数据处理方法、装置、电子设备及计算机存储介质
文献发布时间:2023-06-19 11:57:35
技术领域
本发明涉及计算机技术领域,尤其涉及一种数据处理方法、装置、电子设备及计算机存储介质。
背景技术
交易异常行为链条由分工明确的上下游小群体配合衔接组成,如上游的办卡小组、中游的拨号小组和下游的转账取款小组等,一般采取远程的、非接触式的交易异常行为,这对阻止交易异常行为带来了很大的困难。在相关技术中,识别交易异常行为主要包括基于交易异常名单库的识别方法和基于通话信息的识别方法。基于交易异常名单库的识别方法根据发起通信业务的手机号码是否为名单库里的手机号码,来判断交易异常个体,但是不能识别交易异常群体。基于通话信息的识别方法通过分析来电音频的通话时长、通话内容或/ 和音频指纹等特征对应的指标值,并与交易异常名单库中的指标值进行匹配,在匹配度达到预设阈值时判定来电音频为交易异常音频,对名单库外的交易异常行为识别度不高,造成对交易异常群体识别的准确度较低。
针对相关技术中,识别交易异常群体存在准确度低的问题,目前尚未提出有效的解决方案。
发明内容
本申请实施例提供了一种数据处理方法、装置、电子设备及计算机存储介质,以至少解决相关技术中识别交易异常群体存在准确度低的问题。
第一方面,本申请实施例提供了一种数据处理方法,所述方法包括:
根据交易数据构建关联网络,并基于社区发现算法对所述关联网络进行划分得到多个社群;
基于交易异常名单训练机器学习模型;
将所述交易数据输入训练好的机器学习模型进行交易异常个体识别,将交易异常个体的占比达到预设阈值的社群作为交易异常群体。
在其中一些实施例中,所述根据交易数据构建关联网络之前,所述方法还包括:
获取交易流水日志,检查所述交易流水日志中的交易信息包含的字段是否完整,并对字段完整的交易信息进行标准化处理得到所述交易数据。
在其中一些实施例中,所述根据交易数据构建关联网络包括:
对所述交易数据进行实体抽取和实体间关系抽取,并根据抽取得到的实体和实体间关系得到所述关联网络,其中,所述实体包括客户、手机号码、IP以及设备编号,所述实体间关系包括客户与设备编号间的使用关系、客户与IP间的使用关系、客户与手机号码间的使用关系以及客户间的交易关系。
在其中一些实施例中,所述机器学习模型的特征指标包括非图指标和图指标:
所述非图指标根据所述交易数据中的交易日期、交易时间、交易类型和交易结果进行指标加工得到;
所述图指标根据所述关联网络加工得到。
在其中一些实施例中,所述基于交易异常名单训练机器学习模型包括:
根据所述实体间关系对所述交易异常名单进行扩展,并基于扩展后的名单的交易数据训练所述机器学习模型。
在其中一些实施例中,所述根据所述实体间关系对所述交易异常名单进行扩展包括:
根据所述交易异常名单中的手机号码、所述客户与手机号码间的使用关系以及客户间的一度交易关系和二度交易关系,得到黑样本;
将所述黑样本的手机号码加入所述交易异常名单,得到所述扩展后的名单。
在其中一些实施例中,所述交易异常群体包括所述交易异常个体和可疑个体,所述将交易异常个体的占比达到预设阈值的社群作为交易异常群体之后,所述方法还包括:
将所述可疑个体的手机号码加入所述扩展后的名单,得到二次扩展后的名单;
根据所述二次扩展后的名单再次训练所述训练好的机器学习模型,得到二次训练的机器学习模块,其中,所述二次训练的机器学习模型用于交易异常个体识别。
第二方面,本申请实施例提供了一种数据处理装置,所述装置包括关联网络构建模块、训练模块和识别模块;
