一种沉浸式语音交互方法及系统
文献发布时间:2023-06-19 11:54:11
技术领域
本申请涉及智能家居技术领域,尤其涉及一种沉浸式语音交互方法及系统。
背景技术
随着智能家居的快速发展,智能家居设备的种类也越来越多样化,比如,智能照明设备、智能电视、智能冰箱以及智能空调等等。在使用该类智能家居设备的过程中,为方便操作,用户可以通过语音来控制该类智能家居设备。比如,用户可以通过语音“打开电视”来控制智能电视的打开。
在现有技术中,用户通过语音来控制智能家居设备的方法主要为:设置一个语音采集设备,并且,该语音采集设备通过智能家居网关与智能家居设备建立网络连接。在使用过程中,首先,利用语音采集设备来采集用户的语音信息,然后,由智能家居网关对该语音信息进行识别,并生成控制指令,该控制指令用于指示智能家居设备执行相应的操作,然后,智能家居网关根据用户欲控制的目标智能家居设备,将控制指令发送至目标智能家居设备,以控制其执行相应的动作。
但是,由于语音采集设备的拾音距离有限,所以,当部署场景范围大的情况下,设置一个语音采集设备,无法满足用户在任意位置进行语音交互的需求。
发明内容
本申请实施例提供了一种沉浸式语音交互方法及系统,以实现用户在部署场景的任意位置的语音交互。
根据本申请实施例的第一方面,提供了一种沉浸式语音交互方法,该方法主要用于采集用户的语音数据,主要包括如下步骤:
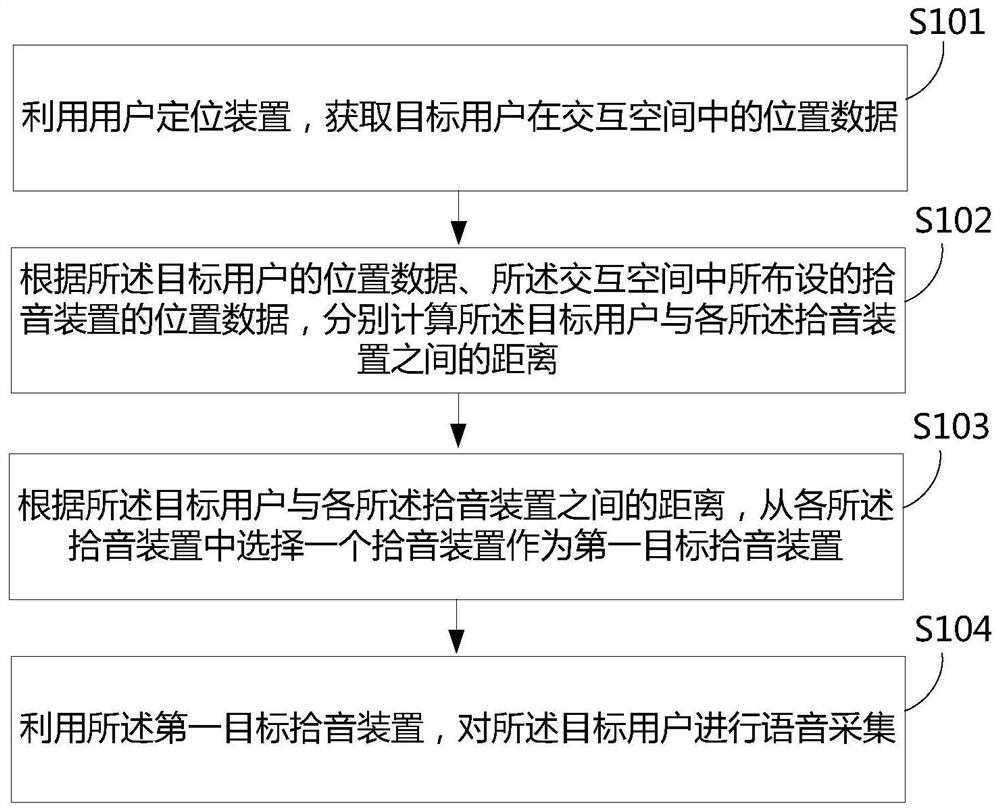
利用用户定位装置,获取目标用户在交互空间中的位置数据;
根据所述目标用户的位置数据、所述交互空间中所布设的拾音装置的位置数据,分别计算所述目标用户与各所述拾音装置之间的距离;
根据所述目标用户与各所述拾音装置之间的距离,从各所述拾音装置中选择一个拾音装置作为第一目标拾音装置;
利用所述第一目标拾音装置,对所述目标用户进行语音采集。
根据本申请实施例的第二方面,提供了另一种沉浸式语音交互方法,该方法主要用于向用户播放音频数据,主要包括如下步骤:
利用用户定位装置,获取目标用户在交互空间中的位置数据;
根据所述目标用户的位置数据、所述交互空间中所布设的音频播放装置的位置数据,分别计算所述目标用户与各所述音频播放装置之间的距离;
根据所述目标用户与各所述音频播放装置之间的距离,从各所述音频播放装置中选择一个音频播放装置作为第一目标音频播放装置;
利用所述第一目标音频播放装置,向所述目标用户播放音频数据。
根据本申请实施例的第三方面,提供了一种沉浸式语音交互系统,该系统包括:数据处理装置、与所述数据处理装置相连接的用户定位装置和多个拾音装置,其中,所述数据处理装置被配置为执行本申请实施第一方面所述的方法。
根据本申请实施例的第四方面,提供了另一种沉浸式语音交互系统,该系统包括:数据处理装置、与所述数据处理装置相连接的用户定位装置和多个音频播放装置,其中,所述数据处理装置被配置为执行本申请实施第二方面所述的方法。
