一种基于Xgboost的轧机多目标振动预测方法
文献发布时间:2023-06-19 10:38:35
技术领域
本发明涉及一种基于Xgboost的轧机多目标振动预测方法,它属于轧机振动预测技术领域。
背景技术
轧机振动是反映轧机设备工作状态的重要指标,轧机振动会影响生产效率并影响产品质量,运行时振动不仅会造成轧辊、轧件表面出现振痕。还会造成板带厚度波动,限制轧制的速度,进而导致生产效率下降,甚至出现断钢停产等安全事故。随着轧机设备向自动化、智能化方向快速发展,对设备振动要求更加严格,对轧机振动的预测就显得尤为重要,现有的振动预测方法都是单目标预测,预测范围窄,无法实现多目标振动预测。
发明内容
本发明的目的是解决现有的振动预测方法存在的作用预测范围窄和无法实现多目标振动预测的技术问题,提供一种基于Xgboost的轧机多目标振动预测方法。
为解决上述技术问题,本发明采用的技术方案是:
一种基于Xgboost的轧机多目标振动预测方法,其包括如下步骤:
步骤1:将从轧机现场实测到的工艺参数和振动数据进行拼接,组成完整的数据集;再将数据导入Jupyter中,查看数据是否有缺失值和异常值;若有缺失值,采用均值填充法填充缺失值;若有异常值直接删除;最后将数据标准化;
步骤2:对标准化后的数据进行聚类、降维处理,选取数据特征;
步骤3:将选取的数据特征进行训练集、测试集划分,70%为训练集,30%为测试集;
步骤4:设置Xgboost模型及参数,设置精度要求;
步骤5:将训练集数据导入Xgboost模型进行训练,查看预测精度;若预测精度达到设置精度要求,则进行下一步骤,否则绘制学习曲线,重新确定Xgboost模型参数,重新训练Xgboost模型;
步骤6:将测试集数据导入满足精度要求的Xgboost模型,得出预测值,调用Xgboost模型Score接口查看预测准确率,用matplotlib绘制预测结果图像并与测试集真实值进行对比。
进一步地,所述步骤1中的工艺参数采用PDA进行记录提取;所述振动数据为在轧机设备工作辊、上支撑辊和下支承辊位置布置传感器采集的工作辊、上支撑辊和下支承辊的振动数据,使用东华动态信号采集分析系统将轧机工艺参数、振动数据导出为CSV文件。
进一步地,所述步骤1中的数据标准化为采用如下公式对数据进行标准化处理,
式中:μ为均值,σ为标准差,x
进一步地,所述步骤1中的均值填充法为调用Sklearn中的impute.Simplelmputer模块,模块中的strategy参数代表填补缺失值策略,默认为均值;所述步骤1中的异常值直接删除为使用impute.Simplelmputer中的drop函数,直接将异常值删除。
进一步地,所述步骤2中的对标准化后的数据进行聚类、降维处理为调用sklearn中的聚类、降维算法,对数据进行聚类、降维处理,最终选取6个轧机工艺参数即轧制力、轧制速度、入口厚度、出口厚度,前张力和后张力为输入特征,选取3个轧机振动即工作辊、上支撑辊和下支撑辊振动为输出特征。
进一步地,所述步骤3中的将提取的特征数据进行训练集、测试集划分是指:调用sklearn中的model_selection模块中的train_test_split函数,随机将特征数据的70%划分为训练集,30%划分测试集。
