一种基于Transformer-ESIM注意力机制的多模态情绪识别方法
文献发布时间:2023-06-19 10:32:14
技术领域
本发明涉及模式识别与人工智能技术领域,尤其涉及一种基于Transformer-ESIM注意力机制的多模态情绪识别方法。
背景技术
随着人工智能领域的迅速发展以及深度学习的助力,人机交互领域受到越来越多研究学者的重视。而情绪识别作为人机交互中一个重要的分支,也成为了当前的热点研究方向。目前,对情绪识别的研究大多集中在语音、面部表情、文本等单模态领域。语音作为人们交流最直接的手段,其中涵盖了丰富的情绪信息,人们情绪的变化可以通过语音特征体现出来。语音情绪识别正是将输入包含情绪信息的语音信号转化为可读的物理特征,并提取其中与情绪表达相关的语音特征,再构建情绪识别分类器进行测试和训练,最后输出情绪识别分类结果。然而,单一语音模态的情绪识别易受外界因素影响缺失一些情感信息,如噪音、信号强弱等,导致语音情绪识别的效果不够显著。鉴于不同模态间存在互补性,可将文本模态和语音模态进行融合改善单一语音模态情绪识别的缺陷,从而提高情绪识别准确率。
为了利用来自语音信号和文本序列的信息,Jin等人从声学和词汇两个层面生成特征表示,并构建情绪识别系统。Sahay等人提出了一种利用段内模态间相互作用的关系张量网络结构,利用更丰富的语音和文本上下文信息生成文本和语音模态的丰富表示。Akhtar等人提出了一个同时预测话语情绪和情绪表达的语境跨模态注意框架,将注意力集中在对相邻话语和多模态表征的贡献上,有助于网络更好的学习。此外,Gamage等人提出了使用音素序列来编码与情绪表达相关的语言线索,将文本信息与语音特征相结合,从而提高情绪识别的准确率。虽然基于语音和文本的多模态情绪识别方法已取得了不错的成果,然而在传统端到端的神经网络中,由于提取情感信息特征时易受模型固有的顺序特性限制,导致无法获取整个语句序列前后间的相关特征信息。因此,多模态情绪识别的分类准确率仍有待提高。
发明内容
本发明的目的在于提供一种基于Transformer-ESIM注意力机制的多模态情绪识别方法,旨在解决传统循环神经网络在序列特征提取时存在长期依赖性,其自身顺序属性无法捕获长距离特征的问题以及多模态特征直接融合而忽视的模态间交互的问题。
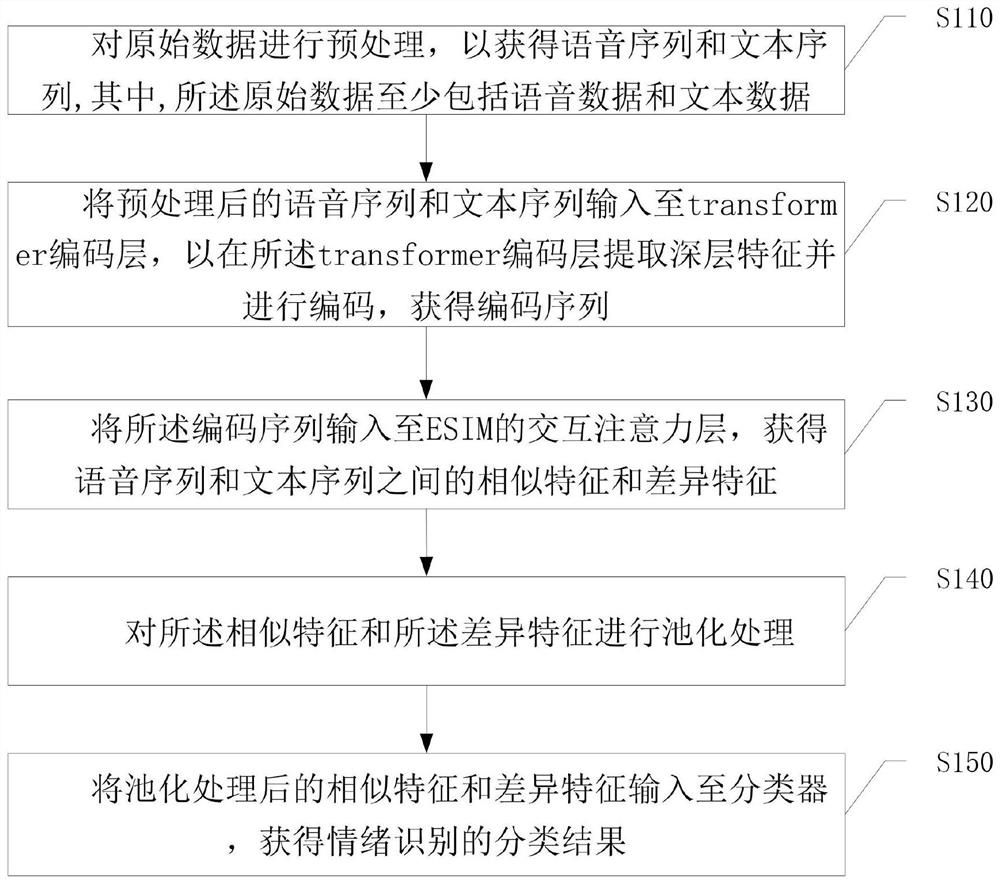
为了实现上述目的,本发明提供一种基于Transformer-ESIM注意力机制的多模态情绪识别方法,包括:
对原始数据进行预处理,以获得语音序列和文本序列,其中,所述原始数据至少包括语音数据和文本数据;
将预处理后的语音序列和文本序列输入至transformer编码层,以在所述transformer编码层提取深层特征并进行编码,获得编码序列;
将所述编码序列输入至ESIM的交互注意力层,获得语音序列和文本序列之间的相似特征和差异特征;
对所述相似特征和所述差异特征进行池化处理;
将池化处理后的相似特征和差异特征输入至分类器,获得情绪识别的分类结果。
一种实现方式中,所述将预处理后的语音序列和文本序列输入至transformer编码层,以在所述transformer编码层提取深层特征并进行编码,获得编码序列的步骤包括:
使用transformer编码层对预处理后的语音序列和文本序列进行并行化特征处理;
基于所述特征化的处理结果进行深层情感语义编码,获得编码序列。
可选的,所述将所述编码序列输入至ESIM的交互注意力层,获得语音序列和文本序列数据之间的相似特征和差异特征的步骤包括:
根据语音序列和文本序列的相似度矩阵,提取文本词中的相似信息和语音帧的相似信息;
基于所述文本词中的相似信息和所述语音帧的相似信息,计算语音序列和文本序列之间的差异特征。
一种实现方式中,所述计算语音序列与文本序列之间的相似度矩阵所采用的具体公式为:
其中,其中,i表示语音序列中的第i个标记,j表示文本序列中的第j个标记,
可选的,所述语音序列和所述文本序列之间的差异特征的表达式为:
其中,m
一种实现方式中,所述对所述相似特征和所述差异特征进行池化处理的步骤包括:
对增强后的语音信息和文本信息进行池化;
对所述语音序列和所述文本序列进行平均池化和最大池化操作;
将池化操作后的结果放入定长向量中。
应用本发明实施例提供的一种基于Transformer-ESIM注意力机制的多模态情绪识别方法,具备的有益效果如下:
(1)在对语音和文本特征进行特征提取时,借助transformer编码层的多头注意力机制,可以解决传统神经网络的长期依赖性,其自身顺序属性无法捕获长距离特征等问题,同时缩短了提取时间。
(2)考虑到语音和文本模态间的交互作用,设计了基于ESIM的交互注意力机制获取语音和文本的相似特征,实现语音和文本模态在时域上的对齐,解决了多模态特征直接融合而忽视的模态间交互问题,提高了模型对情感语义的理解和泛化能力。
附图说明
图1是本发明实施例一种基于Transformer-ESIM注意力机制的多模态情绪识别方法的流程示意图。
图2是本发明实施例多模态情绪识别模型整体框架图。
图3是本发明实施例transformer编码器结构图。
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。
请参阅图1-3。需要说明的是,本实施例中所提供的图示仅以示意方式说明本发明的基本构想,遂图式中仅显示与本发明中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的型态、数量及比例可为一种随意的改变,且其组件布局型态也可能更为复杂。
如图1本发明提供一种基于Transformer-ESIM注意力机制的多模态情绪识别方法,包括:
S110,对原始数据进行预处理,以获得语音序列和文本序列,其中,所述原始数据至少包括语音数据和文本数据;
需要说明的是,对于语音原始数据,由于语音情感信号中的“happy”和“excited”以及“frustration”和“sad”的频谱图接近,因此将“excited”归类到“happy”标签中,“frustration”归类到“sad”标签中,并忽略“others”标签。最后只保留“happy”“sad”“neutral”“anger”四类情感标签,作为情绪识别的分类类别。对于文本原始数据,首先对文本中的一些没有情感意义的符号文本进行预处理,去掉与情感无关的标点符号,其次对文本中的单词进行嵌入操作,将单词转换成固定长度的向量以便后续方便进行特征提取。
S120,将预处理后的语音序列和文本序列输入至transformer编码层,以在所述transformer编码层提取深层特征并进行编码,获得编码序列;
可以理解的是,由于传统神经网络RNN、CNN、LSTM、Bi-LSTM等存在长期依赖性问题,以及其自身固有顺序属性而导致无法捕获长距离特征的问题,都会导致情绪识别的分类结果准确率不高,因此本发明设计了transformer编码层对语音序列和文本序列进行编码,通过transformer编码层中的多头注意力机制对序列进行并行化提取特征,可以有效消除序列距离的限制,缩短了特征提取时间,充分提取序列内的情感语义信息,从而对语音序列和文本序列进行深层情感语义编码,解决了序列距离的限制。
具体的,transformer编码层结构如图2所示,主要由多头自注意力机制层和前馈神经网络层构成,多头自注意力机制层可使用多个查询向量
