一种大数据高并发下人群画像存储及定向系统及方法
文献发布时间:2023-06-19 12:19:35
技术领域
本发明涉及一种大数据高并发下人群画像存储及定向系统及方法。
背景技术
随着网络技术的发展及智能终端的快速普及,移动互联网及传统互联网给大数据精准营销公司带来了新的机遇,同时也带来了新的挑战。
在大数据精准营销公司中,互联网广告平台DSP(需求方平台)是一个在线实时广告平台,它拥有两个核心特点,一是大量数据下非常快的数据运算速度和技术,二是高并发下先进的用户定向技术能力。
互联网广告平台对数据运算技术和速度、用户定向技术都要求极其苛刻。媒体卖方平台向DSP发竞价请求,到DSP的竞价响应,整个时间不得超过120毫秒。在这段时间内dsp平台还需要对几十乃至于上百个订单的每个订单进行地域判断,平台判断,频控次数判断,价格判断,尺寸判断,广告类型判断,点击数判断,曝光数判断,黑白名单判断,展示类型判断等等,还要对用户进行性别、职业、年龄、收入、兴趣爱好等等进行判断。实现用户定向投放。在几十万QPS的DSP平台上,实现对60亿左右的人群画像数据进行精准投放,这样的高并发下大量数据精准定向这对系统的架构带来极大的挑战。
用户定向是指对用户进行性别、职业、年龄、收入、兴趣爱好等等属性进行判断,选择出合适的用户。例如:某个奶粉的广告主希望看到广告的用户是女性、年龄在20-45之间的,月收入5000以上等等要求的人看到,DSP平台会根据这些要求定向投放。本公司的人群画像数据分6类45种左右状态,一条数据大约是200个byte左右,60亿左右的数据大小为12T左右,这些数据需要全部放在内存中,对于key value的缓存大约需要16T左右的内存,像redis还需要准备2倍以上的空间,大约需要32T以上。对内存的占用及系统的维护都是公司难以承受的。
人群画像的存储和定向系统需要满足以下要求:第一,毫秒级的读写及精确定向。第二,实时的在线增量添加及更新及数据的可持久化。第三,间隔时日,实时的在线无痕动态全量更新,更新中不对竞价系统有任何影响。第四,高并发下的稳定性,健壮性及运维的简单易用性。毫秒级的读写和可持久化,决定了必须用可持久化的分布式缓存,但现在常用的可持久化的分布式缓存redis面临着一系列的问题。首先,当数据量比较大时,持久化会占大量的CPU和内存资源,出现服务暂停现象。其次,全量更新时,主从进行全量同步,内存占用是Redis存储量的一倍以上。更可怕的是,大量数据的全量同步,会使主服务器占大量的CPU和内存资源造成说服务会中断,服务器无法响应请求。再次,redis是单线程的,单台服务器无法充分利用多核服务器的CPU。内存利用也很不经济。最后,是redis在全量更新删除操作的时候,也需要手动删除,同时还要做主从同步,造成系统中断服务。同时只能做物理删除,无法保留历史数据。
发明内容
本发明的目的在于提供一种大数据高并发下人群画像存储及定向系统及方法,旨在通过将基于文件的共享内存、分组、分片、bit位映射压缩人群画像,hash映射和链表结合的存储、bit位映射数据快速用户定向,远程调用(RPC)等功能有机的结合在一起,形成了一套完善的技术方案。
为实现上述的发明目的,本发明的技术方案如下:
