一种基于多源图像信息的特定人员重识别方法
文献发布时间:2023-06-19 11:35:49
技术领域
本发明属于视频监控领域,具体涉及一种基于多源图像信息的特定人员重识别方法。
背景技术
行人重识别是计算机视觉领域近年来非常热的一个研究课题,可以被视为图像检索的一个子问题,其目标是给定一个监控行人图像检索其他设备下的该行人图像。传统的方法依赖手工特征,不能适应数据量很大的复杂环境。近年来随着深度学习的发展,大量基于深度学习的行人重识别方法被提出。
按照网络训练损失分类,行人重识别的方法可以分为表征学习和度量学习两类。表征学习和度量学习拥有各自的优缺点,目前学术界和工业界逐渐开始联合两种学习损失。联合的方式也比较直接,在传统度量学习方法的基础上,在特征层后面再添加一个全连接层进行ID分类学习。网络同时优化表征学习损失和度量学习损失,来共同优化特征层。
按照网络输出特征类型,行人重识别方法可以分为基于全局特征与局部特征的方法。融合全局特征和局部特征是目前一种提高网络性能非常常用的手段,目前融合全局特征和局部特征常用的思路是对于全局模块和局部模块分别提取特征,之后再将全局特征和局部特征拼接在一起作为最终的特征。Spindle net就提取了全局特征和n个不同尺度的局部特征,然后融合成最终的图像特征用于进行最后的相似度度量。AlignedReID给出了另外一种融合方法,即分别计算两幅图像全局特征距离和局部特征距离,然后加权求和作为最终两幅图像在特征空间的距离。
按照网络输入数据,行人重识别方法可以分为基于单帧图像与视频序列的方法。基于视频序列的方法可以解决单帧图像信息不足的缺点,并且可以融入运动信息加强鲁棒性,然而由于每次要处理多张图像,因此计算效率较低。当然基于视频序列的方法大部分都是单帧图像方法的扩展延伸,因此发展单帧图像的方法对于发展视频序列的方法也是有益的.
现实中,行人重识别的识别要求和识别性能受限于各种实际因素,首先,行人重识别获取到的是监控视频场景下的全景图像,对行人重识别的前提是利用检测网络检测出监控画面中包含的行人目标,再进行行人之间的相似度匹配。目前已有的检测网络和重识别网络的运行效率的累计总和不足以支持视频场景下的实时行人重识别操作;其次,行人重识别的识别性能受限于自身因素及环境因素。从自身因素考虑,高分辨率的摄像头或者复杂情境下拍摄到的图像都会增加延长检测时间,而低分辨率的摄像头、远距离拍摄的行人目标或是摄像头的抖动则会降低检测精度;另一方面,光照、遮挡带来的像素值渐变性特点也会对检测精度带来影响。从环境因素考虑,运动行人的相似着装、相似背景或者严重遮挡等情况,大大减弱了识别物体特征间的差异性,是重识别的识别能力进一步受限。
目前的一些行人重识别方法依旧存在无法针对视频监控进行实时处理的问题,若无法完成实时处理,行人重识别在应用至实际场景中就容易使得未处理的监控视频被积压,从而最终使得存储或是重识别结果出现问题(例如延迟、内存溢出等)。因此这些方法也就难以应用至实际场景中。若通过多个识别装置对监控视频进行处理则无疑会大幅度地提升硬件成本。另外,实际场景中的监控视频数量有限,往往无法覆盖特定区域,在这种情况对于特定人员的重识别定位,其难度大大增加。
发明内容
为解决上述问题,本发明提出了一种基于多源图像信息的特定人员重识别方法,用于实际场景中监控视频和无人机视频进行实时的行人重识别。
本发明所采用的技术方案是:
步骤1,在同一场景中设置多个固定摄像头和无人机,无人机上安装有一个云台摄像头,固定摄像头和云台摄像头共同组成摄像头,设置图像缓存队列并对多路摄像头的视频进行采集和存储同步;