其中,所述关联网络构建模块,用于根据交易数据构建关联网络,并基于社区发现算法对所述关联网络进行划分得到多个社群;
所述训练模块,用于基于交易异常名单训练机器学习模型;
所述识别模块,用于将所述交易数据输入训练好的机器学习模型进行交易异常个体识别,将交易异常个体的占比达到预设阈值的社群作为交易异常群体。
第三方面,本申请实施例提供了一种电子设备,包括存储器、处理器以及存储在所述存储器上并在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述第一方面所述的数据处理方法。
第四方面,本申请实施例提供了一种计算机存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上述第一方面的数据处理方法。
相比相关技术,本申请实施例提供的数据处理方法,根据该交易数据构建包括各个客户以及客户间交易关系的关联网络,并对该关联网络中的客户进行划分,将交易关系紧密的客户分在同一个社群中。然后在根据交易异常名单对应的交易数据训练机器学习模型,使得训练好的机器学习模型完全是基于客观可靠的交易数据,可以准确得识别出交易异常个体。又因为同一社群中个体之间的交易关系非常紧密,就可以通过分析各个社群的成员构成可以准确识别交易异常群体。相较于通话信息,交易数据可靠性更高,因此基于交易数据对交易异常群体的识别结果也更可靠,并且交易数据对于金融机构来说获取更加方便,有利于金融机构在发现交易异常群体的情况下及时阻止交易异常转账行为,还可以为后期交易异常行为的侦查提供准确的数据支撑。进一步可以基于交易异常名单和关联网络中客户间的交易关系等实体间关系,对交易异常名单进行扩展,并基于扩展后的名单训练机器学习模型,使得训练好的机器学习模型相较于仅利用现有的交易异常名单训练得到的模型,具有更强的泛化能力,可以在一定程度上克服了模型缺乏训练样本的问题,提高模型识别交易异常个体的准确率。
附图说明
此处所说明的附图用来提供对本申请的进一步理解,构成本申请的一部分,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
图1是根据本申请实施例的数据处理方法的流程图;
图2是根据本申请实施例的另一种数据处理方法的流程图;
图3是根据本申请实施例的数据处理装置的结构示意图;
图4是根据本申请实施例的电子设备的内部结构示意图。
具体实施方式
为了使本申请的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本申请进行描述和说明。应当理解,此处所描述的具体实施例仅仅用以解释本申请,并不用于限定本申请。基于本申请提供的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本申请保护的范围。
显而易见地,下面描述中的附图仅仅是本申请的一些示例或实施例,对于本领域的普通技术人员而言,在不付出创造性劳动的前提下,还可以根据这些附图将本申请应用于其他类似情景。此外,还可以理解的是,虽然这种开发过程中所作出的努力可能是复杂并且冗长的,然而对于与本申请公开的内容相关的本领域的普通技术人员而言,在本申请揭露的技术内容的基础上进行的一些设计,制造或者生产等变更只是常规的技术手段,不应当理解为本申请公开的内容不充分。
在本申请中提及“实施例”意味着,结合实施例描述的特定特征、结构或特性可以包含在本申请的至少一个实施例中。在说明书中的各个位置出现该短语并不一定均是指相同的实施例,也不是与其它实施例互斥的独立的或备选的实施例。本领域普通技术人员显式地和隐式地理解的是,本申请所描述的实施例在不冲突的情况下,可以与其它实施例相结合。
