一种基于代价敏感分类算法的缓存方法及系统
文献发布时间:2023-06-19 12:14:58
技术领域
本发明属于计算机存储技术领域,更具体地,涉及一种基于代价敏感分类算法的缓存方法及系统。
背景技术
随着移动互联网产业的迅猛发展,对象服务提供商正面临着存储、传输和处理海量对象带来的严峻挑战。实际应用中,最常见的传统缓存置换策略不仅难以得到高缓存命中率,还可能会出现缓存污染等问题,即缓存中包含不经常被访问的对象。
近年来,许多研究者尝试利用机器学习技术来制定缓存预取、缓存准入和淘汰等智能缓存策略。优秀的缓存策略不仅可以减少用户访问时间,还可以提高系统在海量数据传输中的性能。现有的研究者们主要采用机器学习算法(如支持向量机、随机森林、朴素贝叶斯)来实现缓存预取、准入、淘汰等智能缓存策略。
然而,现有基于机器学习算法的智能缓存策略都没有考虑错误分类在实际缓存场景中所产生的代价,因此会导致缓存命中率低,并增加网络带宽的消耗、以及用户访问的延时。
发明内容
针对现有技术的以上缺陷或改进需求,本发明提供了一种基于代价敏感分类算法的缓存方法,其目的在于,提升缓存管理策略的缓存命中率和缓存字节命中率。
为实现上述目的,按照本发明的一个方面,提供了一种基于代价敏感分类算法的缓存方法,包括以下步骤:
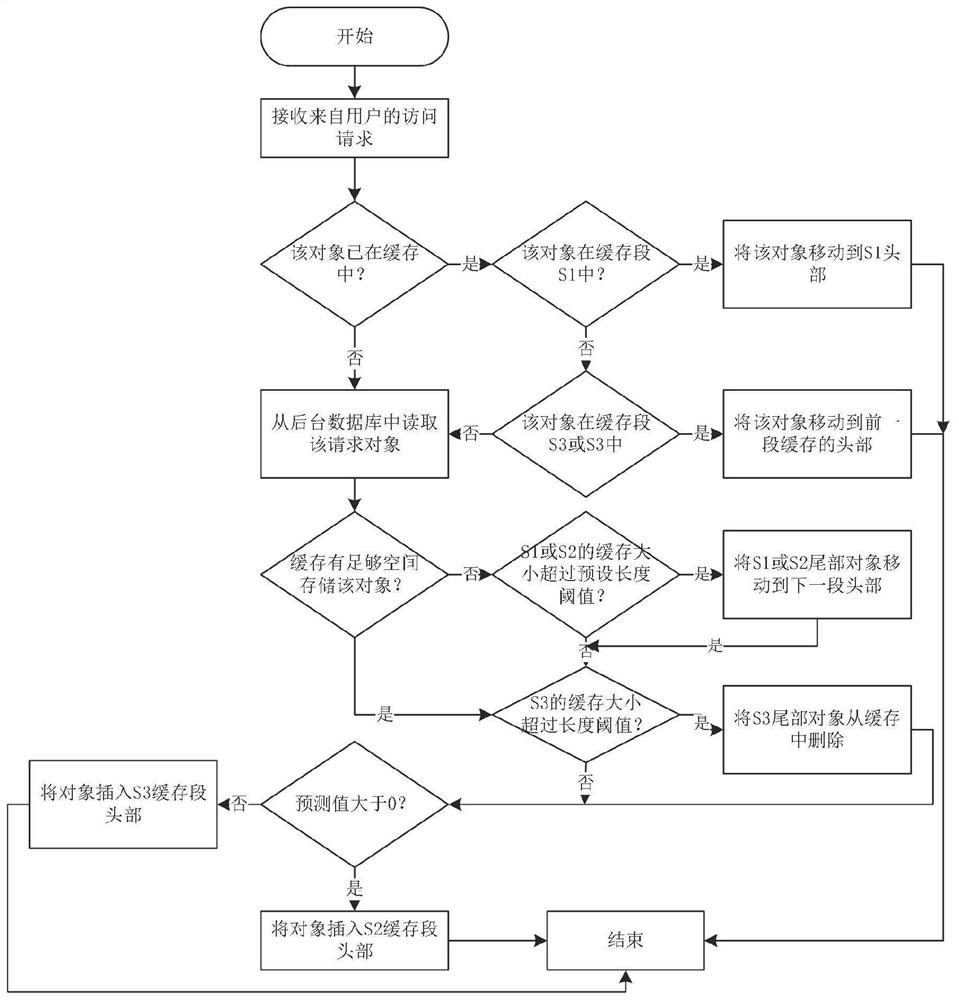
(1)接收来自用户的访问请求,并根据该访问请求判断对应的对象是否在缓存中,如果是则转入步骤(2),否则转入步骤(5);其中缓存包括三段S1、S2和S3;
(2)判断对象是否位于缓存的第一段S1中,如果是则将该对象移动到该第一段S1的头部,过程结束,否则转入步骤(3);
(3)判断对象是否位于缓存的第二段S2或者第二段S3中,如果是则将该对象移动到该段前一段的头部,过程结束,否则转入步骤(4);
(4)从后台数据库中读取该对象,并确定缓存中是否还有足够的空间存储该对象,如果是则转至步骤(6),否则进入步骤(5);
(5)判断第一段S1或第二段S2的缓存大小是否超过预设长度阈值,如果是则将第一段S1或第二段S2尾部的对象移动到下一段的头部,并进入步骤(6),否则进入步骤(6);
(6)判断第三段S3的缓存大小是否超过预设长度阈值,如果是则将第三段S3尾部的对象从缓存中删除,然后转入步骤(7),否则转入步骤(7);
(7)将步骤(1)得到的访问请求对应的对象输入训练好的SAdaCost分类模型,以得到预测值,并判断预测值是否大于0,如果是则将该对象移动到第二段S2的头部,过程结束,否则将该对象移动到第三段S3的头部,过程结束。
优选地,步骤(7)中使用的SAdaCost分类模型是通过以下步骤训练得到的:
(3-1)获取训练数据集S={(x
(3-2)将训练数据集S中的每个对象的权重D
(3-3)设置计数器t=1;
(3-4)判断t是否大于预设的迭代阈值T,如果是则进入步骤(3-10),否则进入步骤(3-5);
(3-5)将训练数据集S中每个对象的权重D
(3-6)根据步骤(3-5)得到的弱分类结果集合f
(3-7)根据步骤(3-6)得到的误差估值值ε
(3-8)根据步骤(3-6)得到的误差估值值ε
(3-9)设置t=t+1,并返回步骤(3-4);
(3-10)根据得到的T个弱分类结果集合生成最终的强分类结果F(x),将其作为训练好的SAdaCost分类模型:
优选地,步骤(6)中是采用以下公式计算误差估值值ε
优选地,步骤(3-7)中是采用以下公式计算权重更新参数α
优选地,步骤(3-8)中第t+1次迭代过程中每个对象的权重D
其中,Z
优选地,步骤(3-10)中最终的强分类结果F(x)等于:
按照本发明的另一个方面,提供了一种基于代价敏感分类算法的缓存系统,包括:
第一模块,用于接收来自用户的访问请求,并根据该访问请求判断对应的对象是否在缓存中,如果是则转入第二模块,否则转入第五模块;其中缓存包括三段S1、S2和S3;
第二模块,用于判断对象是否位于缓存的第一段S1中,如果是则将该对象移动到该第一段S1的头部,过程结束,否则转入第三模块;
第三模块,用于判断对象是否位于缓存的第二段S2或者第二段S3中,如果是则将该对象移动到该段前一段的头部,过程结束,否则转入第四模块;
第四模块,用于从后台数据库中读取该对象,并确定缓存中是否还有足够的空间存储该对象,如果是则转至第六模块,否则进入第五模块。
第五模块,用于判断第一段S1或第二段S2的缓存大小是否超过预设长度阈值,如果是则将第一段S1或第二段S2尾部的对象移动到下一段的头部,并进入第六模块,否则进入第六模块;
第六模块,用于判断第三段S3的缓存大小是否超过预设长度阈值,如果是则将第三段S3尾部的对象从缓存中删除,然后转入第七模块,否则转入第七模块;
第七模块,用于将第一模块得到的访问请求对应的对象输入训练好的SAdaCost分类模型,以得到预测值,并判断预测值是否大于0,如果是则将该对象移动到第二段S2的头部,过程结束,否则将该对象移动到第三段S3的头部,过程结束。
总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有益效果:
1.本发明采用了步骤(7),其提出了一种大小感知代价敏感的AdaBoost算法-SAdaCost,以准确地预测对象是否会被再次访问。SAdaCost在错误预测实际会被再次访问的对象为不会被再次访问,赋予较高的权重(w
2.本发明由于采用了步骤(2)到步骤(7),将SAdaCost分类器预测为会被再次访问的对象放入第二级缓存段的头部,给予对象较长的缓存驻留时间以待下次命中;将预测为不会被再次访问的对象放入第三级缓存段的头部,给予对象较短的缓存驻留时间,以便能够更快地被驱逐出缓存;因此进一步提升了缓存命中率。
附图说明
图1是本发明基于代价敏感分类算法的缓存方法的流程图;
图2是本发明与现有分类方法的缓存性能对比图,其中图2(a)是命中率的性能比较,图2(b)是字节命中率的性能比较。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
本发明的思路在于,提供一种基于代价敏感分类算法的缓存方法,其目的是为了提高缓存命中率,减少未命中,从而减少向后台存储查找所需的时间和网络带宽等。随着大数据时代的来临,数据访问模式千变万化,传统的缓存置换策略容易造成缓存污染等问题,智能缓存策略从历史信息中学习,预测对象将来是否会被再次访问,从而根据预测结果做出不同决策。
如图1所示,本发明基于代价敏感分类算法的缓存方法包括以下步骤:
(1)接收来自用户的访问请求,并根据该访问请求判断对应的对象是否在缓存中,如果是则转入步骤(2),否则转入步骤(5);其中缓存被均匀分为三段S1、S2和S3;
(2)判断对象是否位于缓存的第一段S1中,如果是则将该对象移动到该第一段S1的头部,过程结束,否则转入步骤(3);
(3)判断对象是否位于缓存的第二段S2或者第二段S3中,如果是则将该对象移动到该段前一段的头部,过程结束,否则转入步骤(4);
(4)从后台数据库中读取该对象,并确定缓存中是否还有足够的空间存储该对象,如果是则转至步骤(6),否则进入步骤(5);
(5)判断第一段S1或第二段S2的缓存大小是否超过预设长度阈值,如果是则将第一段S1或第二段S2尾部的对象移动到下一段的头部,并进入步骤(6),否则进入步骤(6);
具体而言,预设长度阈值的大小等于当前时刻前一天所接收到的所有访问请求对应的所有对象大小和的1/30。
