涉及基于适体的可逆细胞选择的组合物和方法
文献发布时间:2023-06-19 10:58:46
相关申请的交叉引用
根据35U.S.C.§119(e),本申请要求2018年7月17日提交的美国临时申请No.62/699,438以及2018年12月14日提交的美国临时申请No.62/779,946的优先权,以引用的方式将它们的内容整体并入本文。
序列表
本申请包括序列表,所述序列表已经以ASCII格式电子提交,并在此以引用的方式将其整体并入。所述ASCII副本创建于2019年7月12日,命名为034186-092710WOPT_SL.txt,并且大小为32,467字节。
技术领域
本公开内容涉及细胞的分离。
背景技术
随着对于治疗急性淋巴细胞白血病(ALL)和弥漫性大B细胞淋巴瘤的嵌合抗原受体(CAR)T细胞疗法的两个最近的FDA批准以及在临床管道中的许多有希望的试验,正迅速意识到细胞疗法的临床影响。除癌症外,还产生了CAR T细胞来用于其它细胞疗法,例如抗HIV疗法。当前用于细胞疗法应用(例如CAR T细胞疗法、树突状细胞疫苗等)的程序可以包括收获和分离靶细胞(例如T细胞的特定亚群、单核细胞等)并对其进行操纵(例如刺激它们和/或对其进行遗传修饰),然后再将它们或它们的子代重新引入患者内。已经开发了无标记的基于蛋白质的分离技术来分离特定的细胞亚群(例如T细胞),但是这些方法仍然具有挑战,包括由所需的连续正选择(successive positive selections)的数量所导致的高成本和低细胞产率。
发明内容
本文描述了用于生产规模的无标记细胞(例如CD8+T细胞)分离的可逆适体(aptamer)选择技术。
在一个方面,尤其是,本文描述了用于从包含多种细胞类型的生物样品中分离(isolating)感兴趣的细胞的方法,该方法包括:(i)在允许形成与适体结合的细胞的条件下,使生物样品与适体接触,所述适体特异性结合对感兴趣的细胞具有特异性的细胞表面标志物;(ii)将与适体结合的细胞与未与适体结合的细胞分开(separating);以及(iii)通过破坏适体与细胞表面标志物的结合来回收感兴趣的细胞,从而从生物样品中分离感兴趣的细胞。
在一个实施方式中,感兴趣的细胞是活的(viable)。
在另一实施方式中,感兴趣的细胞是白细胞、淋巴细胞、单核细胞、T细胞或CD3+细胞、CD4+细胞或CD8+细胞。
在另一实施方式中,适体包含标记。
在另一实施方式中,将与适体结合的细胞与未与适体结合的细胞分开的步骤包括使用第一固体支持物或相变剂。
在另一实施方式中,适体(i)缀合或固定至第一固体支持物;和/或(ii)被亲和对的第一成员标记。
在另一实施方式中,分开步骤(ii)包括(i)从生物样品中去除通过适体结合至第一固体支持物的与适体结合的细胞;或(ii)添加带有亲和对的第二成员的第二固体支持物,以允许通过亲和对的第一成员和第二成员的相互作用使适体物理缔合至第二固体支持物,并从生物样品中去除与适体结合的细胞。
在另一实施方式中,适体缀合至相变剂。
在另一实施方式中,接触步骤(i)在相变剂处于溶液相的条件下进行;分开步骤(ii)包括诱导相变剂从溶液中沉淀,从而从生物样品中去除与适体结合的细胞。
在另一实施方式中,第一固体支持物和/或第二固体支持物包括磁响应(magnetoresponsive)珠。
在另一实施方式中,第一固体支持物和/或第二固体支持物包括聚合物、金属、陶瓷、玻璃、水凝胶或树脂。
在另一实施方式中,分开步骤包括使样品经受磁场,从而将包含与适体结合的细胞的磁响应珠或固体支持物与生物样品分开。
在另一实施方式中,逆转剂(reversal agent)包括聚阴离子、小分子或寡核苷酸或寡核苷酸模拟物,所述寡核苷酸或寡核苷酸模拟物包含与适体的序列充分互补的序列以与适体杂交,从而破坏适体与细胞表面标志物的结合。
在另一实施方式中,与适体结合的细胞包含对选定的标志物对呈双重阳性的细胞,所述标志物对包括适体所结合的标志物。
在另一实施方式中,分离的细胞级分包含对选定的标志物对呈双重阳性的细胞,所述标志物对包括适体所结合的标志物。
在另一方面,本文描述了从生物样品中分离多种细胞级分的方法,该方法包括:(i)在允许形成与适体结合的细胞的条件下,使生物样品与多种适体接触,所述适体特异性结合对多种不同的感兴趣的细胞具有特异性的细胞表面标志物;(ii)将与适体结合的细胞的群与未与适体结合的细胞分开;(iii)依次向步骤(ii)中分开的与适体结合的细胞中添加多种逆转剂,所述多种逆转剂破坏多种适体中的一种或多种与多种细胞表面标志物中的一种或多种的结合,从而使依次添加的逆转剂从步骤(ii)中分开的细胞的群中洗脱出不同的细胞级分,从而从生物样品中分离多种不同的细胞级分。
在一个实施方式中,多种逆转剂包括聚阴离子、小分子、寡核苷酸或寡核苷酸模拟物或它们的组合,所述寡核苷酸或寡核苷酸模拟物包含与多种适体中的适体的序列充分互补的序列以与适体杂交,从而破坏适体与其细胞表面标志物的结合。
在另一实施方式中,多种适体结合至一种或多种固体支持物或相变剂。
在另一实施方式中,固体支持物包括磁响应珠。
在另一实施方式中,固体支持物包括聚合物、金属、陶瓷、玻璃、水凝胶或树脂。
在另一实施方式中,分开步骤包括使样品经受磁场,从而将包含与多种不同适体结合的细胞群的磁响应珠或固体支持物与样品分开。
在一些实施方式中,通过使样品经受磁场,将与多种不同适体结合的细胞群与生物样品分开。
在一个实施方式中,与适体结合的细胞是白细胞、淋巴细胞、T细胞或表达CD3、CD8和/或CD4的细胞。
在另一方面,本文描述了从生物样品中分离细胞级分的方法,所述细胞级分富集了对靶细胞标志物对呈双重阳性的细胞,该方法包括:(i)在允许形成与适体结合的细胞的条件下,使生物样品与特异性结合第一靶细胞表面标志物的第一适体接触;(ii)将与适体结合的细胞的群与未与适体结合的细胞分开;(iii)将步骤(ii)中分开的与适体结合的细胞的群与破坏第一适体与步骤(ii)中分开的细胞的结合的第一逆转剂接触,从而分离出对第一靶细胞表面标志物呈阳性的细胞群;(iv)在允许形成与适体结合的细胞的条件下,使步骤(iii)中分离的群与特异性结合第二靶细胞表面标志物的第二适体接触;(v)将步骤(iv)中形成的与适体结合的细胞的群与未与适体结合的细胞分开;以及(vi)将步骤(v)中分开的与适体结合的细胞的群与破坏第二适体与步骤(v)中分开的细胞的结合的第二逆转剂接触,从而分离对第一靶细胞表面标志物和第二靶细胞表面标志物呈阳性的细胞群。
其它方法可用于分离双重阳性细胞。例如,使用同时添加适体来分离CD3+CD8+细胞的方法可以使用结合CD3、CD4和CD8的三种适体。在结合细胞并将它们置于柱上后,首先用CD8逆转剂洗脱以洗下(strip off)CD3阴性/CD8
CD3+CD4+双重阳性细胞的分离也是可能的。PBMC中有很多CD4
在一个实施方式中,逆转剂包括小分子、聚阴离子、寡核苷酸或寡核苷酸模拟物或它们的组合,所述寡核苷酸或寡核苷酸模拟物包含与相应的适体的序列充分互补的序列以与适体杂交,从而破坏适体与细胞表面标志物的结合。
在另一实施方式中,第一适体和/或第二适体固定或缀合至一种或多种固体支持物或相变剂。
在另一实施方式中,固体支持物包括磁响应珠、聚合物、金属、陶瓷、玻璃、水凝胶或树脂。
在另一实施方式中,固体支持物包括磁响应珠,并且其中通过使细胞群经受磁场来将与第一适体和/或第二适体结合的细胞群分开。
在一个实施方式中,与适体结合的细胞包含白细胞、淋巴细胞、T细胞、CD3+T细胞、CD8+T细胞、CD4+T细胞、CD3+CD4+T细胞或CD3+CD8+T细胞。
在另一方面,本文描述了基于细胞表面标志物的表达程度将生物样品中的感兴趣的细胞分开的方法,该方法包括:(i)在允许形成与适体结合的细胞的条件下,使生物样品与适体接触,所述适体特异性结合对感兴趣的细胞具有特异性的细胞表面标志物;(ii)将与适体结合的细胞与未与适体结合的细胞分开;以及(iii)使步骤(ii)中分开的与适体结合的细胞阶梯式地(step-wise)或梯度式地与浓度增加的逆转剂接触,所述逆转剂破坏适体与细胞表面标志物的结合;从而基于细胞表面标志物的表达程度将生物样品中的感兴趣的细胞分开,使得样品中具有较低标志物表达(marker
在一个实施方式中,逆转剂包括聚阴离子、小分子、寡核苷酸或寡核苷酸模拟物或它们的组合,所述寡核苷酸或寡核苷酸模拟物包含与适体的序列充分互补的序列以与适体杂交,从而破坏适体与细胞表面标志物的结合。
在另一方面,本文描述了基于细胞表面标志物的表达程度将生物样品中的感兴趣的细胞分开的方法,该方法包括:(i)在允许形成与适体结合的细胞的条件下,使生物样品与适体接触,所述适体特异性结合对感兴趣的细胞具有特异性的细胞表面标志物;(ii)将与适体结合的细胞与未与适体结合的细胞分开;以及(iii)使步骤(ii)中分开的与适体结合的细胞依次与在置换动力学(kinetics of displacement)或适体亲和力方面不同的多种逆转剂接触,并且以增加的相对置换动力学或相对适体亲和力的顺序添加逆转剂,从而基于细胞表面标志物的表达程度将生物样品中的感兴趣的细胞分开,使得样品中具有较低标志物表达(marker
在一个实施方式中,逆转剂包括聚阴离子、小分子、寡核苷酸或寡核苷酸模拟物或它们的组合,所述寡核苷酸或寡核苷酸模拟物包含与适体的序列充分互补的序列以与适体杂交,从而破坏适体与细胞表面标志物的结合。
在另一实施方式中,感兴趣的细胞是白细胞、淋巴细胞、T细胞或表达CD3、CD8和/或CD4的细胞。
在另一实施方式中,适体结合至一种或多种固体支持物或相变剂。
在另一实施方式中,固体支持物或相变剂包括磁响应珠。
在另一实施方式中,固体支持物包括聚合物、金属、陶瓷、玻璃、水凝胶或树脂。
在另一实施方式中,分开步骤包括使样品经受磁场,从而将包含与多种不同适体结合的细胞群的磁响应珠或固体支持物与生物样品分开。
在另一方面,本文描述了选择性地与人CD8多肽结合的包含SEQ ID NO:1-SEQ IDNO:6、SEQ ID NO:10-SEQ ID NO:14、SEQ ID NO:17-SEQ ID NO:22、SEQ ID NO:27-SEQ IDNO:30、SEQ ID NO:33-SEQ ID NO:48或SEQ ID NO:52-SEQ ID NO:66的序列的核酸分子。
在一个实施方式中,所述核酸分子在选自于由以下核苷酸对所组成的组中的核苷酸对处包含补偿性变化(compensatory change):核苷酸3和75、4和74、5和73、6和72、7和71、8和70、9和69、10和68、13和54、14和53、15和52、16和51、17和50、18和49、19和48、25和47、26和46、27和45、28和44、29和43、30和42、31和41、32和40、33和39或34和38;其中,所述核酸分子相对于SEQ ID NO:1的核酸分子保留与CD8多肽的选择性结合。
在另一实施方式中,所述核酸分子在选自于由以下核苷酸对所组成的组中的两个以上的核苷酸对处包含补偿性变化:核苷酸3和75、4和74、5和73、6和72、7和71、8和70、9和69、10和68、13和54、14和53、15和52、16和51、17和50、18和49、19和48、25和47、26和46、27和45、28和44、29和43、30和42、31和41、32和40、33和39或34和38;其中,所述核酸分子相对于SEQ ID NO:3的核酸分子保留与CD8多肽的选择性结合。
在另一实施方式中,核酸分子是DNA分子、RNA分子或PNA分子。
在另一实施方式中,核酸分子包含经修饰的核苷。
可以并入保持适体结合其靶标的能力的任何经修饰的核苷,例如,以增强或修饰体内稳定性、或使适体的二级结构稳定或不稳定。
在另一实施方式中,适体的核苷或经修饰的核苷可以选自例如表1中的核苷或经修饰的核苷。
在另一实施方式中,固体支持物包含本文所述的任何一种或多种适体核酸的核酸分子。
在另一实施方式中,固体支持物是磁响应珠。
在另一实施方式中,固体支持物包括聚合物、金属、陶瓷、玻璃、水凝胶或树脂。
在另一实施方式中,固体支持物通过核酸分子与CD8+T细胞结合。
在另一实施方式中,核酸还包含标记。
在另一实施方式中,核酸具有生物素标记和/或荧光标记。
在另一方面,本文描述了包含与本文所述的核酸结合的CD8+人T细胞的组合物。
在一个实施方式中,将本文所述的适体核酸与包含核酸的逆转剂杂交,所述核酸包含与所述适体的至少八个连续核苷酸互补的序列。
在另一方面,本文描述了包含核酸分子的逆转剂,所述核酸分子包含与本文所述的适体互补的至少八个连续核苷酸,其中所述逆转剂分别抑制本文所述的CD8结合适体中的任一种与人CD8多肽的结合。
在一方面,本文描述了从生物样品中分离CD8+T细胞的方法,该方法包括使包含人CD8+T细胞的生物样品与本文所述的结合CD8的适体或包含此类适体的固体支持物接触,其中所述接触允许CD8+T细胞与适体的选择性结合。
在一个实施方式中,生物样品包括全血、血沉棕黄层(buffy coat)或分离的单个核细胞(mononuclear cells)。
在另一实施方式中,所述方法包括在使生物样品与适体或包含适体的固体支持物接触后,使样品与包含核酸分子的逆转剂接触的步骤,所述核酸分子包含与适体互补的至少八个连续核苷酸的序列,其中逆转剂抑制所述核酸与人CD8多肽的结合,从而允许CD8+T细胞的释放。
在一个实施方式中,使样品与包含结合CD8的本文所述的适体的固体支持物接触,并且使样品进一步经受磁场,从而允许将与固体支持物结合的CD8+T细胞与样品中的其它细胞分开。
在一个方面,本文描述了从生物样品中制备感兴趣的细胞的靶细胞类型或类别的群的方法,该方法包括:(i)在允许形成与适体结合的细胞的条件下,使生物样品与适体接触,所述适体特异性结合对感兴趣的细胞的靶细胞类型或类别具有特异性的细胞表面标志物;(ii)将与适体结合的细胞与未与适体结合的细胞分开;(iii)通过破坏适体与其结合靶标的结合来回收感兴趣的细胞群。在一个实施方式中,进行(iv)对回收的感兴趣的细胞进行修饰这一另外的步骤。
在一个实施方式中,修饰包括激活或刺激细胞的遗传修饰或处理。
在一个实施方式中,细胞是T细胞、B细胞、单核细胞、树突状细胞或自然杀伤细胞。
在一个方面,本文描述了对结合感兴趣的细胞的特定细胞类型或类别的适体序列进行选择的方法,该方法包括:(i)将感兴趣的细胞类型或类别与单链DNA文库一起孵育,所述文库包含20个至85个核苷酸的给定长度的随机序列;(ii)分离与感兴趣的细胞结合的单链DNA;(iii)将来自步骤ii的分离的单链DNA序列与包含感兴趣的细胞在内的细胞类型的混合物一起孵育;(iv)用抗体和抗体特异性支持柱从步骤iii的孵育中分离感兴趣的细胞;(v)从步骤iv中分离的细胞中提取结合的单链DNA;(vi)对来自步骤v的结合的单链DNA序列进行PCR扩增;(vii)将来自步骤vi的单链DNA序列与缺乏感兴趣的表面受体的细胞类型一起孵育;(viii)将未结合的单链DNA与步骤vii中的细胞分开;(ix)对来自步骤viii的未结合的单链DNA序列进行PCR扩增;(x)重复步骤iii-步骤ix至少两次;以及(xi)对剩余的单链DNA进行测序。
在一个实施方式中,感兴趣的细胞是白细胞、淋巴细胞、T细胞或CD8+T细胞、或CD3+T细胞、或CD2+T细胞、或CD4+T细胞、或CD28+T细胞、或B细胞、或单核细胞、或树突状细胞、或干细胞(例如造血干细胞)。
在一个实施方式中,感兴趣的细胞包含两种以上的本文所述的细胞表面标志物的组合。
在另一实施方式中,本文所述的方法用于感兴趣的细胞群的大规模选择。
在另一方面,本文描述了治疗疾病或紊乱的方法,该方法包括给予通过本文所述的方法分离的细胞或其子代的组合物,其中该细胞的组合物将疾病的至少一种症状减轻至少10%。
在一个实施方式中,疾病或紊乱是癌症、自身免疫疾病或HIV感染。
在另一方面,本文描述了已通过本文所述的方法分离的细胞的组合物。
在另一方面,本文描述了已通过本文所述的方法分离的细胞级分的组合物。
在另一方面,本文描述了已通过本文所述的方法分开的细胞的组合物。
在另一方面,本文描述了已通过本文所述的方法分离的CD8+T细胞的组合物。
在另一方面,本文描述了通过本文所述的方法制备的细胞的组合物。
在另一方面,本文描述了特异性结合通过本文所述的方法选择的适体的细胞的组合物。
附图说明
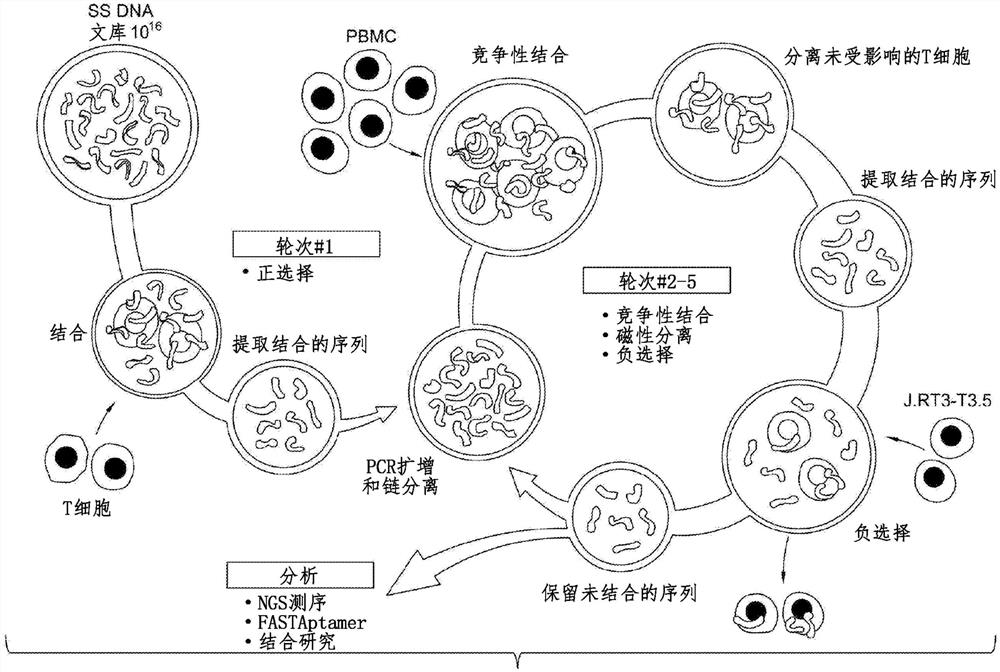
图1是具有从PBMC中进行磁性耗竭的竞争性细胞-SELEX的示意图。DNA适体文库以低严格性针对混合T细胞经历一轮正选择(positive selection),然后在严格性增加的条件下分别针对PBMC和CD4loCD8-J.RT3-T3.5细胞经历四轮连续竞争性选择和负选择(negative selection)。对于竞争性选择,在适体文库暴露后将T细胞从PBMC中作为负级分(negative fraction)分离,以富集T细胞特异性适体,并将针对非T细胞淋巴细胞、单核细胞和树突状细胞的结合物耗竭。在竞争性选择后,通过使用Pan T细胞分离试剂盒将非靶细胞耗竭,从PMBC中分离未受影响的(untouched)T细胞和结合的适体。
图2A-图2B表示来自不同轮次的T细胞SELEX的适体池与T细胞和J.RT3-T3.5细胞的结合。图2A示出了在连续轮次的SELEX之后,适体池与正选择混合T细胞和负选择J.RT3-T3.5细胞的结合的流式细胞术直方图。图2B代表用来自不同轮次的适体池染色呈阳性的细胞的相应百分比。各个数据点代表技术重复,水平条形代表平均值。
图3表示来自连续轮次的T细胞SELEX的前100种适体的系统进化树和脱颖而出的共有基序。用FigTree软件(可在万维网上按照http://tree.bio.ed.ac.uk/software/figtree/获得)生成系统进化树,并使用MEME分析(可在万维网上按照http://www.MEME-suite.org获得)预测结合基序。
图4示出了A1、A2、A3、A7和A8适体的预测的最小自由能(MFE)二级结构。适体是根据它们的第5轮排名而命名的。使用NUPACK软件计算结构(温度=4℃;Na+=137mM;Mg++=5.5mM)。
图5A-图5B表示从前10个第5轮序列中选择的单个适体与T细胞和J.RT3-T3.5细胞的结合。图5A示出了用随机(RN)适体以及A1、A3和A8适体(根据第5轮排名而命名)染色呈阳性的混合T细胞和J.RT3-T3.5细胞的百分比的流式细胞术分析。各个数据点代表技术重复。图5B示出了RN、A2和A7适体与混合T细胞和J.RT3-T3.5细胞的结合的中值荧光强度(MFI)的流式细胞术分析。各个数据点代表技术重复(n=3),水平条形代表平均值。
图6A-图6E表示与CD8a糖蛋白结合的适体1、3和8。图6A示出了50nM随机(RN)、A1、A3和A8适体与混合T细胞群中的CD4+和CD8+T细胞的结合的流式细胞术图。图6B示出了用非特异性(NS)siRNA或CD8 siRNA双链体对细胞进行核转染24小时后,CD8a抗体(CD8a Ab)以及10nM RN、A1、A3和A8适体与3天激活的CD8+T细胞的结合的流式细胞术分析。直方图代表具有技术三重复的3个独立实验。图表显示相对于NS siRNA处理的对照,与CD8 siRNA处理的细胞的结合。数据为平均值±s.d.,n=3,*P<0.05和**P<0.01(单因素ANOVA和Bonferroni校正)。图6C示出了用具有GFP报告子的CD8a质粒对细胞进行核转染24小时后,CD8a Ab以及10nM RN、A1、A3和A8适体与CD8-Jurkat细胞的结合的流式细胞术分析。图代表具有技术三重复的3个生物学重复。图表显示对抗体或适体结合也呈阳性的GFP+Jurkats的百分比。数据为平均值±s.d.,n=3,*P<0.05,***P<0.001和****P<0.0001(配对单因素ANOVA和Dunnett检验)。图6D示出了BLI测量的连续稀释的CD8a蛋白与固定的A1、A3和A8适体的结合的缔合和解离动力学。缔合阶段从0到1200秒示出,而解离阶段从1200-1800秒示出。通过将不同浓度的CD8a蛋白的动力学数据对1:1结合模型进行全局拟合来计算K
图7A-图7B表示A1、A3和A8适体与鼠脾T细胞和恒河猴PBMC的结合。图7A示出了流式细胞术图,其显示了CD8a Ab以及50nM RN、A1、A3和A8与CD3+CD8+鼠(mu)脾T细胞的结合。图代表3个生物学重复。图7B示出了适体与CD3+CD8+恒河猴(rh)PBMC的结合的相似的图。
图8A-图8B示出了不同CD8a抗体浓度与固定浓度的A1、A3和A8适体的竞争性结合。图8A示出了在0至40纳摩尔(nM)对照CD3e抗体或竞争性CD8a抗体存在下,10nM A1、A3&A8与CD8+T细胞的结合的流式细胞术直方图。直方图代表一个生物学复制。图8B示出了适体结合的相应MFI。数据为n=1个生物学重复。
图9表示A3适体和先前文献报道的CD8 DNA适体的结合比较。图表示出了在描述的结合条件(T-BB)和公开的适体结合条件(A-BB)下,RN、已公开的CD8Ap17s和A3在一定浓度范围内与CD8+T细胞的结合的MFI。结合条件说明了所用的缓冲液和退火条件。数据为平均值±s.d.,n=3个技术重复(误差条太小而无法可视化)。
图10A-图10B表示设计用于阻断具有经修饰的toehold的A3适体的结合的互补逆转剂。图10A表示使用UNPACK软件预测的改变的A3适体的最小自由能(MFE)二级结构(温度=4℃;Na+=137mM;Mg++=5.5mM)。通过从5'末端去除2个碱基对(bp)(如圆圈所指示)并向3'末端添加2bp(如圆圈所指示)来修饰A3适体,创建具有3'8bp toehold的A3适体(A3t)。灰线表示设计用于使互补逆转剂(RA)退火的36bp区域。图10A公开了SEQ ID NO:6。图10B表示在用RA进行链置换后,A3t适体的预测的MFE二级结构(温度=20℃;Na+=137mM;Mg++=5.5mM)。图10B按出现顺序分别公开了SEQ ID NO:6-SEQ ID NO:7。
图11A-图11B表示使用互补逆转剂洗脱A3t适体的优化。图11A示出了在不同过量倍数的浓度的逆转剂(RA)和与逆转剂(RA)的不同孵育时间和温度下从CD8+T细胞中洗脱的A3t适体(5nM)的百分比的流式细胞术分析。使用给定条件下的MFI计算洗脱,然后将其除以给定温度下无逆转剂时的染色的MFI。数据为平均值±s.d.,n=3个技术重复(误差条太小而无法可视化)。图11B示出了在不同温度下与100倍过量的逆转剂孵育10min后A3t结合的流式细胞术直方图。直方图代表技术三重复。使用Overton减法计算每个窗格中的阳性百分比或重叠百分比。
