一种基于微博数据的交通异常致因解析方法
文献发布时间:2023-06-19 10:51:07
技术领域
本发明涉及智能交通信息采集技术领域,更具体的说是涉及一种基于微博数据的交通异常致因解析方法。
背景技术
在过去20年,大量应用研究从实践角度证实了先进出行信息服务(ATIS)的使用价值。无论是日常出行抑或举办重大活动期间,ATIS为维护交通态势平稳提供了强有力的信息支撑(如我们比较关注的实时路况、路径选择、行程时间等);但是,城市中的一些非周期事件(如交通事故、道路施工管制、大型赛事/活动、恶劣天气等)往往导致交通异常,严重影响着ATIS的可靠性。首当其冲的就是交通异常的致因不确定性,即出行者通常能感应到交通异常(如非周期拥堵),但却不能及时了解交通异常发生的具体原因。
一种理想的方法是让出行者上报所有事件,因为他们可以提供详细和准确的事件相关信息。然而,由于较高人力成本和人工报告的严重延迟,很多学者开始致力于自动事件检测(AID)系统的开发。通过分析交通网络中采集的实时交通数据,可以识别事故及其特征。实际上是一种推断,它实质是检测交通异常状态,并用来推断某些事件的发生,但并不能从交通参数中分析出事件的具体信息,比如事件的类型,发生的时间和地点。
由于交通是每个人日常生活的一部分,许多活跃用户在遇到非周期事件时或事件发生后不久就会发布消息,例如微博。这个巨大的资源可能会潜在地收集关于不同类型、位置和时间的事件的有价值的信息,这已经成为提取各种信息的强大而廉价的工具,因此社交媒体可以作为一种社会传感器为及时的交通异常致因解析提高解决方案。
因此,提供一种基于微博数据的交通异常致因解析方法是本领域技术人员亟需解决的问题。
发明内容
有鉴于此,本发明提供了一种基于微博数据的交通异常致因解析方法,相比于基于交通数据的AID算法,本方法从真正意义上的事件检测入手,在挖掘更为充分详细的引起交通异常状态的事件信息,帮助提高出行者对交通态势的正确感知的同时,也为交通管理者的响应决策提高信息支撑。
为了实现上述目的,本发明采用如下技术方案:
一种基于微博数据的交通异常致因解析方法,包括:
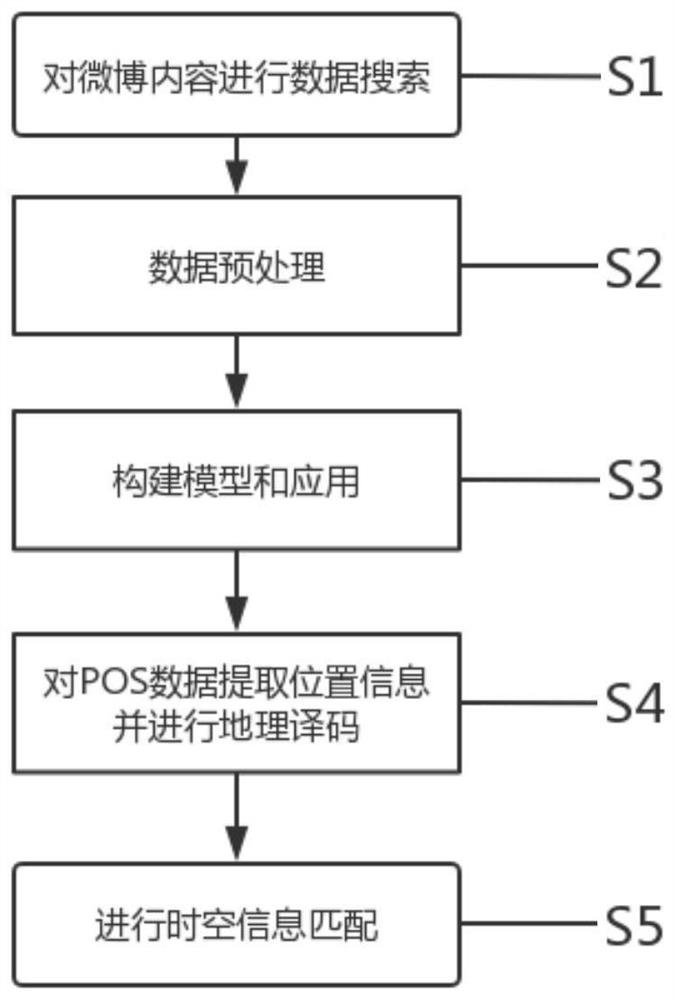
步骤S1,对微博内容进行数据搜索,得到原始语句;
步骤S2,对所述原始语句进行预处理,获得原始标记语句;
步骤S3,对所述原始标记语句切分成词向量,通过所述词向量构建分类模型并进行训练,使用训练后的分类模型将实时的微博数据分类别标记为POS数据、NEG数据;
步骤S4,对所述POS数据进行提取位置信息并进行地理编码,得到实时信息;
步骤S5,对所述实时信息进行时空信息匹配。
进一步,使用基于条件搜索的方式获得微博内容;通过去重和人工标记去做预处理;预处理后的数据通过文本切分、词向量转化并计算构建Xgboost模型并进行训练,训练过的模型用于识别新事件;然后使用命名实体方法从被分类为POS的微博文本中提取位置信息并进行地理编码;最后,根据时空信息匹配,构建交通异常状态与非周期事件之间的因果关系。
优选的,一种基于微博数据的交通异常致因解析方法中,所述步骤S1中数据搜索方式采用条件式搜索,所述搜索条件包括空间范围、时间范围和关键词。进一步,利用爬虫技术采集每条微博的内容和发布时间。
优选的,一种基于微博数据的交通异常致因解析方法中,所述步骤S1中,用于搜索非周期事件相关微博的关键词为交通事故、道路施工、演唱会、商业活动、马拉松。
优选的,一种基于微博数据的交通异常致因解析方法中,所述步骤S2包括:
步骤S21,对原始语句进行去重,得到第一信息语句;
步骤S22,对所述第一信息语句进行人工标记。