步骤2,采用一阶段(one-stage)目标检测网络对采集到的多路摄像头的视频中的图像进行实时行人检测并将结果存入缓存区;
步骤3,构建行人重识别网络并读取缓存区中的行人数据进行处理获得重识别的欧氏距离,对重识别得到的欧氏距离进行排序,根据排序的结果进行人员位置框的绘制并显示。
本发明的多源图像信息来源于地面固定的监控摄像头与空中活动的无人机上的摄像头,根据地面监控摄像头与控制无人机视频的结合,定位特定人员的实时位置。
本发明中,特定人员可以是小偷、盗贼等特定职业的人员或者特定人的人员。
所述步骤1包括如下子步骤:
步骤1-1,通过rtsp协议分别采集多路固定摄像头的监控视频到pc端解码,同时,无人机通过图传将云台摄像头的图像视频传输到手机端进行编码再后通过制定的tcp协议发送到pc端并解码;pc端为PC计算机。
步骤1-2,在pc端为每一路摄像头的视频建立一个线程和一个图像缓存队列,每一路摄像头下的视频中的每一帧图像按时序存储在自身的图像缓存队列中,每一路摄像头下的线程对应处理该路摄像头下的图像缓存队列,每间隔处理读取所有图像缓存队列中帧数最小的图像缓存队列作为参考图像缓存队列,用于同步每一个摄像头的视频时间;
步骤1-3,使用双线性插值法统一每一路摄像头的图像的分辨率大小;
步骤1-4,由所有线程建立线程池,使得每一路摄像头的视频共同处理在显示界面中的固定位置显示。
所述步骤2包括如下子骤:
步骤2-1,选择YOLOv3神经网络作为目标检测网络的基础模型,并在YOLOv3神经网络的基础上加上空间金字塔池化结构(spp结构)形成最终的目标检测网络,使得目标检测网络能够检测到不同尺度的目标,提高检测精度;
所述的空间金字塔池化结构连接在YOLOv3神经网络的主干网络和头部网络之间。主干网络为Darknet网络,头部网络为分类网络。
步骤2-2,将目标检测网络加载在coco2017数据集上进行预训练网络的权重,并对步骤1中采集到的多路摄像头的视频中的图像进行调整尺寸、归一化等预处理后输入网络模型进行预测处理,获得行人类别的预测框,提取出行人类别的预测框作为行人图像并存入缓存区。
所述步骤3包括如下子步骤:
步骤3-1,选取轻量级主干网络osnet为行人重识别网络的主干,行人重识别网络的头部分为局部分支和全局分支的两个分支,局部分支和全局分支分别提取获得局部特征和全局特征,局部分支采用PCB的结构,将局部分支输出的特征图自上而下平均分成与人体拓扑结构相吻合的四个部分,例如头部、上躯干、下躯干和脚部,最后将全局分支与局部分支的输出拼接;
从而行人重识别网络的头部采用局部特征和全局特征的融合处理,能够试神经网络提取到更具鲁棒性的特征,提升重识别的精度。
步骤3-2,将拼接后的特征结果进行分类,使用交叉熵加上三元组损失函数作为分类损失函数,共同对行人重识别网络进行训练和监督;
步骤3-3,由训练后的行人重识别网络将步骤2缓存区中的行人图像进行处理得到行人图像的每一个行人的特征向量,将每一个特征向量与预先获得的特定人员的特征向量之间计算欧氏距离;
步骤3-4,对重识别得到的欧氏距离进行排序,根据排序的结果进行人员位置框的绘制并显示。
预先获得的特定人员的特征向量是由已知特定人员的照片或者肖像输入目标检测网络,再输入到行人重识别网络后获得。
本发明中,步骤2-2中目标检测与步骤3-3中的重识别是各自为一个线程,即两者同时进行,两者通过缓存区进行数据的存取。方法实现了多线程,提升了运行效率,使得实时性大大提升,实时处理的视频帧数能达到15fps,超过了现有的许多方法。
视频信息来源于地面监控摄像头与空中的无人机,根据地面监控摄像头与控制无人机视频的结合,定位特定人员的实时位置。