进一步地,所述步骤4中的参数为Xgboost模型默认参数即learning_rate=0.1,n_estimators=500,max_depth=5,min_child_weight=1,gamma=0,subsample=0.8,reg_alpha=0,reg_lambda=1;所述精度要求为90%以上。
进一步地,所述步骤5中的绘制学习曲线为在Jupyter中,绘制Xgboost模型主要参数学习曲线,学习曲线的最佳参数为learning_rate=0.1,n_estimators=4000,max_depth=4,min_child_weight=1,gamma=0,subsample=0.8,reg_alpha=0,reg_lambda=1。
本发明的有益效果是:
本发明采用上述技术方案,解决了现有的振动预测方法存在的作用预测范围窄和无法实现多目标振动预测的技术问题。与背景技术相比,本发明具有能够实现多目标振动预测和能够获得较好的预测性能等优点。
附图说明
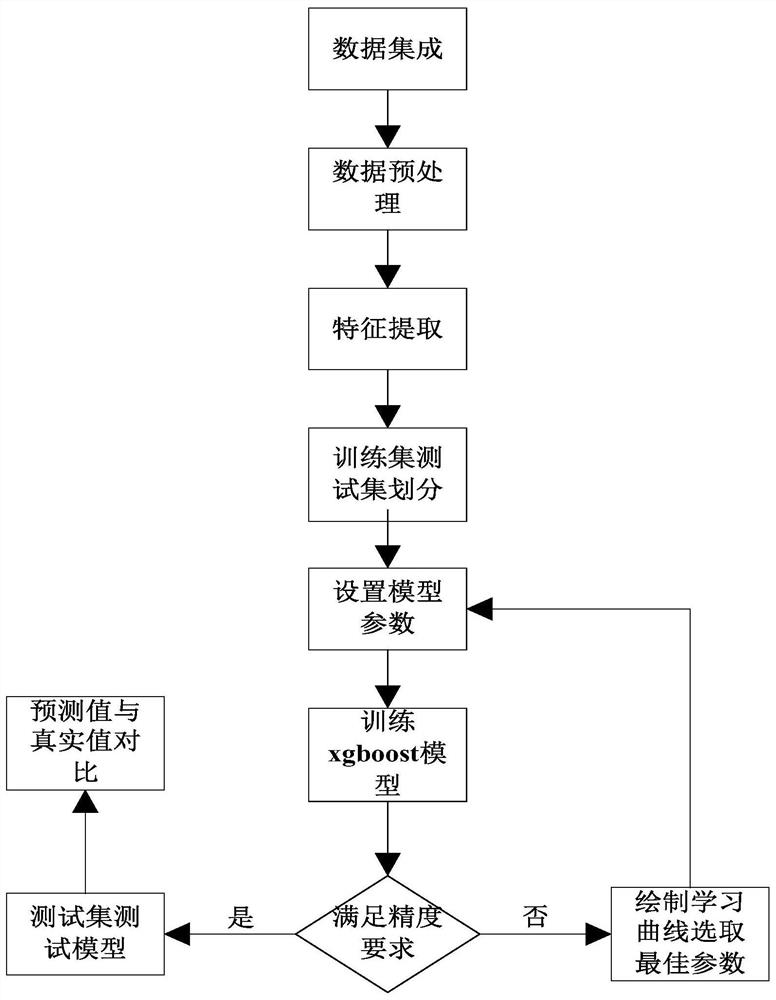
图1是本发明的流程示意图;
图2是本发明主要参数n_estimators最佳值的学习曲线图;
图3是本发明主要参数max_depth最佳值的学习曲线图;
图4是本发明F2(序号为2的轧机)工作辊真实值图
图5是本发明F2工作辊预测值图;
图6是本发明F2上支撑辊真实值图;
图7是本发明F2上支撑辊预测值图;
图8是本发明F2下支撑辊真实值图;
图9是本发明F2下支撑辊预测值图。
具体实施方式
下面结合附图和实施例对本发明作进一步的描述。
如图1所示,本实施例中的一种基于Xgboost的轧机多目标振动预测方法,其包括如下步骤:
步骤1:将从轧机现场实测到的工艺参数和振动数据进行拼接,组成完整的数据集;再将数据导入Jupyter中,查看数据是否有缺失值和异常值;若有缺失值,采用均值填充法填充缺失值;若有异常值直接删除;最后将数据标准化;
所述工艺参数采用PDA进行记录提取;所述振动数据为在轧机设备工作辊、上支撑辊和下支承辊位置布置传感器采集的工作辊、上支撑辊和下支承辊的振动数据,使用东华动态信号采集分析系统将轧机工艺参数、振动数据导出为CSV文件。
所述数据标准化为采用如下公式对数据进行标准化处理,
式中:μ为均值,σ为标准差,x
所述均值填充法为调用Sklearn中的impute.Simplelmputer模块,模块中的strategy参数代表填补缺失值策略,默认为均值;所述步骤1中的异常值直接删除为使用impute.Simplelmputer中的drop函数,直接将异常值删除。
步骤2:对标准化后的数据进行聚类、降维处理,选取数据特征;
所述对标准化后的数据进行聚类、降维处理为调用sklearn中的聚类、降维算法,对数据进行聚类、降维处理,最终选取6个轧机工艺参数即轧制力、轧制速度、入口厚度、出口厚度,前张力和后张力为输入特征,选取3个轧机振动即工作辊、上支撑辊和下支撑辊振动为输出特征。
步骤3:将选取的数据特征进行训练集、测试集划分,70%为训练集,30%为测试集;
所述将特征提取后的数据进行训练集、测试集划分是指:调用sklearn中的model_selection模块中的train_test_split函数,随机将数据的70%划分为训练集,30%划分测试集。
