一种基于分层联邦学习的轻量级激励模型的训练方法
文献发布时间:2023-06-19 11:39:06
技术领域
本发明属于联邦学习技术领域,尤其涉及一种基于分层联邦学习的轻量级激励模型的训练方法及激励方法。
背景技术
深度学习的最新发展彻底变革了包括电力领域在内的很多应用领域,如图像处理、自然语言处理、视频分析等。深度学习能在这些领域中取得巨大的成功源于大量训练数据和海量计算能力的可用性。但是,出于用户数据安全、运算成本和效率等方面的原因,提出了端-边-云分层联邦学习(HFL)的概念。
端-边-云分层联邦学习(HFL)能够有效地降低通信开销,同时仍能充分利用端侧的丰富数据。虽然HFL具有很多的优点,但同时也存在一些弊端。
在实现本发明的过程中发现,现有HFL的端侧用户数量有限,导致HFL的训练效果较差,目前没有合适的激励方法激励端侧用户加入到HFL的模型训练中。
发明内容
鉴于上述问题,本公开提供了一种基于分层联邦学习的轻量级激励模型的训练方法、训练系统及基于分层联邦学习的轻量级激励、激励系统。
本公开实施例的一个方面公开了一种基于分层联邦学习的轻量级激励模型的训练方法,包括:
根据端侧用户的初始单位数据成本信息从所述端侧用户中确定目标端侧用户,以生成目标端侧用户组,其中,所述目标端侧用户组设置有L组,L≥1;
根据每个所述目标端侧用户的所述初始单位数据成本信息,计算云侧服务器的最佳云侧策略;
根据所述最佳云侧策略,计算每个边缘聚合器的最佳边缘侧策略,其中,边缘聚合器设置有L个,每个边缘聚合器分别对应一个所述目标端侧用户组;
根据每个所述边缘聚合器的最佳边缘侧策略,计算当前所述边缘聚合器对应的所述目标端侧用户组中每个所述目标端侧用户的最佳端侧策略;
根据所述最佳云侧策略、所述最佳边缘侧策略和所述最佳端侧策略,训练所述激励模型,得到训练后的所述激励模型。
根据本公开的实施例,所述根据端侧用户的初始单位数据成本信息从所述端侧用户中确定目标端侧用户,以生成目标端侧用户组包括:
获取至少两个所述端侧用户的所述初始单位数据成本信息;
将每个所述初始单位数据成本信息按升序进行排列,构建成本信息队列;
根据所述成本信息队列确定所述目标端侧用户组。
根据本公开的实施例,所述根据所述成本信息队列确定所述目标端侧用户组包括:
依次遍历所述成本信息队列中的每个所述初始单位数据成本信息;
判断每个所述初始单位数据成本信息是否符合筛选条件:
其中,L
将与符合筛选条件的所述初始单位数据成本信息对应的目标端侧用户划分至所述目标端侧用户组中。
根据本公开的实施例,所述根据每个所述目标端侧用户的所述初始单位数据成本信息,计算云侧服务器的最佳云侧策略包括:
其中:m=∑
根据本公开的实施例,所述根据所述最佳云侧策略,计算每个边缘聚合器的最佳边缘侧策略包括:
其中:
根据本公开的实施例,所述根据每个所述边缘聚合器的最佳边缘侧策略,计算当前所述边缘聚合器对应的所述目标端侧用户组中每个所述目标端侧用户的最佳端侧策略包括:
其中,
本公开实施例的另一个方面公开了一种基于分层联邦学习的轻量级激励方法,其中,所述激励方法由上述训练方法得到的激励模型实现,所述激励方法包括:
