一种分布式文件系统算法并行执行方法
文献发布时间:2023-06-19 12:00:51
技术领域
本发明涉及大数据技术领域,尤其涉及一种分布式文件系统算法并行执行方法。
背景技术
大数据平台是对海量结构化、非结构化、半结构化数据进行采集、存储、计算、统计、分析处理的一系列技术平台。
分布式并行技术大数据领域方面的重要技术,大数据主要环节包括:数据准备、数据存储和管理、计算处理、数据分析、知识展现,在数据存储和管理中,HDFS(HadoopDistributed File System,分布式文件系统)是奠定了大数据存储技术的基础。
现代智能电网发展至今,拥有大量的电力系统数据,这些数据来自电力系统的各个生产运行环节,基础电力行业计算分析依赖很多成熟的算法,这些算法大都是可执行程序,执行潮流计算等都是很耗时的,效率低。
发明内容
本发明实施例提供一种分布式文件系统算法并行执行方法,能有并行执行可执行程序,提高可执行程序执行效率。
本发明一实施例提供一种分布式文件系统算法并行执行方法,所述方法包括:
输入可执行程序的参数数据;
加载所述可执行程序;
监控并管理所述可执行程序的生命周期;
将所述参数数据分发到不同机器;
将所述可执行程序分发到不同机器执行;
将并行处理后的所述可执行程序的结果回收,并将回收的结果输出。
作为一种优选方式,所述输入可执行程序的参数数据,具体包括:
将所述可执行程序的参数数据以单文件或文件夹的方式上传到分布式文件系统中;
以列表方式或文件方式获取参数数据的存储地址。
作为一种优选方式,所述加载所述可执行程序,具体包括:
通过上传和/或在分布式文件系统上选择的方式,加载所述可执行程序;
并通过所述可执行程序的命令行引用所述可执行程序的参数数据。
作为一种优选方式,所述监控并管理所述可执行程序的生命周期,具体包括:
监控并管理所述可执行程序的调度执行、资源管理和结果回收的流程。
优选地,所述将所述参数数据分发到不同机器,具体包括:
通过所述调度器将所述参数数据从所述分布式文件系统分发到各个机器;
在各个机器上安装执行引擎。
优选地,所述将所述可执行程序分发到不同机器执行,具体包括:
根据所述参数数据,将每一个参数数据的可执行程序作为一个任务;
根据预设的任务分发机制将任务随机分发到空余机器执行。
优选地,所述将并行处理后的所述可执行程序的结果回收,并将回收的结果输出,具体包括:
监控所述可执行程序的任务执行状态;
当所述任务执行完成时,根据预设的条件,筛选出符合条件的结果;
将筛选出的结果上传到所述分布式文件系统预设的目录中;
结果回收完毕后,将所述目录中的结果输出。
本发明提供一种分布式文件系统算法并行执行的方法,通过分析电力研究所输入多个计算算法的可执行程序的输入数据,加载的可执行程序,并对可执行程序的生命周期的进行管理,分发外部程序执行和参数数据到不同的机器执行,实现可执行程序的并行计算功能,获取并行计算的可执行程序的计算结果,并输出展示,提高了可执行程序的执行效率,并且能够便于管理和调度可执行程序的执行过程。
附图说明
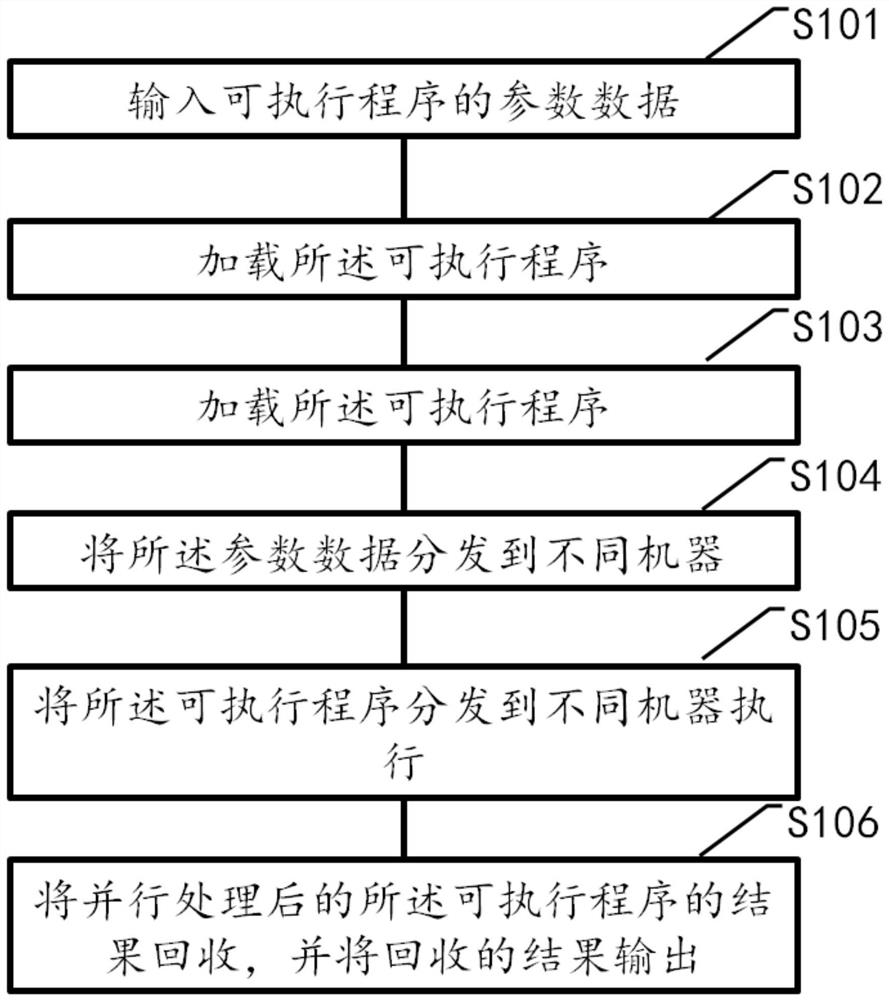
图1是本发明实施例提供的一种分布式文件系统算法并行执行方法的流程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例提供一种分布式文件系统算法并行执行方法,参见图1所示,是本发明实施例提供的一种分布式文件系统算法并行执行方法的流程示意图,所述方法包括S101~S106:
S101,输入可执行程序的参数数据;
S102,加载所述可执行程序;
S103,监控并管理所述可执行程序的生命周期;
S104,将所述参数数据分发到不同机器;
S105,将所述可执行程序分发到不同机器执行;
S106,将并行处理后的所述可执行程序的结果回收,并将回收的结果输出。
在本实施例具体实施时,通过分析电力研究所输入多个计算算法的可执行程序的输入数据,加载通用的可执行程序执行方法,通过资源分配调度器进行可执行程序的生命周期的管理,并使用资源分配调度器的外部程序执行接口进行任务的分发,实现可执行程序的并行计算功能,获取并行计算的可执行程序的计算结果,并输出展示;提高了可执行程序的执行效率,并且能够便于管理和调度可执行程序的执行过程,并行执行过程更加简便。
在本发明提供的又一实施例中,步骤S101具体包括:
将所述可执行程序的参数数据以单文件或文件夹的方式上传到分布式文件系统中;
以列表方式或文件方式获取参数数据的存储地址。
结合上述实施例,在本实施例具体实施时,输入的参数数据为可执行程序的参数数据,有两种形式,一种是单个文件,另一种是文件夹。将数据统一上传到分布式文件系统的分布式存储器中,并输出获取参数数据的地址,可通过获取列表方式或获取文件方式获取参数数据的地址。
通过将输入的参数数据存储在分布式文件系统中,并以获取列表方式或获取文件方式,获取地址方便用户并行操作。分布式文件系统作为数据存储以及中转的位置,用于数据的分发以及数据的结果收回。
在本发明提供的又一实施例中,步骤S102具体包括:
通过上传和/或在分布式文件系统上选择的方式,加载所述可执行程序;
并通过命令行引用所述可执行程序的参数数据。
结合上述实施例,在本实施例具体实施时,可执行程序的加载有两种方式,一种是在分布式文件系统上选择,另一种是直接上传可执行程序,可执行程序作为计算算法的核心,一般可执行程序的参数都是在命令行里面写的,设置引用的方式,命令行引输入的所述参数数据作为参数来使用。
通过可执行程序的命令行来引用输入的参数数据,加载可执行程序,能够将可执行程序和参数数据拆分,便于参数数据和可执行程序的传输和管理。
在本发明提供的又一实施例中,步骤S103具体包括:
监控并管理所述可执行程序的调度执行、资源管理和结果回收的流程。
结合上述实施例,在本实施例具体实施时,通过资源分配调度器对可执行程序的生命周期进行监控和管理,保证程序异常终止以及程序出错在可控范围之内,不影响其他的程序使用。使用了资源分配调度器的spark集群的执行外部程序的接口去执行可执行程序,使得可执行程序可以在集群上调度执行、资源管理、结果回收。
其中,Spark集群是一种资源分配调度器,是作为客户端向系统申请运算节点,运算节点分配后,Spark集群会分解一些计算工作,将计算工作分为不同的可执行程序,并把这些可执行程序发送到运算节点中运行。
分布式文件系统作为数据统一管理的地方,资源分配调度器作为资源和调度中心,spark集群类似程序的执行器,大大的减少了人为的干预,自动对可执行程序的整个生命周期进行管理以及调度。
在本发明提供的又一实施例中,步骤S104具体包括:
通过所述调度器将所述参数数据从所述分布式文件系统分发到各个机器;
在各个机器上安装执行引擎。
结合上述实施例,在本实施例具体实施时,输入参数数据,并加载了可执行程序后,可进行可执行程序任务的分发,spark集群是将可执行发送到集群中的多台机器上执行,可执行程序需要Wine执行引擎,因此需要在每台机器上安装Wine执行引擎,为可执行程序的执行配置执行环境。在可执行程序分发的时候,需要将数据从分布式文件系统的分布式存储器分发到各个机器,保证可执行程序在各个机器上能执行。