首先,计算所需要的缓存大小进行分块,每个分块建立一个基于文件的共享内存,生成自定义缓存。同服务器的不同的进程开启远程调用(RPC)功能并共享该共享内存。共享内存中的数据有操作系统控制刷新文件到磁盘上。该服务器有多个读进程和一个写进程,进程间的数据通过共享内存映射。
其次,将缓存机器按组分配,每组2-3台机器。同组的机器数据一致,不同组的机器器数据不同。同组的每个服务器多进程间实现读写分离。不同组服务器的分片有客户端控制。
再次,同组服务器间的同步,不同组服务器的数据的实时的在线增量添加及更新,都通过分布式消息系统完成。为每台缓存服务器启动一个消息处理进程,保证其更新的速度。消息处理系统按规则实现不同组服务器数据的分片。当消息处理进程出故障时,标记该对应服务器不可读,并发送消息到监控系统。
再次,将人群画像数据进行bit位映射,本公司的人群画像共用6大类45种左右的状态,映射为45个bit,每个bit表示一个状态。例如从右向左第一位表示性别,1表示男性,0表示女性。第二到第六位表示年龄,第二位表示0-20岁年龄段的人,第三位表示20-35岁年龄段的人,第四位表示35-50岁年龄段的人,第五位表示50-65岁年龄段的人,第六位表示65岁以上年龄段的人。
再次,通过hash函数将用户标识ID生成32位的hash值,通过该hash值决定分块信息及在分块信息上的存储地址,即链表的头。地址上存储数据格式为:用户标识ID的64位哈希值#人群画像的映射值#用的是那个哈希函数#链表下一个数据的存储地址#链表下一个数据所在的分块。其类型都是整型,分别占用的字节为:8#6#1#4#1,共20个字节。这样每条人群画像数据压缩到20个byte.60亿左右的数据,对于key/value的内存占有大约160G左右。计算一些其他的内存开销大约占有200G左右内存,相比32T来说,大大节约了内存空间。
再次,当用户定向计算的时候,先查询人群画像布隆过滤器,该用户如果存在,则获取广告主对定向的要求,生成订单的bit位映射值及校验值。(本公司的人群画像共用6大类45种左右的状态,6种大类间是并且关系,大类中的状态是或者关系,例如:广告主要求:性别男并且年龄20-35或者35-50之间并且爱好跑步或者打球的人,其中性别、年龄、爱好是属于大类。校验值就是大类的bit位映射。)将订单的bit位映射值与用户的的bit位映射值进行位与操作,计算位与操作结果值的校验值,如果和订单的校验值相等,则该用户符合订单要求
最后,自定义缓存系统会定时检查是否要全量更新,当需要全量更新时,自定义缓存系统会加载其中的一个新的分块的内存共享文件(该内存共享文件是其他的机器生成好上传到该服务器上的),开辟共享内存空间,将共享内存映射到自定义缓存中替换旧的映射。然后释放本分块的旧的共享内存,将旧的共享内存文件保存在磁盘上,并不删除,然后循环操作,直到加载完所有的分块。
其大体流程为:自定义缓存系统启动时,会检查配置文件加载分块的内存共享文件,如果没有该分块的内存共享文件,则创建该文件并开辟共享内存,对共享内存初始化。如果有该分块的文件,则判断该文件的共享内存是否存在,存在就继续下一个,不存在则开辟共享内存,对共享内存初始化并把文件的内容加载到共享内存中,并将共享内存映射到自定义缓存中。并定时检查是否要全量更新,如果是全量更新,则加载其中的一个新的分块的内存共享文件,开辟共享内存空间,将共享内存映射到自定义缓存中替换旧的映射。然后释放本分块的旧的共享内存,然后循环操作,直到加载完所有的分块。