基于语义关系约束的词向量修正方法及计算系统
文献发布时间:2023-06-19 11:26:00
技术领域
本发明涉及一种采用语义词典中语义关系约束集对神经网络词嵌入向量进行修正的方法和计算词汇相似性的系统,尤其是利用语义层次结构中具有非对称关系的直接上位/下位词来约束词嵌入向量之间的语义距离,属于自然语言处理语义计算领域。
背景技术
分布式语义表示(Distributional Representations)是自然语言处理的重要研究内容之一。分布式表示是基于Harris的分布式假设,即如果两个词的上下文相似,那么这两个词也是相似的。上下文的类型可以为相邻词,所在句子或所在的文档等。这样我们就可以通过词与其上下文的共现矩阵来进行词的表示,即把共现矩阵的每一行看作对应词的向量表示。神经网络词嵌入的主要用途有三种:(1)在嵌入空间中找到最近邻;(2)作为有监督的机器学习模型的输入;(3)挖掘变量间的关系。利用神经网络嵌入,我们能将Wikipedia中的37000多本书转换为至多包含50个数值的向量。神经网络嵌入还克服了独热编码的局限性。
通过学习上下文中单词共现关系得到的神经网络词嵌入模型在相同上下文中出现的词通常具有相同的含义。神经网络词嵌入模型的表达能力还需要进一步提高。
词语向量表达(word vector representation)是机器翻译、文本分类、情感分析等自然语言处理(natural language processing NLP)下游应用中的重要基础。作为词语的向量化形式,词语向量表达通过计算后能够捕捉语言的特性,因此其被用于解决各种NLP的任务。近年来,以分布假说---词的语义由其上下文决定作为理论基础,由神经网络模型训练语言模型时生成的词分布表示,又叫词嵌入(word embedding)或词向量,在许多NLP任务上,取得超越传统的词袋(CBOW)特征表达方法的效果。这一提升归功于神经网络语言模型可以使用组合方式,以线性复杂度对复杂的n元上下文进行建模,解决了传统CBOW特征表达方法高维稀疏的问题。然而这种统一式的神经网络词嵌入模型不能有效区分词汇语义的相似度和相关度,在需要利用语义相似性区分单词含义或理解上,上下文不等同于真正的语义,词分布表示也存在局限性。
中国专利文献CN106610940A公开的一种新的本体概念词汇语义相似度求解方法,包括:初始化统计方法模块;将待比较词输入初始化统计方法模块中;将待比较词映射到本体概念模块中;分别选取待比较词对应深度最大的本体概念;计算待比较词对应深度最大的两本体概念间的相似度;待比较词之间的词形相似度;经过上述步骤,计算两待比较词最近共同祖先的深度对两待比较词相似度的影响,构造影响因子函数;综合上述步骤,计算两待比较词的相似度。
中国专利文献CN106610948A公开的一种改进的词汇语义相似度求解算法,本发明涉及语义网络技术领域,具体涉及一种改进的词汇语义相似度求解算法包括如下步骤:初始化统计方法模块,这里可以是《词语字典》、《词林》、知网、《百度百科》等等语料库;将待比较词输入初始化统计方法模块中;在统计模块中找到待比较词相邻上下文中权重最大的上下文词;根据待比较词分别对应的权重最大上下文词之间的相似度,提取相似度最大关键字;分别计算相似度最大关键字与待比较词的相关度;再利用求得的相关度,得出待比较词的相似度sim值。
中国专利文献CN102567306A公开的一种不同语言间词汇相似度的获取方法及系统,包括:获得源语言中第一词汇的上下文词汇及所述上下文词汇与所述第一词汇的源语言依存关系,获得目标语言中第二词汇的上下文词汇及所述上下文词汇与所述第二词汇的目标语言依存关系;获得所述第一词汇的上下文词汇与所述第二词汇的上下文词汇之间的上下文相似度,获得所述源语言依存关系与所述目标语言依存关系的依存相似度;根据所述上下文相似度及所述依存相似度获得所述第一词汇与所述第二词汇的相似度。