图12A-图12B示出了RN和A3t适体与PBMC内不同细胞类型的结合。图12A示出了显示CD3、CD14、CD19和CD56抗体以及5nM RN和A3t适体与PBMC的结合的流式细胞术图。图代表3个生物学重复。图12B示出了RN和A3t适体与构成PBMC群约92%的不同细胞类型的结合的相应统计信息。用适体染色呈阳性的每种细胞类型的百分比是亲本群的统计信息,而不是总PBMC的统计信息。通过减去用于描绘(delineate)适体阴性和阳性细胞的荧光值来将MFI值归一化。数据为平均值±s.d.,n=3个生物学重复。
图13A-图13F表示使用可逆的基于适体的选择策略从PBMC分离无标记的CD8+T细胞。图13A示出了使用A3t适体对CD8+T细胞进行无痕选择(traceless selection)的示意图。将预加载到Miltenyi抗生物素微珠上的生物素化适体(5nM)与PBMC一起孵育以磁性标记CD8+T细胞。将细胞悬浮液在磁场下施加到LS柱上,其中未标记的细胞在流穿(FT)级分中被去除。将保留在柱上的微珠标记的CD8+T细胞与100×过量的互补RA孵育,并在RA洗脱(RAE)级分中将释放的CD8+T细胞从柱上洗掉。在没有磁场的情况下,使用柱塞(plunger)柱冲洗(column flush,CF)去除柱上的剩余细胞。图13B示出了标准的基于抗体的MiltenyiCD8微珠分离和无痕的基于适体的分离的不同级分中的CD8表达的流式细胞术直方图。直方图代表具有技术三重复的3个独立实验。图13C示出了CD8+抗体分离的CF和适体分离的RAE细胞级分中的CD3和CD16表达的流式细胞术图,以在CD3+CD16-T细胞和CD3-CD16+单核细胞以及NK细胞之间进行区分。图代表具有技术三重复的3个独立实验。图13D-图13F示出了基于抗体和基于适体的分离的不同级分中的CD3+CD8+CD16-T细胞的产率、纯度和CD8 MFI的流式细胞术分析。符号代表来自单独的分离实验的不同供体,并且所有数据以技术三重复来收集。数据为平均值±s.d.,n=3,ns>0.05和*P<0.05(图13D和图13F,配对单因素ANOVA和Tukey检验;e,双侧配对t检验)。
图14A-图14B表示用于产率、纯度和表型分析的流式细胞术门控策略。图14A表示用于确定样品中CD8+T细胞的百分比以及由此的分离级分的纯度和产率的门控方案。通过使用活细胞的CD8+CD3+CD16-细胞的百分比来确定CD8+T细胞的百分比,因为CD8loCD3-CD16+细胞代表单核细胞和NK细胞。在此实例中示出了预选的PBMC。图14B示出了用于确定PBMC或新鲜分离的细胞级分中的CD8+T细胞表型的门控方案。CD45RA和CD45RO表达分别用于区分初始(naive)/效应(N/E)细胞与中央/效应记忆(CM/EM)细胞,CD62L和CCR7表达(单或双)一起用于从不表达的E/EM细胞中鉴别N/CM细胞。CD45RA/RO双重阳性且未门控的细胞被鉴别为过渡细胞。在此实例中示出了预选的PBMC。
图15A-图15B表示新鲜的抗体分离和适体分离的CD8+T细胞的流式细胞术表型和NanoString
图16A-图16H示出了由抗体分离和适体分离的细胞产生的CD19 CAR T细胞的表征。图16A表示用于对分离的T细胞进行逆转录病毒转导的具有EGFRt报告子的第二代CD19CAR T细胞构建体。图16B示出了初始珠刺激9天后(S1D9)和用经辐照的CD19+TM-LCL细胞进行快速扩增方案(REP)13天后(S1R1D13)抗体分离和适体分离的T细胞中的EGFRt表达的流式细胞术分析。细胞扩增时间线在图17中示出。图表表示S1R1D13的EGFRt报告MFI,符号如图13D-图13F。数据为平均值±s.d.,n=3,ns>0.05(双侧配对t检验)。图16C示出了珠刺激后未转导空白对照T细胞的生长。符号如图13D-图13F,n=3,ns>0.05(配对双因素ANOVA和Bonferroni校正)。曲线表示对指数增长方程的最小二乘拟合。图16D示出了在S1D14临近REP前,空白对照和CD19 CAR T细胞中Ki-67表达的流式细胞术分析。个体供体值可见于图19。符号如图13D-图13F。数据为平均值±s.d.,n=3,ns>0.05(配对双因素ANOVA和Sidak校正)。图16E示出了在S1D14临近REP前,空白对照和CD19 CAR T细胞中PD1/TIM3/LAG3表达的流式细胞术分析。饼状图示出了细胞平均表型,n=3,*P<0.05(配对双因素ANOVA和Bonferroni校正)。图16F示出了在S1D14临近REP前以及在S1R1D14临近功能测定之前,空白对照和CD19 CAR T细胞中CD62L/CD45RA表达的流式细胞术分析。个体供体值可见于图20。饼图示出了细胞平均表型,n=3,*P<0.05(配对双因素ANOVA和Bonferroni校正)。图16G-图16H示出了空白对照和CD19 CAR T细胞的体外抗肿瘤细胞毒性和细胞因子释放。对于图16H,符号如图13D-图13F。数据为平均值±s.d.,n=3,ns>0.05(图16G,配对双因素ANOVA和Bonferroni校正;图16H,配对双因素ANOVA和Sidak校正)。
图17表示CAR T细胞产生、过度生长(outgrowth)和表征的时间线。将来自三个健康供体的储存的抗体分离的CD8+T细胞和无痕的适体分离的CD8+T细胞解冻,分成两组3.3e6个细胞,并用激活珠进行刺激。刺激介导的过度生长进行两周:其中一组在第2天(S1D2)用CD19 CAR进行逆转录病毒转导,在第9天(S1D9)将珠从细胞移除并对EGFRt转导报告子进行染色,在第12天(S1D12)磁性富集EGFRt+细胞,最后在第14天(S1D14)表征细胞的分化、激活/增殖和耗竭。然后在S1D14,将来自每个样品的1.5e6个细胞置于两周快速扩增方案(REP)中,在该方案中,将它们与经辐照的饲养细胞共培养。在REP第13天(S1R1D13),通过EGFRt染色评价CAR+T细胞富集。最后,在REP第14天(S1R1D14),使用抗肿瘤细胞毒性和细胞因子释放测定对细胞进行功能表征,并对分化和基因表达进行表型表征。
图18示出了REP后未转导的空白对照和经转导的CD19 CAR T细胞的生长。符号如图15A。n=3,P>0.05(配对双因素ANOVA和Bonferroni校正)。曲线表示对指数增长方程的最小二乘拟合。
图19示出了S1D14的抗体分离和适体分离的空白对照和CD19 CAR T细胞中PD1/TIM3/LAG3表达的个体值。数据代表图16E中的饼状图。符号如图15A。数据为平均值±s.d.,n=3,P>0.05,*P<0.05和**P<0.01(配对双因素ANOVA和Bonferroni校正)。抗体分离的细胞和适体分离的细胞之间的所有其它成对比较均是P>0.999。
图20示出了S1D14和S1R1D14的抗体分离和适体分离的空白对照和CD19 CAR T细胞中CD62L/CD45RA表达的个体值。数据代表图16F中的饼状图。符号如图15A。数据为平均值±s.d.,n=3,P>0.05和*P<0.05(配对双因素ANOVA和Bonferroni校正)。
图21示出了S1R1D14的抗体分离和适体分离的空白对照和CD19 CAR T细胞的Nanostring
图22表示肿瘤抗原在用于T细胞功能研究的靶细胞系上的表达。直方图(左)表示CAR所靶向的Raji亲本、K562+CD19和K562亲本(阴性对照)细胞中的细胞外CD19表达。直方图(右)表示TCR/CD3所靶向的K562+OKT3(阳性对照)和K562亲本细胞中的细胞外OKT3 Fab表达。
图23A-图23B表示利用抗体分离和适体分离的CD8+CD19 CAR T细胞进行的肿瘤应激测试。用5×10
图24A-图24B表示适体和具有不同长度的逆转剂对以及A3逆转剂的优化。图24A示出了A1(40bp)、A3(42bp)和A8(37bp)的逆转剂序列,其中下划线示出了每种逆转剂之间的同源序列(上)。示出了选定逆转剂和适体的结合(下)。图24A按出现顺序分别公开了SEQ IDNO:49-SEQ ID NO:51。图24B示出了A3逆转剂长度的优化,其长度为从20个到85个碱基对,序列在左侧示出,结合研究则在右侧示出。图24B按出现顺序分别公开了SEQ ID NO:53-SEQID NO:59、SEQ ID NO:54、SEQ ID NO:61-SEQ ID NO:62和SEQ ID NO:55。
图25示出了用于改善逆转剂的链置换的具有8bp延伸的toehold(该toehold具有4个或6个鸟嘌呤(G))的额外的A3适体序列(上)和二级结构(下)。图25按出现顺序分别公开了SEQ ID NO:65-SEQ ID NO:66。
图26示出了用于改善链置换的具有不同鸟嘌呤量的理论截短的A3t适体。图26按出现顺序分别公开了SEQ ID NO:6、SEQ ID NO:112-SEQ ID NO:114、SEQ ID NO:7和SEQ IDNO:115-SEQ ID NO:117。
图27示出了选定适体的结合研究。适体CD3.CD28.A1显示出与PBMC中的CD3+群的优先结合。
图28示出了预测的TCBA.1二级结构(左)和结合常数(右)。将TCBA.1、TCBA.1-tr1和TCBA.1-tr2与PBMC在存在CD3和CD28抗体的情况下以0.1nM至25nM的浓度范围在4℃孵育30min。TCBA.1对于结合PBMC中的CD3+群具有1nM-2nM的kD,对CD3+CD28-具有更高的最大结合。TCBA.1-tr1以较低的亲和力结合,TCBA.1-tr2则完全不结合(数据未示出)。TCBA.1不结合H9、Jurkat、Jurkat/CD3KO和Jurkat/CD28KO细胞。图28公开了SEQ ID NO:118。
图29示出了适体TCBA.1的81个碱基对的适体序列和在4℃下的预测二级结构与平衡概率。图29公开了SEQ ID NO:64。
图30示出了与TCBA.1接触的T细胞的下拉(pulldown)测定结果。将5×10
图31示出了CD8是TCBA.1结合的受体。将CD8+T细胞激活3天,然后用NS或CD8siRNA进行核转染。24小时后进行抗CD8抗体和TCBA.1适体结合的流式细胞术研究。
图32示出了抗CD8抗体相对于TCBA.1适体的PBMC分离的比较。将PBMC与抗CD8-生物素抗体(REA734)或TCBA.1-生物素和抗生物素磁珠一起孵育,然后将其施加至MS柱。通过流式细胞术将流穿(FT)和下拉(PD)细胞针对结合CD8抗体和TCBA.1适体进行分析。TCBA.1下拉显示出比抗CD8 Ab下拉更高的CD8+细胞纯度。通过TCBA.1所下拉的85%的细胞为CD8阳性。
图33示出了基于适体的CD8+细胞分离的示意图。步骤如下:1)用生物素化适体标记PBMC混合物;2)用磁性链霉亲和素珠分离经标记的细胞;以及3)特异性释放无标记的细胞。
图34表示使用互补DNA链来逆转适体结合。与序列(上)一起示出了解毒剂(antidote)的二级结构预测(左)。在添加或不添加解毒剂的情况下,将CD8+T细胞与TCBA.1以10nM和25nM在3种不同温度下孵育。与解毒剂共孵育将结合降低了高达90%,在更高温度下更是如此。在37℃时,实现了结合的60%降低。图34按出现顺序分别公开了SEQ ID NO:8和SEQ ID NO:118。
图35示出了用10×逆转剂对CD8低(CD8
图36是进一步说明使用两种适体和逆转剂进行连续洗脱以分离两类T细胞(例如CD4
具体实施方式
本文所述的组合物和方法部分涉及以下发现:核酸适体可以选择性地结合至感兴趣的细胞(包括但不限于T细胞),并且可以用互补逆转剂可逆地去除,从而分离多种感兴趣的细胞。本文还描述了包括对核酸适体和逆转剂进行选择和表征的方法和组合物。可逆的基于适体的细胞选择使得能够进行稳健(robust)且具有成本效益的大规模细胞分离程序。此外,适体(诸如本文所述的适体)可容易地用逆转剂从细胞表面去除,这是朝向允许从单个装置进行多重细胞选择的完全合成系统的重要技术进步。本文所述的方法和组合物可增强分离以其天然形式有用的细胞的能力,或可用于对用于治疗或工业目的的细胞(例如CART细胞和CD8T细胞、树突状细胞疫苗或其它细胞疗法)进行修饰以用于治疗癌症、HIV或其它适合用细胞疗法治疗的疾病的方法中。
以下内容描述了注意事项,以促进本领域的普通技术人员进行本文所述技术的实践。
定义
本文所使用的术语“分离感兴趣的细胞”是指从包含其它细胞、细胞类型或细胞类别的样品中选择性分开或富集靶细胞、细胞类型或细胞类别,从而由此类分开所产生的细胞群具有如通过特异性细胞标志物(例如,对于CD8阳性T细胞而言为CD8)所确定的高水平的细胞纯度。
尽管相比较低水平的细胞纯度而言优选较高水平的细胞纯度,但本文所使用的术语细胞“分离”不要求所得细胞群具有100%的纯度。如果靶细胞或其群包含由本文所述的分离方法产生的靶细胞群的至少60%,并且优选地为至少70%、至少80%、至少90%或更高,则通常认为它们是如本文所使用的术语“分离的”。
“多个/多种”包含至少两个成员。在某些情况下,多个/多种可以具有至少10个、至少100个、至少1000个、至少10,000个、至少100,000个或至少1,000,000个或更多的成员。本文所使用的“多种细胞类型”是指包含具有不同细胞表面标志物或它们的组合物和/或生理功能的细胞的生物样品。
本文所使用的“对”靶细胞或细胞级分或感兴趣的群“具有特异性”的表面标志物是在靶细胞或细胞级分的表面上表达的对该靶细胞或细胞级分而言独特的多肽或其它分子,从而允许使用本文所述的方法鉴别和分离该细胞或细胞级分。在一些实施方式中,单个表面标志物足以鉴别靶细胞,例如CD8a鉴别CD8+T细胞。在其它实施方式中,两个以上的标志物可以一起鉴别靶细胞或细胞群或级分。在其它实施方式中,单个标记物可以鉴别靶细胞类别,例如CD3基本上鉴别作为一个类别的T细胞。在其它实施方式中,细胞表面标志物是膜脂质、肽、多肽或蛋白质。
在本文所述的适体或核酸的背景下使用时,本文所使用的术语“接触生物样品”是指在允许适体与细胞的细胞表面或细胞外基质上的靶部分或标志物的特异性或选择性结合的条件下,向生物样品中添加适体。
本文所使用的术语“允许形成与适体结合的细胞的条件”是指将细胞在包含0.1mg/mL tRNA、0.1g/L CaCl
本文所使用的术语“核酸”包括以下的一种或多种类型:多脱氧核糖核苷酸(含有2-脱氧-D-核糖)、多核糖核苷酸(含有D-核糖)和任何其它类型的多核苷酸,所述多核苷酸为嘌呤或嘧啶碱基或者经修饰的嘌呤或嘧啶碱基的N-糖苷(包括无碱基位点)。本文所使用的术语“核酸”还包括通常通过亚单元之间的磷酸二酯键、但在一些情况下通过硫代磷酸酯、甲基膦酸酯等而共价键合的核糖核苷或脱氧核糖核苷的聚合物。“核酸”包括单链和双链DNA以及单链和双链RNA。示例性核酸包括但不限于gDNA;hnRNA;mRNA;rRNA、tRNA、微小RNA(miRNA)、小干扰RNA(siRNA)、小核仁RNA(snORNA)、小核RNA(snRNA)和小时序RNA(smalltemporal RNA,stRNA)等以及它们的任意组合。
本文所述的“补偿性变化”是指维持适体的靶结合和/或预测的二级结构的核苷或核碱基对的变化。补偿性变化的非限制性实例包括例如在核酸的茎环结构中将G:C碱基对变化为C:G碱基对或将A:T碱基对变化为T:A碱基对。由于A:T和C:G碱基对之间氢键键合特性的差异,预期用C:G碱基对替代A:T碱基对将改变二级结构的稳定性,即增加其稳定性。因此,本文所述的补偿性变化可以进一步包括此类变化。在考虑之列的是,从C:G或G:C碱基对到A:T或T:A碱基对的变化有时可以被容许而不显著影响二级结构或靶结合特性。但是,应在适体的总体茎稳定性的背景下考虑这种补偿性变化。如本文所述,适体核苷酸序列中的补偿性变化可适当涉及选自但不限于表1中所述的核碱基或核苷的经修饰核苷。
本文所使用的术语“多肽”旨在涵盖单数“多肽”以及复数“多肽”,并且包括两个以上的氨基酸的任何链。因此,本文所使用的包括但不限于“肽”、“二肽”、“三肽”、“蛋白质”、“酶”、“氨基酸链”和“连续氨基酸序列”的术语全都涵盖于“多肽”的定义中,并且可以使用“多肽”代替这些术语中的任何一个或与它们互换使用。该术语进一步包括经历一种或多种翻译后修饰的多肽,所述翻译后修饰包括但不限于糖基化、乙酰化、磷酸化、酰胺化、衍生化、蛋白水解切割、翻译后加工或通过包含一种或多种非天然存在的氨基酸进行的修饰。本领域存在用于多核苷酸和多肽结构的常规命名法。例如,单字母和三字母缩写被广泛用于描述氨基酸:丙氨酸(A;Ala)、精氨酸(R;Arg)、天冬酰胺(N;Asn)、天冬氨酸(D;Asp)、半胱氨酸(C;Cys)、谷氨酰胺(Q;Gln)、谷氨酸(E;Glu)、甘氨酸(G;Gly)、组氨酸(H;His)、异亮氨酸(I;Ile)、亮氨酸(L;Leu)、甲硫氨酸(M;Met)、苯丙氨酸(F;Phe)、脯氨酸(P;Pro)、丝氨酸(S;Ser)、苏氨酸(T;Thr)、色氨酸(W;Trp)、酪氨酸(Y;Tyr)、缬氨酸(V;Val)和赖氨酸(K;Lys)。本文所述的氨基酸残基优选为“L”异构形式。但是,只要保留了多肽的期望特性,“D”异构形式的残基可以代替任何L-氨基酸残基。
本文所述的“固体支持物”是可以在其上陈列一种或多种适体以与靶细胞接触的结构。固体支持物提供了从混合物或悬浮液中分离或去除结合的靶细胞的现成手段。固体支持物可以是例如颗粒、珠、滤器或片、树脂、支架、基质或柱的形式。固体支持物可以包括的材料的非限制性类别包括聚合物、金属、陶瓷、凝胶、纸或玻璃。该材料可以包括但不限于聚苯乙烯、琼脂糖、明胶、氧化铁、不锈钢、聚碳酸酯、聚二甲基硅氧烷、聚乙烯、丙烯腈丁二烯苯乙烯、环烯烃聚合物和环烯烃共聚物。
本文所述的“相变剂”是在一组条件下可溶于水性溶液但在另一组条件下诱导成不可溶的沉淀形式的试剂。可溶和不可溶形式这二者的条件都必须与维持靶细胞的活力相容。改变相的条件的非限制性实例包括温度、pH和盐或溶质浓度。相变剂的实例包括聚(N-异丙基丙烯酰胺)相变聚合物,其在一个温度下可溶,然后在不同温度下从溶液中沉淀出。
本文所使用的术语“亲和对”是指通常以低的微摩尔至皮摩尔范围以高亲和力彼此特异性结合的部分的对。当亲和对中的一个成员缀合至第一元件,而该对中的另一成员缀合至第二元件时,第一元件和第二元件将通过亲和对成员的相互作用而聚集在一起。可以缀合至适体或固体支持物的亲和对的非限制性实例包括配体-受体对、抗体-抗原对以及较小的对(如生物素-亲和素或生物素-亲和素变体,例如尤其是生物素-链霉亲和素或生物素-中性亲和素等)。仅作为一个实例,生物素-链霉亲和素相互作用具有10
本文所使用的术语“缀合至”包括通过共价键合(包括但不限于通过交联剂进行交联)或通过强的非共价相互作用(其在待使用缀合物的条件下得以保持)将适体与固体支持体、相变剂或亲和对的成员缔合。
本文所使用的术语“杂交”是指单链核酸或其区域与另一单链核酸或其区域(分子间杂交)或与同一核酸的另一单链区域(分子内杂交)形成氢键键合碱基对相互作用的现象。逆转剂与适体之间的杂交使得能通过使适体的二级结构去稳定来破坏适体与靶标的结合,从而实现可逆细胞选择。杂交由涉及的碱基序列控制,互补的核碱基形成氢键,而任何杂交物的稳定性由碱基对的类型(例如,G:C碱基对强于A:T碱基对)和连续碱基对的数量确定,较长的互补碱基串形成更稳定的杂交物。
本文所使用的“磁响应珠”是指可被吸引至磁性装置或磁场的固体支持物颗粒。包被有适体或以其它方式缀合至适体的磁响应珠可用于将与适体结合的细胞从生物样品中分开。尽管术语“珠”推断为球形,但这并不是对可用于将与适体结合的细胞与未与适体结合的细胞分开的磁响应性固体支持物的形状的限制。形状可以是不规则的,或者可以是球形、椭圆形、立方体等的一些变型。在各种实施方式中,磁响应珠可以例如通过交联反应而共价缀合至适体,或者可以例如通过亲和对成员的相互作用而非共价地缀合。
本文所使用的术语“表达”是指基于基因的核酸序列产生多肽的过程。该过程包括转录和翻译二者。
本文所使用的“细胞级分”是指样品群中共享给定特征(例如某种标志物或标志物组的表达)的细胞亚群。靶向的细胞级分可以包含多于一种细胞类型;仅作为一个实例,当T细胞是细胞级分时,该级分可以包含例如CD4+T细胞和CD8+T细胞等。在一些实施方式中,靶向的细胞级分包含单一细胞类型。像其它细胞一样,T细胞可以通过分化簇(CD)标志物或趋化因子受体(CCR)来鉴别。T细胞标志物的非限制性实例包括CD8、CD19、CD4、CD3、CD28、CD45、CD62、CD31、CD27或CCR-7。
本文所使用的术语“特异性结合细胞表面标志物”是指在保持哺乳动物细胞的活力的条件下,本文所述的适体与给定靶细胞或其上的细胞表面标志物结合的能力,使得适体结合给定靶细胞表面标志物的程度比结合其它标志物或不表达给定标志物的其它细胞的程度显著更高。至少,特异性结合细胞表面标志物的适体以1微摩尔以下的Kd结合该标志物,并以比结合无关细胞表面标志物至少高100×的亲和力结合靶标志物。
本文所使用的术语“小分子”是指可以包括但不限于以下的化学试剂:肽、拟肽、氨基酸、氨基酸类似物、多核苷酸、多核苷酸类似物、适体、核苷酸、核苷酸类似物或具有小于约10,000克每摩尔的分子量的有机或无机化合物(例如包括杂有机化合物和有机金属化合物)、具有小于约5,000克每摩尔的分子量的有机或无机化合物、具有小于约1,000克每摩尔的分子量的有机或无机化合物、具有小于约500克每摩尔的分子量的有机或无机化合物以及此类化合物的盐、酯和其它形式,其在有效将适体从细胞上的细胞表面标志物释放的逆转剂浓度下与细胞活力相容。
本文所定义的“流式细胞术”是指通过将显微颗粒(例如细胞和染色体)悬浮在流体流中并使它们通过电子检测装置来对显微颗粒进行计数和检查的技术。流式细胞术允许每秒对多达数千个颗粒的物理参数和/或化学参数(例如荧光参数)进行同时多参数分析。现代流式细胞仪通常具有多个激光器和荧光检测器。激光器和检测器数量的增加允许使用多种抗体进行标记,并可以通过其表型标志物更精确地鉴别靶标群。某些流式细胞仪可以拍摄单个细胞的数字图像,使得能够在细胞内或细胞表面上进行荧光信号位置的分析。
本文所使用的术语“免疫疗法”是指通过对受试者的免疫系统进行刺激、诱导、颠覆(subversion)、模仿、增强(enhancement)、增进(augmentation)或任何其它调节以引发或增强针对癌性或其它有害的蛋白质、细胞或组织的适应性或先天免疫力(主动或被动地)来治疗疾病。免疫疗法(即免疫治疗剂)包括癌症疫苗、免疫调节剂、“基于抗体的免疫疗法”或单克隆抗体(例如人源化单克隆抗体)、免疫刺激剂、基于细胞的疗法(例如过继T细胞疗法或树突状细胞免疫疗法或树突状细胞疫苗)和病毒疗法,无论是设计用来治疗现有的癌症或预防癌症的发展,还是用于设定为减少癌症复发的可能性的佐剂中。