此外Wine执行引擎还能够在Linux系统的机器上执行Windows系统的可执行程序,wine执行引擎在Linux系统的机器上不是模拟一套windows的系统环境,而是将所有Windows的动态库都基于Linux的动态库重新编译,运用API转换技术做出Linux系统对应到Windows系统相对应的函数来调用DLL(动态链接库)以运行Windows程序,因此支持Windows系统的可执行程序的执行。
通过spark集群完成可执行程序及参数数据的分发,不需要人为干预的,减少人工参与,提高效率。
通过Wine执行引擎可实现在多台不同机器上执行可执行程序,并可实现Windows系统的可执行程序在Linux系统的执行。
在本发明提供的又一实施例中,步骤S105具体包括:
根据所述参数数据,将每一个参数数据的可执行程序作为一个任务;
根据预设的任务分发机制将任务随机分发到空余机器执行。
结合上述实施例,在本实施例具体实施时,Spark集群将可执行程序的任务分发给不同的机器并行执行的,依赖于要处理可执行程序的参数数据,spark集群会将每个参数数据的可执行程序作为一个任务,依赖自身特有的任务分发机制,将任务随机的分发到空余的机器上,这样每个机器上都会有很多任务,每个任务都会执行一个可执行程序,实现可执行程序的并行计算。
通过Spark集群,使得可执行程序可以在不同的机器上并行执行,提高了可执行程序的执行效率。
在本发明提供的又一实施例中,步骤S106具体包括:
监控所述可执行程序的任务执行状态;
当所述任务执行完成时,根据预设的条件,筛选出符合条件的结果;
将筛选出的结果上传到所述分布式文件系统预设的目录中;
结果回收完毕后,将所述目录中的结果输出。
结合上述实施例,本实施例在具体实施时,可执行程序的任务在分发到不同机器后,开始并行执行,在执行的时候,spark集群监控可执行程序的任务执行状态,当任务执行完成,根据预设的条件,判断执行结果是否符合条件,并将符合条件的结果收回,上传到分布式文件系统的目录上,并可以通过文本、表格和曲线等方式输出结果数据。
通过spark集群监控可执行程序任务的执行状态,并及时将执行完毕的结果回收,而不用等全部可执行程序的任务执行完成再上传,大大提高了结果回收的效率,就算有可执行程序的任务执行失败,也会有一部分结果被回收,不会导致执行没有结果的情况。结果回收完毕以后,所有的结果都存在于分布式文件系统中,这样就完成了整个任务的分发、并行、结果回收和结果输出的过程。
本发明提供一种分布式文件系统算法并行执行的方法,通过分析电力研究所输入多个计算算法的可执行程序的输入数据,加载通用的可执行程序执行方法,通过资源分配调度器进行可执行程序的生命周期的管理,并使用资源分配调度器的外部程序执行接口进行任务的分发,实现可执行程序的并行计算功能,获取并行计算的可执行程序的计算结果,并输出展示,提高了可执行程序的执行效率,并且能够便于管理和调度可执行程序的执行过程,并行执行过程更加简便,通过资源分配调度器能够完成可执行程序的数据分发、过程监控、数据收回和结果输出过程,使得可执行程序的并行处理流程化、易于操作;通过安装执行引擎,能够在不同的系统上运行可执行程序,提高可执行程序的机器的兼容性。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
- 一种分布式文件系统算法并行执行方法
- 一种分布式文件系统的CLI命令的执行方法及装置