进一步,微博内容的分享和转发会造成样本的重复,这种过采样问题会影响分类性能,因此首先对微博数据进行去重工作;其次对微博内容进行人工标记,以便分类器的训练和验证。
优选的,一种基于微博数据的交通异常致因解析方法中,所述步骤S22中,把所述第一信息语句中的非周期事件语句标记为POS,其余语句则标记为NEG。
优选的,一种基于微博数据的交通异常致因解析方法中,6、步骤S3包括:
步骤S31,将原始标记语句进行文本切分,得到词向量;
步骤S32,将所述词向量转化为可计算的特征向量,计算公式如下:
TF_IDF=TF*IDF,
其中TF表示词频,IDF表示反义文档频率,TF_IDF为一个词对应的特征值;
步骤S33,构建Xgboost分类模型,并采用步骤32中的数据集进行训练和验证;
步骤S34,对训练后的Xgboost模型对实时的微博数据进行分类识别。
进一步,文本切分,即把一条微博文本切分为多个词,并删除无具体语义的停止词,例如“的”“是”“了”,然后获得一个词向量;词向量转化为可计算的特征向量,其中每个词对应一个特征值;随后构建Xgboost分类模型,并用上述步骤S32中的数据集进行训练和验证;最后使用训练过的Xgboost模型对实时的微博数据进行分类以识别刚发生的事件。
优选的,一种基于微博数据的交通异常致因解析方法中,步骤S32中,数据集通常以7:3的比例用于分类器的训练和验证。
优选的,一种基于微博数据的交通异常致因解析方法中,8、步骤S4采用实体命名方法,其中:
步骤S41,收集表征地址信息的命名实体;
步骤S42,检测信息数据文本对应的词向量,根据所述命名实体进行筛选并标记实体词;
步骤S43,使用地理编码引擎对所述实体词进行编码,得到所述实体词对应的坐标。
进一步,首先收集道路和兴趣点的名称,把他们作为一种表征地址信息的命名实体;其次检测微博文本对应的词向量,若其中的某个词出现在命名实体中,称它为实体词,意味着它能够表征事件发生的位置;最后使用地理编码引擎对实体词进行编码,获得其对应的坐标;
优选的,一种基于微博数据的交通异常致因解析方法中,步骤S5中构建交通异常状态与非周期事件之间的因果关系,满足所述交通异常状态与所述非周期事件之间匹配原则,
dist(lT,lI)≤Dτ,
|tT-tI|≤Tτ,
其中,dist(*)函数表示欧式距离函数,lT和tT为交通异常状态发生的地点和时间,lI和tI和代表非周期事件发生的地点和时间,Dτ为空间距离偏差;Tτ为时间偏差。
进一步,用非周期事件的时空信息与交通状态日志中的异常状态的时空信息进行匹配,若二者在时间和空间上足够近,则建立它们之间的因果关系。
经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种基于微博数据的交通异常致因解析方法,首先通过条件搜索进行微博内容收集;其次对微博内容进行预处理工作,主要包括文本去重和人工标记;随后构建文本分类器,并用它识别事件相关微博;然后从事件相关微博中提取事件位置信息和发布时间信息;最后通过时空信息匹配构建事件相关微博与交通异常之间的因果关系。
本发明的优点在于:
(1)本发明的最大特点就是以不再单纯地从交通参数显著变化的角度来推断非周期事件的发生,从而直接从社交媒体中挖掘可能导致交通异常的事件。
(2)本发明的主要目的是构建基于微博数据的非周期事件实时检测系统,及时地为交通异常提供致因解析服务。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
图1附图为本发明提供的基于微博数据的交通异常致因解析方法的流程图;
图2附图为本发明提供的基于微博数据的交通异常致因解析方法的应用流程图;
图3附图为本发明提供的混淆矩阵图;
图4附图为本发明提供的时空匹配结果示意图;