由上述实施例可见,本申请实施例提供的沉浸式语音交互方法及系统,在预设交互空间内布设用户定位装置和多个拾音装置。根据用户定位装置所获取的目标用户在该交互空间中的位置数据、以及布设的各拾音装置的位置数据,分别计算所述目标用户与各所述拾音装置之间的距离,选取其中的一个拾音装置,对该目标用户进行语音采集,这样,用户便可以不再受单个拾音装置的拾音距离限制,实现用户在预设交互空间的任意位置的语音交互,并且,通过用户定位装置对用户的实时定位,可以实现通过切换拾音装置对用户进行语音采集,进而可为用户营造沉浸式、无处不在的语音交互体验。另外,基于上述设计方式,本实施例还提供了用于向用户播放音频数据的交互方式,进而可以为用户提供更佳的听觉效果。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本申请实施例提供的一种沉浸式语音交互系统的结构示意图;
图2为本申请实施例提供的一种沉浸式语音交互方法的基本流程示意图;
图3为本申请实施例提供的目标用户在交互空间中的位置计算方法示意图;
图4为本申请实施例提供的目标用户与拾音装置之间的距离计算方法示意图;
图5为本申请实施例提供的在相邻拾音装置之间设置的预激活区域示意图;
图6为本申请实施例提供的另一种沉浸式语音交互方法的基本流程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
图1为本申请实施例提供的一种沉浸式语音交互系统的结构示意图。如图1所示,在该系统设有数据处理装置300、与所述数据处理装置300相连接的用户定位装置100和多个拾音装置200,用户定位装置100和多个拾音装置200布设在预设交互空间中,其中,多个拾音装置200可以布设在交互空间中的不同位置。本实施例中,将部署该用户定位装置100和多个拾音装置200的空间称为交互空间,例如,会议室、客厅等均可以称为交互空间。
数据处理装置300可以根据用户定位装置100对用户的定位,启用一个拾音装置200,然后,根据启用的拾音装置200所采集的语音数据,控制相应的目标智能家居设备400、如智能电视、空调、音响等等。当然,需要说明的是,本实施例提供的沉浸式语音交互系统不仅适用于智能家居中,即数据处理装置300并不限于控制智能家居设备400,在其他实施例中还可以用于智能教室中控制屏幕投放等应用场景,或者,还可以仅用于用户语音的采集并进行用户语音的存储等。
另外,该系统中还可以设置多个音频播放装置,以为用户播放音频数据,其中,音频播放装置和拾音装置在本实施例可以被统称为语音交互装置。
基于上述系统,本实施例提供了一种沉浸式语音交互方法。图2为本申请实施例提供的一种沉浸式语音交互方法的基本流程示意图。如图2所示,该方法主要包括如下步骤:
S101:利用用户定位装置,获取目标用户在交互空间中的位置数据。
其中,本实施例中将在交互空间中发出语音的用户为声源用户,在所述声源用户中所筛选出的可以与该交互系统进行语音交互的用户为目标用户,例如,基于各声源用户的权限有限级别进行目标用户的筛选、和/或基于已构建的语音交互的进程不中断的原则进行目标用户的筛选。
对于用户的位置数据,可以在交互空间中构建XYZ三维空间模型,将用户在该三维空间模型中的位置坐标,作为其在该交互空间中的位置数据。当然,可以采用其它标定方法,例如采用极坐标的标定方式。
对于用户的定位方式,可以采用机器视觉与声纹识别相结合的方式,例如,利用图像采集装置、测距装置以及声纹识别装置进行用户定位,具体可以包括如下步骤:
S1011a:利用图像采集装置,采集所述交互空间中的用户图像,所述用户图像中包含一个或多个用户。
例如,采用RGB摄像头采集交互空间中的用户图像,然后,利用人脸识别算法识别出每一帧的用户图像中各用户信息、以及每个用户在所述用户图像的位置。