除非另作定义,本申请所涉及的技术术语或者科学术语应当为本申请所属技术领域内具有一般技能的人士所理解的通常意义。本申请所涉及的“一”、“一个”、“一种”、“该”等类似词语并不表示数量限制,可表示单数或复数。本申请所涉及的术语“包括”、“包含”、“具有”以及它们任何变形,意图在于覆盖不排他的包含;例如包含了一系列步骤或模块(单元)的过程、方法、系统、产品或设备没有限定于已列出的步骤或单元,而是可以还包括没有列出的步骤或单元,或可以还包括对于这些过程、方法、产品或设备固有的其它步骤或单元。本申请所涉及的“连接”、“相连”、“耦接”等类似的词语并非限定于物理的或者机械的连接,而是可以包括电气的连接,不管是直接的还是间接的。本申请所涉及的“多个”是指两个或两个以上。“和/或”描述关联对象的关联关系,表示可以存在三种关系,例如,“A和/ 或B”可以表示:单独存在A,同时存在A和B,单独存在B这三种情况。字符“/”一般表示前后关联对象是一种“或”的关系。本申请所涉及的术语“第一”、“第二”、“第三”等仅仅是区别类似的对象,不代表针对对象的特定排序。
在交易异常行为中,交易异常个体通过手机、固定电话、网络和短信方式,编造虚假信息,对用户实施远程、非接触式交易异常行为,会造成用户给交易异常个体打款或转账。而在整个交易异常行为链条中,用户资金损失的关键环节是转账环节,若转账成功,则交易异常行为成功;若转账被拦截,则交易异常行为失败。转账环节涉及的主体是用户、银行和支付机构,通常情况下,基于交易异常个体的行为,会导致用户无法做出正确的决策,因此银行和支付机构等金融机构成为关键主体,承担起阻止交易异常行为的责任。
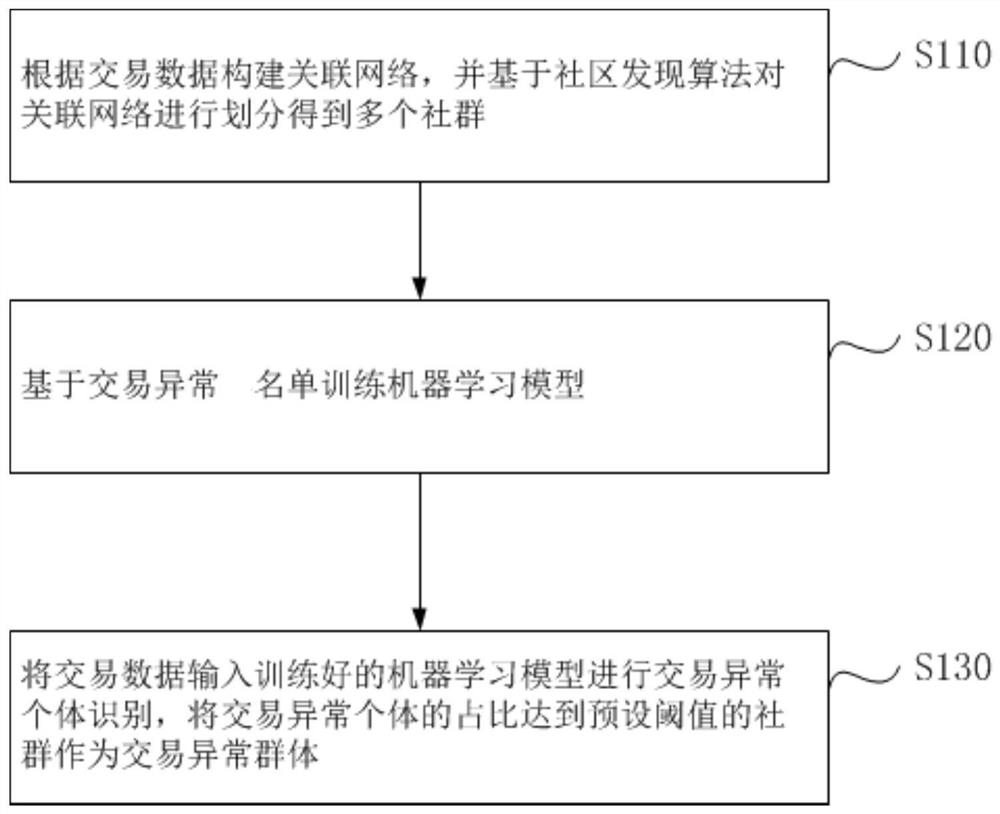
本实施例提供了一种数据处理方法。图1是根据本申请实施例的数据处理方法的流程图,如图1所示,该流程包括如下步骤:
S110、根据交易数据构建关联网络,并基于社区发现算法对关联网络进行划分得到多个社群。
交易数据来源于银行和/或支付机构的交易流水日志,包括但不限于客户编号、交易账号、交易对方账号、交易日期、交易时间、交易类型、交易结果、IP、交易设备编号、手机号码等。交易数据是交易流水日志通过处理后得到的结构化数据,对该交易数据进行实体抽取,并根据各项之间存在的关系名称和对应关系,确定并抽取实体间关系。实体是现实世界中如人物、企业、电话、邮箱、地址等的任何事物。优选地,实体包括客户、手机号码、IP 以及设备编号,实体间关系包括客户与设备编号间的使用关系、客户与IP间的使用关系、客户与手机号码间的使用关系以及客户间的交易关系。将各实体作为关联网络中的各节点,根据实体间关系生成各节点之间的边,得到关联网络。该关联网络可以通过网络结构表示出交易数据中客户等实体及客户间的交易关系等实体关系。
然后采用社区发现算法将该关联网络中交易关系紧密的客户实体节点归为同一个社群,而不同社群之间的交易关系比较稀疏。社区发现算法包括但不限于标签传播算法(Label Propagation,简称LP算法)和鲁汶(Louvain Method,简称LM)算法。