自定义缓存启动完毕后,消息处理系统启动,读取消息,数据进行分片处理,将属于该机的数据,通过hash函数将用户ID生产的hash值计算出分块信息及在分块信息上的存储地址,即链表的头。判断该链表头是否有数据存在,如不存在,则存入。如果存在,判断链表下一个数据的存储地址是否存在,如果存在,则继续取下一个,直到不存在,即链表的尾。如果不存在,则将人群画像数据存入新的地址,将该数据的地址及分块信息更新到链表尾部的数据中。竞价系统进行用户定向的时候,先调用定向功能模块,定向模块先查询人群画像布隆过滤器,询问用户人群画像是否存在,如果存在则将数据进行分片计算,确定是访问那组缓存服务器,然后再计算访问那台服务器,检查这台服务器是否可查,如果可查,则连接该缓存服务器的某个读进程,读进程根据用户ID生产的hash值计算出分块信息及在分块信息上的存储地址,即链表的头,读进程遍历链表判断用户ID并取出人群画像的映射值,返回给定向功能模块,定向功能模块将订单的需求用户定向的映射值与人群画像的映射值做位与操作,并生成校验值。将订单的用户定向校验值与生成的校验值比较,相等则符合要求,否则不符合。定向功能模块将结果返回给竞价系统,竞价系统判断符合的订单,返回给媒体服务器。
本发明的优点和有益效果在于:本发明所提供的大数据高并发下人群画像的存储及定向系统,通过基于文件的共享内存的自定义缓存、分组,分片,分块、bit位映射压缩人群画像,hash映射和链表结合的存储、bit位映射数据快速用户定向等功能的结合实现,不仅能完成人群画像存储所需的分布式缓存的功能,还实现了毫秒级的存取及精确定向功能。通过用户定向功能模块的bit位映射数值的位与操作及位校验值的比较,解决了用户定向中多个并且和并且之间或者的复杂性,实现了用户定向的快速及准确性。通过人群画像数据的bit位映射压缩、用户标识ID转化为64位hash值存储,使内存的应用大大减少,降低了使用成本,减少了服务器的数量,使得运维更加方便,具有更强的健壮性。通过灵活的内存共享文件的分块,使的全量更新与系统无缝结合,实现了实时在线动态更新,更新对系统完全没有影响。并且占用更小的资源,更灵活的加载和释放内存空间。使得系统更加经济、简单、灵活、易用。利用本发明,可以将人群画像分布式缓存存储独立应用,特别是对于大数据下资源库的key/value可持续化缓存存储。通过将字符串的key转化为64位hash值,大大节约了内存空间,有的value也可以采用本发明的bit位映射方法,能够解决高并发大数据下的很多难解的问题。
附图说明
图1为大数据高并发下人群画像存储及定向系统的示意图。
图2为大数据高并发下人群画像的存储及定向系统在整个DSP平台中的架构示意图。
图3为大数据高并发下人群画像的存储及定向系统的自定义缓存系统流程图。
图4为大数据高并发下人群画像的存储及定向系统的压缩写流程图。
图5为大数据高并发下人群画像的存储及定向系统的读取流程图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
实施例:
如图1所示,大数据高并发下人群画像存储及定向系统,人群画像存储及定向系统的输出端连接DSP竞价服务器,输入端分别连接DSP竞价服务器、分布式消息系统服务器和DMP服务器,所述人群画像存储及定向系统包括人群画像缓存系统、读取系统、压缩写系统以及消息处理管理系统。