S1012a:根据各所述用户在所述用户图像中的位置,利用测距装置,分别测量各所述用户与所述测距装置的距离。
其中,测距装置可以为深度摄像头,深度摄像头和RGB摄像头设置在同一位置且拍摄角度也相同。根据RGB摄像头中采集的用户在用户图像中的位置,在深度摄像头采集的图像数据中的对应位置,取出用户距离深度摄像头的距离信息。利用交互空间中布设的深度摄像头和RGB摄像头,便可以获取在该交互空间中所有用户距离其对应的深度摄像头的距离信息。
S1013a:根据各所述用户与所述测距装置的距离、所述测距装置在所述交互空间中的位置数据,分别计算出各所述用户在所述交互空间的位置数据。
图3为本申请实施例提供的目标用户在交互空间中的位置计算方法示意图。如图3所示,设测距装置在交互空间中的位置坐标为(x
在上述公式中,m为用户与x轴之间的夹角,其可以根据测距装置摆放时相对于x轴的倾斜角度、用户面部与测距装置所处位置垂线的夹角计算得到;S
当然,上述只是本实施例提供的一种用户位置的计算方法,在其他实施例中还可以采用其它方法,本实施例不再一一赘述。
S1014a:利用声纹识别装置,识别出所述交互空间中的目标用户。
首先,利用声纹识别装置,通过用户的声音分别判别出各说话用户的身份信息,即判别出谁发出的声音,其中,该步骤可以与上述用户位置的定位过程同步进行;然后,根据预设的目标用户筛选规则,以及说话用户的身份信息,从说话的用户中筛选出可以与语音交互系统进行语音交互的目标用户。
S1015a:从各所述用户在所述交互空间的位置数据中,筛选出所述目标用户在交互空间中的位置数据。
根据步骤S1014a中所筛选出目标用户以及其身份信息,从步骤S1013a中所计算得到的各用户在所述交互空间的位置数据中,筛选出该目标用户在交互空间中的位置数据。
进一步的,为减少数据处理装置的数据处理量,在利用图像采集装置、测距装置以及声纹识别装置进行用户定位时,本实施例还提供了如下处理方式:
S1011b:利用声纹识别装置,识别出所述交互空间中的目标用户。
首先,利用声纹识别装置,通过声音判别出交互空间中说话用户的身份信息,然后,根据预设的目标用户筛选规则,以及说话用户的身份信息,从当前说话的用户中筛选出目标用户。
S1012b:利用图像采集装置,采集所述交互空间中的用户图像。
利用图像采集装置,采集交互空间中的用户图像后,根据目标用户的身份信息,从该用户图像中找到目标用户以及该目标用户在用户图像中的位置。
S1013b:根据所述目标用户在所述用户图像中的位置,利用测距装置,测量所述目标用户与所述测距装置的距离。
其中,测距装置可以为深度摄像头,深度摄像头和RGB摄像头设置在同一位置且拍摄角度也相同。根据RGB摄像头中采集的用户在用户图像中的位置,在深度摄像头采集的图像数据中的对应位置,取出用户距离深度摄像头的距离信息。利用交互空间中布设的深度摄像头和RGB摄像头,便可以获取在该交互空间中所有用户距离其对应的深度摄像头的距离信息。
S1014b:根据所述目标用户与所述测距装置的距离、所述测距装置在所述交互空间中的位置数据,计算出所述目标用户在所述交互空间的位置数据。
具体计算过程可以参考S1013a,本实施例先进行目标用户筛选的方式,只需要计算目标用户在交互空间的位置数据,进而可以减少数据处理装置的数据计算量,尤其适用于交互空间中用户较多的应用场景。