本文所使用的术语“toehold”描述了被设计为单链并且与逆转剂的区域互补的适体的5-15个碱基对的突出(overhang)区域。toehold的互补性质使逆转剂能够容易地杂交至单链区,并促进与适体的相邻双链区互补的逆转剂剩余部分在相邻的双链区引发链置换。因此,通常将toehold设计或选择为与希望破坏或置换的双链序列区域相邻,所述双链序列区域通常是适体中的茎结构。toehold为逆转剂启动杂交和链置换提供了动力学优势,从而有效地破坏适体与其细胞表面标志物靶标的结合。一旦发现适体结合期望的靶标,通常(但并非必须)将toehold添加到该适体。作为替代,适体文库的每个成员可以例如在一端或另一端具有相同的序列,该序列将充当toehold。因此,在结构预测下并未碱基配对的适体的内部区域可以充当toehold序列。toehold可以包含例如相对较高的GC含量,从而相对于具有较低GC含量的序列,提供用于与其互补物杂交的链置换速率常数(stranddisplacement rate constant)的改善。
本文所使用的术语“包括/包含/含有(comprising/comprises)”是指对所要求保护的技术而言必需的组合物、方法及它们各自的组成部分,但仍对未指定的要素(无论是否必需)的纳入保持开放。
本文所使用的术语“基本上由……组成(consisting essentially of)”是指给定实施方式所需的那些要素。该术语允许存在并不实质上影响本发明的该实施方式的基本的和新的或功能性的特征的额外要素。
术语“由……组成(consisting of)”是指本文所述的组合物、方法及它们各自的组成部分,其排除在该实施方式的描述中未列举的任何要素。
除非上下文另外明确规定,否则本说明书和所附权利要求书中所使使用的单数形式“一个/一种(a/an)”和“该/所述(the)”包括复数指代物。因此,例如,对“该方法/所述方法”的引用包括本文所述的一种或多种方法和/或步骤的类型和/或在阅读本公开内容等之后对于本领域技术人员而言将变得显而易见的那些内容。
核酸适体组合物
核酸适体是能够结合靶分子的单链寡核苷酸,是用于细胞选择的抗体的有吸引力的替代物。适体可以具有与抗体相当甚至更高的结合亲和力。重要的是,适体是合成产生的具有长期存储稳定性的定义明确、低变异性的产品。适体可以通过称为指数富集的配体系统进化(SELEX)的文库选择方法而发现,并可针对化学稳定性进一步优化。凭借其良好的特性,适体的应用领域在近25年中持续扩大,涵盖了包括传感、纯化、诊断、药物递送和治疗学的领域。
核酸适体包括能够特异性结合靶分子的RNA、DNA和/或合成的核酸类似物(例如PNA)。适体是用于细胞选择的抗体的有吸引力的替代物,因为它们对细胞表面标志物具有高水平的特异性和亲和力。合成适体由Szostak和Gold小组于20世纪90年代首次开发,并且发现适体可以具有与抗体相当甚至更高的结合亲和力。
本文提供了产生用于细胞选择的功能性核酸适体的方法和组合物。核酸适体的组成可以包括但不限于表1(如下)中所述的核碱基,并且可以包含DNA、RNA或合成的核酸类似物(例如PNA或BNA)的骨架或核碱基结构的一种或多种组合。
适体通常由相对较短的寡核苷酸组成,其长度范围通常为20个至80个核苷酸,例如至少20个核苷酸、至少30个核苷酸、至少40个核苷酸、至少50个核苷酸、至少60个核苷酸、至少70个核苷酸、至少80个核苷酸或更多。适体可以例如在适体的一端或另一端附着至更长的序列,不过,影响适体二级结构的附加序列可能会影响适体功能。
适体的功能活性(即结合至给定靶分子)涉及适体中的部分或元件与靶分子上的部分或元件之间的相互作用。相互作用可包括例如疏水/亲水相互作用、电荷或静电相互作用、氢键键合等,并且给定适体与给定靶标的特异性相互作用由适体的序列以及在结合条件下由该序列推定的二级和三级结构确定。因此,适体中分子内碱基配对的出现是适体结构以及由此的适体功能的首要因素。分子内碱基配对可以产生例如双链茎结构、茎环结构和可参与与靶分子的结合相互作用的适体的各种元件的暴露。如果适体的二级结构由其序列所定义(包括在互补序列区域之间存在分子内碱基对,其将分子折叠成功能性形状),则应理解在茎结构中发生的适体序列变化或引入分子内碱基配对的新选择的适体序列变化可以破坏分子的构象,从而破坏其功能。就是说,当碱基配对的茎结构中的一个核苷酸的变化伴随着保持碱基配对的能力的互补核苷酸的补偿性变化时,适体结构和由此的适体功能可以得以维持。也就是说,一些适体可以耐受一定程度的序列变化并且仍然保留结合活性。此外,本文所述的适体的截短序列或部分序列也可以保留结合活性,如果该截短不改变适体二级结构所必需的分子内碱基配对。特别地,在考虑之列的是,从本文所述适体的5'或3'末端去除一些序列可以产生保留结合活性的适体分子。实际上,一些变化可以改善结合活性。当然,这是用于鉴定结合给定靶标并以高亲和力结合给定靶标的适体的迭代选择方法的一个基础。本文的实施例提供了特异性结合给定靶标的适体选择的工作示范。
如本文所述,适体可额外地或可替代地包含核碱基(在本领域中通常简称为“碱基”)修饰或置换。此类置换可以例如通过降低对酶促降解或化学降解的敏感性来修饰适体或逆转剂的稳定性,或者可以修饰(提高或降低)分子内或分子间相互作用(包括但不限于碱基配对相互作用)。适体和逆转剂核碱基包括嘌呤碱基腺嘌呤(A)和鸟嘌呤(G);以及嘧啶碱基胸腺嘧啶(T)、胞嘧啶(C)和尿嘧啶(U);或它们的经修饰的或相关的形式。作为非限制性实例,经修饰的核碱基包括其它合成和天然的核碱基,例如:5-甲基胞嘧啶(5-me-C);5-羟甲基胞嘧啶;黄嘌呤;次黄嘌呤;2-氨基腺嘌呤;腺嘌呤和鸟嘌呤的6-甲基衍生物和其它烷基衍生物;腺嘌呤和鸟嘌呤的2-丙基衍生物和其它烷基衍生物;2-硫尿嘧啶、2-硫胸腺嘧啶和2-硫胞嘧啶;5-卤代尿嘧啶和5-卤代胞嘧啶;5-丙炔基尿嘧啶和5-丙炔基胞嘧啶;6-偶氮尿嘧啶、6-偶氮胞嘧啶和6-偶氮胸腺嘧啶;5-尿嘧啶(假尿嘧啶);4-硫尿嘧啶;8-卤代、8-氨基、8-硫醇、8-硫代烷基、8-羟基和其它8-取代的腺嘌呤和鸟嘌呤;5-卤代(特别是5-溴)、5-三氟甲基和其它5-取代的尿嘧啶和胞嘧啶;7-甲基鸟嘌呤和7-甲基腺嘌呤;8-氮杂鸟嘌呤和8-氮杂腺嘌呤;7-脱氮鸟嘌呤和7-脱氮腺嘌呤;以及3-脱氮鸟嘌呤和3-脱氮腺嘌呤等。这些核碱基的碱基配对行为和偏好是本领域已知的。
构成适体的合成寡核苷酸可包括但不限于肽核酸(PNA)、桥接核酸(bridgednucleic acid,BNA)、吗啉代(morpholinos)、锁核酸(LNA)、乙二醇核酸(glycol nucleicacids,GNA)、苏糖核酸(TNA)或本领域描述的任何其它非天然核酸(xeno nucleic acid,XNA)。
一种已显示具有优异的杂交特性的此类寡核苷酸(寡核苷酸模拟物)被称为肽核酸(PNA)。在PNA化合物中,寡核苷酸的糖-骨架被含酰胺的骨架、特别是氨基乙基甘氨酸骨架取代。核碱基被保留并且直接或间接结合到骨架的酰胺部分的原子上。
核酸适体二级结构和细胞靶向
本文所述的适体具有折叠成与特定靶标相互作用的2维(2D)和3维(3D)结构的能力。适体通常通过与靶细胞表面标志物的非共价相互作用与特定靶标结合,所述非共价相互作用包括但不限于静电相互作用、疏水相互作用和/或它们的互补形状(complementaryshapes)。
本领域技术人员将理解,可以通过数种方法中的任一种来预测适体2-D和3-D结构以定义诸如平衡概率和稳定性的性质。NUPACK网络应用程序可用于生成适体序列的预测二级结构
不同的结构预测模型可以产生不同预测结构,甚至如果使用不同的基线参数(例如温度、离子强度等),同一模型也可以产生不同预测结构。
在考虑之列的是,实施例中描述的适体的反向、互补、反向互补或截短的序列可用于细胞分离,因为在考虑之列的是这些序列将维持适体的二级结构。这些序列在例如SEQID NO:9-SEQ ID NO:63中描述。此外,适体文库可以包括45个核苷酸的文库,其可以允许额外适体的选择,例如SEQ ID NO:64的适体的选择。额外的修饰可以包括例如向适体添加toehold序列——在SEQ ID NO:65-SEQ ID NO:66中提供了包含具有不同鸟嘌呤数量的toehold的实例。
对于任何给定的二级结构预测模型,当基于预测的结构进行修饰(例如补偿性或非补偿性变化)时,适体与其靶标的结合的维持或改善应通过实验进行测试。
在本文所述的细胞选择方法之前,适体的靶标可能已知或也可能未知。感兴趣的细胞的已知表面受体可用于靶向细胞的特定级分。SEQ ID NO:67-SEQ ID NO:77中描述了其它细胞特异性适体序列(例如,对CD4+细胞具有特异性)的实例。
使用本文所述的方法,核酸适体也可以靶向淋巴细胞和白细胞以外的其它细胞类型。在考虑之列的是,适体的细胞表面靶标可以包括但不限于膜脂质、肽、多肽或细胞基质蛋白或细胞外基质蛋白。进一步在本文考虑之列的是,如本文所述,可以使用适体和逆转剂来分离生物样品的其它组分,包括表面暴露的标志物(例如外泌体、囊泡等)。
在一个实施方式中,膜脂质是磷脂、鞘脂、固醇、糖脂、脂肪酸或磷酸甘油酯。
除了已知的细胞表面标志物之外,还可以对细胞表面标志物进行遗传修饰,以用于在细胞群或细胞混合物内对感兴趣的细胞的特定突变或变体进行细胞选择。如实施例1中所详述的,本文所述的适体可用于靶向经遗传修饰的细胞。
在一个实施方式中,适体靶向细胞表面受体或抗原。T细胞的细胞表面标志物的非限制性实例包括T细胞受体(TCR)、分化簇(CD)抗原标志物或趋化因子受体(CCR)。B细胞的细胞表面标志物的非限制性实例包括分化簇(CD)标志物(例如19或20)和主要组织相容性复合物(MHC)分子。
在一个实施方式中,细胞表面标志物包括分化簇抗原,例如CD2、CD3、CD4、CD5、CD7、CD8、CD9、CD10、CD11、CD13、CD15、CD16、CD18、CD19、CD20、CD21、CD22、CD23、CD24、CD25、CD27、CD28、CD31、CD33、CD34、CD36、CD37、CD38、CD 40、CD41、CD42、CD44、CD45、CD45RA、CD45RO、CD52、CD54、CD56、CD57、CD60、CD61、CD62L、CD64、CD71、CD79、CD80、CD83、CD90、CD95、CD103、CD117、CD122、CD127、CD133、CD134、CD137、CD138或CD152、CD154、CD272、CD276和CD278等。
在一些实施方式中,细胞表面标志物是免疫检查点调节剂。此类细胞表面标志物的实例包括但不限于CTLA4、程序性死亡因子1(PD-1)、腺苷A2A受体、VTCN1、杀伤细胞免疫球蛋白样受体(KIR)、T细胞免疫球蛋白结构域和粘蛋白结构域3(TIM-3)、具有Ig和ITIM结构域的T细胞免疫受体(TIGIT)和T细胞激活的V结构域Ig抑制因子(VISTA)等。
在一个实施方式中,细胞表面标志物包括G蛋白偶联受体(GPCR),也称为七跨膜受体或7TM受体。例如,所述受体可以包括毒蕈碱型乙酰胆碱受体、腺苷受体、肾上腺素能受体、GABA-B受体、血管紧张素受体、大麻素受体、胆囊收缩素受体、多巴胺受体、胰高血糖素受体、组胺受体、嗅觉受体、阿片受体(opioid receptor)、视紫红质受体(rhodopsinreceptor)、促胰泌素受体(secretin receptor)、血清素受体或生长抑素受体。
在一个实施方式中,细胞表面标志物是生长因子受体,例如ErbB或表皮生长因子受体(EGFR)家族的成员,例如EGFR(ErbB1)、HER2(ErbB2)、HER3(ErbB3)和HER4(ErbB4)。
在一个实施方式中,细胞表面标志物包括但不限于酪氨酸激酶受体,例如促红细胞生成素受体、胰岛素受体、激素受体或细胞因子受体。优选的酪氨酸激酶包括成纤维细胞生长因子(FGF)受体、血小板衍生生长因子(PDGF)受体、神经生长因子(NGF)受体、脑源性神经营养因子(BDNF)受体和神经营养因子-3(NT-3)受体和神经营养因子-4(NT-4)受体。受体可以包括鸟苷酰基环化酶受体,例如GC-A&GC-B(心房利钠肽(ANP)和其它利钠肽的受体)或GC-C(鸟苷蛋白受体)。
在一个实施方式中,细胞表面标志物是离子通道(例如Na
在一个实施方式中,细胞表面标志物与疾病(优选人或动物的疾病)相关。例如,标记物可以与癌症(例如乳腺癌或卵巢癌)相关。合适的癌细胞标志物可以包括上述受体或CD抗原或另外的癌细胞特异性标志物,例如CA-125(MUC-16)或CA19-9。多种肿瘤抗原是本领域已知的。
对于本文所述的任何细胞表面标志物,可以将细胞指定为“阳性”或“高”,“暗(dim)”或“低”或“阴性”,并且这种指定对本文所述的细胞分离方法和测定的实践而言有用。如果细胞以使用本领域技术人员已知的方法(所述方法例如为将细胞与特异性结合标志物的抗体或适体接触,并随后对此类经接触的细胞进行流式细胞术分析以确定抗体是否与细胞结合)足以检测到的量在其细胞表面表达该标志物,则认为该细胞对该细胞表面标志物呈“阳性”。应当理解,尽管细胞可以表达细胞表面标志物的信使RNA,但是为了就本文所述的测定和方法而言被认为呈阳性,细胞必须在其表面上表达它。如果细胞以使用本领域技术人员已知的方法(所述方法例如为将细胞与特异性结合标志物的抗体接触,并随后对此类经接触的细胞进行流式细胞术分析以确定抗体是否与细胞结合)足以检测到的量在其细胞表面表达该标志物,但存在以更高水平表达该标志物的另一不同的细胞群,使得产生当使用例如流式细胞术进行分析时可被区分的至少两个群,则认为该细胞对该细胞表面标志物呈“暗”或“低”。类似地,如果细胞未以使用本领域技术人员已知的方法(所述方法例如为将细胞与特异性结合标志物的抗体接触,并随后对此类经接触的细胞进行流式细胞术分析以确定抗体是否与细胞结合)足以检测到的量在其细胞表面表达该标志物,则认为该细胞对该细胞表面标志物呈“阴性”。
核酸适体合成与修饰
作为非限制性实例,可以使用核苷亚磷酰胺方法化学合成本文所述的适体。此外,可以通过DNA或RNA提取方法从生物样品中分离适体。这些方法包括但不限于柱纯化、乙醇沉淀、酚-氯仿提取或者酸性硫氰酸胍-酚氯仿提取(AGPC)。
在提取或合成之后,本文所述的适体可以通过液相色谱法、质谱法、下一代测序、聚合酶链式反应(PCR)、凝胶电泳或者鉴别核苷序列、二级结构、化学组成、表达、热力学、结合或功能的任何其它方法进行表征。如实施例中所述,通过细胞-SELEX鉴别的适体可以进一步通过适体细胞结合测定、流式细胞术或体内功能进行表征。
本文所述的适体也可以被修饰或缀合至固体支持物或相变剂以用于细胞选择和细胞加工。缀合方法的非限制性实例包括对适体的化学修饰、热力学修饰或结构修饰,其允许将与适体结合的细胞与未与适体结合的细胞或生物样品分开。
在某些实施方式中,本文所述的适体可以被标记。标记的非限制性实例可以包括例如荧光团和/或亲和对的成员。可以缀合至适体的亲和对的非限制性实例包括例如生物素:亲和素、生物素:链霉亲和素、生物素:中性亲和素(或结合生物素的亲和素的其它变体)。
固体支持物
在某些实施方式中,适体直接或间接结合至固体支持物。
本文所述的与适体结合的固体支持物可以以平台、柱、滤器或片、皿(dish)、微流体捕获装置、毛细管、电化学响应平台、支架、药筒(cartridge)、树脂、基质、珠或本领域已知的其它固体支持物的形式存在。
在一些实施方式中,固体支持物包含的材料包括但不限于聚合物、金属、陶瓷、凝胶、纸或玻璃。作为非限制性实例,固体支持物的材料还可包括聚苯乙烯、琼脂糖、明胶、藻酸盐、氧化铁、不锈钢、金纳米珠或颗粒、铜、氯化银、聚碳酸酯、聚二甲基硅氧烷、聚乙烯、丙烯腈丁二烯苯乙烯、环烯烃聚合物或环烯烃共聚物或Sepharose
与适体结合的固体支持物可以进一步包括磁响应元件,例如磁响应珠。在一些实施方式中,磁响应元件或珠处于球体、立方体、矩形、圆柱体、圆锥体或本领域描述的任何其它形状的形式。与磁响应珠结合的适体提供了通过允许细胞悬浮液与缀合有适体的珠相互作用,然后使样品经受磁场来将与适体结合的细胞与未结合的细胞分开的简单方法。带有与适体结合的细胞的珠被吸引到磁源,从而允许例如通过移液管去除未结合的细胞。带有结合的细胞的珠可以被洗涤并再次经受磁场以增加分离的细胞级分的相对纯度。
在一些实施方式中,磁响应元件包括磁铁矿、氧化铁(III)、钐-钴、terfenol-D或本领域描述的任何其它磁性元件。
在一些实施方式中,固体支持物与细胞外基质蛋白或组分接触。非限制性实例包括纤连蛋白、胶原蛋白、层粘连蛋白、聚L-赖氨酸、Matrigel
在替代实施方式中,可以使用相变剂代替固体支持物。相变剂可以在给定的条件组下改变相或沉淀,从而可以促进与适体结合的细胞与未与适体结合的细胞分开。
在一些实施方式中,相变剂可以结合至适体。例如,相变剂可以在一组条件下可溶于水性溶液但在另一组条件下诱导成不可溶的沉淀形式。可诱导相变的其它示例性条件包括温度、pH、盐或溶质浓度、光(例如紫外线或荧光)或机械力。例如,聚(N-异丙基丙烯酰胺)是在一个温度下可溶、然后在不同的温度下从溶液中沉淀出的相变聚合物。还在考虑之列的是,相变剂可以通过与被紫外线激活的核黄素相似的方式起作用。
与适体结合的固体支持物也可以包含标记。在一些实施方式中,标记是异源蛋白。在一些实施方式中,异源蛋白是标签,例如荧光蛋白。此类蛋白质可以促进适体的追踪和/或可视化。荧光蛋白的实例包括但不限于:来自水母Aequorea victoria的绿色荧光蛋白(GFP);发出不同颜色荧光的GFP突变体形式(例如BFP,蓝色荧光蛋白;YFP,黄色荧光蛋白;以及CFP,青色荧光蛋白);dsRed荧光蛋白(dsRed2FP);eqFP611,分离自奶嘴海葵(Entacmaea quadricolor)的红色荧光蛋白;AmCyan1,分离自Anemonia majano的青色荧光蛋白,最初名为amFP486;Azami Green,分离自Galaxeidae的明亮荧光蛋白;ZSGREEN
核酸适体SELEX文库选择
适体可以通过称为SELEX(指数富集的配体系统进化)的文库选择方法而发现,并可针对化学稳定性进一步优化。凭借其良好的特性,适体的应用领域在近25年中持续扩大,涵盖了包括传感、纯化、诊断、药物递送和治疗学的领域。
为了使用传统的蛋白质-SELEX开发针对特定疾病的膜蛋白适体,需要蛋白质靶标的先验知识。但是,由于翻译后修饰或翻译后修饰的缺乏,在原核或某些真核系统中表达的膜蛋白经常无法折叠成在生理条件下形成的正确3D结构。这导致由体外表达系统所表达的膜蛋白的低溶解度和低产率,这限制了它们的应用。
细胞-SELEX克服了获得纯化重组膜蛋白中存在的困难。在细胞SELEX中,针对细胞表面上的分子而开发适体,无需分子靶标的先验知识。因此,在选择之前也不需要蛋白质纯化。
以下描述了提供强结果的适体细胞SELEX方法的实施方式。整个过程都记录受到改变的参数。细胞-SELEX的主要步骤与传统SELEX相似,包括孵育、划分和扩增步骤。细胞-SELEX的方案由Sefah等修改而来,示意图根据如实施例1中详细描述的本文所述的方法在图1中强调。
本文所述的细胞SELEX过程中使用的ssDNA文库可以通过高效液相色谱法(HPLC)纯化。尽管可以选择其它长度的适体,但是在一个实施方式中,ssDNA文库可以包括侧翼为两个18个碱基对(bp)恒定区的52bp的随机序列。在一些实施方式中,如本文所述的用于鉴别适体的文库的ssDNA随机序列可包含20个碱基对以上、25个碱基对以上、30个碱基对以上、35个碱基对以上、40个碱基对以上、45个碱基对以上、50个碱基对以上、55个碱基对以上、60个碱基对以上、65个碱基对以上、70个碱基对以上、75个碱基对以上、80个碱基对以上、85个碱基对以上、90个碱基对以上、95个碱基对以上或100个碱基对以上以及更多个碱基对。本文还描述了选自45个碱基对文库的适体的实例。
在一些实施方式中,ssDNA文库可以是RNA文库。因此,可变大小和不同核酸二者均可产生对细胞选择有用的适体结果。
还在考虑之列的是,如本文所述的细胞-SELEX ssDNA或RNA文库的18bp恒定区可包含5bp以上、10bp以上、20bp以上、30bp以上、40bp以上、50bp以上以及更多个碱基对。
带有集成DNA技术(IDT)修饰代码的用于SELEX轮次之间的文库扩增的引物可以是例如正向5’-/56-FAM/ATCCAGAGTGACGCAGCA-3’(SEQ ID NO:105)和反向5’-/5BiosG/ACTAAGCCACCGTGTCCA-3’(SEQ ID NO:106)。也可以生成并使用其它引物序列而无需过度实验。表5中列出了分别合成的ssDNA适体的实例。
IDT代码FAM被定义为与大多数荧光检测设备兼容的寡核苷酸的荧光染料附着物。它在低于pH 7时变为质子化,并且具有降低的荧光;它通常在7.5-8.5的pH范围内使用。FAM可以附着至寡核苷酸的5'或3'末端。IDT代码5BiosG被定义为生物素附着物。
在一些实施方式中,适体缀合至本文所述的另一标记或蛋白质。
表2中强调了通过细胞-SELEX的适体选择的示例性条件。
第1轮可以进行非严格正选择(non-stringent positive selection),其中将耗竭了死细胞的已知的感兴趣的细胞(其可包括T细胞)例如与40纳摩尔ssDNA文库(~10
在第1轮的正细胞-SELEX中,感兴趣的细胞可以来自任何生物样品,包括但不限于干细胞、癌细胞、白细胞、淋巴细胞、T细胞或表达CD8的细胞、自然杀伤细胞、树突状细胞、CD8+T细胞、CD3+T细胞、CD2+T细胞、CD4+T细胞或CD28+T细胞或任何其它类型的T细胞,例如记忆T细胞、细胞毒性杀伤T细胞、辅助性T细胞、效应T细胞、调节性T细胞(T
如果可以例如通过胶原酶或者其它酶处理或物理处理使实体组织的细胞解离,则感兴趣的细胞可以来自任何其它器官或系统(包括脑、心脏、皮肤、骨、肺、胃肠道、肝、骨骼肌、神经系统、循环系统、胰腺、生殖器官、眼、耳、内分泌系统)或本领域已知的任何其它生物样品。
第1轮中的生物样品可以来自人或任何其它感兴趣的动物物种。生物样品可以包括细胞的组合,包括本文所述的任何细胞类型的组合。
在一些实施方式中,用于第1轮的正选择的细胞数量包括1×10
尽管各种参数(如温度、离子强度等)可影响适体结合特性,但应记住适体必须在维持细胞活力的条件下结合。温度、离子强度等应仅在活细胞或可解冻并在细胞选择后变为活细胞的细胞所容许的范围内变化。