优选地,采用LM算法对该关联网络进行划分,具体分为两个阶段。第一阶段中,将每个客户实体节点作为一个独立的初始社群,初始社群的个数和客户实体节点个数相同。然后针对每个客户实体节点i,i=1,...,N,N表示该关联网络中客户实体节点的数量,计算将客户实体节点i尝试分配到一度关联节点所属社区的模块度增量。一度关联节点是指与该客户实体节点i之间具有一度交易关系的客户实体节点。模块度增量可以根据客户间的交易金额等交易关系计算得到,表示了模块度在客户实体节点i分配后相对于分配前模块度的变化量,该值越大,划分效果越好。将客户实体节点i分配到模块度增量最大的一度关联节点所属的社群。第二阶段中,将第一阶段形成的每个社群压缩为一个新节点,然后重复第一阶段中的节点分配,直到关联网络的模块度不变或变小,各客户实体节点所属的社群不再变化,对该关联网络的社群划分完成。各社群可以准确地表示客户个体行为的局部特性以及客户个体间的关联特性。
并且关联网络中的各社群具有层次性。比如关联网络中有 20000个客户实体节点,先将每个客户实体节点为一个初始社群,经过第一阶段形成了100个社群,假设其中有社群A1、A2、...A100 均包括200个客户实体节点。实际引用需要说明的是,实际应用中,每个社群包括的实体节点个数根据算法产生,不一定相同。在第二阶段将100个社群缩成100个新节点,对100个新节点执行第一阶段的节点分配形成10社群,假设其中有社群B1包括10个新节点,这10个新节点分别是社群A1、A2、...A10缩成的新节点,因此社群B1就有了层次性,200个客户实体节点是第一层, 10个新节点是第二层。虽然在第一阶段涉及到的客户实体节点较多,并且每次都要计算分配到一度关联节点的模块度增量,计算量较大,但在第二阶段中新节点的数量显著减少,计算量显著降低。因此采用LM算法可以对包含大量客户实体节点的关联网络快速实现社群划分。
S120、基于交易异常名单训练机器学习模型。
交易异常名单包括交易异常行为链条中拨号小组的手机号码。将交易异常名单中手机号码用户的交易数据作为交易异常群体的标签样本,根据机器学习模型的特征指标得到该标签样本的交易特征向量。该交易特征向量可以包括交易异常名单中手机用户的行为类、交易类、时序类、高频类等常规的非图特征值,比如,交易金额为整数倍的大额交易的笔数、单笔交易金额占每笔限额的比例等。该交易特征向量还可以包括交易异常名单中手机用户所在社群的社群规模、一度关联节点数等根据关联网络得到的图特征值。基于该交易特征向量对机器学习模型的模型参数进行训练,获得训练好的机器学习模型。机器学习模型不限于是神经网络模型或GBDT(Gradient Boosting Decision Tree,梯度提升决策树)模型。
本实施例中,机器学习模型为LightGBM(Light Gradient Boosting Machine)模型,LightGBM模型是一种基于直方图的决策树,可以对大量交易异常名单的交易数据进行训练。具体地, LightGBM模型训练过程包括:将交易特征向量中浮点型的各非图特征值和各图特征值,分别按照预设参数K进行离散化得到K个整数,同时构造一个宽度为K的直方图。在直方图中统计交易异常名单中各手机用户的交易特征向量中各个特征值离散化后的整数值,然后遍历统计的整数值找到分裂节点,以根据该分裂节点将各手机用户分裂为决策树中的叶子节点。相较于训练GBDT模型对所有特征都按照特征值进行预排序然后遍历寻找分裂节点,需要保存特征值以及特征预排序的结果,训练 LightGBM模型只需保存特征离散化后的值,并且这个值一般用8 位整型存储,可以极大地降低大量内存消耗。同时训练LightGBM 模型在遍历寻找分裂节点时只需要计算K次分裂增益就可以找到分裂节点,可以大量减少计算时间。