图5附图为本发明提供的关键字对应的微博数量图;
图6附图为本发明提供的对关键词标记后的结果图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例公开了一种基于微博数据的交通异常致因解析方法,包括:
步骤S1,对微博内容进行数据搜索,得到原始语句;
步骤S2,对所述原始语句进行预处理,获得原始标记语句;
步骤S3,对所述原始标记语句切分成词向量,通过所述词向量构建分类模型并进行训练,使用训练后的分类模型将实时的微博数据分类别标记为POS数据、NEG数据;
步骤S4,对所述POS数据进行提取位置信息并进行地理编码,得到实时信息;
步骤S5,对所述实时信息进行时空信息匹配。
为了进一步优化上述技术方案,图2是根据一示例性实施例示出的基于微博数据的交通异常致因解析方法的应用流程图,使用基于条件搜索的方式检索微博内容,其中搜索条件包括空间范围、时间范围和关键词,并利用爬虫技术采集每条微博的内容和发布时间;微博内容的分享和转发会造成样本的重复,因此对微博数据进行去重工作,然后对微博内容进行人工标记,其中把与非周期事件相关的微博标记为POS,其余的则标记为NEG;通过对微博数据搜索的数据进行文本分类和事件识别,先把一些无具体语义的停止词(如“的”、“是”、“了”)删除,最后获得一个词向量,然后把词向量转化为可计算的特征向量,进行计算,利用构建Xgboost分类模型,并计算后的数据集进行训练和验证;使用训练过的Xgboost模型对实时的微博数据进行分类以识别刚发生的事件,主要有时间位置信息、微博发布时间;最后通过路网交通数据获得相关信息;最后通过判定,去检测相关微博事件。
更具体的,一种基于微博数据的交通异常致因解析方法。
数据搜索。以北京市为例,时间范围为2019年全年,利用关键词检索微博,其中关键字及其对应的微博数量如图5所示,其中所获得的每条微博数据均包括微博内容和发布时间两个属性。此外,由微博数量可知,像演唱会、大型赛事这样的参与人数众多且影响力大的事件往往会产生较多的相关微博。
数据预处理。首先是数据去重,在上一步骤获得的19360条数据中,经过去重,还剩16708条非重复数据。其次是进行人工标记,标记的示例结果如图6所示,可以看出,被标记为POS的微博文本一般是事件描述,具有明确的时间/空间信息,而标记为NEG的微博文本主要是用户基于关键词发表的意见、讨论和想法等。
构建模型和应用。选取2019年前9个月的数据以7:3的比例进行文本分类模型的训练和验证,流程如下。
a.以文本串Text=“志新路发生了严重交通事故”为例,经分词及停止词过滤后,Text转换为词序列[志新路、发生、严重、交通事故]。
b.随后计算每个词对应的TF_IDF特征值,得到特征向量
c.将所有训练集转换为特征向量后,输入Xgboost模型进行训练,并使用验证集进行分类性能验证。验证过程所得的混淆矩阵如图3所示。结果表明分类器具有很高的分类性能,其召回率率、精确度和准确性分别达到0.946、0.939和0.952。
对POS数据提取位置信息并进行地理译码。用2019年后三个月的微博文本作为测试集,并用对其进行分类以识别事件相关微博。随后收集北京市内的各道路及兴趣点名称,比如[志新路,京藏高速,鸟巢......]。最终检索出事件相关微博中的位置信息。最后通过高德地图的地理编码引擎获得位置名称的地理坐标,比如志新路的坐标为[116.366074,39.993732]。
进行时空信息匹配。令空间阈值、D
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 一种基于微博数据的交通异常致因解析方法
- 一种基于微博的交通数据获取方法