大数据高并发下人群画像存储及定向的方法,通过将人群画像数据分片、分块的计算形成的分块标识,加载或者创建共享内存文件,创建基于文件的共享内存,并生成自定义缓存,将共享内存映射到缓存中。自定义缓存启动定时器自动管理,定时分块检查更新状态,如果更新状态是全量更新,则加载该分块标识对应的共享内存文件,开辟共享内存空间,将数据加载到共享内存中,则将新分块共享内存映射更新到自定义缓存中,释放对应老分块的共享内存;如果不是,则检查该分块的共享内存映射是否存在,如果不存在则加载该分块标识对应的共享内存文件,开辟共享内存空间,将数据加载到共享内存中,将共享内存映射到自定义缓存中;如果存在,则进行下一个;循环检查,直到检查到最后一个分块为止;增量的添加及更新通过消息处理系统完成,消息处理系统管理多个压缩写进程,将写进程出现异常时,将该进程对应的机器设置为不可读。当数据添加及更新时,压缩写进程数据进行分片处理,然后用hash函数将用户标识ID生成32位的hash值,通过该hash值获取该缓存地址中的链表数据。先用第一个hash函数将用户标识ID生成64位的hash值,然后与链表中人群画像数据的每一个64位hash值进行比较,如果有相等的,则用下一个hash函数生成hash值,再比较。如果没有相等的,则再比较所用的hash函数的序列号,是否小于链表中所用hash函数的最大的序列号,如果小于最大的序列号,则再取用下一个hash函数生成hash值,再进行比较,直到完全没有相等为止(确保每一个用户标识hash值的唯一性)。当所有都没有相等的时候,取人群画像数据,将数据与bit位一一映射,然后将64位用户标识ID的函数值和人群画像的映射值及用的hash函数的序列号按规则生成数据,存入链表的尾部,写入缓存中。并将共享内存中更新的数据刷新到硬盘上的该共享内存对应的文件中。竞价系统进行用户定向的时候,先通过用户标识ID调用定向功能模块,定向功能模块查询人群画像布隆过滤器,询问该用户标识ID是否用入群画像,如果有,则定向功能模块计算分片分组信息,确定访问那组缓存服务器的那台服务器可读,连接该缓存服务器的某个读进程,根据分组标识,从自定义缓存中取出对应的共享内存映射。然后用hash函数将用户标识ID生成32位的hash值,通过该hash值获取该缓存地址中的链表数据。遍历链表数据,取出每个数据的hash函数值及其序列号,用该序列号的hash函数将用户标识ID生成64位的hash函数值,并与该hash函数值进行比较。如果相等,则判断链表头的碰撞标志,如果没有碰撞,则直接返回该人群画像映射值。如果有碰撞,则将该人群画像数据保存在结果数组中,接着比较下一个数据,直到遍历完链表中所有的数据为止。然后检查结果数组,如果多于1个,取hash函数序列号最大的那个数据的人群画像映射值,然后将结果返回给定向功能模块,定向功能模块将人群画像的映射值临时保存并与订单要求的人群画像的映射值做位与操作,将位与操作的结果值进行校验值计算,然后将该校验值和订单要求的定向值比较,符合则返给竞价系统。并依据上述方法发明一种大数据高并发下人群画像存储及定向的系统,通过基于共享内存文件的自定义缓存,实现了人群画像数据的分块,并通过对分块的加载和卸载,实现了全量更新的无缝连续,不仅大大减少了对机器资源的占用,还完全避免了全量更新对系统的影响。