参见图2,需要进一步说明的是,首先是对数据进行预处理对于语音数据调用TensorFlow里的python_speech_feature库进行预处理,将语音转化为300*200的特征矩阵,对于本文数据先对单词做预处理,将每个单词映射到一个唯一的索引,再将文本从单词的序列转换为索引的序列,每一单词转换为200维度的向量,文本字符长度设置为固定值,当长度不一致时进行截断和pad操作;然后得到的特征矩阵传输到transformer编码层进行编码获取更深层的情绪特征(此层主要是一个多头注意力机制的过程,原理如图3),再通过交互注意力层计算得到语音和文本的相似特征以及差异特征,然后对特征进行平均池化和最大池化,将两种池化结果拼接并通过全连接层和softmax激活函数进行情绪分类识别。
主要的改进点在于将transformer的多头注意力机制与ESIM的交互注意力机制结合起来获得了语音和文本更深层的特征以及两者直接的相似特征,从而使得情绪识别准确率提高。
多头自注意力机制的计算如下:
Multihead(Q,K,V)=Concat(head
其中,Q,K,V分别代表编码器的输入向量生成的查询向量、键向量和值向量,
进一步的,通过前馈神经网络得到句子的特征向量,该步骤是是为了更好的提取特征,因为前面多头自注意力层中的输入和输出是存在依赖关系的,但在前馈层没有依赖,因此通过前馈神经网络并行计算将结果输入到下一层,前馈神经网络层计算如公式所示。在前馈神经网络层中输入和输出之间是不存在依赖关系的。前馈神经网络层的计算公式如下:
FFN(x)=max(0,ZW
其中,W
S130,将所述编码序列输入至ESIM的交互注意力层,获得语音序列和文本序列之间的相似特征和差异特征;
可以理解的是,本发明通过ESIM的交互注意力机制来处理语音序列和文本序列,通过ESIM的交互注意力层计算出语音序列和文本序列之间的相似特征,并进一步获取语音序列和文本之间的差异特征,实现语音和文本模态在时域上的对齐,解决了多模态特征直接融合而忽视的模态间交互问题,提高模型对情感语义的理解和泛化能力。ESIM交互注意力层具体的工作步骤如下:
计算语音与文本特征之间的相似度矩阵:
其中,i和j分别表示语音序列中的第i个标记以及文本序列中的第j个标记,e
再获取语音和文本之间的差异特征,计算
其中,m
S140,对所述相似特征和所述差异特征进行池化处理;
需要说明的是,对增强后的语音序列和文本序列进行池化,是为了提高模型的鲁棒性,同时对语音序列和文本序列进行平均池化和最大池化操作,最后再把结果放入一个定长向量中。
v=[v
其中,v
S150,将池化处理后的相似特征和差异特征输入至分类器,获得情绪识别的分类结果。
可以理解的是,本发明采用两层全连接层和SoftMax分类器作为四种情绪识别的分类层,如图3所示,若采用单一的全连接层往往会存在非线性问题,故本发明采用两个全连接FC1和FC2以解决可能存在的非线性问题,全连接层中选用线性的ReLU函数作为激活函数,可以有效避免梯度爆炸的问题。最后使用SoftMax函数进行最终的情绪分类预测,通过SoftMax函数为每个输出情绪的类别都赋予一个概率值,表示出每个类别输出的可能性。
其中,e
参见图3,需要进一步说明的是,transformer编码器首先是进行多头注意力机制,当输入一个语音/文本序列进去,首先经过线性变化生成Q、K、V三个权重向量,为所有输入共享。然后进行分头操作,对每个头进行自注意力机制操作,再将完成自注意力机制的每个头进行拼接,经过层归一化再输入到前馈神经网络,因为前面多头自注意力层中的输入和输出是存在依赖关系的,但在前馈层没有依赖,因此通过前馈神经网络并行计算将结果输入到下一层,可以更好的提取情感特征。
需要说明的是,在模型的训练过程中,本发明选取交叉熵作为损失函数,交叉熵表示出模型实际预测类别的概率与期望模型预测类别的概率间的差距,交叉熵的值越小,两个类别预测概率分布就越接近。损失函数的计算公式如下:
其中,y
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
- 一种基于Transformer-ESIM注意力机制的多模态情绪识别方法
- 一种基于注意力机制的脑电情绪识别方法