S130、将交易数据输入训练好的机器学习模型进行交易异常个体识别,将交易异常个体的占比达到预设阈值的社群作为交易异常群体。该预设阈值是根据关联网络中交易异常个体的分布确定的,且该预设阈值还可以根据交易异常群体经过模型验证的结果来反馈迭代进行优化。优选地,在将多个社群中交易异常个体的占比达到预设阈值的社群作为交易异常群体之后,针对交易异常群体的汇款记录实现资金查询追踪,自动输出大量交易异常汇款记录所对应的资金流向以及所经各嫌疑账户的资金流水,从而最大化提高查询追踪交易异常群体的效率,同时为后期交易异常行为的侦查提供准确的数据支撑。
通过上述步骤,根据该交易数据构建包括各个客户以及客户间交易关系的关联网络,并对该关联网络中的客户进行划分,将交易关系紧密的客户分在同一个社群中。然后在根据交易异常名单对应的交易数据训练机器学习模型,使得训练好的机器学习模型完全是基于客观可靠的交易数据,可以准确得识别出交易异常个体。又因为同一社群中个体之间的交易关系非常紧密,就可以通过分析各个社群的成员构成可以准确识别交易异常群体。相较于通话信息,交易数据可靠性更高,基于交易数据对交易异常群体的识别结果也更可靠,并且交易数据对于金融机构来说获取更加方便,有利于金融机构在发现交易异常群体的情况下及时阻止交易异常转账行为,还可以为后期交易异常行为的侦查提供准确的数据支撑。
在实际交易异常行为中涉及交易异常资金的交易环节复杂、交易层级较多,从开立账户接收交易异常资金,到转移赃款直至最终清洗完毕(多为取现),其间涉及众多账户。在每个交易环节,所涉账户均存在诸多不同的可疑特征。为了有效发现相关交易异常账户,不能简单依靠某一个可疑特征作出判断,必须在客户尽职调查的基础上,结合多种可疑特征进行综合判断,因此通过非图指标和图指标丰富机器学习模型的特征指标,以提高模型质量。
在一些实施例中,非图指标根据交易数据中的交易日期、交易时间、交易类型和交易结果进行指标加工得到。非图指标包括常规的行为类、交易类、时序类、高频类等特征,比如,交易金额为整数倍的大额交易的笔数、单笔交易金额占每笔限额的比例等。图指标根据关联网络加工得到。图指标包括但不限于所在社群指标、自身属性指标、一度关联指标和二度关联指标。根据关联网络中实体和实体间关系的属性,比如客户间交易关系的交易时间属性、交易金额属性等特性描述,结合关联网络特有的节点度数 (degree)、pagerank值等,可以得到如下表1所述的图指标。根据非图指标和图指标构建机器学习模型的特征指标,可以丰富机器学习模型的特征指标,有利于提取交易数据的多种可疑特征。
表1
在一些实施例中,在很多场景下无法获取包含大量交易异常黑样本的名单,机器学习模型的训练样本较少,无法训练获得高质量的机器学习模型。为了克服模型缺乏训练样本的问题,通过关联网络中的实体间关系对交易异常名单进行扩展,利用扩展后的名单训练机器学习模型,从而使机器学习模型具有更多的训练样本,在一定程度上提高模型的识别能力。
优选地,根据交易异常名单中的手机号码、关联网络中客户与手机号码间的使用关系以及客户间的一度交易关系和二度交易关系,得到可疑的黑样本。具体地,在关联网络中确定使用交易异常名单中手机号码的客户,进一步根据交易异常行为链条中转账环节涉及的交易关系结合专家经验、规则系统,获得与交易异常名单中的客户有一度交易关系和二度交易关系甚至多度交易关系的其他客户,即为可疑的黑样本。将这些黑样本的手机号码加入交易异常名单,可以得到扩展后的名单。然后将扩展后的名单对应的交易数据作为标签样本,来训练机器学习模型,训练好的机器学习模型相较于仅利用现有的交易异常名单训练得到的模型,具有更强的泛化能力,可以在一定程度上提高识别交易异常个体的准确率。