获取与每个边缘聚合器相对应的目标端侧用户组中每个目标端侧用户的目标单位数据成本信息,其中,所述边缘聚合器设置有L个;
根据每个所述目标端侧用户的所述目标单位数据成本信息,计算云侧服务器的最佳云侧策略;
根据所述最佳云侧策略,计算每个边缘聚合器的最佳边缘侧策略;
根据每个所述边缘聚合器的最佳边缘侧策略,计算当前所述边缘聚合器对应的所述目标端侧用户组中每个所述目标端侧用户的最佳端侧策略;将所述最佳云侧策略、所述最佳边缘侧策略和所述最佳端侧策略作为最终结果进行输出。
根据本公开的实施例,所述根据每个所述目标端侧用户的所述目标单位数据成本信息,计算云侧服务器的最佳云侧策略包括:
其中:m=∑
根据本公开的实施例,所述根据所述最佳云侧策略,计算每个边缘聚合器的最佳边缘侧策略包括:
其中:
根据本公开的实施例,所述根据每个所述边缘聚合器的最佳边缘侧策略,计算当前所述边缘聚合器对应的所述目标端侧用户组中每个所述目标端侧用户的最佳端侧策略包括:
其中,
本公开实施例的另一个方面公开了一种基于分层联邦学习的轻量级激励模型的训练系统,包括:
确定模块,用于根据端侧用户的初始单位数据成本信息从所述端侧用户中确定目标端侧用户,以生成目标端侧用户组,其中,所述目标端侧用户组设置有L组,L≥1;
第一计算模块,用于根据每个所述目标端侧用户的所述初始单位数据成本信息,计算云侧服务器的最佳云侧策略;
第二计算模块,用于根据所述最佳云侧策略,计算每个边缘聚合器的最佳边缘侧策略,其中,边缘聚合器设置有L个,每个边缘聚合器分别对应一个所述目标端侧用户组;
第三计算模块,用于根据每个所述边缘聚合器的最佳边缘侧策略,计算当前所述边缘聚合器对应的所述目标端侧用户组中每个所述目标端侧用户的最佳端侧策略;
训练模块,用于根据所述最佳云侧策略、所述最佳边缘侧策略和所述最佳端侧策略,训练所述激励模型,得到训练后的所述激励模型。
根据本公开的实施例,所述确定模块包括:
获取单元,用于获取至少两个所述端侧用户的所述初始单位数据成本信息;
排列单元,用于将每个所述初始单位数据成本信息按升序进行排列,构建成本信息队列;
确定单元,用于根据所述成本信息队列确定所述目标端侧用户组。
根据本公开的实施例,所述确定单元包括:
遍历子单元,用于依次遍历所述成本信息队列中的每个所述初始单位数据成本信息;
判断子单元,用于判断每个所述初始单位数据成本信息是否符合筛选条件:
其中,L
划分子单元,用于将与符合筛选条件的所述初始单位数据成本信息对应的目标端侧用户划分至所述目标端侧用户组中。
本公开实施例的另一个方面公开了一种基于分层联邦学习的轻量级激励系统,其中,所述激励方法由上述训练系统得到的激励模型实现,所述激励系统包括:
获取模块,用于获取与每个边缘聚合器相对应的目标端侧用户组中每个目标端侧用户的目标单位数据成本信息,其中,所述边缘聚合器设置有L个;
第四计算模块,用于根据每个所述目标端侧用户的所述目标单位数据成本信息,计算云侧服务器的最佳云侧策略;
第五计算模块,用于根据所述最佳云侧策略,计算每个边缘聚合器的最佳边缘侧策略;
第六计算模块,用于根据每个所述边缘聚合器的最佳边缘侧策略,计算当前所述边缘聚合器对应的所述目标端侧用户组中每个所述目标端侧用户的最佳端侧策略;输出模块,用于将所述最佳云侧策略、所述最佳边缘侧策略和所述最佳端侧策略作为最终结果进行输出。
