基于答案类别和句法指导的案情阅读理解方法
文献发布时间:2023-06-19 11:44:10
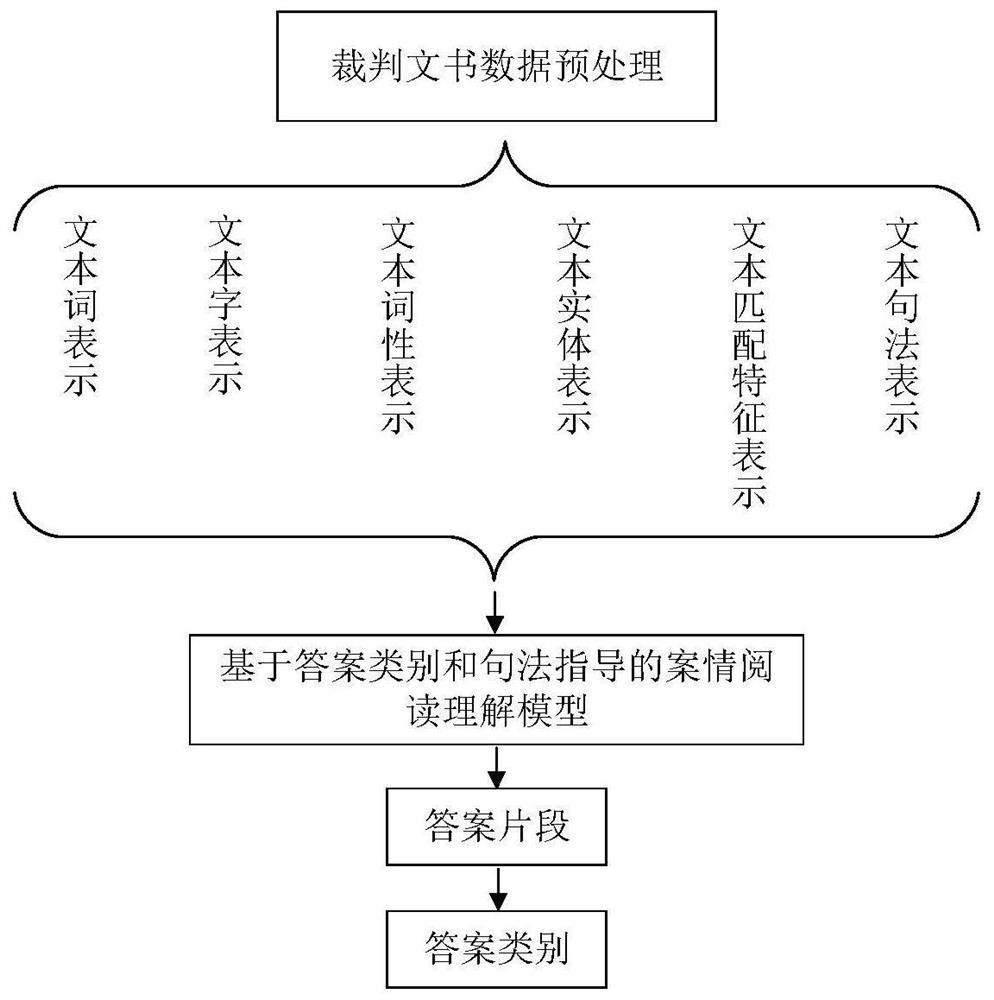
技术领域
本发明涉及基于答案类别和句法指导的案情阅读理解方法,属于自然语言处理技术领域。
背景技术
机器阅读理解在人工智能领域是一个挑战性的任务,而案情阅读理解是机器阅读理解在司法领域的重要应用,有望辅助相关工作人员以问答的方式获取案件信息。
近年来,随着深度学习技术的发展,出现了许多基于神经网络的阅读理解方法。其中基于深度学习的抽取式阅读理解,普遍的模型是将问题和篇章编码共同输入到模型当中,最后输出答案片段。这些阅读理解模型,都是通过问题和篇章的语义编码,互注意力及自注意力机制获取篇章中与问题相关的信息,最后通过Pointer网络提取问题的答案。
机器阅读理解在司法智能方面有着很多的应用,基于裁判文书的案情阅读理解就是重要的应用之一。案情阅读理解是通过计算机阅读用户指定的裁判文书案情,并回答用户提出的问题。当前机器阅读理解的主流方法是采用深度学习模型对文本词语进行编码,并由此获得文本的向量表示。模型建模的核心问题是如何获得文本的语义表示,以及问题与上下文的匹配。但是在实际应用当中,用户提出的问题的答案不一定都有,以及句法信息有助于模型对关键信息的识别。
对于法研杯2019案情阅读理解,答案类型包括:无答案类、是类、否类、片段抽取类四类。其中无答案类即问题的答案在篇章中不存在,而是类和否类在表达上直接是是否或者有明显的倾向性。同时我们注意到这些问句,例如:“原告的月收入是?”、“原告的车损估价是多少?”、“原告的车辆的车牌号是?”等。这些问题在前期的注意力机制下基本都会注意到相关的信息,但在最后确定答案时,受限于问题的Sum_attention对每个词都要不同程度的关注而不能提取到问句的关键信息,就不能从前期关注到的相关信息中提取到正确的答案,造成答案不准。
发明内容
为了解决上述问题,本发明提供了基于答案类别和句法指导的案情阅读理解方法,本发明提高案情文本的编码能力,提升案情阅读理解的EM值和F1值。
本发明针对案情阅读理解的答案特征:无答案类、是类、否类、片段类,在案情阅读理解模型的注意力融合层之后对篇章表示进行答案有无二分类,在输出层利用起始位置的计算进行答案三分类。由于答案类别在训练数据上存在不平衡问题,通过对现有数据的改动增加无答案类和是否类答案的训练数据。针对问句在Sum_attention时的受限问题运用句法指导的mask注意力机制来提取问句当中的关键信息,提出了基于答案类别和句法指导的案情阅读理解模型,进行案情阅读理解答案抽取。
本发明的技术方案是:基于答案类别和句法指导的案情阅读理解方法,所述方法包括:
Step1、首先对训练数据中无答案类、是类否类进行数据扩充;
Step2、然后经过数据预处理将数据输入到词嵌入层,在词嵌入层对篇章和问题进行向量化;
Step3、紧接着在表示编码层将文本的词嵌入、词性、命名实体、二进制特性、词注意力、字符注意力以及MT-LSTM向量进行拼接综合文本的整体信息编码;
Step4、通过两层GRU进行上下文语义理解;
Step5、然后通过注意力及融合层进行重要信息提取同时做答案有无二分类;
Step6、最终利用输出层获取答案的起始位置和答案三分类。
作为本发明的进一步方案,所述Step1中,具体是把有答案片段的问题对应的篇章中的答案片段删去和该问题一起作为无答案类来扩充无答案数据,把是否类问题中的实体换成对应实体的英文表示来扩充是否类数据。