当然除了上述利用图像采集装置、测距装置以及声纹识别装置进行目标用户的方式外,还可以使用其它定位方式,例如,声纹识别装置和毫米波雷达装置对目标用户定位,具体的,首先借助声纹识别装置识别出交互空间中的目标用户,然后毫米波雷达装置识别出目标用户在该交互空间中位置数据,以满足用户的隐私要求,本实施例在此不再一一赘述。
S102:根据所述目标用户的位置数据、所述交互空间中所布设的拾音装置的位置数据,分别计算所述目标用户与各所述拾音装置之间的距离。
图4为本申请实施例提供的目标用户与拾音装置之间的距离计算方法示意图。如图4所示,该交互空间内布设有四个拾音装置,如果采用XYZ三维空间坐标模型,则可以根据该目标用户在交互空间中的位置坐标、各拾音装置在该交互空间的位置坐标,计算出该目标用户与各拾音装置之间的距离,分别为L
S103:根据所述目标用户与各所述拾音装置之间的距离,从各所述拾音装置中选择一个拾音装置作为第一目标拾音装置。
其中,可以选用距离目标用户最近的一个拾音装置,作为用户语音采集的第一目标拾音装置。例如,在图4中的部署场景中,L
S104:利用所述第一目标拾音装置,对所述目标用户进行语音采集。
本实施例中的拾音装置可以由多颗麦克风单元组成,多颗麦克风单元组成麦克风阵列进行录音,这样便可以利用多通道的语音信号数据进行后期处理,从而可以抑制噪声,增强目标语音信号。其中,使用麦克风阵列进行拾音的步骤主要包括:首先,确定目标用户的位置;然后,利用波束形成技术对语音信号进行增强。
然而,在对目标用户进行语音采集的过程中,常会存在目标用户位置移动的情况,如果一致将麦克风阵列的拾音增强位置固定在该目标拾音装置唤醒的时刻时所确定出的位置,将会影响最终的拾音效果,因此,在利用第一目标拾音装置,对所述目标用户进行语音采集时,会采用如下处理方式:
(1),根据所述用户定位装置所获取的所述目标用户在交互空间中的当前位置数据,调整所述第一目标拾音装置的拾音增强方向。
即利用用户定位装置实时获取的目标用户在交互空间中的当前位置数据,确定目标用户相对于第一目标拾音装置的定位方向,来调整第一目标拾音装置的拾音增强方向,以对拾音增强方向的语音信号进行语音增强。其中,该定位方向的计算方式,可以根据第一目标拾音装置中各麦克风单元的排布方式来确定,例如,其麦克风阵列为多颗在xy平面排布的麦克风单元组成的平面环形结构,进而该目标用户相对于第一目标拾音装置的定位方向,可以根据两者在xy平面在夹角来确定。
(2),将所述第一目标拾音装置所采集的所述目标用户的语音信号中,位于所述拾音增强方向的语音信号进行语音增强。
其中,将增强过的语音信号定义为第一增强语音信号,也就是说第一增强语音信号为对所述拾音增强方向对应的一路语音信号进行语音增强后得到的,其中,语音增强的方法主要是进行噪声抑制,然后,将第一增强语音信号作为最终所拾取到的语音输出。
本实施例根据用户定位装置对目标用的实时定位计算的结果,向拾音装置发送定位信号,拾音装置根据目标用户的实时的定位角度信息,调整拾音增强方向,进而可以满足用户的位置移动下,最佳收音角度的调整,保证拾音效果的稳定性。
进一步的,为了保证目标用户在移动的场景下,拾音的连续性,在上述步骤S104之后,还包括如下步骤:
S105:利用所述用户定位装置,获取的所述目标用户在交互空间中的当前位置数据。
即在利用第一目标拾音装置对目标用户进行语音采集的过程中,同时启用用户定位装置对目标用户在交互空间中位置进行定位。