通过消息处理模块对增量添加和更新管理,实现了在线添加和更新及时性和准确性。通过压缩写,将人群画像数据进行bit位映射,用户标识ID进行hash值存储。大大减小了内存的占用,不仅节约了大量的服务器,减少了成本,还减轻了运维的复杂性,提高了查询的效率及速度。通过定向功能模块,实现了订单的定向需求和人群画像数据映射值的位操作,引入校验值,不仅能实现精准的判断还大大加快的定向的速度,使得用户定向更快速更精准。整个系统解决了现有分布式缓存的缺点和不足及人群画像存储及定向的难点,非常适用于大数据并且高并发的环境。完全满足人群画像存储及定向的需求。
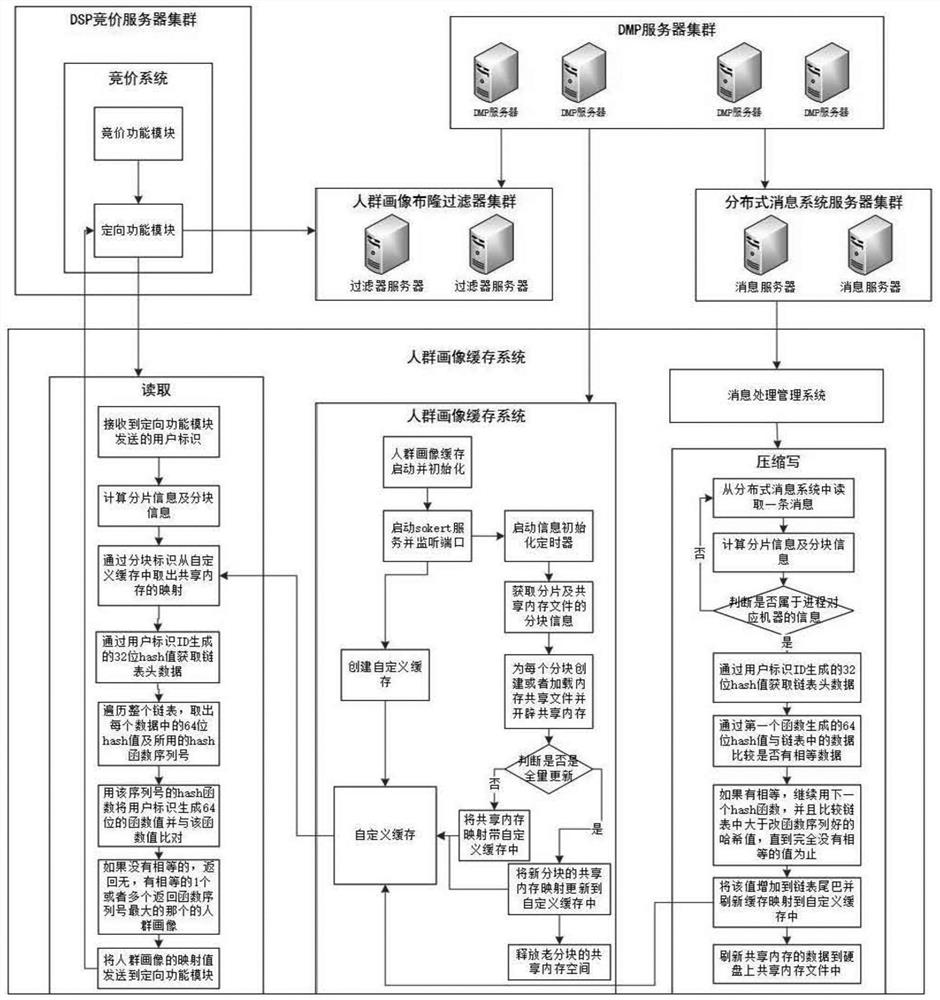
如图2所示,系统分为DSP竞价服务器集群,日志处理服务器集群,人群画像的DMP(数据管理平台)服务器集群,分布式消息系统集群,人群画像的存储系统集群等几个部分。DSP竞价服务器调用定向功能模块向人群画像的存储及定向系统服务器发送信息,询问该用户的人群画像数据信息,人群画像的存储及定向系统服务器通过相应的算法返回该用户的人群画像数据信息,定向功能模块经过一系列判断,返回符合定向要求的订单给竞价服务器,竞价服务器再经过一系列判断,返回符合要求的订单的广告素材和竞价价格等给媒体服务器。dsp竞价服务器将接收到的竞价请求信息发送到日志处理服务器日志处理服务器将信息格式化,发送到DMP(数据管理平台)服务器,DMP服务器结合其他的数据来源进行一系列的处理,将生产的新人群画像数据或者更新的数据发送到分布式消息系统服务器,并添加或者更新自己的人群画像数据库。人群画像的存储系统服务器的消息处理系统处理人群画像数据,将处理后的数据,写入自定义缓存中。DMP服务器定期生成全量人群画像分块的内存共享文件,发送到人群画像的存储及定向系统服务器。人群画像的存储及定向系统服务器启动加载或者定期更新。
如图3所示,人群画像的存储及定向的自定义缓存系统实现原理
1、系统启动时,自定义缓存系统初始化,启动socketserver,监听端口。
2、启动信息初始化定时器线程,定时器每10分钟执行一次。
3、判断初始化信息是否更新,如果没有更新,则不做任何操作,等待下次任务执行。
4、如果有更新,则开始初始化,并获取初始化信息。
5、如果获取失败,则判断重新获取信息的次数,如果小于3次,则等待10秒钟,小于10次大约3次,则等待5分钟,再重新获取信息。如果大于10次,则退出信息获取,发送消息到监控系统,信息初始化退出,等待下次任务执行。
6、如果获取成功,则判断自定义缓存是否存在,不存在,则创建缓存。
7、如果缓存存在,则获取机器的分组信息及共享内存文件信息。
8、取一个分块信息标识,并为分块信息标识初始化信息。
9、判断自定义缓存中是否已经存在共享缓存映射,如果存在,则继续去下一个。
10、如果不存在,初始化共享内存信息。
11、判断是否存在共享内存文件,如果不存在,生成共享内存文件,保存在磁盘上,开辟共享内存空间。
12、如果存在,则判断是否开辟了共享内存空间,如果开辟了,则映射共享内存到自定义缓存中,循环8至11的步骤
13、如果没有开辟,则开辟共享内存空间。加载内存文件的内容到共享内存中。
14、检查自定义分块的更新标记,是否是全量更新。
15、如果是全量更新,则将新分块共享内存映射更新到自定义缓存中,释放对应老分块的共享内存。