对于细胞-SELEX第2轮至第5轮,可以将由先前轮次产生的经富集和扩增的ssDNA池与耗竭了死细胞的来自感兴趣的生物样品的细胞混合物(例如外周血单个核细胞,也称为PBMC)一起孵育,这是称为“竞争性选择”的处理步骤。尽管在实施例2中描述了5轮的细胞-SELEX,通常两轮以上即可为有益的,例如三轮、四轮、五轮或更多。
在一些实施方式中,生物样品包括全血、血沉棕黄层或分离的单个核细胞。
在一些实施方式中,生物样品可包含来自组织的细胞,所述组织包括但不限于肌肉、平滑肌(例如血管平滑肌、细支气管等)、心肌、骨髓、软骨、胃肠器官、眼、耳、生殖器官、肾、胰腺、肝、皮肤或本领域已知的任何其它器官。
在例如三次洗涤后,可以使用可商购的细胞分离试剂盒或抗体提取方法来富集期望的细胞亚群和结合的ssDNA序列。感兴趣的细胞(例如T细胞)可以通过煮沸裂解,并可以在澄清的上清液中提取ssDNA序列。
可以将ssDNA池与例如1×10
在一些实施方式中,缺乏感兴趣的细胞表面标志物的负选择细胞的数量可以达到1×10
在一些实施方式中,用于随后轮次的负细胞-SELEX的孵育时间可以包括5分钟以上、10分钟以上、20分钟以上、30分钟以上、60分钟以上、90分钟以上或120分钟以上。
在轮次之间,可以使用例如0.02U/微升(μL)Phusion高保真DNA聚合酶(NEB)、1×Phusion GC缓冲液、500nM本文所述的正向和反向引物二者以及200μM dNTP通过PCR(98℃下10s,56℃下30s,72℃下30s)扩增剩余的ssDNA序列。可以在使用200微升(μL)ssDNA的2毫升(mL)大制备PCR反应之前进行使用10微升(μL)ssDNA的100微升(μL)小分析PCR反应和2%琼脂糖凝胶电泳,以确定大的非特异性扩增子出现之前的最佳循环数。用高容量中性亲和素琼脂糖树脂、1摩尔(M)NaOH和脱盐illustra NAP-5柱(GE)产生用于随后轮次的SELEX和流式细胞术轮次结合测定二者的FAM标记的ssDNA。ssDNA的量可以通过例如NanoDrop2000c分光光度法(Thermo Scientific)进行定量,并可以通过例如Savant ISS110SpeedVac干燥(Thermo Scientific)进行浓缩。可以对本文所述的方法进行修饰以包括不同浓度的PCR试剂。
在所有SELEX轮次和结合测定中使用的洗涤缓冲液配方可以是0.22微米(μm)过滤的500毫升(mL)含钙和镁的磷酸盐缓冲溶液(Corning),其补充有2.25克葡萄糖(以达到终浓度25毫摩尔(mM))和2.5mL的1摩尔(M)氯化镁(MgCl
除了本文所述的细胞-SELEX方法之外,还在考虑之列的是,适体选择也可以用其它方法进行,例如由Ouellet等,Biotechnol Bioeng(2015)描述的高保真(Hi-Fi)SELEX方法等。
可以使用下一代测序以及适体寡核苷酸鉴别的其它方法。
在根据制造商说明使用MiSeq Reagent Kit v2(300个循环)和MiSeq系统(Illumina)测序后,可以用例如在表2中列出的条形码引物(barcoded primers)PCR扩增起始原初文库和来自每个SELEX轮次的ssDNA池。导出的FASTA文件可以用FASTAptamer软件进行分析。具体而言,可以使用FASTAptamer-Count来确定每个序列的排名和每百万读段(RPM),在此之后,然后可以使用FASTAptamer-Compare来进行相邻轮次之间序列的RPM的成对比较,并由此计算富集倍数(表4)。可以通过FigTree软件(tree.bio.ed.ac.uk/software/figtree/)(用于系统进化树生成)和MEME Suite软件(用于基序预测)二者进一步分析来自竞争性细胞-SELEX第2-4轮的前100个序列。可以根据需要使用额外的竞争性细胞-SELEX轮次来分离能够实现期望的细胞产物的分离的适体。
用于可逆细胞选择的逆转剂
逆转剂包括破坏适体结构并由此引起适体所结合的细胞或分子的释放的分子,或与适体结合从而降低细胞结合亲和力的分子。在一些实施方式中,逆转剂对共享给定序列基序或结构的一种或有限数量的适体具有特异性;而在其它实施方式中,逆转剂非特异性地破坏适体结构,使得可以将一种逆转剂用于多种不同适体中的任何一种。此类非特异性逆转剂包括但不限于例如聚阴离子,如硫酸葡聚糖、硫酸肝素、植酸或多磷酸盐。在其它实施方式中,感兴趣的适体可以与小分子结合适体融合,使得逆转剂可以包含结合并影响适体的折叠结构的小分子,从而引起结合的靶分子或细胞的释放。在另一实例中,逆转剂可以是结合促进适体的二级结构的必需离子的螯合剂。小分子逆转剂可以是非特异性或特异性的,取决于其如何与适体相互作用。例如,可以使用的小分子包括但不限于ATP、氨苄青霉素、四环素、多巴胺和磺基罗丹明B。与适体结合的小分子的进一步实例描述于McKeague和DeRosa,J Nucleic Acids.Vol.2012,文章ID No.748913(2102),以引用的方式将其整体并入本文。
在其它实施方式中,逆转剂可包括寡核苷酸或寡核苷酸模拟物(PNA、LNA、BNA等),所述寡核苷酸或寡核苷酸模拟物包含与形成双链茎结构的适体部分互补的序列。寡核苷酸逆转剂与适体中其互补物的杂交破坏了适体结构,并导致适体的靶分子的释放。寡核苷酸逆转剂还可包含与适体的非双链区互补的序列。一种此类寡核苷酸逆转剂配置包含与靶适体的单链部分互补的序列元件和与靶适体的相邻双链部分互补的序列元件。在这种配置中,寡核苷酸逆转剂可以有效地引发与适体的单链部分的杂交,然后将适体的相邻双链部分链置换以促进适体从其靶标释放。
小分子逆转剂可以选自例如小分子文库,其可以包括例如氨基酸、寡肽、多肽、蛋白质、或肽或蛋白质的片段;核酸(例如反义;DNA;RNA;或肽核酸PNA);碳水化合物或多糖;或有机或无机化合物(例如包括杂有机化合物和有机金属化合物)。文库的每个成员可以是单个的,也可以是混合物(例如压缩文库)的一部分。文库可以包含经纯化的化合物,也可以是“脏”的(即包含相当量的杂质)。可商购的文库可例如从Affymetrix、ArQule、NeoseTechnologies、Sarco、Ciddco、Oxford Asymmetry、Maybridge、Aldrich、Panlabs、Pharmacopoeia、Sigma或Tripose等获得。
逆转剂的使用允许可逆的、无标签的细胞选择。以这种方式释放与适体结合的细胞的优点在于分离的细胞将具有与之结合的相对较少的适体。这与使用抗体分离细胞相反,其中在分离细胞之后难以使抗体从细胞上解离。取决于细胞如何与适体一起孵育(例如,适体是最初与固体支持物结合还是先在溶液中孵育并随后通过亲和对下拉)以及细胞如何与逆转剂一起孵育(例如逆转剂浓度、时机等),逆转后仍然与经分离的细胞结合的适体的量可以是用于结合的适体的例如50%以下、40%以下、30%以下、20%以下、10%以下或者甚至5%以下。
如本文所述,寡核苷酸逆转剂可额外地或可替代地包含核碱基(在本领域中通常简称为“碱基”)修饰或置换。本文所使用的适体和逆转剂核碱基包括嘌呤碱基腺嘌呤(A)和鸟嘌呤(G);以及嘧啶碱基胸腺嘧啶(T)、胞嘧啶(C)和尿嘧啶(U)。经修饰的核碱基包括其它合成和天然的核碱基,例如:5-甲基胞嘧啶(5-me-C);5-羟甲基胞嘧啶;黄嘌呤;次黄嘌呤;2-氨基腺嘌呤;腺嘌呤和鸟嘌呤的6-甲基衍生物和其它烷基衍生物;腺嘌呤和鸟嘌呤的2-丙基衍生物和其它烷基衍生物;2-硫尿嘧啶、2-硫胸腺嘧啶和2-硫胞嘧啶;5-卤代尿嘧啶和5-卤代胞嘧啶;5-丙炔基尿嘧啶和5-丙炔基胞嘧啶;6-偶氮尿嘧啶、6-偶氮胞嘧啶和6-偶氮胸腺嘧啶;5-尿嘧啶(假尿嘧啶);4-硫尿嘧啶;8-卤代、8-氨基、8-硫醇、8-硫代烷基、8-羟基和其它8-取代的腺嘌呤和鸟嘌呤;5-卤代(特别是5-溴)、5-三氟甲基和其它5-取代的尿嘧啶和胞嘧啶;7-甲基鸟嘌呤和7-甲基腺嘌呤;8-氮杂鸟嘌呤和8-氮杂腺嘌呤;7-脱氮鸟嘌呤和7-脱氮腺嘌呤;以及3-脱氮鸟嘌呤和3-脱氮腺嘌呤。
逆转剂的合成寡核苷酸可以包括但不限于肽核酸(PNA)、桥接核酸(BNA)、吗啉代、锁核酸(LNA)、乙二醇核酸(GNA)、苏糖核酸(TNA)或本领域描述的任何其它非天然核酸(XNA)。
寡核苷酸逆转剂可以通过与本文所述的用于合成核酸适体的相同方法进行合成。
寡核苷酸逆转剂通常由短寡核苷酸链组成,其长度范围通常为8个至50个核碱基,但是可以与靶适体一样长或更长。在一些实施方式中,寡核苷酸逆转剂可包含8个以上、10个以上、20个以上、30个以上、40个以上、50个以上、60个以上、70个以上、80个以上、90个以上、100个以上以及更长的多核苷酸长度。
逆转剂选择可以包括设计针对适体3'末端的互补寡核苷酸序列(也参见实施例1中的表5),或针对已知或预测参与分子内碱基配对的适体的任何区域的互补寡核苷酸序列。
在一些实施方式中,可以利用二级(secondary)荧光链霉亲和素标记来进行感兴趣的细胞与5nM适体的结合。可以将经标记的细胞以不同过量倍数(超过所用的适体量)例如在含有1%(重量/体积)BSA的洗涤缓冲液中的200微升(μL)逆转剂中在不同温度下孵育不同时间。可以用洗涤缓冲液和1%(重量/体积)BSA将细胞洗涤两次,以去除洗脱的适体,然后进行固定和/或流式细胞术分析。
在一些实施方式中,添加到细胞混合物中的逆转剂的浓度为1纳摩尔以上、10纳摩尔以上、100纳摩尔以上、1微摩尔以上、10微摩尔以上、100微摩尔以上、1毫摩尔以上以及更高。逆转剂可以是适体浓度的0.1倍至100倍过量。
在一些实施方式中,适体的toehold区域可以促进逆转剂杂交,其破坏所选择的适体的二级结构。取决于预测的二级结构,toehold区域可以在适体的末端或在适体的内部位于单链区域处。
适体细胞结合的表征
通过本文所述的细胞-SELEX方法或通过本领域已知的另一方法鉴别的核酸适体可以通过多种方法进行表征,所述方法包括但不限于适体结合测定、下一代测序、基因谱分析、功能测定(诸如细胞毒性测定、细胞因子释放测定)以及将例如通过使用适体分离的天然或经修饰的细胞体内递送至动物或人类模型。上述方法可以充当本文所述的细胞选择的方法和组合物的质量控制。
为了表征适体与靶细胞或感兴趣的细胞的结合,可以进行体外结合测定,例如如下所述。将包含例如2×10
在一些实施方式中,用生物素、亲和素、链霉亲和素、琼脂糖或中性亲和素标记适体。
在一些实施方式中,用荧光团标记适体。荧光团的非限制性实例包括荧光素、罗丹明、Oregon green、伊红、德克萨斯红(Texas red)、青色素(cyanins)(例如Cy5.5)等。
在例如100μL总体积中孵育后,将细胞在例如补充有1%(重量/体积)BSA的200μL洗涤缓冲液中洗涤两次,以去除过量的适体。如果使用的适体经生物素化,则可使细胞经历与100μL荧光标记的链霉亲和素或中性亲和素第二标记在4℃在含有1%BSA的洗涤缓冲液中进行20min的二次孵育,然后再次洗涤两次。将经染色的细胞在例如200μL含有1%BSA(重量/体积)和0.1%(重量/体积)多聚甲醛(PFA)的洗涤缓冲液中固定,然后通过流式细胞术进行分析。
至少,特异性结合给定靶细胞或细胞表面标志物的适体以比该适体与不表达该标志物的细胞的结合高至少100×的亲和力结合表达该标志物的细胞,优选为高至少200×的亲和力、高至少300×的亲和力、高至少500×的亲和力、高至少600×的亲和力、高至少700×的亲和力、高至少800×的亲和力、高至少900×的亲和力、高至少1000×的亲和力或更高。
亲和力可以按照解离常数或Kd来表示。选择性结合细胞表面标志物的适体通常以低于1微摩尔(1μM)的Kd结合。已经描述了以皮摩尔(pM)范围内的Kd结合其靶标的适体。但是,对细胞选择有用的适体可在以下范围内结合:1μM至10pM、1μM至100pM、1μM至200pM、1μM至300pM、1μM至400pM、1μM至500pM、1μM至600pM、1μM至700pM、1μM至800pM、1μM至900pM、1μM至1nM、1μM至10nM、1μM至50nM、1μM至100nM、1μM至150nM、1μM至200nM、1μM至250nM、1μM至300nM、1μM至350nM、1μM至400nM、1μM至450nM、1μM至500nM、1μM至550nM、1μM至600nM、1μM至650nM、1μM至700nM、1μM至750nM、1μM至800nM、1μM至850nM、1μM至900nM、1μM至950nM、小于500nM至10pM、小于450nM至10pM、小于400nM至10pM、小于350nM至10pM、小于300nM至10pM、小于250nM至10pM、小于200nM至10pM、小于150nM至10pM、小于100nM至10pM、小于50nM至10pM、小于100nM至900pM、小于100nM至800pM、小于100nM至700pM、小于100nM至600pM、小于100nM至500pM、小于100nM至400pM、小于100nM至300pM、小于100nM至200pM、小于100nM至100pM、小于100nM至50pM或小于100nM至10pM。
本领域已知用于确定适体与其靶标结合的Kd的各种方法。Jing&Bowser,Anal.Chim.Acta 686:9-18(以引用的方式将其并入本文)综述了各种方法。本文所述的实施例提供了基于流式细胞术的测定;参见例如实施例1以及图6D和对图6D的描述。
使用细胞选择的适体池的细胞选择质量控制和无痕细胞选择方法
流式细胞术分析以及用于细胞鉴别的其它方法可用于评价适体/细胞相互作用以及使用给定适体或适体组合选择靶细胞的能力。如果需要,可以使用OneComp eBeads(Invitrogen)来准备用于补偿的单色对照。可以使用例如MACSQuant Analyzer 10(Miltenyi)、Attune NxT(Invitrogen)或BD LSRFortessa(BD Biosciences)流式细胞仪分析经染色的生物样品。
本文描述了并在实施例中证明了使用细胞-SELEX适体池的无痕细胞选择方法。在一种方法中,对于每种竞争性细胞-SELEX生物样品(例如PBMC),将抗生物素磁响应微珠(Miltenyi)的两份100微升(μL)等分试样各自在含有对细胞或细胞标志物(例如CD8)具有特异性的5nM适体的结合缓冲液中稀释至500微升(μL),并在4℃在温和旋转下孵育15min。
在一些实施方式中,微珠可以被例如本文所述的另一固体支持物代替。
在一些实施方式中,与用于细胞选择的细胞一起孵育的适体的量为1皮摩尔(pM)以上、1纳摩尔(nM)以上、1微摩尔(μM)以上。
在细胞选择步骤中,结合缓冲液中tRNA或另一非特异性核酸的存在可能是有用的,因为tRNA或其它非特异性核酸可以帮助阻断适体的非特异性结合或(当存在时)寡核苷酸逆转剂的非特异性结合。
然后,在一些实施方式中,结合缓冲液可包含例如0.1mg/mL tRNA、0.1g/L CaCl
对于细胞选择,将标记或缀合有适体的珠悬浮液添加至例如200×10
在一些实施方式中,生物样品可以包括全血、血沉棕黄层或分离的单个核细胞。
磁性分离可以使用例如Miltenyi MACS细胞分离系统(例如QUADROMACS
可以分离流穿(FT)级分,所述FT级分包括来自最初施加细胞和例如3次后续的3mL柱洗涤的流穿液。
当从磁体移除时,可使用5毫升(mL)柱冲洗液(CF)从柱中移除CD8微珠标记的细胞。可以将在1mL含有0.5%(重量/体积)BSA和5毫摩尔(mM)氯化镁(MgCl
逆转剂的浓度可以变化,这取决于试剂的性质(例如小分子相较于寡核苷酸)及其与适体的结合动力学。
可以使大约600-700微升(μL)逆转剂溶液通过柱,然后用M/F Luer Lock Plug(Smiths Medical)塞住,以在室温或允许使用功能逆转剂的任何条件下孵育10分钟。取下塞子后,可以用3毫升(mL)含有0.5%(重量/体积)BSA和5毫摩尔(mM)乙二胺四乙酸(EDTA)的autoMACS缓冲液洗涤柱3次,这构成了逆转剂洗脱(RAE)级分。
可立即对逆转剂洗脱的细胞进行离心并重悬于新鲜缓冲液中以去除任何剩余的逆转剂。可以用如本文所述的柱冲洗去除柱上的剩余细胞。
基于适体结合选择的细胞的用途
特定细胞类型的大规模制备或生产对于基于细胞的疗法变得越来越有用。细胞疗法的非限制性实例包括使用多种细胞祖细胞类型中的任何一种的干细胞疗法(例如治疗脊髓损伤、心肌梗塞等)、用于癌症治疗的免疫疗法以及用于糖尿病的同种异体细胞疗法等。本文所述的方法和组合物提供了用于分离特定靶细胞类型的有效方法,该方法容易扩大规模以用于这些和其它用途的细胞的大规模分离。
还在考虑之列的是,本文所述的方法可用于通过用对代表感兴趣的特定细胞类型的给定细胞发育阶段的细胞表面标志物具有特异性的适体分离细胞来改善干细胞分化。因此,本文所述的细胞分离方法可以用作干细胞疗法的质量控制步骤。
在一些实施方式中,如本文所述而选择的细胞可以其天然形式用于疾病的治疗性处理或用于缓解疾病的症状。因此,适体选择的细胞可用于治疗动物(包括哺乳动物,包括人)的可用此类细胞治疗的疾病或紊乱。在其它实施方式中,在将细胞引入患者前对细胞进行操纵和/或扩增。细胞可以是患者自体的、同种异体的或甚至是异种的。作为非限制性实例,操纵可包括进一步的细胞分选、抗原刺激、诱导分化和/或遗传修饰。经操纵的细胞可以但并非必须在给予前进行扩增。
在一个实施方式中,细胞疗法可用于治疗癌症或用于治疗感染,例如病毒(包括但不限于人免疫缺陷病毒(HIV))感染。
当前,自体CAR T细胞癌症疗法的产生和给予涉及在将经工程化的细胞重新引入患者之前对T细胞进行收获和遗传操纵。
嵌合抗原受体(CAR)是一种允许经修饰的T细胞表达它们以识别肿瘤细胞上的特定蛋白(抗原)的重组蛋白。经工程化以表达CAR的T细胞(称为CAR T细胞)在实验室中扩增,然后输注到患者内。在输注后,T细胞在患者体内扩增(multiply),并在其经工程化的受体的指导下识别并杀死在其表面展示抗原的癌细胞。
该过程的第一步骤(细胞收获)需要期望细胞群的高纯度分离。例如,本领域已知在白血病动物模型中,具有确定的1:1的CD4+:CD8+细胞群的CAR T细胞比纯(仅CD4+或CD8+)的群和未选择的群二者都更有效,并且在ALL的人类临床试验中也非常有效。
T细胞通常从通过白细胞去除术(leukapheresis)收集的外周血单个核细胞(PBMC)中分离。临床规模T细胞分离的主要方法包括(i)免疫耗竭不期望的细胞,然后使用抗体缀合的磁珠(例如CliniMACS)选择T细胞群;以及(ii)使用Streptamer技术进行“无痕”选择,该技术基于固定在磁珠上的抗原结合片段(Fab)构建体。第一种方法产生仍与抗体包被的磁珠缔合的最终细胞群,并且可能具有低靶细胞产率和纯度。Streptamer方法通过与肽标签融合的Fab(其可逆地与包被有经工程化的链霉亲和素的磁珠结合)部分地避免了这种结果。Fab可以通过与高亲和力的D-生物素竞争而从珠释放,因此必须经工程化以具有相对较低的受体结合亲和力,以使它们一旦以单价形式释放就迅速从细胞解离。尽管在从固体支持物释放后Fab内化进入细胞的程度尚不清楚,但经工程化以具有相对较低的受体结合的Fab不显著保留在细胞表面上。但是,该方法仍然具有差的靶细胞产率,每个选择步骤平均损失50%的细胞。此外,由于使用生物产生的抗体或Fab,上述两种方法都与巨大成本相关。
随着对于治疗急性淋巴细胞白血病(ALL)和弥漫性大B细胞淋巴瘤的CAR T细胞疗法的两个最近的FDA批准以及在临床试验中的许多有希望的结果,正迅速意识到T细胞疗法的临床影响。
可以使用利用本文所述的方法和组合物制备的细胞来治疗的癌症的实例包括但不限于恶性肿瘤(carcinoma)、淋巴瘤、胚细胞瘤、肉瘤和白血病。此类癌症的更具体实例包括但不限于基底细胞恶性肿瘤;胆道癌;膀胱癌;骨癌;脑和CNS癌;乳腺癌;腹膜癌;宫颈癌;胆管癌;绒毛膜癌;结直肠癌;结缔组织癌;消化系统癌;子宫内膜癌;食管癌;眼癌;头颈癌;胃癌(包括胃肠癌);胶质母细胞瘤;肝恶性肿瘤(hepatic carcinoma);肝细胞瘤(hepatoma);上皮内瘤变;肾癌(kidney or renal cancer);喉癌;白血病;肝癌(livercancer);肺癌(例如小细胞肺癌、非小细胞肺癌、肺腺癌和肺鳞状癌);淋巴瘤,包括霍奇金淋巴瘤和非霍奇金淋巴瘤;黑素瘤;骨髓瘤;神经母细胞瘤;口腔癌(例如唇、舌、口和咽);卵巢癌;胰腺癌;前列腺癌;视网膜母细胞瘤;横纹肌肉瘤;直肠癌;呼吸系统癌;唾液腺癌;肉瘤;皮肤癌;鳞状细胞癌;胃癌;畸胎恶性肿瘤(teratocarcinoma);睾丸癌;甲状腺癌;子宫或子宫内膜癌;泌尿系统癌;外阴癌;以及其它恶性肿瘤和肉瘤;以及B细胞淋巴瘤(包括低级/滤泡性非霍奇金淋巴瘤(NHL)、小淋巴细胞(SL)NHL、中级/滤泡性NHL、中级弥漫性NHL、高级免疫母细胞性NHL、高级淋巴母细胞性NHL、高级小无裂细胞(high grade small non-cleaved cell)NHL、肿块性疾病(bulky disease)NHL、套细胞淋巴瘤、AIDS相关淋巴瘤和Waldenstrom巨球蛋白血症);慢性淋巴细胞性白血病(CLL);急性淋巴细胞白血病(ALL);毛细胞白血病;慢性髓细胞性白血病;以及移植后淋巴增生性紊乱(PTLD);以及与母斑病(phacomatoses)相关的异常血管增生;水肿(例如与脑肿瘤相关的水肿);原发起源(primitive origins)的肿瘤;以及Meigs综合征。
本文的实施例中描述了靶向CD19肿瘤抗原的CAR-T细胞的产生,并且多种方法是本领域已知的。可以使用特异性结合T细胞的期望亚群上的标志物的任何适体或其组合以及本文所述的方法和组合物来分离用于产生对这种抗原和基本上任何其它抗原具有特异性的CAR-T细胞的自体或同种异体T细胞。包含例如细胞内结构域的各种组合的一系列不同嵌合抗原受体构建体在本领域中是已知的,并且可以将它们中的任何一种或随后产生的任何变异形式引入根据本文所述的方法分离的细胞中。可以通过例如病毒载体、质粒、裸DNA或允许将核酸引入细胞的任何其它方法来进行引入。不仅可以使用本文所述的基于适体的方法来分离起始T细胞从而制备CAR-T细胞,而且基于适体的细胞选择方法还可以应用于对在其表面成功表达CAR的T细胞进行选择(例如,通过使用选择用于与CAR自身的细胞外结构域上的决定簇或在CAR构建体上表达的替代(surrogate)标志物(例如EGFR)特异性结合的适体)。