根据本公开实施例,根据目标端侧用户的成本信息计算并训练云侧服务器、边缘聚合器和用户端侧的策略,能够使云侧服务器根据每个目标端侧用户的单位数据贡献量制定出合理的资源报价,达到既能激励用户参与训练,又可以节约训练成本的技术效果,同时,由于本公开的训练方法能够使更多的端侧用户参与到模型训练中,因此,提高了模型的训练效果。
附图说明
图1示意性示出了本公开实施例提供的基于云的联邦学习流程图。
图2示意性示出了本公开实施例提供的基于边缘的联邦学习流程图。
图3示意性示出了本公开实施例提供的基于端-边-云分层联邦学习的联邦学习流程图。
图4示意性示出了本公开实施例的基于分层联邦学习的轻量级激励模型的训练方法流程图。
图5示意性示出了本公开实施例的基于分层联邦学习的轻量级激励方法流程图。
图6示意性示出了根据本公开实施例轻量级激励方法、传统随机、贪婪、固定算法的云侧服务器的效用值对比图。
图7示意性示出了根据本公开实施例轻量级激励方法、传统随机、贪婪、固定算法的云侧服务器的策略对比图。
图8示意性示出了根据本公开实施例轻量级激励方法、传统随机、贪婪、固定算法的端侧用户的数据贡献量对比图。
图9示意性示出了本公开实施例基于分层联邦学习的轻量级激励模型的训练系统的模块示意图。
具体实施方式
以下,将参照附图来描述本公开的实施例。但是应该理解,这些描述只是示例性的,而并非要限制本公开的范围。在下面的详细描述中,为便于解释,阐述了许多具体的细节以提供对本公开实施例的全面理解。然而,明显地,一个或多个实施例在没有这些具体细节的情况下也可以被实施。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本公开的概念。
在此使用的术语仅仅是为了描述具体实施例,而并非意在限制本公开。在此使用的术语“包括”、“包含”等表明了特征、步骤、操作和/或部件的存在,但是并不排除存在或添加一个或多个其他特征、步骤、操作或部件。
在此使用的所有术语(包括技术和科学术语)具有本领域技术人员通常所理解的含义,除非另外定义。应注意,这里使用的术语应解释为具有与本说明书的上下文相一致的含义,而不应以理想化或过于刻板的方式来解释。
在使用类似于“A、B和C等中至少一个”这样的表述的情况下,一般来说应该按照本领域技术人员通常理解该表述的含义来予以解释(例如,“具有A、B和C中至少一个的系统”应包括但不限于单独具有A、单独具有B、单独具有C、具有A和B、具有A和C、具有B和C、和/或具有A、B、C的系统等)。在使用类似于“A、B或C等中至少一个”这样的表述的情况下,一般来说应该按照本领域技术人员通常理解该表述的含义来予以解释(例如,“具有A、B或C中至少一个的系统”应包括但不限于单独具有A、单独具有B、单独具有C、具有A和B、具有A和C、具有B和C、和/或具有A、B、C的系统等)。