本发明的作用与效果是:
根据本发明的基于多源图像信息的特定人员重识别方法,由于通过评估神经网络算法的效率设置了图像缓存队列的方式,因此在实际场景下可以有效地对监控视频图像进行稳定获取,同时也可以适应不同的深度学习算法对方案进行改进和完善。
进一步,由于相对于其他主流的重识别网络,本发明采用了轻量级别的主干网络和全局,局部特征相融合的头部网络,使得在保证精度的前提下,效率也有所保证,同时,多线程的使用使得方法能在8路视频同时处理的情况下达到15fps的重识别效率,大大超过了目前主流的行人重识别网络,从而为实时识别提供了保障。
通过本发明的特定人员重识别方法,采用行人目标检测、行人重识别相结合的方式实现了特定人员的实时重识别,因此对日常场景下获取到的图像场景、视频场景甚至无人机航拍视频场景下的行人重识别具有更大的实际价值。
附图说明
图1本发明实施例中特定人员重识别方法的流程图;
图2本发明实施例中行人重识别网络的示意图;
图3本发明实施例中特定人员重识别方法算法的流程图;
图4本发明实施例中特定人员重识别效果的示意图。
具体实施方式
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,以下结合实施例及附图对本发明的特定人员重识别方法作具体阐述。
本发明的实施例如下:
本实施例中,特定人员重识别方法通过八台监控摄像头和一架无人机摄像头相连接的计算机实现,该计算机能够实时获取八台监控摄像头拍摄到的监控视频和一架无人机拍摄到视频并运行实时行人重识别算法对这些视频进行实时处理。本实例中,计算机通过采集八台摄像头的rtsp地址获取实时的监控视频,通过tcp协议接收无人机端回传的航拍视频。
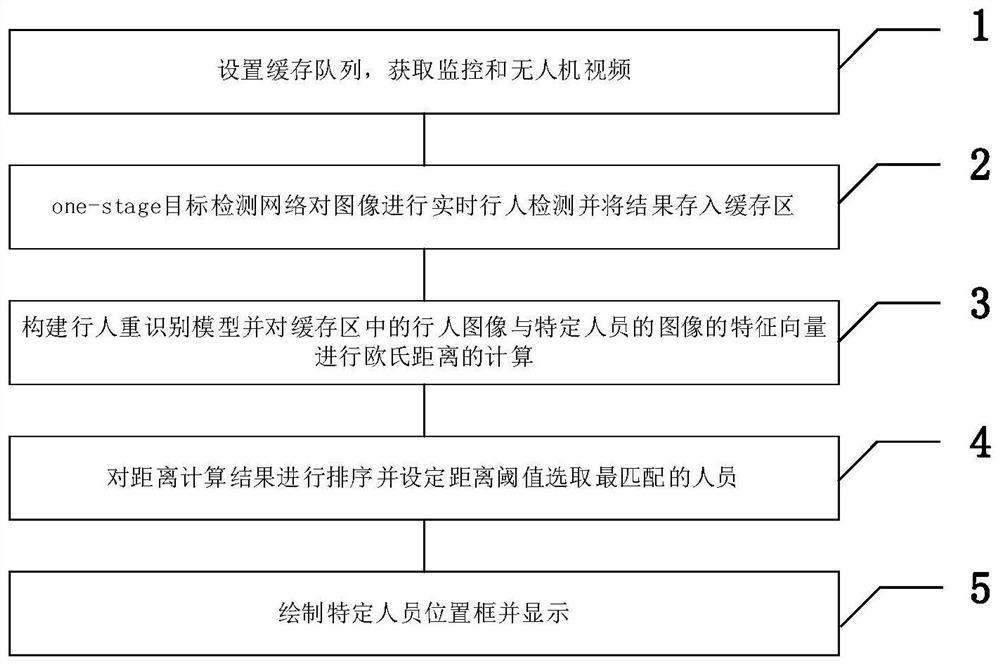
图1是本发明实施例中特定人员重识别方法的流程图。
如图1所示,本实施例的特定人员重识别方法的实现包括如下步骤:
步骤1,设置图像缓存队列并对八路摄像头图像进行同步同时采集无人机端的视频。本实施例中,该步骤1包括如下子步骤:
步骤1-1,通过rtsp协议分别采集八路监控视频图像到pc端解码,同时,无人机通过图传将图像传输到手机端进行编码后通过制定的tcp协议将手机端的图像发送到pc端并解码;
步骤1-2,在pc为每一路摄像头的视频建立一个线程和一个图像缓存队列,每一路摄像头下的视频中的每一帧图像按时序存储在自身的图像缓存队列中,每一路摄像头下的线程对应处理该路摄像头下的图像缓存队列,每一时间间隔处理读取所有图像缓存队列中帧数最小的图像缓存队列作为参考队列。具体地,设置Q1,Q2,...,Q8共8个队列分别用来实时缓存视频图像,主线程中获取这8个队列各自的长度,获取8个队列中的最短帧数Qmin,接着从8个队列中获取Qmin帧数的图像从而同步8个监控视频的时间。
步骤1-3,基于双线性插值法对获取的每一帧图像进行分辨率的调整,每个视频的输出画面大小保持一致。
步骤1-4,开启线程池,其容量与视频数量保持一致。新建一个空的图像,将图像平均分为几个部分,每个部分由一个线程中获取到的图像进行填充。
步骤2,采用一阶段(one-stage)目标检测网络对图像进行实时行人检测并将结果存入缓存区。
本实施例中的步骤2中,one-stage检测网络采用主流的YOLO-V3(在其他实施例中,也可以是其他的one-stage检测网络)对行人图像特征的提取。在此基础上,加入了spp(空间金字塔池化)结构,使得网络能够检测到更多大小差异较大的实例物体。同时,还获取画面中行人的具体图像区域,用于行人重识别阶段中各行人间的相似度匹配。one-stage检测网络的检测速度能在8路视频同时检测的情况下达到30fps/s,因此能够保证行人重识别的实时检测。