S106:根据所述当前位置数据,判断所述目标用户是否处于预激活区域内,所述预激活区域设置在相邻的拾音装置之间。
图5为本申请实施例提供的在相邻拾音装置之间设置的预激活区域示意图。如图5所示,本实施例在相邻的拾音装置之间设置一块预激活区域,其中,预激活区域的范围可以根据实际需求设定。其中,各预激活区域之间可以存在交集,也可以相互独立,如果存在交集,则还需要利用所述用户定位装置所获取的各位置数据,形成目标用户的运动轨迹,以确定目标用户的运动方向。
若用户处于该预激活区域内,则执行步骤S107,否则,则继续执行步骤S104。
S107:如果所述目标用户处于预激活区域内,则根据所述目标用户所处的预激活区域,确定第二目标拾音装置。
例如,如图5所示,目标用户当前处于拾音装置1与拾音装置4之间的预激活区域,则将拾音装置4作为第二目标拾音装置,或者,当前目标用户当前处于各预激活区域重叠区域,则可以根据用户的运动轨迹,确定该目标用户正走向拾音装置3,则将拾音装置2作为第二目标拾音装置。
S108:向所述第二目标拾音装置发送启动指令,以启动所述第二目标拾音装置。
第二目标拾音装置在接收到该启动指令后,便会直接启动,以待目标用户移动到了预设的切换边界后,便可以直接将拾音装置切换为第二目标拾音装置,直接进行语音采集,保证语音采集结果的连续性。当然,如果启动第二目标拾音装置后,在预设时间之后,用户未进入启用第二目标拾音装置的预设的切换边界,则可以再关闭第二目标拾音装置或者控制第二目标拾音装置进入省电模式。
S109:根据所述目标用户的当前位置数据,判断所述目标用户是否进入所述第二目标拾音装置的拾音区域内。
基于上述预设的预激活区域,本实施例提供了在进行拾音装置切换时,划分拾音装置的拾音区域的方法,其中,将围成预激活区域的边界由第一边界和第二边界组成,其中,第一边界为靠近第一目标拾音装置的边界,第二边界为靠近第二目标拾音装置的边界。如果目标用户由第一目标拾音装置走向第二拾音装置,则只有目标用户越过第二边界后,才会判定其处于第二目标拾音装置的拾音区域内,进而会启用第二目标拾音装置对该目标用户进行语音采集;如果目标用户由第二目标拾音装置走向第一目标拾音装置,则只有目标用户越过第一边界后,才会判定其处于第一目标拾音装置的拾音区域内,进而会启用第一目标拾音装置对该目标用户进行语音采集。即,第二目标拾音装置向第一目标拾音装置与第一目标拾音装置向第二目标拾音装置的边界并不相同,中间相隔了预激活区域,这边便可以保证目标用户处于切换临界附近位置是,不会连续切换拾音装置。
S110:如果所述目标用户处于所述第二目标拾音装置的拾音区域内,则利用所述第二目标拾音装置对所述目标用户进行语音采集,向所述第一目标拾音装置发送关闭指令。
其中,该关闭指令可以控制第一目标拾音装置直接关闭,还可以控制其进入省电模式,本实施例在此不做具体限定。
本实例提供的语音交互方法,用户不再受单个拾音装置的拾音距离限制,可以实现用户在预设交互空间的任意位置的语音交互,并且,通过用户定位装置对用户的实时定位,可以实现通过切换拾音装置对用户进行语音采集,进而可为用户营造沉浸式、无处不在的语音交互体验。
基于上述设计思想,本实施例还提供了用于向用户播放音频数据的交互方式,进而可以为用户提供更佳的听觉效果。
图6为本申请实施例提供的另一种沉浸式语音交互方法的基本流程示意图。如图6所示,该方法具体包括如下步骤:
S201:利用用户定位装置,获取目标用户在交互空间中的位置数据。
其中,本实施例中将在交互空间中,需要向其推送音频数据的用户为目标用户,例如,向用于播放音频的音频设备发送特定唤醒指令的用户。
对于用户的位置数据,可以在交互空间中构建XYZ三维空间模型,将用户在该三维空间模型中的位置坐标,作为其在该交互空间中的位置数据。当然,可以采用其它标定方法,例如采用极坐标的标定方式。
对于用户的定位方式,可以采用机器视觉与声纹识别相结合的方式,也可以采用视觉传感器、毫米波雷达定为方式,本实施例在此不做具体限定。
S202:根据所述目标用户的位置数据、所述交互空间中所布设的音频播放装置的位置数据,分别计算所述目标用户与各所述音频播放装置之间的距离。
S203:根据所述目标用户与各所述音频播放装置之间的距离,从各所述音频播放装置中选择一个音频播放装置作为第一目标音频播放装置。
S204:利用所述第一目标音频播放装置,向所述目标用户播放音频数据。
需要说明的是,本实施例提供了方法可以与上述拾音过程在一个应用场景中,例如,用户通过语音控制音频播放装置的场景中,利用拾音装置采集用户发出的语音指令后,再基于用户发出的指令,通过音频播放装置向用户播放音频数据。
进一步的,为了适应于用户移动的应用场景,本实施例还提供了如下处理步骤:
S205:利用所述用户定位装置,获取所述目标用户在交互空间中的各当前位置数据;
S206:根据所述当前位置数据,判断所述目标用户是否处于预激活区域内,所述预激活区域设置在相邻的音频播放装置之间。
S207:如果所述目标用户处于预激活区域内,则根据所述目标用户所处的预激活区域,确定第二目标音频播放装置。
S208:向所述第二目标音频播放装置发送启动指令,以启动所述第二目标音频播放装置。
S209:根据所述目标用户的当前位置数据,判断所述目标用户是否处于所述第二目标音频播放装置的拾音区域内。
S210:如果所述目标用户处于所述第二目标音频播放装置的拾音区域内,则利用所述第二目标音频播放装置对所述目标用户进行语音采集,向所述第一目标音频播放装置发送关闭指令。
本实施例在相邻的音频播放装置之间设置预激活区域,用户移动到此区域时,不会立刻进行语音播放装置的切换,到达只有到公共激活区域的边界后才会切换,并且,将由第一目标音频播放装置到第二目标音频播放装置和由第二目标音频播放装置到第一目标音频播放装置的切换边界设置为不同的边界,以保证用户移动临界点位置不会连续切换设备,其具体的实现方式可以参考上述实施例。
基于上述方法同样的发明构思,本实施例还提供了一种沉浸式语音交互系统,用于语音采集,所述系统包括:数据处理装置、与所述数据处理装置相连接的用户定位装置和多个拾音装置,其中,所述数据处理装置被配置为执行上述实施例中的用于语音采集的沉浸式语音交互方法。
本实施例还提供了另一种沉浸式语音交互系统,用于音频数据的播放,所述系统包括:数据处理装置、与所述数据处理装置相连接的用户定位装置和多个音频播放装置,其中,所述数据处理装置被配置为执行上述实施例中的用于音频播放的沉浸式语音交互方法。
当然,上述两个系统可以集成在一个系统中,即该系统中同时包括拾音装置和语音播放装置。
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包括这些改动和变型在内。
- 一种沉浸式语音交互方法及系统
- 一种智能眼镜的语音交互方法、语音交互系统及智能眼镜