(6)判断第三段S3的缓存大小是否超过预设长度阈值,如果是则将第三段S3尾部的对象从缓存中删除,然后转入步骤(7),否则转入步骤(7);
具体而言,预设长度阈值的大小等于当前时刻前一天所接收到的所有访问请求对应的所有对象大小和的1/30。
(7)将步骤(1)得到的访问请求对应的对象输入训练好的SAdaCost分类模型,以得到预测值,并判断预测值是否大于0,如果是则将该对象移动到第二段S2的头部,过程结束,否则将该对象移动到第三段S3的头部,过程结束。
具体而言,步骤(7)中使用的SAdaCost分类模型是通过以下步骤训练得到的:
(3-1)获取训练数据集S={(x
(3-2)将训练数据集S中的每个对象的权重D
D
(3-3)设置计数器t=1;
(3-4)判断t是否大于预设的迭代阈值T,如果是则进入步骤(3-10),否则进入步骤(3-5);
在本步骤中,迭代阈值T的取值是100到1000,优选为100。
(3-5)将训练数据集S中每个对象的权重D
(3-6)根据步骤(3-5)得到的弱分类结果集合f
(3-7)根据步骤(3-6)得到的误差估值值ε
(3-8)根据步骤(3-6)得到的误差估值值ε
其中,Z
β(i)指对象被错误分类(即y
(3-9)设置t=t+1,并返回步骤(3-4);
(3-10)根据得到的T个弱分类结果集合生成最终的强分类结果F(x),将其作为训练好的SAdaCost分类模型:
本步骤的优点在于,当更新误分类对象权重时SAdaCost算法增加了代价参数β(i),SAdaCost在错误预测实际会被再次访问的对象为不会被再次访问,赋予较高的权重(w
从系统工作流程可以看出,相较于传统的缓存工作流程,本发明増加了对对象是否可以进入缓存进行分类预测,从而将预测为会被再次访问的对象放入第二级缓存段的头部,给予对象较长的缓存驻留时间以待下次命中;将预测为不会被再次访问的对象放入第三级缓存段的头部,给予对象较短的缓存驻留时间,以便能够更快地被驱逐出缓存。此外,缓存分类预测器是基于离线的分类策略,虽然在精度上略有损失,并不能完全分类正确,但可以在不增加缓存请求时间的情况下增大缓存利用率。
实验结果
本发明实验环境:CPU为Intel(R)Core(TM)i5-8265U CPU@1.80GHz,内存为8GB,硬盘容量为4TB,网卡选择百兆网卡,在Win10操作系统下,主要采用Python语言来进行仿真,分类算法的训练过程使用了Sklearn包,具体的参数设置如下:w
为了说明本发明所提出的大小感知代价敏感的AdaBoost算法—SAdaCost的优越性,本发明在腾讯QQ相册数据集上做了相关的测试,选择了C4.5、朴素贝叶斯(NaiveBayes)、K最近邻(K-Nearest Neighbors)、逻辑回归(Logistic Regression)、随机森林(Random Forest)、装袋(Bagging)和AdaBoost这七种主流分类算法与本文算法进行比较,记录下了缓存命中率和缓存字节命中率。
由图2的对比结果可知,本发明能够获得更高的缓存命中率和缓存字节命中率。在0.1X缓存大小时,相比于NB-S3LRU,本发明的缓存命中率提高了7.89%,字节命中率提升了8.82%;相比于LogR本发明的缓存命中率提升了6.90%,字节命中率提升了7.70%;相比于AdaBoost,本发明的缓存命中率提升了1.36%,字节命中率提升了1.49%。上述结果表明本发明提出的SAdaCost代价敏感分类算法在提高缓存性能方面起到了至关重要的作用,进一步说明了本发明提出的SAdaCost分类算法具有很好的分类预测效果。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 一种基于代价敏感分类算法的缓存方法及系统
- 一种基于分类算法的角度识别方法及系统