本文所述的方法和组合物还可用于基于适体的CAR巨噬细胞选择。CAR巨噬细胞在本领域中已被描述为靶向实体肿瘤细胞以进行吞噬作用(参见Morrissey等,eLife.2018;Alvey等,Journal of Leukocyte Biology.2017;Lim等,Cell 1995)。用于分离巨噬细胞以进行CAR巨噬细胞制备的表面标志包括但不限于Megf10、Bai1、MerTK和CD47。也可以通过与CAR自身或与CAR构建体上表达的替代标志物(例如EGFR)结合的适体来从培养物中选择成功转化为CAR巨噬细胞的巨噬细胞。用结合标志物的适体靶向由修饰的构建体编码的替代细胞表面标志物的能力可用于广泛范围的其它细胞修饰和分离应用中的任一种。
除癌症之外,还已经产生了CAR T细胞作为潜在的抗HIV疗法。Hale等(2017)的最新研究表明,利用基于由高亲和力广泛中和抗体(high-affinity broadly neutralizingantibodies,bNAb)衍生而来的单链可变片段(scFv)并包含第二代共刺激结构域的CAR的T细胞以及并行的HIV遗传保护可以破坏CCR5,并有效地靶向HIV感染的细胞。
另一种基于细胞的癌症治疗方法包括使用经引发(primed)以将抗原引入T细胞的树突状细胞,从而引起抗肿瘤免疫应答。所谓的树突状细胞疫苗是通过在体外将单核细胞分化为树突状细胞并用特异性肿瘤抗原或源自患者肿瘤的制剂刺激树突状细胞,然后再将激活的呈递抗原的树突状细胞重新引入患者内来制备的。能够分化为树突状细胞的单核细胞的标志物是已知的,并且可以根据本文所述的方法用适体来靶向以提供用于树突状细胞疫苗制剂的自体细胞。
在一些实施方式中,还可以使用CRISPR/Cas9、RNAi、转染或本领域已知的任何其它类型的遗传修饰来修饰根据本文所述方法使用适体而分离的细胞。使用结合构建体的产物的适体或结合同一构建体上编码的替代(surrogate)细胞表面标志物的适体,基于适体的细胞分离也可用于分离利用外源构建体成功转化的细胞。
在一些实施方式中,所选择的细胞是干细胞或祖细胞。此类细胞的非限制性实例包括造血干细胞、间充质干细胞、神经干细胞、心脏干细胞、胚胎干细胞或本领域已知的任何其它干细胞。在考虑之列的是,所选择的干细胞可处于其分化的任何阶段,这取决于适体所靶向的细胞表面标志物的选择。本文所述的基于适体的细胞分离方法也可应用于例如通过使由重编程方案产生的干细胞与对多能干细胞标志物具有特异性的适体结合来分离诱导多能干细胞。标志物Oct4和Nanog是多能性标志物,但它们是胞内蛋白,在活细胞中适体不一定可接近到。多能性的细胞表面标志物包括例如SSEA3、SSEA4和CD9等。
干细胞的治疗用途包括用于治疗心脏病(例如心肌梗塞)、糖尿病、外伤性脑损伤、神经退行性疾病(例如帕金森氏病)、肌萎缩性侧索硬化症(ALS)、脊髓损伤、血管疾病、血液疾病(例如再生障碍性贫血)、视力障碍和不育等。本文所述的基于适体的细胞分离方法可用于分离干细胞(例如,基于干细胞标志物表达);以及当期望制备由干细胞衍生的细胞或组织时用于分离干细胞的分化产物(例如,基于与感兴趣的细胞类型上的分化特异性标记物的可逆适体结合)。因此,也在考虑之列的是,所选择的细胞还可以用于细胞或组织的再生、补充或替换,包括但不限于骨、肌肉、韧带、肌腱、神经或皮肤的再生,从而修复伤口。
基于细胞的治疗剂的给予
在一些方面,本文提供的方法包括将多种适体选择的细胞或其子代或分化产物细胞递送至宿主组织。如本文所述,可以将根据本文所述方法通过适体分离或选择的细胞并入适合于给予至受试者(例如用于体内递送至受试者的组织或器官)的药物组合物中。
包含感兴趣的细胞的组合物的剂量范围包括足够大以产生期望的效果(例如期望的基因产物(例如抗体)的表达或疾病(例如癌症)的治疗)的量。剂量不应太大以致引起不可接受的不良副作用。通常,剂量将随感兴趣的细胞的特定特征以及随患者的年龄、状况和性别而变化。剂量可以由本领域技术人员确定,并且与传统的细胞疗法不同,在发生任何并发症的情况下,也可以由个体医师来调整剂量。
在一些实施方式中,将感兴趣的细胞在重复或有限的时间递送。在一些实施方式中,每天一次或每天多次给予剂量。治疗的持续时间取决于受试者的临床进展和对治疗的响应性。
可以通过外科手术植入、静脉内给予、动脉内给予、腹膜内给予、肢体灌注(任选地,腿和/或手臂的隔离肢体灌注;参见例如Arruda等,(2005)Blood 105:3458-3464)和/或直接肌内注射,将包含适体选择的感兴趣的细胞的组合物递送至靶细胞或组织。可以通过任何合适的方法向肌肉(例如隔膜)进行给予,包括静脉内给予、动脉内给予和/或腹膜内给予。
在一些实施方式中,也可以与感兴趣的细胞一起包含一种或多种额外化合物,以减轻疾病症状或以其它方式辅助或支持所给予的细胞的功能。
在一些实施方式中,额外化合物可以是治疗剂。治疗剂可以选自适合于治疗目的的任何类别。换言之,可以根据期望的治疗目的和生物学作用选择治疗剂。此外,可以将治疗剂的活性成分与任选的药学上可接受的并且与活性成分相容的药物添加剂(例如赋形剂或载体)混合。
作为治疗剂而递送的感兴趣的细胞可以进一步包含针对感兴趣的组织的靶向部分。例如,靶向部分可包含受体分子,包括天然识别靶细胞的特定的期望分子的受体。此类受体分子包括经修饰以增加其与靶分子相互作用的特异性的受体、经修饰以与天然不被该受体识别的期望靶分子相互作用的受体以及此类受体的片段(参见例如Skerra,2000,J.Molecular Recognition,13:167-187)。在其它实施方式中,靶向部分可包含配体分子,包括例如天然识别靶细胞上的特定的期望受体的配体。此类配体分子包括经修饰以增加其与靶受体相互作用的特异性的配体、经修饰以与天然不被该配体识别的期望受体相互作用的配体以及此类配体的片段。
在其它实施方式中,靶向部分可包含未曾在如本文所述的初始细胞选择中使用的适体。
应当理解,上面的详细描述和下面的实施例仅是说明性的,而不应被视为对本发明范围的限制。可以在不脱离本发明的精神和范围的情况下对公开的实施方式进行各种改变和修改,这对于本领域技术人员而言将是显而易见的。此外,将标注的所有专利、专利申请和出版物以引用的方式明确并入本文,以用于描述和公开例如在此类出版物中描述的可与本发明关联使用的方法学的目的。这些出版物仅由于它们的公开早于本申请的申请日而提供。在这一方面,不应当视作承认本发明人没有权利借助于先前的发明或因为任何其它原因而将此类公开内容提前。所有关于这些文件的日期的声明或关于这些文件的内容的表述是基于申请人可获得的信息,并不构成关于这些文件的日期或内容的正确性的任何承认。
本文所述的方法和组合物的一些实施方式可以根据下列编号段落中的任何一段进行定义:
1.一种用于从包含多种细胞类型的生物样品中分离感兴趣的细胞的方法,所述方法包括:
a.在允许形成与适体结合的细胞的条件下,使所述生物样品与适体接触,所述适体特异性结合对所述感兴趣的细胞具有特异性的细胞表面标志物;
b.将所述与适体结合的细胞与未与适体结合的细胞分开;以及
c.通过破坏所述适体与所述细胞表面标志物的结合来回收所述感兴趣的细胞,
从而从所述生物样品中分离所述感兴趣的细胞。
2.如段落1所述的方法,其中,所述感兴趣的细胞是活的。
3.如段落1或2所述的方法,其中,所述感兴趣的细胞是白细胞。
4.如段落1-3中任一项所述的方法,其中,所述感兴趣的细胞是淋巴细胞或单核细胞。
5.如段落1-4中任一项所述的方法,其中,所述感兴趣的细胞是T细胞。
6.如段落1-5中任一项所述的方法,其中,所述感兴趣的细胞是CD3+细胞、CD4+细胞、CD8+细胞。
7.如段落1-6中任一项所述的方法,其中,所述适体包含标记。
8.如段落1-7中任一项所述的方法,其中,分开步骤(b)包括使用第一固体支持物或相变剂。
9.如段落1-8中任一项所述的方法,其中,所述适体(i)缀合或固定至第一固体支持物;和/或(ii)被亲和对的第一成员标记。
10.如段落9所述的方法,其中,分开步骤(b)包括(i)从所述生物样品中去除通过所述适体结合至所述第一固体支持物的所述与适体结合的细胞;或(ii)添加带有所述亲和对的第二成员的第二固体支持物,以允许通过所述亲和对的所述第一成员和所述第二成员的相互作用使所述适体物理缔合至所述第二固体支持物,并从所述生物样品中去除所述与适体结合的细胞。
11.如段落9或10所述的方法,其中,所述适体缀合至相变剂。
12.如段落9-11中任一项所述的方法,其中,接触步骤(a)在所述相变剂处于溶液相的条件下进行;其中,分开步骤(b)包括诱导所述相变剂从溶液中沉淀,从而从所述生物样品中去除与适体结合的细胞。
13.如段落8-12中任一项所述的方法,其中,所述第一固体支持物和/或所述第二固体支持物包括磁响应珠。
14.如段落8-12中任一项所述的方法,其中,所述第一固体支持物和/或所述第二固体支持物包括聚合物、金属、陶瓷、玻璃、水凝胶或树脂。
15.如段落13所述的方法,其中,分开步骤包括使所述样品经受磁场,从而将包含与适体结合的细胞的固体支持物与所述生物样品分开。
16.如段落1-15中任一项所述的方法,其中,逆转剂包括聚阴离子、小分子或寡核苷酸或寡核苷酸模拟物,所述寡核苷酸或寡核苷酸模拟物包含与所述适体的序列充分互补的序列以与所述适体杂交,从而破坏所述适体与所述细胞表面标志物的结合。
17.如段落1-16中任一项所述的方法,其中,所述与适体结合的细胞包含对选定的标志物对呈双重阳性的细胞,所述标志物对包括所述适体所结合的标志物。
18.如段落1-17中任一项所述的方法,其中,分离的细胞级分包含对选定的标志物对呈双重阳性的细胞,所述标志物对包括所述适体所结合的标志物。
19.一种从生物样品中分离多种细胞级分的方法,所述方法包括:
a.在允许形成与适体结合的细胞的条件下,使所述生物样品与多种适体接触,所述多种适体特异性结合对多种不同的感兴趣的细胞具有特异性的细胞表面标志物;
b.将所述与适体结合的细胞的群与未与适体结合的细胞分开;
c.依次向步骤(b)中分开的所述与适体结合的细胞中添加多种逆转剂,所述逆转剂破坏所述多种适体中的一种或多种与多种细胞表面标志物中的一种或多种的结合,从而使每种依次添加的逆转剂从步骤(b)中分开的细胞的群中洗脱出不同的细胞级分,从而从所述生物样品中分离多种不同的细胞级分。
20.如段落19所述的方法,其中,所述多种逆转剂包括聚阴离子、小分子、寡核苷酸或寡核苷酸模拟物或它们的组合,所述寡核苷酸或寡核苷酸模拟物包含与所述多种适体中的适体的序列充分互补的序列以与所述适体杂交,从而破坏所述适体与其细胞表面标志物的结合。
21.如段落19或20所述的方法,其中,所述多种适体结合至一种或多种固体支持物或相变剂。
22.如段落21所述的方法,其中,所述固体支持物包括磁响应珠。
23.如段落21或22所述的方法,其中,所述固体支持物包括聚合物、金属、陶瓷、玻璃、水凝胶或树脂。
24.如段落21-23中任一项所述的方法,其中,通过使所述样品经受磁场,将包含与多种不同适体结合的细胞群的固体支持物与所述生物样品分开。
25.如段落19-24中任一项所述的方法,其中,所述与适体结合的细胞是白细胞。
26.如段落19-25中任一项所述的方法,其中,所述与适体结合的细胞是淋巴细胞。
27.如段落19-26中任一项所述的方法,其中,所述与适体结合的细胞是T细胞。
28.如段落19-27中任一项所述的方法,其中,所述与适体结合的细胞表达CD3、CD8和/或CD4。
29.一种从生物样品中分离细胞级分的方法,所述细胞级分富集了对靶细胞标志物对呈双重阳性的细胞,所述方法包括:
a.在允许形成与适体结合的细胞的条件下,使所述生物样品与特异性结合第一靶细胞表面标志物的第一适体接触;
b.将所述与适体结合的细胞的群与未与适体结合的细胞分开;
c.使步骤(b)中分开的所述与适体结合的细胞的群与破坏所述第一适体与步骤(b)中分开的细胞的结合的第一逆转剂接触,从而分离出对所述第一靶细胞表面标志物呈阳性的细胞群;
d.在允许形成与适体结合的细胞的条件下,使步骤(c)中分离的群与特异性结合第二靶细胞表面标志物的第二适体接触;
e.将步骤(d)中形成的所述与适体结合的细胞的群与未与适体结合的细胞分开;以及
f.使步骤(e)中分开的所述与适体结合的细胞的群与破坏所述第二适体与步骤(e)中分开的细胞的结合的第二逆转剂接触,从而分离对所述第一靶细胞表面标志物和所述第二靶细胞表面标志物呈阳性的细胞群。
30.如段落29所述的方法,其中,所述逆转剂包括小分子、聚阴离子、寡核苷酸或寡核苷酸模拟物或它们的组合,所述寡核苷酸或寡核苷酸模拟物包含与相应的适体的序列充分互补的序列以与所述适体杂交,从而破坏所述适体与细胞表面标志物的结合。
31.如段落29或30所述的方法,其中,所述第一适体和/或所述第二适体固定或缀合至一种或多种固体支持物或相变剂。
32.如段落31所述的方法,其中,所述固体支持物包括磁响应珠、聚合物、金属、陶瓷、玻璃、水凝胶或树脂。
33.如段落31或32所述的方法,其中,所述固体支持物包括磁响应珠,并且其中通过使所述细胞群经受磁场来将与所述第一适体和/或所述第二适体结合的细胞群分开。
34.如段落29-33中任一项所述的方法,其中,所述与适体结合的细胞包含淋巴细胞。
35.如段落29-34中任一项所述的方法,其中,所述与适体结合的细胞包含T细胞。
36.如段落29-35中任一项所述的方法,其中,步骤(f)中分离的细胞包含CD3+T细胞、CD8+T细胞、CD4+T细胞、CD3+CD4+T细胞或CD3+CD8+T细胞。
37.一种基于细胞表面标志物的表达程度将生物样品中的感兴趣的细胞分开的方法,所述方法包括:
a.在允许形成与适体结合的细胞的条件下,使所述生物样品与所述适体接触,所述适体特异性结合对所述感兴趣的细胞具有特异性的细胞表面标志物;
b.将所述与适体结合的细胞与未与适体结合的细胞分开;以及
c.使步骤(b)中分开的所述与适体结合的细胞阶梯式地或梯度式地与浓度增加的逆转剂接触,所述逆转剂破坏所述适体与所述细胞表面标志物的结合;
从而基于所述细胞表面标志物的表达程度将所述生物样品中的所述感兴趣的细胞分开,使得所述样品中具有较低标志物表达即marker
38.如段落37所述的方法,其中,所述逆转剂包括聚阴离子、小分子、寡核苷酸或寡核苷酸模拟物或它们的组合,所述寡核苷酸或寡核苷酸模拟物包含与所述适体的序列充分互补的序列以与所述适体杂交,从而破坏所述适体与所述细胞表面标志物的结合。
39.一种基于细胞表面标志物的表达程度将生物样品中的感兴趣的细胞分开的方法,所述方法包括:
a.在允许形成与适体结合的细胞的条件下,使所述生物样品与所述适体接触,所述适体特异性结合对所述感兴趣的细胞具有特异性的细胞表面标志物;
b.将所述与适体结合的细胞与未与适体结合的细胞分开;以及
c.使步骤(b)中分开的所述与适体结合的细胞依次与在置换动力学或适体亲和力方面不同的多种逆转剂接触,并且以增加的相对置换动力学或相对适体亲和力的顺序添加所述逆转剂,
从而基于所述细胞表面标志物的表达程度将所述生物样品中的所述感兴趣的细胞分开,使得所述样品中具有较低标志物表达即marker
40.如段落39所述的方法,其中,所述逆转剂包括聚阴离子、小分子、寡核苷酸或寡核苷酸模拟物或它们的组合,所述寡核苷酸或寡核苷酸模拟物包含与所述适体的序列充分互补的序列以与所述适体杂交,从而破坏所述适体与所述细胞表面标志物的结合。
41.如段落37-40中任一项所述的方法,其中,所述感兴趣的细胞是白细胞。
42.如段落37-41中任一项所述的方法,其中,所述感兴趣的细胞是淋巴细胞。
43.如段落37-42中任一项所述的方法,其中,所述感兴趣的细胞是T细胞。
44.如段落37-43中任一项所述的方法,其中,所述感兴趣的细胞是表达CD8的细胞。
45.如段落37-44中任一项所述的方法,其中,所述适体结合至一种或多种固体支持物或相变剂。
46.如段落45所述的方法,其中,所述一种或多种固体支持物或相变剂包括磁响应珠。
47.如段落45或46所述的方法,其中,所述一种或多种固体支持物包括聚合物、金属、陶瓷、玻璃、水凝胶或树脂。
48.如段落45-47中任一项所述的方法,其中,分开步骤(b)包括使所述样品经受磁场,从而将包含与多种不同适体结合的细胞群的固体支持物与所述生物样品分开。
49.一种核酸分子,所述核酸分子包含SEQ ID NO:1-SEQ ID NO:6、SEQ ID NO:10-SEQ ID NO:14、SEQ ID NO:17-SEQ ID NO:22、SEQ ID NO:27-SEQ ID NO:30、SEQ ID NO:33-SEQ ID NO:48或SEQ ID NO:52-SEQ ID NO:77中任一项的序列,其中,所述核酸分子选择性地与人CD8多肽结合。
50.如段落49所述的核酸分子,其中,所述核酸分子在选自于由以下核苷酸对所组成的组中的核苷酸对处包含补偿性变化:核苷酸3和75、4和74、5和73、6和72、7和71、8和70、9和69、10和68、13和54、14和53、15和52、16和51、17和50、18和49、19和48、25和47、26和46、27和45、28和44、29和43、30和42、31和41、32和40、33和39或34和38;其中,所述核酸分子相对于SEQ ID NO:1的核酸分子保留与CD8多肽的选择性结合。
51.如段落49所述的核酸分子,其中,所述核酸分子在选自于由以下核苷酸对所组成的组中的两个以上的核苷酸对处包含补偿性变化:核苷酸3和75、4和74、5和73、6和72、7和71、8和70、9和69、10和68、13和54、14和53、15和52、16和51、17和50、18和49、19和48、25和47、26和46、27和45、28和44、29和43、30和42、31和41、32和40、33和39或34和38;其中,所述核酸分子相对于SEQ ID NO:3的核酸分子保留与CD8多肽的选择性结合。
52.如段落49所述的核酸分子,其中,所述核酸分子是DNA分子、RNA分子或PNA分子。
53.如段落49-52中任一项所述的核酸分子,其中,所述核酸分子包含经修饰的核苷。
54.如段落53所述的核酸分子,其中,所述经修饰的核苷选自表1。
55.一种固体支持物,所述固体支持物包含如段落49-54中任一项所述的核酸分子。
56.如段落55所述的固体支持物,其中,所述固体支持物为磁响应珠。
57.如段落56所述的固体支持物,其中,所述固体支持物包括聚合物、金属、陶瓷、玻璃、水凝胶或树脂。
58.如段落55-57中任一项所述的固体支持物,其中,所述固体支持物通过所述核酸分子与CD8+T细胞结合。
59.如段落49-54中任一项所述的核酸,其中,所述核酸包含标记。
60.如段落59所述的核酸,其中,所述标记选自生物素标记和荧光标记。
61.一种组合物,所述组合物包含与如段落49-54中任一项所述的核酸结合的CD8+人T细胞。
62.如段落49-54中任一项所述的核酸,其中,所述核酸与逆转剂杂交,所述逆转剂包含含有分别与如段落49-54中任一项所述的核酸的至少八个连续核苷酸互补的序列的核酸。
63.一种包含核酸分子的逆转剂,所述核酸分子包含含有与如段落49-54中任一项所述的核酸互补的至少八个连续核苷酸的序列,其中,所述逆转剂分别抑制如段落49-54中任一项所述的核酸与人CD8多肽的结合。
64.如段落63所述的逆转剂,其中,所述核酸分子包含含有与如段落49-54中任一项所述的核酸互补的至少八个连续核苷酸的序列。
65.一种从生物样品中分离CD8+T细胞的方法,所述方法包括使包含人CD8+T细胞的生物样品与如段落49-54中任一项所述的核酸或如段落55-57中任一项所述的固体支持物接触,其中,所述接触允许所述CD8+T细胞与所述核酸的选择性结合。
66.如段落65所述的方法,其中,所述生物样品包括全血、血沉棕黄层或分离的单个核细胞。
67.如段落65所述的方法,其中,所述方法进一步包括在使所述生物样品与如段落49-54中任一项所述的核酸或如段落55-57中任一项所述的固体支持物接触后,使所述样品与逆转剂接触的步骤,所述逆转剂包含含有与如段落49-54中任一项所述的核酸互补的至少八个连续核苷酸的序列的核酸分子,其中,所述逆转剂抑制如段落49-54中任一项所述的核酸与人CD8多肽的结合,从而允许所述CD8+T细胞的释放。
68.如段落67所述的方法,其中,使所述样品与如段落55-57中任一项所述的固体支持物接触;其中,使所述样品进一步经受磁场,从而允许将与所述固体支持物结合的所述CD8+T细胞与所述样品中的其它细胞分开。
69.一种从生物样品中制备感兴趣的细胞的靶细胞类型或类别的群的方法,所述方法包括:
a.在允许形成与适体结合的细胞的条件下,使所述生物样品与所述适体接触,所述适体特异性结合对所述感兴趣的细胞的靶细胞类型或类别具有特异性的细胞表面标志物;
b.将所述与适体结合的细胞与未与适体结合的细胞分开;以及
c.通过破坏所述适体与所述感兴趣的细胞的结合来回收所述感兴趣的细胞的群。
70.一种对结合感兴趣的细胞的特定细胞类型或类别的适体序列进行选择的方法,所述方法包括:
i.将感兴趣的细胞类型或类别与单链DNA文库一起孵育,所述文库包含20个至85个核苷酸的给定长度的随机序列;
ii.分离与所述感兴趣的细胞结合的单链DNA;
iii.将来自步骤ii的分离的单链DNA序列与包含所述感兴趣的细胞类型或类别在内的细胞类型的混合物一起孵育;
iv.用抗体和抗体特异性支持柱从步骤iii的孵育中分离所述感兴趣的细胞类型或类别;
v.从步骤iv中分离的细胞中提取结合的单链DNA;
vi.对来自步骤v的结合的单链DNA序列进行PCR扩增;
vii.将来自步骤vi的单链DNA序列与缺乏感兴趣的表面受体的细胞类型一起孵育;
viii.将未结合的单链DNA与步骤vii中的细胞分开;
ix.对来自步骤viii的未结合的单链DNA序列进行PCR扩增;
x.重复步骤iii-步骤ix至少两次;以及
xi.对剩余的单链DNA进行测序。
71.如段落70所述的方法,其中,所述感兴趣的细胞类型或类别是白细胞。
72.如段落70或71所述的方法,其中,所述感兴趣的细胞类型或类别是淋巴细胞。
73.如段落70-72中任一项所述的方法,其中,所述感兴趣的细胞类型或类别是CD2+T细胞、CD3+T细胞、CD4+T细胞、CD8+T细胞或CD28+T细胞。
74.如段落70-72中任一项所述的方法,其中,所述感兴趣的细胞类型或类别表达段落73中的两种以上的细胞表面标志物的组合。
75.如段落70-72中任一项所述的方法,其中,所述感兴趣的细胞类型或类别是造血干细胞。
76.如段落1、19、29、37、39、69或70中任一项所述的方法,其中,所述方法用于感兴趣的细胞群的大规模选择;或者其中,分离出多种感兴趣的细胞。
77.一种治疗疾病或紊乱的方法,所述方法包括给予通过如段落1、16、25、26、55或56所述的方法分离的细胞的组合物,其中,所述细胞的组合物将所述疾病的至少一种症状减轻至少10%。
78.如段落77所述的方法,其中,所述疾病或紊乱是癌症。