步骤4:设置Xgboost模型,即建立基于GBDT(梯度提升决策树)的Xgboost回归模型。根据训练数据不断生成CART来拟合上一棵CART产生的残差,最终集成所有CART即为最终Xgboost集成模型。
该Xgboost回归模型,是一种集成提升算法,即在数据上构建多个弱评估器,汇总所有弱评估器的结果,以获得比单个模型更好的回归结果。首先建立一棵树(所有树都是二叉的,即只有“是”和“否”的判断),每个被放入模型的数据都会落到一个叶子节点上,每个叶子节点都会有一个预测分数,也被称为叶子权重,这个叶子权重就是所有在这个叶子节点上的样本在这一颗树的回归取值。因此,Xgboost回归模型预测结果,就是所有弱评估器上叶子权重直接求和得到的。具体到本发明,轧机工艺参数数据为输入特征向量,轧机振动为输出结果,每个样本在每个弱评估器上都会获得一个预测结果,将所有弱评估器的结果求和,即获得最终预测值。
Xgboost模型参数主要包括:learning_rate,即步长,用于限制子学习器的过拟合,提高模型的泛化能力,与n_estimators配合使用;n_estimators,即子学习器个数;max_depth,即树的最大深度,对基学习器函数空间的正则化,一种预修剪手段;min_child_weight,即叶子节点的最小权重;gamma,即分裂阈值(最小损失分裂,用来控制分裂遵循的结构分数提升下限阈值);subsample,即样本子采样数,每个子学习器训练时采样的行采样比例(值区间为0~1),采样方式为无放回采样;reg_alpha,即L1正则化系数;reg_lambda,即L2正则化系数;objective,即损失函数。
所述参数为Xgboost模型默认参数即learning_rate=0.1,n_estimators=100,max_depth=5,min_child_weight=1,gamma=0,subsample=0.8,reg_alpha=0,reg_lambda=1;objective='reg:squarederror;所述精度要求为90%以上。
步骤5:将训练集数据导入Xgboost模型进行训练,查看预测精度;若预测精度达到设置精度要求,则进行下一步骤,否则绘制学习曲线(见图2、3),重新确定Xgboost模型参数取值。本发明采用Xgboost模型默认参数不能满足精度要求时,通过绘制模型参数学习曲线,n_estimators、max_depth需要重新赋值,重新训练Xgboost模型,最终训练出符合精度要求的模型;
步骤6:将测试集数据导入满足精度要求的Xgboost模型,得出预测值,调用Xgboost模型Score接口查看预测准确率,用matplotlib绘制预测结果图像并与测试集真实值进行对比(见图4~9)。
进一步地,所述步骤5中的绘制学习曲线为在Jupyter中,绘制Xgboost模型主要参数学习曲线,学习曲线的最佳参数为learning_rate=0.1,n_estimators=4000,max_depth=4,min_child_weight=1,gamma=0,subsample=0.8,reg_alpha=0,reg_lambda=1,objective='reg:squarederror。表一是本发明模型准确率对比表。
表一
- 一种基于Xgboost的轧机多目标振动预测方法
- 一种提高基于xgboost的轧机振动预测模型泛化能力的调参方法