目前,深度学习的发展彻底变革了包括电力领域在内的很多应用领域,如图像处理、自然语言处理、视频分析等。深度学习能在这些领域中取得巨大的成功源于大量训练数据和海量计算能力的可用性。但是,训练数据是由个人或不同组织拥有的分布式设备生成的。如果这些数据被泄露或用于最初目的以外的其他目的,个人隐私将受到损害。例如一些电力数据设计个人用户隐私信息且安全性要求较高,一旦用电数据的隐私性、完整性、可用性被破坏,不仅会损害用电区域内用户自身的利益,更会对智能电网的整体性能产生不可估量的影响。许多数据所有者不愿意为训练模型共享他们的私有数据。数据隐私正逐渐成为深度学习最严重的问题之一。此外,由于数据大小、延迟和带宽的限制,很难将这些数据聚合到单个计算站点进行集中训练。联邦学习(FL)的概念被提出来缓解这些问题,它允许多个用户在一个中央服务器的协调下,在不共享数据的情况下建立一个联邦模型。例如,在电力物联网架构下,通过感知层具备的较强的通信和计算能力,来满足联邦学习算力和数据分布式需求。因此,移动设备上的大量分布式和隐私敏感数据可以在不泄露隐私的情况下得到很好的利用。
很多场景中的数据涉及用户隐私且安全性要求高,泛在FL的基本思想是让这些计算节点分别使用自己的数据训练局部模型,然后将局部模型而不是数据上传到逻辑上集中的参数服务器,该服务器合成一个全局模型。虽然大多数初步的FL研究假设云作为参数服务器,但是随着最近边缘计算平台的出现,研究人员已经开始研究基于边缘的FL系统,其中边缘服务器将充当参数服务器。
图1示意性示出了本公开实施例提供的基于云的联邦学习流程图。
图2示意性示出了本公开实施例提供的基于边缘的联邦学习流程图。
如图1和图2所示,在基于云的FL中,参与的客户端总数可达数百万,提供深度学习所需的海量数据集。同时,与云服务器的通信缓慢且不可预测,例如由于网络拥塞,这使得训练过程低效。相反,在基于边缘的FL中,由于参数服务器被放置在最接近的边缘,计算的等待时间与到边缘参数服务器的通信的等待时间相当。因此,有可能在计算和通信之间寻求更好的平衡。然而,每个服务器可以访问的客户端数量有限,导致不可避免的训练性能损失。从上面的比较中可知,利用云服务器来访问大量训练样本的必要性,并且每个边缘服务器都可以与其本地端侧用户一起快速更新模型。
图3示意性示出了本公开实施例提供的基于端-边-云分层联邦学习的联邦学习流程图。
如图3所示,端-边-云分层联邦学习(HFL)很好地利用了云和边缘服务器的优点。与基于云的FL相比,端-边-云HFL将显著减少与云的高成本通信,并辅以高效的端-边缘更新,从而显著减少运行时间和本地迭代次数。另一方面,随着云服务器可以访问更多的数据,HFL在模型训练方面将优于基于边缘的FL。最重要的是,HFL能够发挥改善隐私的能力。简而言之,HFL可以有效地降低通信开销,同时仍能充分利用终端的丰富数据。
在实现本公开构思的过程中,发明人发现尽管端-边-云分层联邦学习(HFL)在应用时具有很明显的优势,但其仍然面临着一个公开的挑战,目前没有合适的激励方法激励端侧用户加入到HFL的模型训练中,如果没有设计良好的经济补偿,自利的端侧移动设备不愿意参与模型训练,最终导致HFL的模型训练的效果较差。
为了解决上述问题,本公开实施例提供了一种基于分层联邦学习的轻量级激励模型的训练方法、训练系统及基于分层联邦学习的轻量级激励、激励系统。
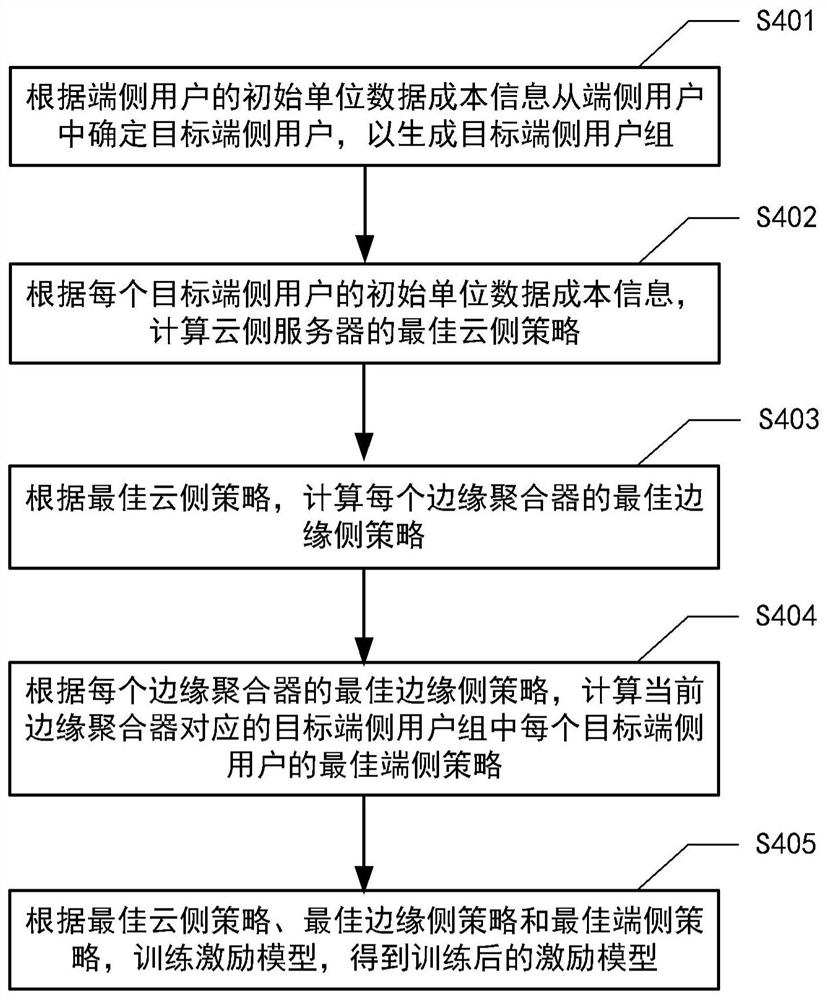