79.如段落77所述的方法,其中,所述疾病或紊乱是免疫疾病。
80.如段落77所述的方法,其中,所述疾病或紊乱是HIV感染。
81.已通过如段落1-18中任一项所述的方法分离的细胞的组合物。
82.已通过如段落19-28中任一项所述的方法分离的细胞级分的组合物。
83.已通过如段落29-36中任一项所述的方法分离的细胞级分的组合物。
84.已通过如段落37-38中任一项所述的方法分开的细胞的组合物。
85.已通过如段落39-48中任一项所述的方法分开的细胞的组合物。
86.已通过如段落65-68中任一项所述的方法分离的CD8+T细胞的组合物。
87.通过如段落69所述的方法制备的细胞的组合物。
88.特异性结合通过如段落70所述的方法选择的适体的细胞的组合物。
实施例
以下提供了证明并支持本文所述技术的非限制性实施例。
本文所述的方法和组合物详细描述了使用经修饰的细胞SELEX程序鉴别的CD8的数种高亲和力DNA适体,并验证了所选适体的结合特性。适体从外周血单个核细胞(PBMC)中分离CD8+T细胞,其效率与标准方法相当。其次,开发了使用互补寡核苷酸序列破坏适体折叠来逆转适体结合的方法,并显示使用这种方法可以以高产率和高纯度从固定有适体的支持物中释放CD8+细胞。最后,由可逆适体选择方法和标准的基于抗体的CD8微珠生成了CART细胞并对其进行了充分表征。使用无痕适体选择分离的CAR T细胞在表型上类似于使用抗体分离的CAR T细胞,并且在体外和体内均表现出几乎相同的效应物功能。因此,这种基于适体的选择方法可实现用于潜在的临床规模细胞疗法应用中的T细胞的高效的无标记选择。随着未来的适体发展,这项技术可以很容易地扩展用于多种T细胞群的连续或并行选择。
实施例1:结合T细胞的适体的鉴别
随着对于治疗急性淋巴细胞白血病(ALL)和弥漫性大B细胞淋巴瘤的嵌合抗原受体(CAR)T细胞疗法的两个最近的FDA批准(分别为Novartis的Kymriah和Gilead-Kite的Yescarta)以及在临床试验中的许多有希望的试验,正迅速意识到T细胞疗法的临床影响
用于CAR T细胞生产的T细胞通常从通过白细胞去除术收集的外周血单个核细胞(PBMC)中分离。报道用于临床规模T细胞分离的一种方法是通过免疫磁性阳性富集(例如CliniMACS)从单采血液分离(apheresis)产物中顺序分离CD8+和CD4+T细胞
已经报道了基于Streptamer的细胞选择技术,该技术通过与肽标签融合的抗原结合片段(Fab)构建体(其可逆地与包被有经工程化的链霉亲和素的磁珠结合)而避免了这些不期望的结果中的一些
核酸适体(能够结合靶分子的单链寡核苷酸)是用于细胞选择的抗体和Fab的有吸引力的替代物。适体由Szostak、Gold和Joyce小组于20世纪90年代首次开发
本文描述了用于分离无标记的CD8+T细胞的可逆适体选择技术。呈现了工作的三个主要方面。首先,使用经修饰的细胞-SELEX程序鉴别了对CD8具有特异性的数种高亲和力DNA适体,并验证了所选适体的结合特性。利用适体中的一种将磁激活细胞分选(MACS)与临床上使用的基于抗体的CD8微珠系统进行比较,发现适体以与标准方法相当的效率从PBMC分离CD8+T细胞。其次,开发了使用互补寡核苷酸逆转剂破坏适体折叠来逆转适体结合的方法,并显示使用这种方法可以以高产率和高纯度从固定有适体的支持物中释放CD8+细胞。最后,由标准的基于抗体的选择和本文所述的可逆适体选择方法二者生成了CAR T细胞并对其进行了充分表征。使用无痕适体选择分离的CAR T细胞在表型上类似于使用抗体分离的CAR T细胞,并且在体外和体内均表现出几乎相同的效应物功能。因此,这种基于适体的选择方法可实现用于潜在的临床规模细胞疗法应用中的T细胞的高效、无标记且廉价的选择。随着未来其它T细胞特异性适体(例如CD4适体)的发现,这项技术可以很容易地扩展用于使用一组适体和相应的逆转剂由单个装置来进行对多种T细胞群的高通量的连续选择。
通过并入竞争性和反向选择(counter selection)的细胞SELEX对结合T细胞的适体进行鉴别
细胞分离应用取决于特异性适体的发现和使用。使用传统蛋白质-SELEX与重组蛋白或使用细胞-SELEX与经工程化的细胞系来鉴别T细胞特异性适体的最初尝试均未成功,并产生具有不良特异性的适体,据假设,细胞-SELEX提供的细胞表面上的受体的天然展示(native display)和竞争性选择提供的选择的严格性增加二者是发现T细胞特异性适体所必需的。修改了Tan小组的细胞-SELEX方案,以包括竞争性选择(在存在相关不期望的细胞的情况下进行选择)和反向选择(结合不期望的靶标的适体的耗竭)二者(图1)。在使用具有52个碱基对随机区域(10
表2:在严格性增加的轮次中的T细胞SELEX的实验条件。
通过流式细胞术监测细胞选择进程(图2)。在第三轮中观察到与T细胞亚群的结合,并在第五轮中增强。由于在第五轮中观察到与反向选择细胞的非特异性结合,在五轮后停止选择。
使用表3(下表)中详述的引物通过下一代测序(NGS)鉴别来自每一轮选择的适体池以及原始适体文库,并使用FASTAptamer进行分析。
表3中的引物也可见于SEQ ID NO:78-SEQ ID NO:84。
表3:用于原初文库(
使用Figtree软件生成前100个适体的系统进化树,并使用MEME分析
表4:T细胞SELEX的轮次之间的前20个第5轮(R5)适体序列的富集。
*百分比表现通过将序列的每百万读段(RPM)转换为百分比来计算,而富集倍数通过将某一轮次的序列的RPM除以前一轮次的值来计算。
基于适体的丰度、基序、轮次之间的富集和系统进化树上的家族表现(familyrepresentation)及它们的二级结构的低能量状态(图4),选择五种适体(根据其在表4中的排名命名,并在表5(下表)中列出)来进行与原代T细胞和反向选择J.RT3-T3.5细胞的结合研究。来自表5的适体序列可见于SEQ ID NO:1-SEQ ID NO:7。
表5:实验中使用的适体和逆转剂的序列。
*斜杠“/”中的文本表示IDT修饰代码,带下划线的碱基对表示用于在PCR反应中进行引发的恒定区。
与来自原初文库的随机选择的适体(RN)相比,荧光素标记的适体A1、A3和A8显示出与混合T细胞的亚群的特异性结合,而A2和A7表现出与T细胞和J.RT3-T3.5细胞二者的整体群结合(图5)。有趣的是,A2和A7(而非A1、A3和A8)属于在第5轮中出现的独特基序3,并且显示出在第4轮和第5轮之间的显著富集(>100倍),此时在大适体池(bulk aptamer pool)中观察到与J.RT3-T3.5细胞的非特异性结合。
结合T细胞的适体的表征
适体A1、A3和A8由于它们重叠的基序而可能结合相同的受体。此外,怀疑这些适体与CD8结合,因为该蛋白不在反向选择细胞系上表达,并且在健康供体pan-T细胞分离物中CD8:CD4 T细胞比率低,与观察到的20%-30%的混合T细胞群结合一致(图5)。因此,分析了适体与具有CD4和CD8抗体标记的混合人T细胞的结合,结果表明所有三种适体均结合至CD8+但不结合至CD4+T细胞,表明适体结合至人CD8(图6A)。然而,针对鼠脾细胞的类似结合研究没有显示出与T淋巴细胞亚群的任何结合,表明适体与CD8抗体类似,不结合鼠CD8(图7A)。适体A1、A3和A8也与恒河猴PBMC中的CD8+T细胞结合,这与在许多抗人CD8抗体克隆中观察到的恒河猴交叉反应性相一致(图7B)。进一步通过三种技术确认了这些适体结合细胞上表达的人CD8α链同种型(CD8a):与CD8特异性抗体的竞争性结合、T细胞中CD8a的siRNA敲减以及CD8-细胞中的强制(enforced)CD8a表达。在共孵育期间,浓度增加的未标记CD8特异性抗体(克隆RPA-T8)而非CD3特异性抗体,在与CD8+T细胞结合方面稳健地强于(outcompeted)所有三种适体(图8)。原代CD8+T细胞中由siRNA进行的CD8a敲减(75%)(下表6)通过抗体染色确认,并且与所有三种适体的结合降低73%-77%相关(图6B)。
表6:用于CD8敲减的siRNA双链体。
在CD8-Jurkat永生化人淋巴细胞中来自GFP报告质粒的CD8a的瞬时表达引入了特异性结合至GFP+细胞的适体(图6C)。为了验证适体结合至CD8a蛋白本身,通过生物层干涉术(BLI)测量了缔合和解离动力学,其中针对固定在链霉亲和素包被的BLI传感器上的适体筛选了连续稀释的重组细胞外CD8a蛋白(Ser22-Asp182)。RN适体阴性对照未显示出与CD8a蛋白的可检测缔合(数据未示出),而A1、A3和A8适体则分别以20.1±0.2、14.7±0.1和5.59±0.11nM的结合亲和力(K
表7:生物层干涉术(BLI)测量的A1、A3和A8适体结合至重组CD8a蛋白的亲和力和动力学。
数据为平均值±s.d.,通过将图6E中的结合曲线数据对1:1结合模型进行全局拟合来计算。解离速率常数(K
用互补寡核苷酸逆转适体结合
为了使用基于适体的亲和剂实现无痕细胞分离,在细胞回收步骤中需要逆转适体与细胞的结合的方法。可通过核酸酶介导的适体降解、施加力、竞争性结合或通过热或互补寡核苷酸结合使二级结构变性而破坏适体结合。在这些前述方法中,互补寡核苷酸置换是优选方法,因为其具有温和(例如与热或力相比)与高产率(例如与竞争性结合相比)和相对低的成本(例如与核酸酶降解相比)的优点。因此,设计了CD8结合适体,该适体可以通过与互补置换链(“逆转剂”)结合而从细胞释放。
选择适体的设计和逆转剂的设计的两个主要考虑因素为:第一,选择适体与靶细胞的高亲和力结合;第二,逆转剂对适体二级结构(其对于受体结合很关键)的快速破坏。因此,选择A3适体用于细胞选择,不仅由于其对于CD8+T细胞的低表观K
然后,在原始A3序列的3'端延伸toehold区域(A3t),以促进通过互补逆转剂进行的细胞释放的启动(图10A和表5)。toehold是单链序列,其允许通过称为链置换的方法进行互补序列结合并取代预先配对的碱基。在这种情况下,逆转剂将通过toehold进行链置换,以消除适体中二级结构所必需的链内碱基配对。Zhang和Winfree报道了链置换的速率常数取决于toehold长度,其变化范围高至6个数量级,toehold的长度超过6个碱基时达到最大速率;因此,在所描述的CD8-适体选择剂中使用了8-mer的toehold。基于所预测的结合后二级结构的变化,将逆转剂(RA)设计为长度为36个碱基(图10B和表5)。
已使用荧光标记的适体和流式细胞术分析证明了RA从细胞中有效且快速地释放适体。为了确定释放的必要条件,评价了RA的各种浓度(范围为过量25倍至100倍)、温度(4℃、室温和37℃)和孵育时间(5min、10min和20min)(图11A-图11B)。虽然在所有条件下均观察到>70%的A3t适体释放,但在室温下用100倍过量的RA孵育仅10min即可达到90%的释放。因此,选择这些参数用于无标记分离策略。
基于适体的无痕T细胞分离策略
在将A3t适体应用于细胞选择过程之前,必须确保该适体在PBMC的背景下选择性地结合T细胞。在待用于细胞分离的浓度(5nM)下,观察到与CD3-CD56-CD14+单核细胞和CD3-CD56-CD19+B细胞的最小结合,并且与这些细胞群的结合不高于RN适体对照(图12)。与B细胞的结合特别低(接近0%)是期望特性,因为最近已证明具有CAR的单个高能白血病B细胞的转导诱导对疗法的抗性
选择适体A3t及其关联的(cognate)RA可用于在完全合成的系统中实现无痕T细胞分离,其中将固定化适体用于分离T细胞,随后通过添加破坏适体用于结合的二级结构的RA而将其释放(图13A)。通过使用免疫磁性抗生物素微珠(Miltenyi Biotec)进行适体固定来实施该策略,并针对其从三个健康供体PBMC群中以高纯度和高产率分离CD8
从使用加载有适体的微珠的FT级分中观察到CD8
为了证实适体分离的细胞与抗体分离的细胞相似,使用流式细胞术表型分析和NanoString
由基于适体的无痕细胞分离物中产生CAR T细胞
尽管紧随分离后在适体分离和抗体分离的细胞之间几乎没有观察到差异,但是有必要确认对于使用这些不同分离方法产生的最终CAR T细胞产物,这是否仍然成立。从图13D-图13F中所示的无痕适体分离的细胞(RAE级分)和抗体分离的细胞两者产生CD8
在两周的刺激期内,在未转导的抗体分离和适体分离的空白对照T细胞之间未观察到过度生长差异(图16C)。这与在两周刺激过度生长结束时在来自不同分离方法的两种空白对照和CD19 CAR T细胞之间发现的相似的Ki-67表达相一致(图16D);并且毫不意外的是,这些细胞在REP期间生长相同(图18)。在S1D14对PD1、TIM3和LAG3(激活和耗竭二者的标志物)共表达的染色显示在两周刺激过度生长结束时,来自不同分离方法的细胞之间这些标志物的积累存在小差异(图16E和图19)。与抗体分离的细胞相比,观察到适体分离的CD19CAR T细胞损失单独的TIM3
针对骨髓性白血病K562细胞系(其经转导以分别稳定表达OKT3 Fab和CD19来用于CD3和CAR接合(engagement))以及B淋巴瘤Raji细胞(其组成性表达中等水平CD19)评价了抗肿瘤效应物功能(图22)。在体外进行肿瘤攻击(challenge)后,适体分离的CD19 CAR T细胞以与抗体分离的细胞相似的程度裂解所有三种细胞类型,并分泌相同量的效应细胞因子TNFα和IFNγ(图16G-图16H)。因此,由基于适体的无痕分离策略衍生而来的CAR T细胞在体外的表现达到了由广泛使用的基于抗体的分离衍生而来的细胞的标准。
适体分离的CAR T细胞在系统性Raji肿瘤小鼠模型中的表现
CAR T细胞的体外细胞毒性结果并不总是与体内结果互相印证。因此,尽管在体外观察到抗体分离和适体分离的CD8+CAR T细胞的效应物功能几乎没有差异,但重要的是进一步证明这可以转化至体内。为此,使用了先前描述的CAR T细胞应激测试的较不严格的版本,其中,在REP结束时(S1R1D14)用来自不同分离方法的非治愈剂量的CD8+CD19 CAR T细胞处理荷有Raji的NSG小鼠。如前所述,用5×10
由于缺乏对治疗持续性而言关键的CD4+CAR T细胞亚群,该模型中2×10
因此,本文提供的T细胞应激研究设计将能够严格鉴别抗体分离和适体分离的CART细胞之间的抗肿瘤效应物功能的任何差异。然而,在体内,不断观察到抗体分离和适体分离的CD8+CAR T细胞之间具有相同的抗肿瘤活性。如通过肿瘤的光子通量所测量的,在多个供体中,在接受了来自不同分离方法的CAR T细胞的小鼠之间的肿瘤消退和复发动力学重叠(图23A)。尽管两种CAR T细胞治疗组的治疗均为非治愈性的(这表明成功的应激测试模型),但接受适体分离的CAR T细胞的小鼠与接受抗体分离的CAR T细胞的小鼠相比表现出相似的延长存活,这由生物学显著性(中位生存时间)和对数秩统计显著性二者所确定(图23B)。这些结果进一步说明,在CAR T细胞疗法的初始生产步骤中,具有链置换的无痕的基于适体的细胞分离是基于抗体的分离的可行替代方法,其对最终细胞产品的质量产生的下游影响可忽略不计。
CAR T细胞疗法的挑战在于与生产临床产品相关的时间和成本。由于最近的文献表明与从非均质PBMC起始的不确定产品相比,选择不同T细胞亚群进行治疗可能提供改善且一致的临床结果,因此越来越急切需要开发出有效且具有成本效益的选择方法来满足这些新治疗组合物的需求
本文描述了高亲和力CD8a特异性适体的发现以及一种适体与逆转剂在无痕CD8+T细胞分离系统中的成功应用。仅使用适体,观察到与广泛使用的基于抗体的方法相比等效的CD8+T细胞选择产率。使用逆转剂用于无标记洗脱,观察到CD8+T细胞的选择产率>70%,纯度>95%。考虑到来自ALL患者的350mL-450mL单采血液分离产物将具有3-9×10
实施例中提供的竞争性SELEX方法对于选择CD8特异性适体特别有效。使用未受影响的CD4+原代T细胞或CD8-Jurkat T细胞系的SELEX策略可在鉴别与替代的T细胞抗原(例如CD3或CD4)结合的适体中提供好处。此外,使用经修饰的DNA文库可以扩大能够适用于用未经修饰的DNA文库进行高亲和力适体发现的蛋白质的范围。对于此类靶标,通过在文库设计中包含一个或两个修饰的碱基对而增加的化学多样性可能有助于高亲和力结合物的成功划分
适体可以容易地功能化以附着至固体支持物来进行亲和色谱分离,由此产生了纯合成的分离系统,而无需重组蛋白、磁性支持物以及与选择剂的预孵育。可以通过借助进一步的序列优化(较高的toehold GC含量、适体截短)以及适体和逆转剂的化学修饰(例如锁核酸)改进适体和逆转剂之间的链置换动力学来改善细胞释放效率
实施例2:材料和方法
寡核苷酸。
所有经研究的寡核苷酸由Integrated DNA Technologies合成。T细胞SELEX过程中使用的ssDNA文库经HPLC纯化,并由侧翼为两个18个碱基对(bp)恒定区的52bp的随机序列组成。带有IDT修饰代码的用于在SELEX轮次之间进行文库扩增的引物如下:正向5’-/56-FAM/ATCCAGAGTGACGCAGCA-3’(SEQ ID NO:105)和反向5’-/5BiosG/ACTAAGCCACCGTGTCCA-3’(SEQ ID NO:106)。分别合成的ssDNA适体列于表5中。
抗体和流式细胞术。
将以下染料、抗体和二抗用于染色细胞:Zombie Violet(100μL/1e6个细胞中1:500,BioLegend)、Zombie Yellow(100μL/1e6个细胞中1:500,BioLegend)、APC抗人CD4(1:100,300514,BioLegend)、PerCP/Cy5.5抗人CD8a(1:100,301031,BioLegend)、APC抗人CD8a(1:100,301014,BioLegend)、CD8-生物素(1:100,130-098-556,Miltenyi)、抗小鼠CD16/CD32Fc block(1:100,14-0161-86,eBioscience)、BV421抗小鼠CD8a(1:50,100737,BioLegend)、FITC抗小鼠CD3e(1:50,100305,BioLegend)、纯化的抗人CD3(克隆UCHT1,300402,BioLegend)、纯化的抗人CD8a(克隆RPA-T8,301002,BioLegend)、Super Bright600抗人CD19(1:20,63-0198-42,eBioscience)、Super Bright 702抗人CD56(1:100,67-0566-42,eBioscience)、PE抗人CD3(1:100,300308,BioLegend)、APC/Cy7抗人CD14、FITC抗人CD16(1:50,302006,BioLegend)、Alexa Fluor 700抗人CD3(1:50,300424,BioLegend)、Brilliant Violet 785抗人CD4(1:50,317442,BioLegend)、PE/Cy7抗人CD8a(1:200,300914,BioLegend)、BUV737小鼠抗人CD45RA(1:25,564442,BD Biosciences)、BUV395小鼠抗人CD45RO(1:25,564291,BD Biosciences)、PE抗人CD62L(1:400,304806,BioLegend)、Brilliant Violet 421抗人CCR7(1:25,353208,BioLegend)、爱必妥-生物素(1:500,Jensen Lab)、PE-Cy7小鼠抗Ki-67(1:20,561283,BD Biosciences)、BUV737小鼠抗人PD-1(1:20,565299,BD Biosciences)、Brilliant Violet 785抗人TIM-3(1:20,345032,BioLegend)、PE小鼠抗人LAG-3(1:20,565616,BD Biosciences)、Brilliant Violet 785抗人CD45RA(1:160,304140,BioLegend)、中性亲和素蛋白DyLight 633(1:500,22844,Invitrogen)、Alexa Fluor 647链霉亲和素(1:500,405237,BioLegend)以及PE链霉亲和素(1:500,405204,BioLegend)。使用OneComp eBead(Invitrogen)制备用于补偿的单色对照(如果需要)。经染色样品用MACSQuant Analyzer 10(Miltenyi)、Attune NxT(Invitrogen)或BD LSRFortessa(BD Biosciences)流式细胞仪进行分析。
细胞系培养和PBMC分离。
分别用于反向选择和核转染的J.RT3-T3.5和Jurkat(克隆E6-1)细胞系购自ATCC。如先前所描述的,T细胞快速扩增方案(REP)中使用的Epstein-Barr病毒转化的淋巴母细胞细胞系(TM-LCL)由单个核细胞制成
具有T细胞耗竭的竞争性细胞SELEX。
SELEX程序的示意图在图1中示出,各个轮次中使用的条件总结在表2中。SELEX方案改编自Sefah等
在轮次之间,使用0.02U/μL Phusion高保真DNA聚合酶(NEB)、1×Phusion GC缓冲液、500nM上文讨论的正向和反向引物二者以及200μM dNTP通过PCR(98℃下10s,56℃下30s,72℃下30s)扩增剩余的ssDNA序列。在使用200μL ssDNA的2mL大制备PCR反应之前,总是进行使用10μL ssDNA的100μL小分析PCR反应和2%琼脂糖凝胶电泳,以确定大的非特异性扩增子出现之前的最佳循环数。用高容量中性亲和素琼脂糖树脂(Thermo Scientific)、1M NaOH和脱盐illustra NAP-5柱(GE)产生用于随后轮次的SELEX和流式细胞术轮次结合测定二者的FAM标记的ssDNA。ssDNA的量通过NanoDrop 2000c分光光度法(ThermoScientific)进行定量,并通过Savant ISS110 SpeedVac干燥(Thermo Scientific)进行浓缩。
在所有SELEX轮次和结合测定中使用的洗涤缓冲液配方为0.22μm过滤的500mL含钙和镁的DPBS(Corning),其补充有2.25g葡萄糖(最终25mM)和2.5mL 1M MgCl
适体结合测定。