上述词汇语义相似度求解方法利用了基于语料库统计的方式计算词汇相似度,考虑到待比较词在本体概念模型中对应深度、最大的本体概念间的距离、深度与密度等因素。但该类汇语义相似度求解方法仍未与外部知识源信息融合。
近年来,研究者们采用各种词汇分类体系提供的词汇语义约束(如词语间的同义关系或者反义关系)对海量语料训练得到的词向量进行修正,改善了词向量的语义表达能力。词向量的修正主要分为两种方法:一种方法是直接在训练词向量的过程中加入词汇语义约束,另一类方法则是对训练好的词向量根据词汇语义约束进行后处理。相比于前者,后者适用于任何模型训练得到的词向量的修正,并且效率较高,被称为轻量级后修正方法。
这种通过在神经网络词嵌入模型中直接注入语义关系的方法来提升单词的分布式语义表达能力,其语义约束关系主要来自外部知识库如WordNet、PPDB等。该后处理方法无需在大规模语料库上重新训练语言模型,仅通过监督式学习对词嵌入向量进行语义约束。相较于前期融入知识源的传统模型训练方法,通过注入同义词关系、反义词关系、蕴含关系等,后处理方法灵活性和普适性更高,不再需要大规模计算资源重新训练语言模型,极大地提高了训练效率和应用领域。
词向量修正方法使用的蕴含关系涉及到跨多层次的语义关系传递的问题,由于语义关系传递自身存在似然性,随着语义传递路径长度的增长,语义传递的有效性逐渐降低,概念相似性也更模糊。同时,随着概念间的语义域重叠度降低,不同领域的概念密切程度也会逐渐稀疏。例如,WordNet中除了对称性的同义词和反义词关系之外,还有非对称性的上/下位关系(IS-A)以及部分-整体关系(PART-OF)等。在IS-A和PART-OF的语义网络层次体系中,随着网络路径距离的增加,概念间的语义域重叠度也会相应降低。如果语义概念间的层次跨度增大,蕴含关系两端概念的语义域相容性也会变低,概念间的相似度也随之降低,若将其作为语义约束注入神经网络词嵌入模型则会影响分布式语义表达能力。
因此有必要提出直接上位/下位词修正神经网络词嵌入向量的方法,结合语义词典中提供的同义词、反义词以及本方法收集的直接上位/下位词汇语义约束集,更新现有的任意神经网络词嵌入向量。进而达到提高词汇语义相似性准确率的目的。
发明内容
本发明针对现有技术存在的不足,提出一种基于语义关系约束的词向量修正方法及计算系统,在神经网络词嵌入向量空间中注入外部知识源中的词汇语义关系,使词向量语义表征能力更强,词汇相似性计算的准确率更高,同时提供一种实现该方法的计算系统。
本发明的基于语义关系约束的词向量修正方法,包括以下步骤:
从WordNet、Roget语义词典中名词、动词、形容词和副词在语义词典中均各自被组织成一个具有对称关系的同义词的网络和反义词网络,从中抽取对称关系的同义词约束集S、反义词约束集A,每个同义词集合和反义词集都代表一个基本的语义概念。
从语义词典中提取非对称关系的直接上位/下位词约束集DH,由于语义关系传递自身存在似然性,随着语义传递路径长度的增长,语义传递的有效性逐渐降低,概念相似性也更模糊。在WordNet IS-A和PART-OF的语义网络层次(Hierarchy)体系中,随着语义网络路径距离的增加,概念间的语义域重叠度也会相应降低,不同领域的概念密切程度也会逐渐稀疏。因此,当两个词汇为相邻的直接上位/下位关系时,两者之间的相似性更高。