图4示意性示出了本公开实施例的基于分层联邦学习的轻量级激励模型的训练方法流程图。
如图4所示,本公开实施例提供的基于分层联邦学习的轻量级激励模型的训练方法包括操作S401~S405。
在操作S401,根据端侧用户的初始单位数据成本信息从端侧用户中确定目标端侧用户,以生成目标端侧用户组,其中,目标端侧用户组设置有L组,L≥1。
根据本公开实施例,端侧用户初始单位数据成本信息例如可以包括计算成本和通信成本两部分,这两部分的成本信息与端侧用户用于训练的数据量成正比。
例如,端侧用户在参与训练时的单位计算成本和单位通信成本分别
根据本公开实施例,以端侧用户在参与训练时的单位计算成本和单位通信成本分别为
其中,τ为端侧用户的本地更新次数,σ为边缘聚合器的聚合次数。
在操作S402,根据每个目标端侧用户的初始单位数据成本信息,计算云侧服务器的最佳云侧策略。
根据本公开实施例,最佳云侧策略例如可以是云侧服务器为激励端侧用户而给端侧用户支付的单位数据量的报酬。
在操作S403,根据最佳云侧策略,计算每个边缘聚合器的最佳边缘侧策略,其中,边缘聚合器设置有L个,每个边缘聚合器分别对应一个目标端侧用户组。
根据本公开实施例,边缘聚合器例如可以设置有多个,每个边缘聚合器对应一个目标端侧用户组,即每个边缘聚合器都与至少一个目标端侧用户相对应。最佳边缘侧策略例如可以是边缘聚合器分配给与其对应的端侧用户的报酬。
在操作S404,根据每个边缘聚合器的最佳边缘侧策略,计算当前边缘聚合器对应的目标端侧用户组中每个目标端侧用户的最佳端侧策略。
根据本公开实施例,最佳端侧策略例如可以是每个目标端侧用户在进行深度学习的模型训练中提供的最佳数据贡献量。
在操作S405,根据最佳云侧策略、最佳边缘侧策略和最佳端侧策略,训练激励模型,得到训练后的激励模型。
根据本公开实施例,目标端侧用户能够根据最佳端侧策略改变自己的数据贡献量,从而调整最佳云侧策略、最佳边缘侧策略和最佳端侧策略,对激励模型进行训练。
根据本公开实施例,在深度学习的模型训练中,根据目标端侧用户的成本信息计算并训练云侧服务器、边缘聚合器和用户端侧的策略,能够使云侧服务器根据每个目标端侧用户的单位数据贡献量制定出合理的资源报价,达到既能激励用户参与训练,又可以节约训练成本的技术效果,同时,由于本公开的训练方法能够使更多的端侧用户参与到模型训练中,因此,提高了模型的训练效果。
根据本公开的实施例,根据端侧用户的初始单位数据成本信息从端侧用户中确定目标端侧用户,以生成目标端侧用户组包括:
获取至少两个端侧用户的初始单位数据成本信息;将每个初始单位数据成本信息按升序进行排列,构建成本信息队列;根据成本信息队列确定目标端侧用户组。
根据本公开实施例,在存在两个或两个以上数量的端侧用户时,需要对端侧用户的初始单位数据成本信息按升序进行排列,需要说明的是,以上是实力仅为示例性实施例,根据具体实现需要,端侧用户的数量可以是任意个。
根据本公开实施例,目标端侧用户可以是其初始单位数据成本信息符合预设筛选条件的端侧用户。
例如,通过将端侧用户的初始单位数据成本信息进行排序,根据端侧用户的初始单位数据成本信息筛选出符合预没筛选条件的端侧用户,将筛选出来的端侧用户标记为目标端侧用户,然后将目标端侧用户划分至相应的目标端侧用户组中。