16、否则,将分块的共享内存映射更新到自定义缓存中。
17、则循环8至16的步骤,直到所有的订单都处理完成。
18、信息更新初始化结束,等待下次任务执行。
19、下次任务执行循环3至18的步骤。
如图4所示,人群画像的存储及定向的bit位映射压缩实现原理
1、当DMP有新增或者更新的人群画像数据信息时,将格式化的人群画像数据信息发送到分布式消息系统服务器。
2、人群画像的存储及定向系统压缩写进程从分布式消息系统中读取一条信息并解析该数据。
3、通过解析数据中的用户标识ID,计算出分组的机器信息及分块信息。
4、通过分块标识,获取该标识在自定义缓存中的共享内存映射。
5、判断自定义缓存中是否存在共享内存映射,如果不存在,则发送信息到监测系统,并结束此次处理,从分布式消息系统中取出下一条信息进行处理。
6、如果存在,则将用户标识ID通过hash函数生成32位hash值。
7、将该hash值与块的最大存储数取余,计算出该hash值在缓存中的位置并从缓存中取出人群画像数据(20个byte)在缓存中的位置。即链表头(用户标识ID的64位哈希值#人群画像的映射值#用的是那个哈希函数#链表下一个数据的存储地址#链表下一个数据所在的分块,字节数8#6#1#4#1共20个)。
8、从这20个byte中取出第15个byte,即“用的是那个哈希函数”标记,哈希函数的序列号。(在链表头数据中该标记表示三种情况,当为0时,表示链表头没有存储人群画像数据,当为1时表示链表头有存储数据并且链表中的64位hash值没有碰撞,当为2时,表示链表头有存储数据并且链表中的64位hash值有碰撞。)
9、计算第15个byte的十进制数组值。
10、判断第15个byte的值是否大于0。如果等于0,则,用第一个64位hash函数将标识ID生成hash存入该20个byte的1-8byte中。
11、取出人群画像的6类45种状态,对应于9-14个byte的后45个bit位1代表有,0表示无,存入该20个byte的9-14byte中。
12、将第15个byte设置为十进制1,将16-20位byte设置为0。
13、将拼接好的20位byte更新到该地址中,及链表头中。
14、如果第15个byte的值是大于0,取第1-8个byte及第15个byte并计算出各自的十进制数值放入数组中(即用户标识ID的64位函数值和所用的hash函数的序列号)。
15、取第16-19个byte并计算出十进制数值(链表的指针/下一个值的位置),并判断是否大于0。
16、如果大于0,则循环14-15步骤,直到链表结束。
17、如果小于0,说明到了链表尾部,则将链表尾数据及尾数据的地址位置及最大的hash函数的序列号保存下来。
18、取第一个64位hash函数将标识ID生成64位long型hash值,并与保存在数组中的所有64位hash函数值比较。
19、判断是否有相等的数值,如果有,则设置有hash碰撞标记为true,在取该hash函数的下一个64位hash函数将标识ID生成64位long型hash值。
20、循环18至19的步骤,直到没有相等的数值为止。
21、如果没有,则将该hash函数的序列号与链表中的最大hash函数的序列号进行比较,判断该hash函数的序列号是否大于或者等于链表中的最大hash函数的序列号。
22、如果是,则转到27步骤.