构建词嵌入向量更新模型和损失函数,使用直接上位词约束集建立新型语义约束条件并构建修正模型,提升了神经网络词嵌入向量的语义表达能力。假设取GloVe CommonCrawl-300D词嵌入向量进行修正,首先获取词嵌入向量词典V,注入的外部语言约束集包括同义词约束集S,反义词约束集A以及直接上位/下位词约束集DH。模型优化过程中分别对同义词约束集、反义词约束集、直接上位/下位词约束集进行小批量训练,依次表示为B
执行同义词拉近函数、反义词推远函数及直接上位/下位词拉近函数对词嵌入向量进行更新;同义词拉近采用铰链函数判断同义词集向量之间彼此拉近的界值,反义词推远函数与此同理;为保留初始向量空间中的高质量的语义信息,每个小批量处理中的词向量,当该信息与上述注入的语言约束一致时,使用L2正则化方法来进行处理;直接上位/下位关系作为非对称语言约束,在修正分布式词向量过程中的顺序是至关重要的。将直接上位/下位关系优化方式与前述函数相同,采用欧几里德范数作为非对称距离函数来重新缩放词向量,以反映上位/下位词汇之间的关系。采用以上定义的损失函数执行词嵌入向量。
根据更新后词嵌入向量对输入词汇初始化,所要计算的相似性词汇的形式可以是任意的,如在词汇语义相似性计算系统的窗口中键入目标词汇,或将目标词汇统一整理成表格形式输入系统中进行计算;输入后的词汇在更新后的词向量检索对应向量值并进行初始化。
所述根据相似性定理计算词汇相似性并输出结果,词汇语义相似性计算方法主要包含:
(1)余弦距离(Cosine Distance)
(2)欧式距离(Euclidean Distance)
(3)曼哈顿距离(Manhattan Distance)
(4)明可夫斯基距离(Minkowski Distance)
根据上述任意语义相似性度量方法均可计算输出词汇相似值。
基于语义关系约束的词向量修正方法及计算系统,其特征在于,包括:
输入单元:一对需计算相似度的目标词汇;
初始化单元:根据语义关系约束修正后的词向量对输入词汇初始化;
计算单元:选取合适的相似性度量方法计算词汇相似度;
输出单元:输出两个目标词汇最终相似性结果。
本发明提出了一种利用语义关系约束的词向量修正方法,基于修正后的神经网络词嵌入向量进行计算,精确定义了修正损失函数,使两个待计算的词汇的形似性判断更接近人类真实判断。本发明提出的利用语义关系约束的词向量修正方法,分析了原有利用蕴含关系修正词嵌入向量方式存在的弊端,从语义词典中抽取直接上位/下位词集进行优化。进一步将原本高度相似的词汇向量在对应向量空间中的距离拉近,克服了因语义传递路径过长而带来的噪声影响。使得词嵌入修正计算速度快,修正效率高,有效提高词汇语义相似性的判断的准确率。相较于现有技术,本发明方法在词汇语义相似性判断上更有效。
附图说明
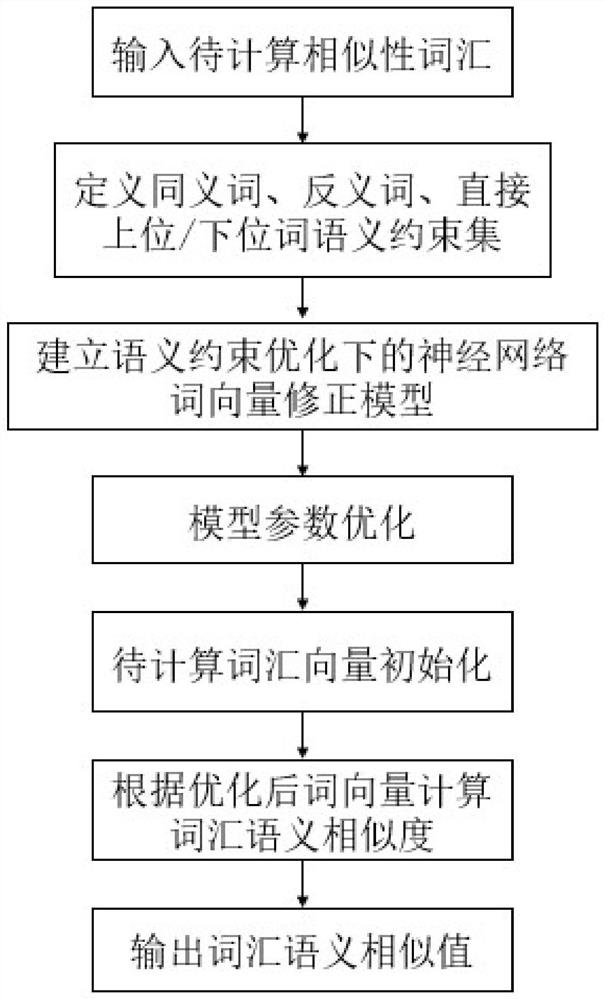
图1是本发明根据修正后词嵌入向量计算单词相似性的系统的单元流程图;
图2是本发明的基于语义关系约束的词向量修正方法的技术架构;
图3是本发明利用语义关系约束修正神经网络词嵌入向量示意图;
图4是本发明改进后的方法相应单词在向量空间中的对比图。
具体实施方式
首先说明语义关系约束集、神经网络词嵌入向量、语义传递的概念。
语义关系约束集:语义词典中的名词、动词、形容词和副词被组织成一个具有对称关系的同义词的网络,网络中的词汇两两构成同义词集(反义词集、蕴含关系词集同理)。
神经网络词嵌入:神经网络词向量表示技术通过神经网络技术对上下文,以及上下文与目标词之间的关系进行建模,将离散的数据表示为连续的低维向量。
语义传递:设存在概念c1,c2,…cn,cn+1,概念间存在语义关系r1(c1,c2),r2(c2,c3),…,rn(cn,cn+1),当n≤2时,称为单级语义传递;当n>2时,称为多级语义传递。