根据本公开的实施例,根据成本信息队列确定目标端侧用户组包括:
依次遍历成本信息队列中的每个初始单位数据成本信息;
判断每个初始单位数据成本信息是否符合筛选条件:
其中,L
将与符合筛选条件的初始单位数据成本信息对应的目标端侧用户划分至目标端侧用户组中。
根据本公开实施例,通过对端侧用户进行筛选,能够排除破坏纳什均衡的端侧用户,防止其参与模型训练,影响训练结果。
需要说明的是,上述实施例仅为示意性实施例,根据具体实现需要,也可以是其它能够达到相同技术效果的筛选方式。
根据本公开的实施例,根据每个目标端侧用户的初始单位数据成本信息,计算云侧服务器的最佳云侧策略包括:
其中:m=∑
根据本公开实施例,最佳云侧策略例如可以是云侧服务器为激励端侧用户而给端侧用户支付的单位数据量的报酬。由于端侧用户存在纳什均衡,云侧服务器只需要最大化自身效用即可定义最佳云侧策略。
根据本公开的实施例,根据最佳云侧策略,计算每个边缘聚合器的最佳边缘侧策略包括:
其中:
根据本公开的实施例,根据每个边缘聚合器的最佳边缘侧策略,计算当前边缘聚合器对应的目标端侧用户组中每个目标端侧用户的最佳端侧策略包括:
其中,
根据本公开实施例,通过上述训练方法得到基于分层联邦学习的轻量级激励模型。
图5示意性示出了本公开实施例的基于分层联邦学习的轻量级激励方法流程图。
如图5所示,该方法包括操作S501~S505。
在操作S501,获取与每个边缘聚合器相对应的目标端侧用户组中每个目标端侧用户的目标单位数据成本信息,其中,边缘聚合器设置有L个。
根据本公开实施例,目标端侧用户目标单位数据成本信息例如可以包括计算成本和通信成本两部分,这两部分的成本信息与目标端侧用户用于训练的数据量成正比。
例如,端侧用户在参与训练时的单位计算成本和单位通信成本分别
根据本公开实施例,以端侧用户在参与训练时的单位计算成本和单位通信成本分别为
其中,τ为端侧用户的本地更新次数,σ为边缘聚合器的聚合次数。
在操作S502,根据每个目标端侧用户的目标单位数据成本信息,计算云侧服务器的最佳云侧策略。
根据本公开实施例,最佳云侧策略例如可以是云侧服务器为激励端侧用户而给端侧用户支付的单位数据量的报酬。
在操作S503,根据最佳云侧策略,计算每个边缘聚合器的最佳边缘侧策略。
在操作S504,根据每个边缘聚合器的最佳边缘侧策略,计算当前边缘聚合器对应的目标端侧用户组中每个目标端侧用户的最佳端侧策略。
根据本公开实施例,最佳端侧策略例如可以是每个目标端侧用户在进行深度学习的模型训练中提供的最佳数据贡献量。
在操作S505,将最佳云侧策略、最佳边缘侧策略和最佳端侧策略作为最终结果进行输出。
根据本公开实施例,云侧服务器将根据目标端侧用户当前的最佳策略制定出合理的资源报价,既能激励端侧用户参与训练,又可以使训练的模型达到良好的训练效果,同时还可以节省资源成本;与此同时,边缘聚合器和目标端侧用户也会根据云侧最佳策略做出最大化自身利益的决策。