在一些实施例中,在根据交易数据构建关联网络之前,首先获取交易流水日志,检查交易流水日志中的交易信息包含的字段是否完整,并对字段完整的交易信息进行标准化处理得到交易数据。交易流水日志包括但不限于客户基本信息和交易流水信息,检查客户编号、交易账号、交易对方账号、交易日期、交易时间、交易类型、交易结果、IP、交易设备编号、手机号码等字段是否缺失,以确保所需要的字段都存在。进一步地,探查字段完整的交易信息的数据质量,分析缺失率,查看业务指标可能性并主要针对IP、Mac 地址、交易流水数据做进一步图结构分析,通过对常见图结构的筛查,提取异常结构指标,并结合业务做异常性分析等建网可行性分析。通过对字段完整的交易信息进行不限于上述操作的标准化处理,可以保证交易数据的完整性,有利于更好地构建关联网络。
本实施例还提供了另一种数据处理方法。图2是根据本申请实施例的另一种数据处理方法的流程图,如图2所示,该流程包括如下步骤:
S210、根据交易数据构建关联网络,并基于社区发现算法对关联网络进行划分得到多个社群。
S220、根据交易异常名单和关联网络中的实体间关系,得到扩展后的名单,并基于扩展后的名单的交易数据训练机器学习模型。
S230、将交易数据输入训练好的机器学习模型进行交易异常个体识别,将交易异常个体的占比达到预设阈值的社群作为交易异常群体。交易异常群体包括被训练好的机器学习模型识别出的交易异常个体和未被识别出的可疑个体。
S240、将交易异常群体中可疑个体的手机号码加入扩展后的名单,得到二次扩展后的名单。
S250、根据二次扩展后的名单再次训练训练好的机器学习模型,得到二次训练的机器学习模块,其中,该二次训练的机器学习模型用于识别交易异常个体。通过步骤S240新增对模型再次训练的标签样本,使得二次训练的机器学习模型相较于通过步骤 S220获得的训练好的机器学习模型,泛化能力得到进一步提升,可以进一步提高识别交易异常个体的准确度。二次训练的机器学习模块可以用于对交易数据进行二次交易异常个体识别,并将交易异常个体的占比达到预设阈值的社群作为交易异常群体,进一步还可以用该交易异常群体验证与通过步骤S230获得的交易异常群体是否一致。二次训练的机器学习模块也可以用于对新的交易数据进行交易异常个体识别。
在一些实施例中,关联网络包括可疑社群,可以通过训练好的机器学习模型对可疑社群进行验证。例如关联网络产生某可疑社群中有1000个成员,而训练好的机器学习模型对这1000个成员的预测结果大多数为确疑个体,则可大程度上认为该社群为确疑社群。反之亦然,通过训练好的机器学习模型预测得到的确疑个体,相应可以查看在关联网络上的划分情况如何,有哪些成员是在关联网络的可疑社群里面。通过这类交叉验证的结合方式,有助于定位可疑社群、获得确疑群体。
本申请实施例提供了一种数据处理装置。图3是根据本申请实施例的数据处理装置的结构示意图,如图3所示,该装置包括关联网络构建模块310、训练模块320和识别模块330:关联网络构建模块310用于根据交易数据构建关联网络,并基于社区发现算法对所述关联网络进行划分得到多个社群;训练模块320用于基于交易异常名单训练机器学习模型;识别模块330用于将所述交易数据输入训练好的机器学习模型进行交易异常个体识别,将交易异常个体的占比达到预设阈值的社群作为交易异常群体。
优选地,该数据处理装置还包括二次训练模块,用于将交易异常群体中可疑个体的手机号码加入扩展后的名单,得到二次扩展后的名单,并根据二次扩展后的名单再次训练训练好的机器学习模型,得到二次训练的机器学习模块。二次训练的机器学习模型用于识别交易异常个体。