步骤3,构建行人重识别模型并读取缓存区中的行人数据进行推断。本实施例中,行人重识别网络模型的结构示意图如图2所示,步骤3具体包括如下子步骤:
步骤3-1:选取轻量级主干网络osnet为重识别网络的主干,网络头部采用局部特征和全局特征的融合,全局特征和局部特征分别由全局分支和局部分支提取获得,其中局部分支采用主流的PCB结构,PCB结构将特征图自上而下平均分成4个部分与人体的拓扑结构相吻合(如头部、上躯干、下躯干和脚部4个结构),最后将全局分支与局部分支输出的特征向量拼接。
步骤3-2,将拼接后的特征结果进行分类,使用交叉熵作为分类损失函数,使用三元组损失作为度量损失函数,共同对行人重识别网络进行监督训练。
步骤3-3,将步骤2-3缓存区中的行人图像输入到重识别模型做推断得到每一个行人的特征向量,将得到每一个特征向量与预先获得的特定人员的特征向量之间计算欧氏距离。
本实施例中,采用欧式距离度量的方式,逐一计算行人重识别归一化后的特征之间的距离并排序,基于triplet loss三元组损失函数最小化同一ID的person,最大化不同ID的行人差异性,对重识别网络继续进行参数学习。
本实施例的步骤3中,上述行人重识别网络以及接入的三元组损失函数采用pytorch深度学习框架进行网络搭建,在模型训练中应用非公开数据集作为训练集,该数据集共有23个摄像头,上千个行人。对算法精度的测试方法为计算在该数据集的测试集上的top1以及map。
步骤4,对距离计算结果进行排序并设定距离阈值选取最匹配的人员。
本实施例的步骤4中,获取到距离排序的重识别结果后,取距离最小的行人为与特定人员最匹配的行人。将最小距离与实验中设置的距离阈值作比较,若该距离小于阈值则可以认为该行人就是预先设定的特定人员。
步骤5,根据排序的结果进行人员位置框的绘制并显示。
本实施例的步骤5中,根据排序结果对应的行人以及行人的目标检测的结果框,将所有行人与特定人员的距离和结果框绘制到图像上,其中对于符合条件的小于阈值的行人,用椭圆标出,如图4所示。
另外,本实施例中,通过多路摄像头形成的闭环区域,以及充实别结果中行人自带的位置信息,可以将该特定人员的运动轨迹描绘在预先准备好地图上。也可以在摄像头中出现特定人员时进行及时的警报。
本实施例上述的特定人员重识别方法中的算法可以打包成一个计算机程序,从而实现即插即用,可以移植性强的效果。该算法的流程图如图3所示。
实施例作用与效果
由于通过评估神经网络算法的效率设置了图像缓存队列的方式,因此在实际场景下可以有效地对监控视频图像进行稳定获取,同时也可以适应不同的深度学习算法对方案进行改进和完善。进一步,由于相对于其他主流的重识别网络,本发明采用了轻量级别的主干网络和全局,局部特征相融合的头部网络,使得在保证精度的前提下,效率也有所保证,同时,多线程的使用使得该方法能在8路视频同时处理的情况下达到15fps的重识别效率,大大超过了目前主流的行人重识别网络,从而为实时识别提供了保障。通过本发明的特定人员重识别方法,采用行人目标检测、行人重识别相结合的方式实现了特定人员的实时重识别,因此对日常场景下获取到的图像场景、视频场景甚至无人机航拍视频场景下的行人重识别具有更大的实际价值。
上述实施例仅用于说明本发明的具体实施方式,而本发明不限于上述实施例的描述范围。
- 一种基于多源图像信息的特定人员重识别方法
- 一种基于多源图像信息融合的果实识别方法