将细胞(200,000个)与100μL折叠的FAM标记的ssDNA池或FAM/生物素标记的单个适体在结合缓冲液中以所指示的浓度在4℃孵育30分钟。对于抗体竞争和用抗体进行多色流式细胞术染色,将抗体添加到与适体的初次孵育中。将细胞在补充有1%(重量/体积)BSA的200μL洗涤缓冲液中洗涤两次,以去除过量的适体。如果使用的适体经生物素化,则使细胞经历与100μL荧光标记的链霉亲和素或中性亲和素在4℃在含有1%(重量/体积)BSA的洗涤缓冲液中进行20min的二次孵育,并洗涤两次。将经染色的细胞在200μL含有1%(重量/体积)BSA和0.1%PFA的洗涤缓冲液中固定,然后通过流式细胞术进行分析。
下一代测序和数据分析。
根据制造商说明使用MiSeq Reagent Kit v2(300个循环)和MiSeq系统(Illumina)用表2中列出的条形码引物对起始原初文库和来自每个SELEX轮次的ssDNA池进行PCR扩增以用于测序。导出的FASTA文件用FASTAptamer软件进行分析
siRNA敲减。
将10e6个解冻的CD8
质粒敲入。
CD8a-hnRNP-M-EGFP来自Addgene(质粒#86054)
鼠脾细胞分离和染色。
将C57BL/6x DBA/2J小鼠用三溴乙醇安乐死并用20mL PBS灌注以限制凝血
生物层干涉术。
BLI研究在25℃下在FortéBio Octet Red96仪器上进行,以1000rpm进行样品震荡。用于所有步骤的样品缓冲液由具有0.01%tween-20的结合缓冲液组成。链霉亲和素包被的生物传感器加载有50nM生物素化适体,直到所有传感器(参考除外)达到捕获阈值0.5nm。在单独的缓冲液中漂洗100秒钟并进行基线步骤后,将传感器暴露于范围为150nM至5.56nM的1:3稀释系列的重组人CD8a蛋白(Sino Biological)。监测与蛋白质的缔合1200秒,并在单独的缓冲液中进行解离600秒。使用Octet Data Analysis 9.0软件(FortéBio)进行数据分析。通过对来自蛋白稀释系列的数种经处理的缔合和解离曲线进行全局拟合至1:1结合模型,计算动力学常数。通过R2和χ2值评价拟合质量。
与先前报道的适体的比较。
以序列5’-CTACAGCTTGCTATGCTCCCCTTGGGGTA/iSp18//3Bio/-3’(SEQ ID NO:111)合成如Wang等所述的CD8Ap17s
逆转剂优化。
设计了与适体A3t的3'末端互补的36bp的逆转剂(表5)。如上所述,首先用二级荧光链霉亲和素标记进行5nM适体A3t与CD8
从PBMC中无痕选择CD8
对于每个PBMC供体,将抗生物素微珠(Miltenyi)的两份100μL等分样品各自在含有5nM适体A3t的结合缓冲液中稀释至500μL,并在4℃在温和旋转下孵育15min。结合缓冲液中的tRNA在此步骤中很关键,因为需要tRNA来阻断逆转剂的非特异性结合以用于有效的下游细胞洗脱(数据未示出)。然后将适体标记的珠悬浮液合并,添加到200×10
通过流式细胞术用两个抗体组对所有级分进行计数和分析:(i)针针对CD3、CD8和CD16表达的产率组染色;以及(ii)针对CD3、CD4、CD8、CD45RA、CD45RO、CCR7和CD62L表达的表型组染色。此外,将来自抗体分离的CF级分和适体分离的RAE级分二者的1e6个细胞沉淀物在干冰和乙醇上快速冷冻,用于NanoString
CD19 CAR T细胞生产。
将来自每个供体的两种分离方法的CD8
如前所述,使用2周快速扩增方案(REP)进一步扩增经2周刺激的T细胞
NanoString
将解冻的细胞沉淀以3,500个细胞/μL重悬在含有β-巯基乙醇的RLT裂解缓冲液中,并根据制造商说明运行与
抗肿瘤细胞毒性测定。
将K562+OKT3、K562+CD19和Raji亲本靶细胞各自以5e6个细胞接种在12孔板的孔中的4mL完全RPMI中,并向含有细胞的各孔加入75μL Cr-51(Perkin Elmer)。一天后收获细胞,并以5,000个细胞/孔以100μL接种在96孔板中。将100μL中的S1R1D14 CD8
抗肿瘤细胞因子释放测定。
将K562+OKT3、K562+CD19和Raji亲本靶细胞以50,000个细胞/孔以100μL铺板于96孔板中。向靶细胞以100,000个细胞/孔添加100μL中的S1R1D14 CD8
T细胞应激测试小鼠模型。
通过尾静脉注射用200μL PBS中的5×10
统计分析。
数据表示为平均值±s.d.,并且生物学重复和技术重复的数量在附图标题(caption)中示出。如果仅比较两个群,则使用双尾t检验进行假设检验;否则,当比较多于两个群时,使用方差分析或ANOVA进行假设检验。通常实施配对假设检验来解释大的供体间变异(donor-to-donor variability)。在进行多重比较时,当将每个平均值与每个其它平均值或对照平均值进行比较时,分别使用Tukey检验或Dunnett检验来调整P值;而在比较选择的一组平均值时,使用Sidak校正来调整P值(假设独立性)。如果不能假定比较是相互独立的,则使用Bonferroni校正代替Sidak校正来调整P值。将Benjamini-Yekutieli校正用于NanoString数据的分析,因为该方法良好地处理不同基因表达之间的依赖性。如果在进行任何调整后P<0.05,则认为差异具有显著性。除非另有说明,否则使用Prism7.0软件(GraphPad)进行绘图和统计检验。
实施例3:额外适体的表征
实施例1中所述的适体A1、A2、A3、A7和A8也可以以如图4所示的替代二级结构存在。还使用来自图4的相应适体测试了预测的适体逆转剂的不同碱基对长度。使用52个碱基对的单链DNA文库鉴别对CD8+T细胞具有特异性的适体。
所测试的逆转剂长度对于A1适体为40个碱基对,对于A3适体为42个碱基对,对于A8适体为37个碱基对(图24A)。使用实施例2中所述的方案,用适体和相应逆转剂进行的共孵育实验引起适体结合显著降低(图24A,底部)。此外,对于适体A3,适体碱基对长度可以从20个碱基对到85个碱基对的长度进行优化(图24B)。预测了实施例1中描述的A3适体的额外二级结构。理论A3适体在图25中示出。对于实施例1中所述的适体A3t,图26中描述了数种A3t适体二级结构预测。这些适体包括截短的A3t(图26,左侧结构),将适体的toehold中的鸟嘌呤核苷酸数量变化为4个鸟嘌呤(图26,中间结构)或6个鸟嘌呤(图26,右侧结构)。
实施例4:TCBA.1适体
为了进一步鉴别对T细胞特异性结合具有特异性的适体,利用45个核苷酸的ssDNA文库对T细胞实施了额外的SELEX,并对各轮次进行测序以鉴别选择性结合T细胞亚群的适体(图27)。适体CD3.CD28.A1显示出与PBMC中的CD3+群的优先结合,与CD3+CD28-细胞的结合水平最高。在图28-图32中,将CD3.CD28.A1适体重命名为TCBA.1(T细胞结合适体)。预测了TCBA.1的二级结构(图28)以及序列的截短(TCBA.1-tr1、碱基对3-75;TCBA.1-tr2、碱基对13-54)。通过流式细胞术分析确定结合常数(图28)。TCBA.1对于结合PBMC中的CD3+群具有1nM-2nM的kD,对CD3+CD28-具有更高的最大结合。TCBA.1-tr1以较低的亲和力结合,TCBA.1-tr2则完全不结合(数据未示出)。此外,TCBA.1不结合H9、Jurkat、Jurkat/CD3KO和Jurkat/CD28KO细胞。
除了52个碱基对的ssDNA文库外,还可以使用45个核苷酸的文库来鉴别T细胞适体。使用45个核苷酸的文库和SELEX策略进一步优化适体TCBA.1(图29)。预测的TCBA.1二级结构与本文描述的额外适体一起通过可在万维网上随http://www.unpack.org获得的UNPACK在4℃确定。
为了确定TCBA.1的激活和选择,将PBMC与100nM TCBA.1-生物素适体在4℃下孵育30分钟,随后添加抗生物素磁珠,洗涤,并施加至磁性分离柱。将收集的细胞关于CD4、CD8、CD2、抗体染色以及TCBA.1-FITC适体结合进行分析(图30)。TCBA.1适体将CD8+细胞下拉。
基于先前的结果,CD8被评价为TCBA.1的潜在受体(图31)。抗CD8抗体和TCBA.1适体结合的流式细胞术研究在用CD8 siRNA对细胞进行核转染后24小时进行。CD8受体的84%KD与适体结合的60.4%减少之间存在正相关。
将抗CD8和TCBA.1适体关于从PBMC分离CD8+T细胞进行比较(图32)。将PBMC与抗CD8-生物素抗体(REA734)或TCBA.1-生物素和抗生物素磁珠一起孵育,然后将其施加至MS柱上。通过流式细胞术分析流穿(FT)和下拉(PD)细胞对CD8抗体和TCBA.1适体的结合。观察到用TCBA.1下拉的细胞中有85%为CD8阳性。因此,TCBA.1和CD8下拉细胞均显示高TCBA.1结合。
如图33中所详述的,确定了用TCBA.1适体分离CD8+细胞的方法。用生物素化适体标记PBMC。然后用磁性链霉亲和素珠标记这些细胞。在标记步骤后,无标记细胞通过链置换而特异性释放。这种方法的优点包括,没有分离剂对细胞的污染以及无需连续选择方法。
使用图34中描述的解毒剂探索了使用互补DNA链来逆转适体结合。解毒剂的二级结构(图34)和序列(图34,上)也在图34中示出。在添加或不添加解毒剂的情况下,将CD8+T细胞与TCBA.1以10nM和25nM在3种不同温度下孵育。随着温度升高,观察到适体结合的减少。与解毒剂共孵育将结合降低高达90%,在更高温度下更是如此。在37℃时实现了结合降低高达60%,这可能是较低的结合、适体结构较不稳定的组合导致的结果。二级结构的未来变化将包括为toehold增加解毒剂的柄(grip)区域,并在各种温度(例如4℃或>37℃)下结合适体。
实施例5:LO和HI CD8 T细胞的分离以及用两种适体进行分离确定低和高CD8标志物的洗脱以分离感兴趣的T细胞的表达梯度(图35)。表达CD8的细胞的洗脱取决于逆转剂(RA)孵育的温度、时间和适体浓度。图35中的图表示在用5nM A3t适体选择时在37℃下不同的逆转剂过量。为了获得较低的CD8表达子(expresser)(CD8
图36示出了如何实现用两种适体进行连续洗脱的示意图。用具有独特toehold和序列的CD4和CD8适体标记的PBMC将通过用CD4逆转剂洗脱而与未与适体结合的细胞分开,从而仅获得CD4阳性T细胞。先前的附图中鉴别的CD8逆转剂的顺序洗脱将允许CD8阳性T细胞的分离。通过允许大规模、特异性、无标签和可逆的细胞分离,这种细胞分离方法相对于先前描述的其它T细胞分离技术具有多个优势。
实施例6:结合Jurkat的DNA适体的表征
单链DNA适体由于其易于合成、活性均一和尺寸相对小而在多种生物学应用中可作为抗体的可行替代物。综上所述,这些特性不仅有助于降低生产成本,而且还可以改善组织穿透。此处,鉴别了优先结合T细胞白血病Jurkat细胞系的单链DNA适体。采用消减(subtractive)细胞-SELEX方法,使用野生型Jurkat细胞进行正选择,使用衍生突变体J.RT3-T3.5细胞系(CD3、CD28和T细胞受体α/β异二聚体阴性)进行反向选择。在8轮选择后,在反向选择细胞系上观察到与Jurkat细胞的选择性结合。通过下一代Illumina测序确定所有轮次中适体池的内容。进行系统进化树分析并鉴别潜在的共有结合位点。第8轮中出现频率最高的适体(表示为JBA8.1)具有低于100nM的结合亲和力。使用二级结构预测算法,创建了保持相似的结合亲和力的该适体的截短版本。该适体还结合分别由T细胞淋巴瘤和B细胞淋巴瘤衍生而来的H9和Raji细胞系;以及活化的人T细胞。当前的工作包括受体鉴别和评价用于肿瘤递送的治疗性负载。
实施例7:用于CAR T细胞疗法的通过可逆的基于适体的选择进行的CD8+T细胞的无痕分离
使用明确的产品组合物的CAR T细胞疗法临床试验数量的增加凸显了持续开发用于选择特定T细胞亚群的稳健且具有成本效益的方法的需求。使用细胞-SELEX的改进方法,鉴别了优先结合人细胞毒性T细胞标志物CD8的新DNA适体。将这些适体中的一种与互补寡核苷酸逆转剂(其与适体经历toehold介导的链置换,从而破坏适体的二级结构)应用于无痕细胞分离策略,从而无标记地洗脱捕获的细胞。观察到该方法产生高产率的CD8+T细胞,并且由这些细胞生产的CAR T细胞在体内增殖、表型、效应物功能和抗肿瘤活性方面与抗体分离的CAR T细胞相当。这些发现代表了朝向用于T细胞选择的全合成系统的重要技术进步。
参考文献
1.Brentjens,R.J.et al.CD19-targeted T cells rapidly induce molecularremissions in adults with chemotherapy-refractory acute lymphoblasticleukemia.Sci.Trans!.Med.5,177ra138(2013).
2.Davila,M.L.et al.Efficacy and toxicity management of 19-28z CAR Tcell therapy in B cell acute
lymphoblastic leukemia.Sci.Trans!.Med.6,224ra225(2014).
3.Lee,D.W.et al.T cells expressing CD19 chimeric antigen receptorsfor acute lymphoblastic leukaemia in children and young adults:a phase 1dose-escalation trial.Lancet 385,517-528(2015).
4.Mirzaei,H.R.,Rodriguez,A.,Shepphird,J.,Brown,C.E.&Badie,B.ChimericAntigen Receptors T Cell Therapy in Solid Tumor:Challenges and ClinicalApplications.Front.Immuno!.8,1850(2017).
5.Hale,M.et al.Engineering HIV-Resistant,Anti-HIV Chimeric AntigenReceptor T Cells.Mo!.Ther.25,570-579(2017).
6.Scholler,J.et al.Decade-long safety and function of retroviral-modified chimeric antigen receptor T cells.Sci.Transl.Med.4,132ral53(2012).
7.Sommermeyer,D.et al.Chimeric antigen receptor-modified T cellsderived from defined CD8+and CD4+subsets confer superior antitumor reactivityin vivo.Leukemia 30,492-500(2016).
8.Turtle,C.J.et al.CD 19 CAR-T cells of defined CD4+:CD8+compositionin adult B cell ALL patients.J.Clin.Invest.126,2123(2016).
9.Gardner,R.A.et al.Intent-to-treat leukemia remission by CD19 CAR Tcells of defined formulation and dose in children and young adults.B!ood 129,3322-3331(2017).
10.Aijaz,A.et al.Biomanufacturing for clinically advanced celltherapies.Nat.Biomed.Eng.2,362-376(2018).
11.Terakura,S.et al.Generation of CD19-chimeric antigen receptormodified CD8+T cells derived from virus-specific central memory T cells.B!ood119,72-82(2012).
12.Wang,X.et al.Phenotypic and functional attributes of lentivirus-modified CD 19-specific human CD8+central memory T cells manufactured atclinical scale.J.Immunother.35,689-701(2012).
13.Voss,S.&Skerra,A.Mutagenesis ora flexible loop in streptavidinleads to higher affinity for the Strep-tag II peptide and improvedperformance in recombinant protein purification.Protein Eng.10,975-982(1997).
14.Knabel,M.et al.Reversible MHC multimer staining for functionalisolation of T-cell populations and effective adoptive transfer.Nat.Med.8,631-637(2002).
15.Schmitt,A.et al.Adoptive transfer and selective reconstitution ofstreptamer-selected cytomegalovirus-specific CD8+T cells leads to virusclearance in patients after allogeneic peripheral blood stem celltransplantation.Transfusion 51,591-599(2011).
16.Stemberger,C.et al.Novel serial positive enrichment technologyenables clinical multiparameter cell sorting.PLoS One 7,e35798(2012).
17.Sabatino,M.et al.Generation of clinical-grade CD19-specific CAR-modified CD8+memory stem cells for the treatment of human B-cellmalignancies.Blood 128,519-528(2016).
18.Ellington,A.D.&Szostak,J.W.In vitro selection of RNA moleculesthat bind specific ligands.Nature 346,818(1990).
19.Tuerk,C.&Gold,L.Systematic evolution ofligands by exponentialenrichment:RNA ligands to
bacteriophage T4 DNA polymerase.Science 249,505-510(1990).
20.Robertson,D.L.&Joyce,G.F.Selection in vitro of an RNA enzyme thatspecifically cleaves single-stranded DNA.Nature 344,467(1990).
21.Bunka,D.H.&Stockley,P.G.Aptamers come of age-atlast.Nat.Rev.Microbiol.4,588-596(2006).
22.Hernandez,L.I.,Machado,I.,Schafer,T.&Hernandez,F.J.Aptamersoverview:selection,features and applications.Curr.Top.Med.Chem.15,1066-1081(2015).
23.Zhou,J.&Rossi,J.Aptamers as targeted therapeutics:currentpotential and challenges.Nat.Rev.Drug
Discov.16,181-202(2017).
24.Dunn,M.R.,Jimenez,R.M.&Chaput,J.C.Analysis ofaptamer discovery andtechnology.Nat.Rev.Chem.1,0076(2017).
25.Daniels,D.A.,Chen,H.,Hicke,B.J.,Swiderek,K.M.&Gold,L.A tenascin-Captamer identified by tumor cell SELEX:systematic evolution of ligands byexponential enrichment.Proc.Natl.Acad.Sci.U.S.A.100,15416-15421(2003).
26.Shangguan,D.et al.Aptamers evolved from live cells as effectivemolecular probes for cancer study.Proc.Natl.Acad.Sci.U.S.A.103,11838-11843(2006).
27.Ogasawara,D.,Hasegawa,H.,Kaneko,K.,Sode,K.&Ikebukuro,K.Screeningof DNA aptamer against mouse prion protein by competitive selection.Prion 1,248-254(2007).
28.Sefah,K.,Shangguan,D.,Xiong,X.,O′Donoghue,M.B.&Tan,W.Developmentof DNA aptamers using Cell-SELEX.Nat.Protoc.5,1169-1185(2010).
29.A!am,K.K.,Chang,J.L.&Burke,D.H.FASTAptamer:A Bioinformatic Toolkitfor High-throughput Sequence Analysis of CombinatorialSelections.Mol.Ther.Nucleic Acids 4,e230(2015).