作为本发明的进一步方案,所述Step1中,输入是裁判文书的案情描述和相关的问题,分别为
作为本发明的进一步方案,所述Step2中,在词嵌入层将文本的分词序列及分字序列输入到词嵌入层分别得词嵌入和字符词嵌入;
C
C
C
C
其中,
为了选出词组中最能代表词语意思的那个字,将字符词嵌入表示做以下处理:
此时的
作为本发明的进一步方案,所述Step5中,在注意力及融合层,通过问题对篇章的注意力以及篇章自注意力增加与问题相关的信息权重,然后融合注意力及自注意力结果。
作为本发明的进一步方案,所述Step5中,在注意力及融合层,在问题对篇章的注意力之后基于答案标签对篇章用softmax作二分类,一类为有答案,另一类为无答案类。
作为本发明的进一步方案,所述Step5中,在注意力及融合层完成句法指导的问题mask自注意力:根据句法解析结果将问题当中的“ATT”、“RAD”及“LAD”位置的单词mask掉以此来生成问题自注意力的mask;
作为本发明的进一步方案,所述Step6中,将注意力融合得到的篇章向量输入到输出层,在输出层中将自注意力mask之后的问题对篇章表示作匹配,得到的结果进行答案开始和结束的计算;通过将计算开始和结束的向量进行门控融合进行答案:是、否、非是否三类进行三分类。
本发明的有益效果是:
本发明针对答案明显的特征,考虑到在问题对篇章注意时有答案和无答案的注意力分布明显差异问题,在注意力即融合层之后做答案有无二分类;考虑到是否类和片段类答案类别对答案起始位置的约束影响,在最后作答案三分类。对问题利用句法分析,在问题自注意力时运用句法指导的mask注意力机制提取问句中的关键信息,促使模型能从前期关注到的相关信息中提取到正确的答案。
实验结果表明本发明提出的方法有效提升了案情阅读理解的EM值和F1值。
附图说明
图1为本发明中的流程图;
图2为本发明中的模型构建示意图;
图3为本发明中的具体一个问题经过句法解析显示词与词之间的依赖关系结果示意图。
具体实施方式
实施例1:如图1-3所示,基于答案类别和句法指导的案情阅读理解方法,所述方法包括:
Step1、首先对训练数据中无答案类、是类否类进行数据扩充;具体是把有答案片段的问题对应的篇章中的答案片段删去和该问题一起作为无答案类来扩充无答案数据,把是否类问题中的实体换成对应实体的英文表示来扩充是否类数据。
作为本发明的进一步方案,所述Step1中,输入是裁判文书的案情描述和相关的问题,分别为
Step2、然后经过数据预处理将数据输入到词嵌入层,在词嵌入层对篇章和问题进行向量化;
作为本发明的进一步方案,所述Step2中,在词嵌入层将文本的分词序列及分字序列输入到词嵌入层分别得词嵌入和字符词嵌入;
C
C
C
C
其中,
为了选出词组中最能代表词语意思的那个字,将字符词嵌入表示做以下处理:
此时的
Step3、紧接着在表示编码层将文本的词嵌入、词性、命名实体、二进制特性、词注意力、字符注意力以及MT-LSTM向量进行拼接综合文本的整体信息编码;
具体的,所述Step3中,在表示编码层将文本词嵌入、词性、命名实体、二进制特征、词注意力、字符注意力以及MT-LSTM向量进行拼接编码,其中词嵌入是融合了字嵌入的词嵌入表示;
词嵌入表示:
问题对篇章的词注意力表示:
S
其中,
其中,α
其中P表示篇章经过问题词注意力的篇章表示;
字符注意力同词注意力表示计算一样,得到篇章经问题字符注意力的篇章表示
拼接生成文本向量表示:
Q=FFN([C
Step4、通过两层GRU进行上下文语义理解;