如图1,本发明的基于语义关系约束的词向量修正方法包括以下步骤:
从WordNet、Roget语义词典中抽取对称关系的同义词、反义词约束集;
提取非对称关系的直接上位/下位词约束集;
构建词嵌入向量更新模型和损失函数;
执行同义词拉近函数、反义词推远函数及直接上位/下位词拉近函数对词嵌入向量进行更新;
根据更新后词嵌入向量对输入词汇初始化;
根据相似性定理计算词汇相似性并输出结果。
如图2,本发明利用语义关系约束修正神经网络词嵌入向量的过程如下:令V为词嵌入向量的词典,注入的外部语言约束集包括同义词约束集S,反义词约束集A以及直接上位词约束集DH。优化过程中分别对同义词BS和反义词BA进行小批量操作,批处理大小分别为k1和k2。
令约束集中的词对为(xl,xr),其对应词向量为(Xl,Xr),则
为迫使同义词对之间的距离更近,反义词对之间的距离更远。首先定义同义词小批处理BS对应负样例
同义词拉近函数:
反义词推远函数:
向量空间信息保留函数:为保留初始向量空间中的高质量的语义信息,V(B)每个小批量处理中的词向量,当该信息与上述注入的语言约束一致时,使用L2正则化方法来进行处理。
直接上位/下位词拉近函数:直接上位/下位关系作为非对称语言约束,在修正分布式词向量过程中的顺序是至关重要的。本文将直接上位/下位关系表示为BDH,批次大小为k3,优化方式与前述函数相同。但在强调相似性的过程中也要反映上位/下位概念的层次结构。本文采用欧几里德范数作为非对称距离函数来重新缩放词向量,以反映上位/下位词汇之间的关系。
语义修正模型训练过程中完整的代价函数是以上四个函数之和:
C=S(B
NNWEs的修正过程中,我们将具有对称关系的同义词和具有非对称性的直接上位/下位关系的空间距离拉近,并将反义词距离推远,以提高分布式语义表示能力。
如图3,本发明根据修正后词嵌入向量计算单词相似性的系统的内部实施步骤如下:
算法:Similarity-Calculation给定修正后的神经网络词嵌入向量及其对应词典V,计算词汇相似性。
输入:待计算相似度的词汇(W1,W2)
输出:词汇(W1,W2)之间的相似值
方法:(1)for(W1,W2)in V
(2)locw1←find W1 in V
(3)locw2←find W2 in V
(4)end for
(5)初始化W1对应locw1词向量E1
(6)初始化W2对应locw2词向量E2
(7)计算词向量E1、E2之间的余弦距离
(8)返回余弦值,即词汇间的相似度
注:所要计算的相似性词汇的形式可以是任意的,如在词汇语义相似性计算系统的窗口中键入目标词汇,或将目标词汇统一整理成表格形式输入系统中进行计算;且相似度计算方式可以根据需要自由选择,词汇语义相似性计算方法主要包含:余弦距离、欧式距离、曼哈顿距离、明可夫斯基距离。根据上述任意语义相似性度量方法均可计算输出词汇相似值。
本发明提出了一种利用语义关系约束的词向量修正方法,基于修正后的神经网络词嵌入向量进行计算,针对现有利用蕴含关系修正词嵌入向量方式存在的不足和限制,将语义词典IS-A语义层次结构中具有对称关系的同义词、反义词注入词嵌入向量空间中,同时充分挖掘语义层次结构中具有非对称关系的直接上位/下位词约束集,将其作为外部知识源注入向量空间中,有效解决了因语义传递路径过长而导致的下位词对上位词语义继承性不强和语义域的重叠度低的问题,克服了因语义传递路径过长而带来的干扰。使得修正词嵌入向量语义表征能力更强,修正效率高,有效提高词汇语义相似性的判断的准确率。
- 基于语义关系约束的词向量修正方法及计算系统
- 一种语义约束的平面基元拓扑关系规则检测与恢复方法