30.Caroli,J.,Taccioli,C.,De La Fuente,A.,Serafini,P.&Bicciato,S.APTANI:a computational tool to select aptamers through sequence-structuremotif analysis of HT-SELEX data.Bioinformatics 32,161-164(2015).
31.Bailey,T.L.et al.MEME SUITE:tools for motif discovery andsearching.Nucleic Acids Res.37,W202-208(2009).
32.Chen,L.et al.Aptamer-mediated efficient capture and release of Tlymphocytes on nanostructured
surfaces.Adv.Mater.23,4376-4380(2011).
33.Li,S.,Chen,N.,Zhang,Z.&Wang,Y.Endonuclease-responsive aptamer-functionalized hydrogel coating for sequential catch and release of cancercells.Biomaterials 34,460-469(2013).
34.Xu,Y.et al.Aptamer-based microfluidic device for enrichment,sorting,and detection of multiple cancer cells.Anal.Chem.81,7436-7442(2009).
35.Yoon,J.W.et al.Isolation of Foreign Material-Free EndothelialProgenitor Cells Using CD31 Aptamer and Therapeutic Application for IschemicInjury.PLoS One 10,e0131785(2015).
36.Zhu,J.,Nguyen,T.,Pei,R.,Stojanovic,M.&Lin,Q.Specific capture andtemperature-mediated release of cells in an aptamer-based microfluidicdevice.Lab Chip 12,3504-3513(2012).
37.Labib,M.et al.Aptamer and Antisense-Mediated Two-DimensionalIsolation of Specific Cancer Cell Subpopulations.J.Am.Chem.Soc.138,2476-2479(2016).
38.Sun,N.Et al.Chitosan Nanofibcrs for Specific Capture andNondestructive Release of CTCs Assisted by pCBMA Brushes.Small 12,5090-5097(2016).
39.Wan,Y.et al.Capture,isolation and release of cancer cells withaptamer-functionalized glass bead array.Lab Chip 12,4693-4701(2012).
40.Zhang,Z.,Chen,N.,Li,S.,Battig,M.R.&Wang,Y.Programmable hydrogelsfor controlled cell catch and release using hybridized aptamers andcomplementary sequences.J.Am.Chem.Soc.134,15716-15719(2012).
41.Nozari,A.&Berezovski,M.V.Aptamers for CD Antigens:From CellProfiling to Activity Modulation.Mol.Ther.Nucleic Acids 6,29-44(2017).
42.Wang,C.-W.et al.A new nucleic acid-based agent inhibits cytotoxicT lymphocyte-mediated immune disorders.J.Allergy Clin.Immunol.132,713-722.e711(2013).
43.Seelig,G.,Soloveichik,D.,Zhang,D.Y.&Winfree,E.Enzyme-free nucleicacid logic circuits.Science 314,1585-1588(2006).
44.Yurke,B.&Mills,A.P.Using DNA to power nanostructures.Genet ProgramEvol M 4,111-122(2003).
45.Yurke,B.,Turberfield,A.J.,Mills,A.P.,Jr.,Simmel,F.C.&Neumann,J.L.ADNA-fuelled molecular machine made of DNA.Nature 406,605-608(2000).
46.Zhang,D.Y.&Seelig,G.Dynamic DNA nanotechnology using strand-displacement reactions.Nat.Chem.3,103-113(2011).
47.Zhang,D.Y.&Winfree,E.Control of DNA strand displacement kineticsusing toehold exchange.J.Am.Chem.Soc.131,17303-17314(2009).
48.Ruella,M.et al.Induction of resistance to chimeric antigenreceptor T cell therapy by transduction of a single leukemic Bcell.Nat.Med.24,1499-1503(2018).
49.Heczey,A.et al.Invariant NKT cells with chimeric antigen receptorprovide a novel platformfor safe and effective cancer immunotherapy.Blood124,2824-2833(2014).
50.Eyquem,J.et al.Targeting a CAR to the TRAC locus with CRISPR/Cas9enhances tumour rejection.Nature543,113-117(2017).
51.Zhao,Z.et al.Structural Design of Engineered CostimulationDetermines Tumor Rejection Kinetics and Persistence of CAR T Cells.CancerCell 28,415-428(2015).
52.Brentjens,R.J.et al.Eradication of systemic B-cell tumors bygenetically targeted human T lymphocytes co-stimulated by CD80 andinterleukin-15.Nat.Med.9,279-286(2003).
53.Dahotre,S.N.,Chang,Y.M.,Wieland,A.,Stammen,S.R.&Kwong,G.A.Individually addressable and dynamic DNA gates for multiplexed cell sorting.Proc.Natl.Acad.Sci.U.S.A.115,4357-4362(2018).
54.Probst,C.E.,Zrazhevskiy,P.&Gao,X.Rapid multitarget immunomagneticseparation through
programmable DNA linker displacement.J.Am.Chem.Soc.133,17126-17129(2011).
55.Gawande,B.N.et al.Selection of DNA aptamers with two modified bases.Proc.Natl.Acad.Sci.U.S.A.114,2898-2903(2017).
56.Ni,S.et al.Chemical Modifications of Nucleic Acid Aptamers forTherapeutic Purposes.Int.J.Mol.Sci.18,1683(2017).
57.Pelloquin,F.,Lamelin,J.&Lenoir,G.Human blymphocytesimmortalization by epstein-barr virus in the presence of cyclosporin a.InVitro Cell.Dev.Biol.22,689-694(1986).
58.Zadeh,J.N.et al.NUPACK:Analysis and design of nucleic acidsystems.J.Comput.Chem.32,170-173(2011).
59.Tsai,H.H.et al.Regional astrocyte allocation regulates CNSsynaptogenesis and repair.Science 337,358-362(2012).
60.Madugula,V.&Lu,L.A ternary complex comprising transportinl,Rab8and the ciliary targeting signal directs proteins to ciliary membranes.J.CellSci.129,3922-3934(2016).
61.Wang,J.et al.Optimizing adoptive polyclonal T cell immunotherapyof lymphomas,using a chimeric T cell receptor possessing CD28 and CD137costimulatory domains.Hum.Gene Ther.18,712-725(2007).
序列表
<110> 华盛顿大学
西雅图儿童医院 D/B/A西雅图儿童
研究所
<120> 涉及基于适体的可逆细胞选择的组合物和方法
<130> 034186-092710WOPT
<140>
<141>
<150> 62/779,946
<151> 2018-12-14
<150> 62/699,438
<151> 2018-07-17
<160> 118
<170> PatentIn version 3.5
<210> 1
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 1
atccagagtg acgcagcacg cagcacccgt ggtagtgtat cagggagaca ctacgtgatg 60
cagcttgaaa tggacacggt ggcttagt 88
<210> 2
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 2
atccagagtg acgcagcacg cagcaaggtg gctgtgggcg gatggtgggc tcgcgtgggc 60
ggccacctga tggacacggt ggcttagt 88
<210> 3
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 3
atccagagtg acgcagcaac agaggtgtag aagtacacgt gaacaagctt gaaattgtct 60
ctgacagagg tggacacggt ggcttagt 88
<210> 4
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 4
atccagagtg acgcagcatt aggaggtggg ctcgcgtgca ccaatccatg gtcggcggga 60
attttaaggg tggacacggt ggcttagt 88
<210> 5
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 5
atccagagtg acgcagcagc tcgatcgtat agccgtgacg cagcttgaaa tgggatcgcg 60
tccacagttt tggacacggt ggcttagt 88
<210> 6
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 6
ccagagtgac gcagcaacag aggtgtagaa gtacacgtga acaagcttga aattgtctct 60
gacagaggtg gacacggtgg cttttagt 88
<210> 7
<211> 36
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 7
actaaaagcc accgtgtcca cctctgtcag agacaa 36
<210> 8
<211> 27
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 8
actaagccac cgtgtccatt tcaagct 27
<210> 9
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 9
atccagagtg acgcagcacg cagcacccgt ggtagtgtat cagggagaca ctacgtgatg 60
cagcttgaaa tggacacggt ggcttagt 88
<210> 10
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 10
taggtctcac tgcgtcgtgc gtcgtgggca ccatcacata gtccctctgt gatgcactac 60
gtcgaacttt acctgtgcca ccgaatca 88
<210> 11
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 11
taggtctcac tgcgtcgttg tctccacatc ttcatgtgca cttgttcgaa ctttaacaga 60
gactgtctcc acctgtgcca ccgaatca 88
<210> 12
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 12
taggtctcac tgcgtcgtaa tcctccaccc gagcgcacgt ggttaggtac cagccgccct 60
taaaattccc acctgtgcca ccgaatca 88
<210> 13
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 13
taggtctcac tgcgtcgtcg agctagcata tcggcactgc gtcgaacttt accctagcgc 60
aggtgtcaaa acctgtgcca ccgaatca 88
<210> 14
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 14
ggtctcactg cgtcgttgtc tccacatctt catgtgcact tgttcgaact ttaacagaga 60
ctgtctccac ctgtgccacc gaaaatca 88
<210> 15
<211> 36
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 15
tgattttcgg tggcacaggt ggagacagtc tctgtt 36
<210> 16
<211> 27
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 16
tgattcggtg gcacaggtaa agttcga 27
<210> 17
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 17
tgattcggtg gcacaggtaa agttcgacgt agtgcatcac agagggacta tgtgatggtg 60
cccacgacgc acgacgcagt gagaccta 88
<210> 18
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 18
tgattcggtg gcacaggtag tccaccggcg ggtgcgctcg ggtggtaggc gggtgtcggt 60
ggaacgacgc acgacgcagt gagaccta 88
<210> 19
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 19
tgattcggtg gcacaggtgg agacagtctc tgttaaagtt cgaacaagtg cacatgaaga 60
tgtggagaca acgacgcagt gagaccta 88
<210> 20
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 20
tgattcggtg gcacaggtgg gaattttaag ggcggctggt acctaaccac gtgcgctcgg 60
gtggaggatt acgacgcagt gagaccta 88
<210> 21
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 21
tgattcggtg gcacaggtaa agttcgacgt agtgcatcac agagggacta tgtgatggtg 60
cccacgacgc acgacgcagt gagaccta 88
<210> 22
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 22
tgattttcgg tggcacaggt ggagacagtc tctgttaaag ttcgaacaag tgcacatgaa 60
gatgtggaga caacgacgca gtgagacc 88
<210> 23
<211> 36
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 23
aacagagact gtctccacct gtgccaccga aaatca 36
<210> 24
<211> 27
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 24
tcgaacttta cctgtgccac cgaatca 27
<210> 25
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 25
actaagccac cgtgtccatt tcaagctgca tcacgtagtg tctccctgat acactaccac 60
gggtgctgcg tgctgcgtca ctctggat 88
<210> 26
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 26
actaagccac cgtgtccatc aggtggccgc ccacgcgagc ccaccatccg cccacagcca 60
ccttgctgcg tgctgcgtca ctctggat 88
<210> 27
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 27
actaagccac cgtgtccacc tctgtcagag acaatttcaa gcttgttcac gtgtacttct 60
acacctctgt tgctgcgtca ctctggat 88
<210> 28
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 28
actaagccac cgtgtccacc cttaaaattc ccgccgacca tggattggtg cacgcgagcc 60
cacctcctaa tgctgcgtca ctctggat 88
<210> 29
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 29
actaagccac cgtgtccatt tcaagctgca tcacgtagtg tctccctgat acactaccac 60
gggtgctgcg tgctgcgtca ctctggat 88
<210> 30
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 30
actaaaagcc accgtgtcca cctctgtcag agacaatttc aagcttgttc acgtgtactt 60
ctacacctct gttgctgcgt cactctgg 88
<210> 31
<211> 36
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 31
ttgtctctga cagaggtgga cacggtggct tttagt 36
<210> 32
<211> 27
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 32
agcttgaaat ggacacggtg gcttagt 27
<210> 33
<211> 82
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 33
atccagagtg acgcagcacg cagcacccgt ggtagtgtat cagggagaca ctacgtgatg 60
cagcttgaaa tggacacggt gg 82
<210> 34
<211> 82
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 34
atccagagtg acgcagcacg cagcaaggtg gctgtgggcg gatggtgggc tcgcgtgggc 60
ggccacctga tggacacggt gg 82
<210> 35
<211> 80
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 35
ccagagtgac gcagcaacag aggtgtagaa gtacacgtga acaagcttga aattgtctct 60
gacagaggtg gacacggtgg 80
<210> 36
<211> 82
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 36
atccagagtg acgcagcatt aggaggtggg ctcgcgtgca ccaatccatg gtcggcggga 60
attttaaggg tggacacggt gg 82
<210> 37
<211> 83
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 37
atccagagtg acgcagcagc tcgatcgtat agccgtgacg cagcttgaaa tgggatcgcg 60
tccacagttt tggacacggt ggc 83
<210> 38
<211> 80
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 38
ccagagtgac gcagcaacag aggtgtagaa gtacacgtga acaagcttga aattgtctct 60
gacagaggtg gacacggtgg 80
<210> 39
<211> 90
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 39
atccagagtg acgcagcacg cagcacccgt ggtagtgtat cagggagaca ctacgtgatg 60
cagcttgaaa tggacacggt ggcttttagt 90
<210> 40
<211> 90
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 40
atccagagtg acgcagcacg cagcaaggtg gctgtgggcg gatggtgggc tcgcgtgggc 60
ggccacctga tggacacggt ggcttttagt 90
<210> 41
<211> 90
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 41
atccagagtg acgcagcatt aggaggtggg ctcgcgtgca ccaatccatg gtcggcggga 60
attttaaggg tggacacggt ggcttttagt 90
<210> 42
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 42
atccagagtg acgcagcagc tcgatcgtat agccgtgacg cagcttgaaa tgggatcgcg 60
tccacagttt tggacacggt ggcttagt 88
<210> 43
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 43
atccagagtg accgtcgtgc gtcgtgggca ccatcacata gtccctctgt gatggtgatg 60
cagcttgaaa tggacacggt ggcttagt 88
<210> 44
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 44
atccagagtg accgtcgtgc gtcgttccac cgacacccgc ctaccacccg agcggtgggc 60
ggccacctga tggacacggt ggcttagt 88
<210> 45
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 45
atccagagtg accgtcgttg tctccacatc ttcatgtgca cttgttcgaa ctttttgtct 60
ctgacagagg tggacacggt ggcttagt 88
<210> 46
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 46
atccagagtg accgtcgtaa tcctccaccc gagcgcacgt ggttaggtac cagcgcggga 60
attttaaggg tggacacggt ggcttagt 88
<210> 47
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 47
taggtctcac tgcgtcgtcg agctagcata tcggcactgc gtcgaacttt accctagcgc 60
aggtgtcaaa acctgtgcca ccgaatca 88
<210> 48
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 48
ccagagtgac cgtcgttgtc tccacatctt catgtgcact tgttcgaact ttttgtctct 60
gacagaggtg gacacggtgg cttttagt 88
<210> 49
<211> 40
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 49
actaagccac cgtgtccatt tcaagctgca tcacgtagtg 40
<210> 50
<211> 42
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 50
actaagccac cgtgtccacc tctgtcagag acaatttcaa gc 42
<210> 51
<211> 37
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 51
actaagccac cgtgtccaaa actgtggacg cgatccc 37
<210> 52
<211> 85
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 52
cacagtgacg cagcaacaga ggtgtagaag tacacgtgaa caagcttgaa attgtctctg 60
acagaggtgg acactgtgtc ttagt 85
<210> 53
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 53
actaagacac agtgtccacc 20
<210> 54
<211> 35
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 54
actaagacac agtgtccacc tctgtcagag acaat 35
<210> 55
<211> 50
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 55
actaagacac agtgtccacc tctgtcagag acaatttcaa gcttgttcac 50
<210> 56
<211> 65
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 56
actaagacac agtgtccacc tctgtcagag acaatttcaa gcttgttcac gtgtacttct 60
acacc 65
<210> 57
<211> 85
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 57
actaagacac agtgtccacc tctgtcagag acaatttcaa gcttgttcac gtgtacttct 60
acacctctgt tgctgcgtca ctgtg 85
<210> 58
<211> 25
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 58
actaagacac agtgtccacc tctgt 25
<210> 59
<211> 30
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 59
actaagacac agtgtccacc tctgtcagag 30
<210> 60
<211> 35
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 60
actaagacac agtgtccacc tctgtcagag acaat 35
<210> 61
<211> 40
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 61
actaagacac agtgtccacc tctgtcagag acaatttcaa 40
<210> 62
<211> 45
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 62
actaagacac agtgtccacc tctgtcagag acaatttcaa gcttg 45
<210> 63
<211> 50
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 63
actaagacac agtgtccacc tctgtcagag acaatttcaa gcttgttcac 50
<210> 64
<211> 81
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 64
ccagagtgac gcagcacccg tggtagtgta tcagggagac actacgtgat gcagcttgaa 60
atggacacgg tggcttttag t 81
<210> 65
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 65
ccagagtgac gcagcaacag aggtgtagaa gtacacgtga acaagcttga aattgtctct 60
gacagaggtg gacacggtgg aaggaagg 88
<210> 66
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 66
ccagagtgac gcagcaacag aggtgtagaa gtacacgtga acaagcttga aattgtctct 60
gacagaggtg gacacggtgg gagggagg 88
<210> 67
<211> 45
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 67
ccaccaccgt acaattcgct ttcttttttc attacctact ctggc 45
<210> 68
<211> 45
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 68
ccaccagtca aatttcatcg tcactttatt tcattcgcac tctgg 45
<210> 69
<211> 27
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 69
tccccgacct tttctttctc tttcgca 27
<210> 70
<211> 28
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 70
ccacgcacca tctatttcct ttttcgcc 28
<210> 71
<211> 40
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 71
ccaccacacc ttcatcttac ttcatttcta tcgcgcttca 40
<210> 72
<211> 27
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 72
ccatcccaac tcgttattct cgctcca 27
<210> 73
<211> 29
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 73
ccaccccgct atttcatctt tctcgctcc 29
<210> 74
<211> 39
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 74
ccaccacttt acctttttat tttgtctact ctcggtaca 39
<210> 75
<211> 44
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 75
ccaccagcga ttcatttcaa catcttctac tttttatccc tccc 44
<210> 76
<211> 31
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 76
tccacccgaa tcttgttatc cttccttcgc c 31
<210> 77
<211> 28
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 77
ccaccacgtt tattctttcg ctccctcc 28
<210> 78
<211> 59
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
引物
<400> 78
aatgatacgg cgaccaccga gatctacacc gaggagatac cactaagcca ccgtgtcca 59
<210> 79
<211> 61
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
引物
<400> 79
caagcagaag acggcatacg agatgcaatt cgacagaccg tcgatccaga gtgacgcagc 60
a 61
<210> 80
<211> 61
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
引物
<400> 80
caagcagaag acggcatacg agatcaagag gtacagaccg tcgatccaga gtgacgcagc 60
a 61
<210> 81
<211> 61
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
引物
<400> 81
caagcagaag acggcatacg agattcgatt aaacagaccg tcgatccaga gtgacgcagc 60
a 61
<210> 82
<211> 61
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
引物
<400> 82
caagcagaag acggcatacg agatgaatgg acacagaccg tcgatccaga gtgacgcagc 60
a 61
<210> 83
<211> 61
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
引物
<400> 83
caagcagaag acggcatacg agatagaatc agacagaccg tcgatccaga gtgacgcagc 60
a 61
<210> 84
<211> 61
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
引物
<400> 84
caagcagaag acggcatacg agataactgc caacagaccg tcgatccaga gtgacgcagc 60
a 61
<210> 85
<211> 52
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 85
cgcagcaccc gtggtagtgt atcagggaga cactacgtga tgcagcttga aa 52
<210> 86
<211> 52
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 86
cgcagcaagg tggctgtggg cggatggtgg gctcgcgtgg gcggccacct ga 52
<210> 87
<211> 52
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 87
acagaggtgt agaagtacac gtgaacaagc ttgaaattgt ctctgacaga gg 52
<210> 88
<211> 52
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 88
cgcagcaccc gtggtagtgt atcatggaga cactacgtga tgcagcttga aa 52
<210> 89
<211> 52
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 89
cgcagcaccc gtggtagtgt atcagggata cactacgtga tgcagcttga aa 52
<210> 90
<211> 52
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 90
cgcagcaccc gtggtagtgt atcagagaga cactacgtga tgcagcttga aa 52
<210> 91
<211> 52
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 91
ttaggaggtg ggctcgcgtg caccaatcca tggtcggcgg gaattttaag gg 52
<210> 92
<211> 52
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 92
gctcgatcgt atagccgtga cgcagcttga aatgggatcg cgtccacagt tt 52
<210> 93
<211> 52
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 93
cgcagcgccc gtggtagtgt atcagggaga cactacgtga tgcagcttga aa 52
<210> 94
<211> 52
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 94
cggccgaacc tccacccttc cgcagcgtag gcagactcgg atcatgataa tc 52
<210> 95
<211> 52
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 95
cgcagcagcc gtggtagtgt atcagggaga cactacgtga tgcagcttga aa 52
<210> 96
<211> 52
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 96
cgcagcaacc gtggtagtgt atcagggaga cactacgtga tgcagcttga aa 52
<210> 97
<211> 52
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 97
cgcagcaccc gtggtagtgt atcggggaga cactacgtga tgcagcttga aa 52
<210> 98
<211> 52
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 98
cgcagcaacg ttatcccctt tacggggtcc tagagccccg tgagtgctca cg 52
<210> 99
<211> 52
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 99
cgcagctccc gtggtagtgt atcagggaga cactacgtga tgcagcttga aa 52
<210> 100
<211> 52
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 100
cgcatcaccc gtggtagtgt atcagggaga cactacgtga tgcagcttga aa 52
<210> 101
<211> 52
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 101
cgcagcaccc gtggtagtgt atcagtgaga cactacgtga tgcagcttga aa 52
<210> 102
<211> 52
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 102
cgcagccccc gtggtagtgt atcagggaga cactacgtga tgcagcttga aa 52
<210> 103
<211> 52
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 103
acgcagcacc cgtggtagtg tatcaggaga cactacgtga tgcagcttga aa 52
<210> 104
<211> 52
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 104
cgcagcaccc gtggtagtgt atcagggaga cactacgtga tgcagcttaa aa 52
<210> 105
<211> 18
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
引物
<400> 105
atccagagtg acgcagca 18
<210> 106
<211> 18
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
引物
<400> 106
actaagccac cgtgtcca 18
<210> 107
<211> 25
<212> RNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 107
cgaggaggua augaauuaaa gaaga 25
<210> 108
<211> 27
<212> RNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 108
ucuucuuuaa uucauuaccu ccucgag 27
<210> 109
<211> 25
<212> RNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 109
cuugcuuaag guaugguaca agcaa 25
<210> 110
<211> 27
<212> RNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 110
uugcuuguac cauaccuuaa gcaagga 27
<210> 111
<211> 29
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 111
ctacagcttg ctatgctccc cttggggta 29
<210> 112
<211> 67
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 112
caccaacaga ggtgtagaag tacacgtgaa caagcttgaa attgtctctg acagaggtgc 60
ttttagt 67
<210> 113
<211> 67
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 113
caccaacaga ggtgtagaag tacacgtgaa caagcttgaa attgtctctg acagaggtga 60
aggaagg 67
<210> 114
<211> 67
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 114
caccaacaga ggtgtagaag tacacgtgaa caagcttgaa attgtctctg acagaggtgg 60
agggagg 67
<210> 115
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 115
actaaaagca cctctgtcag agacaa 26
<210> 116
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 116
ccttccttca cctctgtcag agacaa 26
<210> 117
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 117
cctccctcca cctctgtcag agacaa 26
<210> 118
<211> 81
<212> DNA
<213> 人工序列
<220>
<223> 人工序列的描述:合成的
寡核苷酸
<400> 118
atccagagtg acgcagcacc cgtggtagtg tatcagggag acactacgtg atgcagcttg 60
aaatggacac ggtggcttag t 81
- 涉及基于适体的可逆细胞选择的组合物和方法
- 肝干细胞的选择培养基、选择性分离并扩增肝干细胞的方法及用于治疗糖尿病的药物组合物