精度,直至所述坐标精度大于预设坐标精度,所述预设坐标精度可基于历史校验精度确定,也可根据目标用户的指令进行校验,如在校验坐标精度到符合历史校验精度后,发出预设提示信息用以提示目标用户是否需要继续进行细化处理,若用户选择“是”对应的指令,则继续进行预设细化处理,若用户选择“否”对应的指令,则停止当前的预设细化处理,并输出当前的初阶体型模型,作为个人体型模型。在具体实现中,除通过坐标校验来提高所述初阶体型模型的模型精度外,还可通过平滑滤波技术(如,通过高斯滤波器进行平滑滤波,通过中值滤波器进行平滑滤波等)滤掉所述初阶体型模型中不符合预设光滑标准的过渡区域来避免初阶体型模型发生形变而产生的不平整现象,所述预设光滑标准可根据历史光滑标准确定,也可根据用户需求进行设置,本实施例在此不加以限制。进一步地,在根据所述预设交互指令从预设模型数据库中获得对应的个人体型模型后,可在所述目标用户佩戴的预设显示器中实时渲染所述个人体型模型并进行展示。
在具体实现中,为了提高基于虚拟现实技术的个人体型模型的模型立体度和用户的交互体验,在对所述个人体型模型进行渲染时,可先获取所述个人体型模型的属性信息(如性别、物种、年龄等),再根据所述属性信息渲染所述个人体型模型的模型表面的光源效果和材质,还可对所述个人体型模型进行三维环境光源方向、影子处理等。进一步地,还可对经上述处理后的个人体型模型进行预设比例调整和差异处理,所述预设比例调整可为对经上述处理后的个人体型模型进行比例调整以达到符合预设成像比例规则,所述预设成像比例规则可为符合历史渲染数据库中个人体型模型所对应的比例参数,也可为符合预设比例关系映射表中个人体型模型所对应的比例系数。接着,还可根据目标用户的左右眼的成像差异,对个人体型模型在预设显示器中的显示画面进行对应的差异处理以进一步提升个人体型模型的立体度。
所述交互控制模块30,还用于根据所述位置信息和所述动作信息实时调整所述个人体型模型;
所述交互控制模块30,还用于获取所述场景模型的场景基础层,计算所述场景基础层与调整后的所述个人体型模型的第二交互层之间的相对距离;
所述交互控制模块,还用于获取所述场景模型的场景种类,根据所述场景种类获取所述场景模型的压力反馈值;
所述交互控制模块30,还用于根据所述压力反馈值和所述相对距离实时控制调整后的所述个人体型模型的第一交互层与所述场景模型的交互。
需要说明的是,在获得目标用户的位置信息和所述动作信息后,可根据所述动作信息和所述位置信息实时调整所述个人体型模型,然后获取所述场景模型的场景基础层,计算所述场景基础层与调整后的所述个人体型模型的第二交互层之间的相对距离,所述场景基础层与上述个人体型模型中的第一交互层和第二相互层类似,可理解为第一交互层和第二交互层的结合,即场景基础层有用于在与个人体型模型进行交互时会对应的发生形变的功能,也有在与所述个人体型模型进行交互时,拒绝进行模型交互的功能,以避免产生个人体型模型穿透至场景模型的现象,在具体实现中,可计算所述场景基础层与调整后的所述个人体型模型的第二交互层之间的相对距离,在所述相对距离大于预设距离时,则拒绝与所述个人体型模型交互,同时二者维持当前的形变状态直至个人体型模型再次发生运动,在具体实现中,还可获取所述场景模型的场景种类,并根据所述场景种类确定所述场景模型对应的压力反馈值,然后根据所述压力反馈值实时控制与个人体型模型的交互,所述压力反馈值可理解为场景模型在与个人体型模型交互后产生的形变所对应的模型调控参数,如弯曲度、压缩度等,然后根据所述压力反馈值控制所述场景模型的形变。通过根据所述位置信息和所述动作信息实时调整所述个人体型模型以实现实时根据目标用户的自身运动情况控制个人体型模型的运动,提高目标用户的实时交互体验,并通过根据场景模型的场景基础层与调整后的所述个人体型模型的第二交互层之间的相对距离、场景模型对应的压力反馈值实时控制调整后的所述个人体型模型的第一交互层与所述场景模型的交互以实现自然模拟模型交互时产生的形变,提高实时交互的真实感和沉浸感。
所述模型获取模块10,还用于在接收到目标用户输入的预设交互指令时,获取所述预设交互指令的指令类型;
所述模型获取模块10,还用于在所述指令类型为第三视角交互指令时,根据所述预设交互指令从预设模型数据库中获取对应的个人体型模型。
所述实时追踪模块20,还用于获取所述预设显示器显示的场景模型,并基于所述预设显示器实时追踪所述目标用户的位置信息和动作信息;
所述实时追踪模块20,还用于在检测到所述场景模型中存在预设反射模型时,实时追踪所述目标用户的面部表情信息;
所述交互控制模块30,还用于根据所述位置信息、所述动作信息以及所述面部表情信息实时调整所述个人体型模型,并根据预设交互规则实时控制所述场景模型与调整后的所述个人体型模型的交互。
所述模型获取模块10,还用于在所述指令类型为第一视角交互指令时,根据所述预设交互指令从预设模型数据库中获取对应的个人手部模型;
所述模型获取模块10,还用于对所述个人手部模型进行预设细化处理,获得目标手部模型,并将所述目标手部模型作为所述个人体型模型。
所述模型获取模块10,还用于在接收到目标用户输入的自改模指令时,在所述预设显示器显示预设标准模型;
所述模型获取模块10,还用于接收所述目标用户基于所述预设标准模型输入的模型修改指令,基于所述模型修改指令对所述预设标准模型进行修改,生成个人体型模型。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者系统中还存在另外的相同要素。
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如只读存储器/随机存取存储器、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,空调器,或者网络设备等)执行本发明各个实施例所述的方法。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 基于虚拟现实的实时交互方法、装置、设备及存储介质
- 基于全息成像的实时交互方法、装置、设备及存储介质