23、如果否,则取数组中hash函数序列号大于该hash函数的序列号的所有hash函数值及序列号,存入一临时数组中。
24、遍历该临时数组中,将数组中每一个hash函数值,与用该值对应的hash函数将用户标识ID生成的hash函数值进行比较。判断是否有相等的。
25、如果有相等的,则循环18至24的步骤,直到没有相等的数值为止(确保存入的用户标识hash值的唯一性)。
26、如果不相等,则继续下一步骤。
27、判断碰撞标志是否为true,如果是,则将将链表头个数据的第15个byte设置为十进制2,继续29步骤。
28、如果否,继续下一步骤。
29、用该64位hash函数将标识ID生成hash值存入新的20个byte的1-8byte中。
30、取出人群画像的6类45种状态,对应于9-14个byte的后45个bit位1代表有,0表示无,存入该20个byte的9-14byte中。
31、将第15个byte设置为十进制1,将16-20位byte设置为0。
32、将拼接好的20位byte的人群画像数据存入新的地址中。
33、更新链表尾数据将新地址数据放入16-19位byte,将分块数据放入第20位byte。
34、判断写入是否都成功,如果是,则返回添加成功。
35、如果否,则返回添加失败。
36、结束此次处理,从分布式消息系统中取出下一条信息进行处理,然后循环2至28的步骤。
如图5所示,人群画像的存储及定向的读取实现原理
1、当DSP竞价服务器的竞价系统进行用户定向时。
2、竞价系统取出一个订单的定向信息。
3、DSP竞价服务器通过订单定向信息调用定向功能模块。
4、定向功能模块判断是否有临时保存的用户标识ID对应的人群画像映射数值。
5、如果有,则定向功能模块解析人群画像映射数值。
6、定向功能模块获取订单定向要求的人群画像数值及校验数值。
7、用户标识ID对应的人群画像映射数值与订单定向要求的人群画像数值进行位与操作。
8、将位与操作后的结果计算出校验值。
9、与订单定向要求的人群画像的校验数值进行比较。
10、判断是否相等,相等则返回结果给竞价系统。
11、如果不相等,则竞价系统判断是否有下一个订单。
12、如果有,则循环2至11的步骤,直到所有的订单检查结束。
13、如果没有,则订单检查结束,定向功能模块删除临时保存的用户标识ID对应的人群画像映射数值,返回无符合要求给竞价系统。
14、如果没有临时保存的用户标识ID对应的人群画像映射数值,则定向功能模块询问人群画像过滤器,该用户是否存在人群画像。
15、如果不存在,则告知定向功能模块,返回无人群画像给竞价系统。
16、如果存在,则定向功能模块向人群画像缓存系统发送用户标识ID等信息。
17、人群画像缓存系统通过用户标识ID,计算出分组的机器信息及分块信息。
18、通过分块标识,获取该标识在自定义缓存中的共享内存映射。
19、判断自定义缓存中是否存在共享内存映射,如果不存在,则发送信息到监测系统,并返回该用户的人群画像不存在给定向功能模块,定向功能模块返回无人群画像给竞价系统。
20、如果存在,则将用户标识ID通过hash函数生成32位hash值。
21、将该hash值与块的最大存储数取余,计算出该hash值在缓存中的位置并从缓存中取出人群画像数据(20个byte)在缓存中的位置。即链表头。
22、从这20个byte中取出第15个byte,即哈希函数的序列号。(在链表头数据中该标记表示三种情况,当为0时,表示链表头没有存储人群画像数据,当为1时表示链表头有存储数据并且链表中的64位hash值没有碰撞,当为2时,表示链表头有存储数据并且链表中的64位hash值有碰撞。)
23、计算第15个byte的十进制数值。