具体的,为了对文本语义进行理解,获取文本语义信息,将表示编码层得到的篇章及问题向量表示分别输入到两层GRU:
H=GRU(GRU[X,mt]) (12)
其中X表示篇章及问题的向量表示P和Q。
Step5、然后通过注意力及融合层进行重要信息提取同时做答案有无二分类;
作为本发明的进一步方案,所述Step5中,在注意力及融合层,通过问题对篇章的注意力以及篇章自注意力增加与问题相关的信息权重,然后融合注意力及自注意力结果。
具体如下:
Step5.1、问题对篇章的注意力计算:
S=dropout(ReLU(W
P=concat(P,Q·S) (14)
其中S表示相似度矩阵。
Step5.2、篇章的自注意力计算:
其中drop
Step5.3、注意力融合计算:
其中公式(18)表示问题对篇章的注意力,及篇章的自注意力融合计算。
作为本发明的进一步方案,无答案问题在篇章中找不到答案,因此这类问题在形式上对篇章的注意趋于均匀化,所以在Step5中,在注意力及融合层,在问题对篇章的注意力之后基于答案标签对篇章用softmax作二分类,一类为有答案,另一类为无答案类:
L
其中L
作为本发明的进一步方案,所述Step5中,在注意力及融合层完成句法指导的问题mask自注意力:根据句法解析结果将问题当中的“ATT”、“RAD”及“LAD”位置的单词mask掉以此来生成问题自注意力的mask;
具体一个问题经过句法解析显示词与词之间的依赖关系结果如图3所示,如果我们把mask掉的位置表示成0,未被mask掉的位置表示成1,则这个问题经句法解析生成的mask M可表示成:[0,0,0,1,1,1,1]+padding mask。对应到问题的自注意力应用:
S=W
α=softmax(M·S) (21)
Q'=∑
其中
Step6、最终利用输出层获取答案的起始位置和答案三分类。
作为本发明的进一步方案,所述Step6中,将注意力融合得到的篇章向量P输入到输出层,在输出层中将自注意力mask之后的问题Q'对篇章表示P作最后一次注意力,得到的结果进行答案开始和结束的计算。通过将计算开始和结束的向量进行门控融合进行答案:是、否、非是否三类进行三分类。
Step6.1、通过从以上得到的篇章表示P和问题自注意力表示Q'进行答案的开始和结束的计算。答案开始P
P
其中P
Step6.2、根据计算开始和结束的向量进行门控融合进行三分类:
其中L
本发明的基于答案类别和句法指导的案情阅读理解方法所用到的模型架构包括五个部分:词嵌入层、表示编码层、上下文编码层、注意力及融合层(包含二分类层)、输出层;
词嵌入层是将篇章和问题分别进行词向量化,
表示编码层是将文本的词向量、词性、命名实体、二进制特征、词注意力、字符注意力以及MT-LSTM向量拼接在一起形成文本向量表示;
上下文编码层运用GRU提取文本的特征、注意力及融合层将问题对篇章的注意力和篇章自身的字注意力融合在一起,二分类层是根据问题答案有无进行二分类,输出层通过问题自注意力结果对篇章匹配进行答案的起始位置计算和答案类别三分类。
该模型旨在通过明显的答案类别和句法解析信息提升模型获取重要信息的能力。首先对训练数据中无答案类,是类否类进行数据扩充。然后经过数据预处理将数据输入到模型。
利用梯度下降算法训练参数,由此构建融合句法指导与字符注意力机制的案情阅读理解模型。
本发明采用2019中国法研杯发布的裁判文书阅读理解数据集进行实验。数据集都包含训练集、验证集、测试集三部分,一共五万个问答对,涵盖民事和刑事两个方面的裁判案情,答案类型有片段抽取、是否类、无答案类。各类统计数据参见表1。本发明采用EM和F1作为评价指标。