例如,智能巡检是电力系统安全稳定运行的基础,需要通过图像处理方法识别设备外观、检测设备缺陷,进而实现设备状态分析与缺陷诊断。利用深度学习实现智能巡检的赋能升级已经成为了此领域的热门研究方向,其中必须解决的问题之一就是,场景适用的深度学习网络模型的生成。在电力物联网架构下,采用HFL来训练深度学习模型,在充分利用端侧的丰富数据的同时,保护电力系统中数据的隐私,并有效地降低通信开销。在本实施例中,通过基于分层联邦学习的轻量级激励方法实现电力物联网架构下端-边-云模型训练的合理资源定价。
下面阐述进行合理资源定价的必要性:例如云侧服务器想采用HFL进行模型训练(例如训练卷积神经网络模型),采用端-边-云HFL进行模型训练可以显著减少与云的高成本通信,并辅以高效的端-边缘更新,显著减少运行时间和本地迭代次数。同时也利用了FL(联邦学习)的优势,将数据保留的端侧用户,保护了端侧用户的数据隐私。
端侧用户上报训练模型的目标单位数据成本信息,边缘聚合器侧通过端侧用户上报的目标单位数据成本信息决定是否令此端侧用户参与训练,若某端侧用户的目标单位数据成本信息过高则告知用户不参与此轮模型训练,然后将参与训练的端侧用户上报给云侧服务器,云侧服务器将根据端侧用户目前的策略制定出合理的资源报价,即既能激励用户数据参与训练,又可以使得训练的模型达到良好的训练效果以及节约成本。边缘和端侧用户也会根据云侧的报价做出最大化自身利益的策略。
根据本公开实施例,端侧用户的效用值包括:
其中,
边缘聚合器的效用值包括:
其中,
云侧服务器的效用值包括:
U
其中,U
图6示意性示出了根据本公开实施例轻量级激励方法、传统随机、贪婪、固定算法的云侧服务器的效用值对比图。
如图6所示,图中横坐标为端侧用户数量,纵坐标为云侧服务器的效用值,从图中可以看出,在相同端侧用户数量的情况下,采用轻量级激励方法的云侧服务器的效用值均高于采用传统随机、贪婪、固定算法的云侧服务器的效用值。
图7示意性示出了根据本公开实施例轻量级激励方法、传统随机、贪婪、固定算法的云侧服务器的策略对比图。
如图7所示,图中横坐标为端侧用户数量,纵坐标为云侧服务器的云侧策略(云侧服务器的成本),从图中可以看出,在相同端侧用户数量的情况下,采用轻量级激励方法的云侧服务器的云侧策略均低于采用传统随机、贪婪、固定算法的云侧服务器的云侧策略。
图8示意性示出了根据本公开实施例轻量级激励方法、传统随机、贪婪、固定算法的端侧用户的数据贡献量对比图。
如图8所示,图中横坐标为端侧用户数量,纵坐标为端侧用户的数据贡献量,从图中可以看出,在相同端侧用户数量的情况下,采用轻量级激励方法的云侧服务器的云侧策略均高于采用传统随机、贪婪、固定算法的端侧用户的数据贡献量。
根据本公开的实施例,根据每个目标端侧用户的初始单位数据成本信息,计算云侧服务器的最佳云侧策略包括:
其中:m=∑
根据本公开实施例,最佳云侧策略例如可以是云侧服务器为激励端侧用户而给端侧用户支付的单位数据量的报酬。由于端侧用户存在纳什均衡,云侧服务器只需要最大化自身效用即可定义最佳云侧策略。
根据本公开的实施例,根据最佳云侧策略,计算每个边缘聚合器的最佳边缘侧策略包括:
其中:
根据本公开的实施例,根据每个边缘聚合器的最佳边缘侧策略,计算当前边缘聚合器对应的目标端侧用户组中每个目标端侧用户的最佳端侧策略包括:
其中,
图9示意性示出了本公开实施例基于分层联邦学习的轻量级激励模型的训练系统的模块示意图。