24、判断该值是否大于1。如果不大于1等于0,则,返回该用户的人群画像不存在给定向功能模块,定向功能模块返回无人群画像给竞价系统。
25、如果等于1,则判断第16-19个byte值是否大于0,
26、如果不大于0,则用第一个64位hash函数将标识ID生成hash,并与取出的第1-8个byte的值进行比较。
26、如果不相等,则,返回该用户的人群画像不存在给定向功能模块,定向功能模块返回无人群画像给竞价系统。
27、如果相等,取出该数据对应于9-14个byte并计算出十进制数值,返回用户人群画像数值给定向功能模块,定向功能模块临时保存的用户标识ID对应的人群画像映射数值,继续第5步骤。
28、如果第16-19个byte值大于0,则,继续第30步骤。
29、第15个byte的十进制数值大于1,设置是否有hash碰撞标记为true。
30、取第16-19个byte并计算出十进制数值(链表的指针/链表下一个值的地址)。
31、取第1-8个byte并计算出十进制数值(64位的long型hash值)。
32、取出该数据的第15个byte并计算出十进制数组(用的那个hash函数)。
33、用该64位hash函数将标识ID生成hash值,并比较两个hash值是否相等。
34、如果比较两个hash值不相等,判断链表下一个值的地址是否大于0。
35、如果大于0,则循环30至34步骤,直到链表最后一个。
36、如果等于0,说明到了链表的尾部,则判断结果数组的长度是否大于0
37、如果不大于0,则返回该用户的人群画像不存在给定向功能模块,定向功能模块返回无人群画像给竞价系统。
38、如果大于0,则判断数组的长度是否大于1
39、如果大于1,则取出数组中的所用hash函数序列最大的人群画像数据,并判断数组的长度是否大于2,如果是,发送信息到监控系统,做内存调整。转到41步骤
40、如果等于1,则取出数组中的人群画像数据。
41、取出该数据对应于9-14个byte并计算出十进制数值,返回用户人群画像数值给定向功能模块,定向功能模块临时保存的用户标识ID对应的人群画像映射数值,继续第5步骤。
42、如果比较两个hash值相等,判断Hash碰撞标志是否为true
43、如果为true,则将人群画像数据存入结果数组中循环34至41步骤。
44、如果不为true,取出该数据对应于9-14个byte并计算出十进制数值,返回用户人群画像数值给定向功能模块,定向功能模块临时保存的用户标识ID对应的人群画像映射数值,继续第5步骤。
本系统通过将基于基于文件的共享内存的自定义缓存系统,消息处理管理系统,基于人群画像数据进行bit位映射,用户标识ID转化为64位hash值进行存储,多hash函数,循环比对,避免碰撞的压缩写,基于位操作及校验值的定向功能模块的读进程的结合,形成了一套完善的人群画像的存储及定向系统。本系统具有很强的健壮性,先进性,通用性,很好的可维护性,易用性。利用本系统,不仅能满足竞价系统定向功能及人群画像缓存存储的要求,还可以将人群画像分布式缓存存储独立应用,特别是对于大数据高并发下资源库的key/value可持续化缓存存储。通过将字符串的key转化为64位hash值,大大节约了内存空间,有的value也可以采用本发明的bit位映射方法,不仅能够解决高并发大数据下的很多难解的问题,还可以大大提高单机CPU和内存的利用率,实现全量更新的动态的内存的加载和释放,增加系统应用的灵活性,更有效的压缩和利用内存空间。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 一种大数据高并发下人群画像存储及定向系统及方法
- 一种基于大数据分析的人群画像提取方法及装置