表1数据统计
本发明中,分词采用哈工大LTP分词工具,预训练词向量采用fasttext(cc.zh.300.vec)。模型采用PyTorch框架实现,并在Nvidia Tesla P100 GPU上完成模型的训练和测试。本发明提出模型的参数设置如下:词嵌入维度为300,字嵌入维度为64,BiLSTM隐状态维度为128,所有LSTM的隐状态的dropout和回答模型的输出层的dropout都为0.4,批次大小为32,优化器选择Adamax,初始学习率为0.002。
本发明选择了四种主流的机器阅读理解模型作为基准模型,包括:双向注意力流模型BiDAF、结合卷积网络和自注意力机制的QAnet模型、把问题和篇章连接在一起进行编码的Unet和本发明的baseline模型SAN。为了验证提出方法的有效性,本发明方法及基准模型均未使用预训练语言模型。表2中BiDAF的实验结果为2019年法研杯竞赛给出的基准模型结果,QAnet和SAN的实验结果来源于论文复现的代码,Unet的实验结果来源于作者公布的github的代码。其中代码中的分词、词性及命名实体替换成了哈工大LTP工具。
Table 2Experimental results
表2实验结果
表2展示各基准模型在该数据集上的实验结果,其中Our_modle为本发明的方法。与基准模型相比,本发明提出的方法在该数据集上获得了更好的EM/F1值,表明了字符编码、字符注意力和句法指导的mask的有效性。其中BiDAF在测试集上的F1值来源于竞赛组织方提供的结果,QAnet和Unet表现不佳。对QAnet原因可能是因为法研杯数据集中篇章分词后长度近三分之一超过400分布在500左右,主要构造为卷积的QAnet并不适合处理过长的文本;对Unet原因可能是因为法研杯训练数据量较少和数据本身的特征有关;相比于这三个基准模型,SAN基准模型性能表现良好,因此我们选SAN作为本发明方法的baseline。
为了评估加入字符编码、答案类别以及句法mask各自的贡献,我们做了一个消融实验,其中“-”表示去掉此种方法,实验结果如表3所示。
Table 3Ablation experiments on the Fayan Cup data set
表3在法研杯数据集上的消融实验
表3显示了我们的模型和它在法研杯数据集上的消融情况。问题句法指导的mask的注意力机制对于模型性能是最关键的,它在两个评价标准上的影响是最明显的。原因可能是问题自注意力的时候有效的提取到了问题中的关键信息。答案类别也显著的影响了性能,它在评价标准上的影响次之,因为答案类型有明显的差异性。
由于对于问题自注意力句法指导的mask影响比较大,因此为了探索句法mask对模型性能的影响,我们在句法解析的结果上根据问题重要信息实施了两种策略:1.mask掉问题当中的“ATT”、“RAD”和“LAD”位置的信息,因为在篇章当中与“ATT”相关的信息太多,并且有些是其他问句中的主语;2.留下问题句中的“SBV”、“HED”“VOB”及“FOB”位置的信息,相当于留下了主谓宾位置的信息,实验结果如表4显示,第一种策略要好于第二种策略。
Table 4Mask experiment results of different strategies
表4不同策略的mask实验结果
上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 基于答案类别和句法指导的案情阅读理解方法
- 一种基于机器阅读理解的问题答案获取方法及系统