如图9所示,本公开实施例的训练系统900包括:确定模块910、第一计算模块920、第二计算模块930、第三计算模块940、训练模块950。
确定模块910,用于根据端侧用户的初始单位数据成本信息从端侧用户中确定目标端侧用户,以生成目标端侧用户组,其中,目标端侧用户组设置有L组,L≥1。
第一计算模块920,用于根据每个目标端侧用户的初始单位数据成本信息,计算云侧服务器的最佳云侧策略。
第二计算模块930,用于根据最佳云侧策略,计算每个边缘聚合器的最佳边缘侧策略,其中,边缘聚合器设置有L个,每个边缘聚合器分别对应一个目标端侧用户组。
第三计算模块940,用于根据每个边缘聚合器的最佳边缘侧策略,计算当前边缘聚合器对应的目标端侧用户组中每个目标端侧用户的最佳端侧策略。
训练模块950,用于根据最佳云侧策略、最佳边缘侧策略和最佳端侧策略,训练激励模型,得到训练后的激励模型。根据本公开实施例,根据目标端侧用户的成本信息计算并训练云侧服务器、边缘聚合器和用户端侧的策略,能够使云侧服务器根据每个目标端侧用户的单位数据贡献量制定出合理的资源报价,达到既能激励用户参与训练,又可以节约训练成本的技术效果,同时,由于本公开的训练方法能够使更多的端侧用户参与到模型训练中,因此,提高了模型的训练效果。
根据本公开实施例,确定模块910包括第一获取单元、构建单元和确定单元。
获取单元,用于获取至少两个端侧用户的初始单位数据成本信息。
构建单元,用于将每个初始单位数据成本信息按升序进行排列,构建成本信息队列。
确定单元,用于根据成本信息队列确定目标端侧用户组。
根据本公开实施例,确定单元包括:遍历子单元、判断子单元和划分子单元。
遍历子单元,用于依次遍历成本信息队列中的每个初始单位数据成本信息。
判断子单元,用于判断每个初始单位数据成本信息是否符合筛选条件。
其中,L
划分子单元,用于将与符合筛选条件的初始单位数据成本信息对应的目标端侧用户划分至目标端侧用户组中。
根据本公开实施例,还提供了一种基于分层联邦学习的轻量级激励系统,其中,激励方法由上述训练系统得到的激励模型实现,激励系统包括获取模块、第四计算模块、第五计算模块、第六计算模块和输出模块。
获取模块,用于获取与每个边缘聚合器相对应的目标端侧用户组中每个目标端侧用户的目标单位数据成本信息,其中,边缘聚合器设置有L个。
第四计算模块,用于根据每个目标端侧用户的目标单位数据成本信息,计算云侧服务器的最佳云侧策略。
第五计算模块,用于根据最佳云侧策略,计算每个边缘聚合器的最佳边缘侧策略。
第六计算模块,用于根据每个边缘聚合器的最佳边缘侧策略,计算当前边缘聚合器对应的目标端侧用户组中每个目标端侧用户的最佳端侧策略。输出模块,用于将最佳云侧策略、最佳边缘侧策略和最佳端侧策略作为最终结果进行输出。
需要说明的是,本公开的实施例中训练系统和激励系统部分与本公开的实施例中训练方法和激励方法部分是相对应的,训练系统和激励系统部分的描述具体参考训练方法和激励方法部分,在此不再赘述。
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种基于分层联邦学习的轻量级激励模型的训练方法
- 一种联邦学习模型训练方法、装置及联邦学习系统