关于数据处理装置的具体限定可以参见上文中对于数据处理方法的限定,在此不再赘述。上述数据处理装置中的各个模块可全部或部分通过软件、硬件及其组合来实现。上述各模块可以硬件形式内嵌于或独立于计算机设备中的处理器中,也可以以软件形式存储于计算机设备中的存储器中,以便于处理器调用执行以上各个模块对应的操作。
本申请实施例还提供了一种电子设备,包括存储器和处理器,该存储器中存储有计算机程序,该处理器被设置为运行计算机程序以执行上述任一项方法实施例中的步骤。
可选地,上述电子设备还可以包括传输设备以及输入输出设备,其中,该传输设备和上述处理器连接,该输入输出设备和上述处理器连接。
需要说明的是,本实施例中的具体示例可以参考上述实施例及可选实施方式中所描述的示例,本实施例在此不再赘述。
另外,结合上述实施例中的数据处理方法,本申请实施例可提供一种存储介质来实现。该存储介质上存储有计算机程序;该计算机程序被处理器执行时实现上述实施例中的任意一种数据处理方法。
在一个实施例中,图4是根据本申请实施例的电子设备的内部结构示意图,如图4所示,提供了一种电子设备,该电子设备可以是服务器,其内部结构图可以如图4所示。该电子设备包括通过系统总线连接的处理器、存储器、网络接口和数据库。其中,该电子设备的处理器用于提供计算和控制能力。该电子设备的存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统、计算机程序和数据库。该内存储器为非易失性存储介质中的操作系统和计算机程序的运行提供环境。该电子设备的数据库用于存储数据。该电子设备的网络接口用于与外部的终端通过网络连接通信。该计算机程序被处理器执行时以实现一种数据处理方法。
本领域技术人员可以理解,图4中示出的结构,仅仅是与本申请方案相关的部分结构的框图,并不构成对本申请方案所应用于其上的电子设备的限定,具体的电子设备可以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有不同的部件布置。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,该计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本申请所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可包括只读存储器(ROM)、可编程ROM(PROM)、电可编程ROM(EPROM)、电可擦除可编程ROM(EEPROM)或闪存。易失性存储器可包括随机存取存储器(RAM)或者外部高速缓冲存储器。作为说明而非局限,RAM以多种形式可得,诸如静态RAM (SRAM)、动态RAM(DRAM)、同步DRAM(SDRAM)、双数据率SDRAM (DDRSDRAM)、增强型SDRAM(ESDRAM)、同步链路(Synchl ink) DRAM(SLDRAM)、存储器总线(Rambus)直接RAM(RDRAM)、直接存储器总线动态RAM(DRDRAM)、以及存储器总线动态RAM(RDRAM) 等。
本领域的技术人员应该明白,以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本申请的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。因此,本申请专利的保护范围应以所附权利要求为准。
- 数据处理方法及装置、电子设备和计算机可读存储介质
- 数据处理方法和装置、计算机可读存储介质和电子设备