一种基于自监督的三阶段故事阅读理解训练方法
文献发布时间:2023-06-19 12:22:51
技术领域
本发明涉及一种基于自监督的三阶段故事阅读理解训练方法,属于深度学习中的自然语言处理领域。
背景技术
近年来,自然语言处理(NLP)引起了人们的长期关注并广泛应用于各个领域。故事阅读理解作为自然语言处理的一项热门任务,也吸引了不少学者的目光。故事完形测试(SCT)挑战由Mostafazadeh等人首次提出,该挑战提供了标记的验证集和测试集作为评估故事阅读理解系统的基准。同时,他们提供了无监督的ROCStories日常故事语料作为辅助。
故事完形测试任务需要一个故事理解模型来从给定故事上下文的两个候选结尾中选择正确的结尾,而ROCStories是完整的五句话常识故事。其中,SCT和ROCStories之间存在较高的词重叠,如果机器事先看过这些词所出现的情景,对SCT任务中推断正确结尾很有帮助。
目前,完成故事完形测试有很多方法,既包括传统的机器学习方法,又可以使用神经网络模型。一些作品还利用诸如情感、主题词和事件框架之类的信息。在2018年以后,Radford等人提出GPT(Generative Pre-Training)来利用大型未标记的开放域语料库,例如BooksCorpus数据集,给故事阅读理解任务带来了革新。Chen等人基于GPT,提出ISCK模型,融合了三种类型的外部信息,包括叙事顺序、情感演变和结构化的常识知识来预测故事的结局。除此之外,Google Brain在2018年提出的自编码语言模型框架——BERT在该任务上也有很好的效果,它与GPT非常的相似,都是基于Transformer的二阶段训练模型,都在预训练阶段无监督地训练出一个可通用的Transformer模型,然后在微调阶段对这个模型中的参数进行微调,使之能够适应不同的下游任务。与GPT不同的是,BERT在预训练阶段采用的是mask语言模型损失函数。
然而,当前的方法都缺乏SCT的领域相关的知识。与用于预训练BERT的BooksCorpus相比,ROCStories是SCT的大规模、同领域的无监督知识来源。SCT和ROCStories之间存在许多密切相关的语义联系,考虑使用ROCStories日常故事中的领域相关知识对于SCT中推理正确的结局是有效的。
发明内容
本发明的目的是提出一个三阶段故事阅读理解训练方法,引入在ROCStories故事无监督语料上的预训练步骤,提高预训练语言模型在故事完形填空SCT任务的准确率。
为了实现上述目的,本发明创造采用了如下技术方案:
一种基于自监督的三阶段故事阅读理解训练方法,其特征在于,包括以下步骤:
1)使用语言模型在开放域语料库上进行预训练;
2)采用语言模型LM或者掩码语言模型MLM的自我监督学习目标继续在无监督、同领域的ROCStories日常故事语料上进行预训练;
3)对目标SCT任务上的结果模型进行训练。
所述的步骤2)中,具体方法为:
2.1)调整BERT和任务特定参数,在无监督的ROCStories上执行自监督任务:
随机将ROCStories分成80%的训练集和20%开发集两部分,接着使用自我监督任务MLM和下一个句子预测NSP目标来预训练BERT;在MLM任务中,遵循BERT的程序,随机掩蔽15%经过Wordpiece分词之后、每个序列中的所有词项,使用模型预测掩蔽词项;使用的每条训练样例是一条5句话的故事;
2.2)为了理解故事,重新设计了用于ROCStories的变体NSP任务:
随机选择每个故事中的前句作为sent.A,当为每个训练前考试选择sent.B时,50%的时间B是A之后的实际下一个句子,50%的时间是故事中的随机句子;正样本与IsNext一起标记,负样本标记为NotNext;最终生成的模型在ROCStories开发集上的NSP任务中;
2.3)为了完成SCT任务,在BERT模型中,引入多项选择头作为模型的决策层:
表示形式C
引入了任务特定的参数——向量V∈R
C
其中:N是SCT任务中选项的数量。
所述的步骤3)中,具体方法为:
对于目标任务SCT,将四句故事视为句子A,将每个候选作为sent.B结尾,最终概率分布如下:
P
其中:RM这个函数代表自监督学习任务预训练的BERT模型和多选头;每个候选结尾都标有SCT数据集中的"错误结尾"或"正确结尾";由此将一般语义知识和同领域中的故事知识转移到SCT任务中;
训练模型的损失函数为交叉熵损失:
所述的步骤3)中,选择Adam优化器对目标领域监督训练模型进行训练。
本发明创造的有益效果:
本发明引入在ROCStories故事无监督语料上的预训练步骤,提高预训练语言模型对领域知识的融合,实现了SCT故事完形填空效果的提升。
附图说明
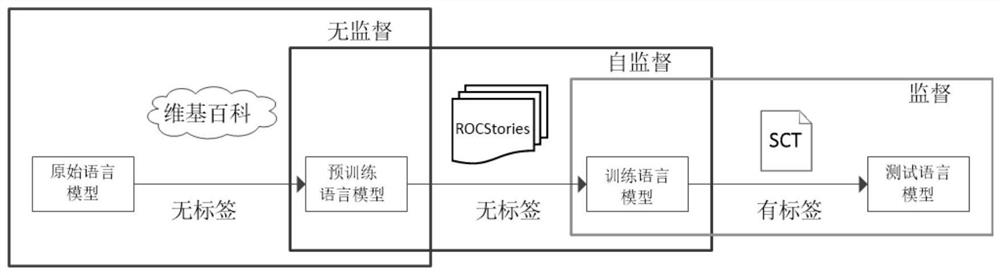
图1为自监督的三阶段故事阅读理解训练方法框架图。
具体实施方式
下面将结合本发明创造实施例中的附图,对本发明创造实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明创造一部分实施例,而不是全部的实施例。
下面结合附图和具体实施例对本发明作进一步详细说明。
为了使预训练语言模型能够掌握更多的领域相关知识,本发明提供了一种基于自监督的三阶段故事阅读理解训练框架,其包括三个阶段,如图1所示。在第一阶段,使用语言模型在开放域语料库上进行预训练。在第二阶段,继续采用LM或者MLM的自我监督学习目标继续在无监督、同领域的ROCStories预训练。在第三阶段,对目标SCT任务上的结果模型进行了微调。
下面展开阐述这三个阶段:
第一阶段:开放域预训练
本文采用原始BERT的做法进行开放领域预训练,这个阶段使用的自监督任务是masked语言模型和连续句子预测。同时,保持故事理解系统的输入与BERT一样,为sent.A和sent.B形式。还利用了分段嵌入来指示两个不同的句子,输入向量的结构与BERT一致,为
第二阶段:同领域自监督预训练
与之前的工作不同,本文调整了BERT和任务特定参数,在无监督的ROCStories上执行自监督任务,如下所述。随机将ROCStories分成两部分:80%的训练集和20%的开发集。
使用Masked Language Model(MLM)和下一个句子预测(NSP)目标来预训练BERT。本专利中,沿用此自我监督任务。
MLM任务遵循BERT的程序。随机掩蔽15%经过Wordpiece分词之后、每个序列中的所有词项,模型需要预测掩蔽词项。与开放域预训练不同的是,这里使用的每条训练样例不再是512长度的自然语言文本,而是一条5句话故事。
接着,为了理解故事,重新设计了用于ROCStories的变体NSP任务。与BERT不同,随机选择每个故事中的前句作为sent.A。当为每个训练前考试选择sent.B时,50%的时间B是A之后的实际下一个句子,50%的时间是故事中的随机句子。正样本与IsNext一起标记,负样本标记为NotNext。最终生成的模型在ROCStories开发集上的NSP任务中实现了95%-96%的精度。
为了完成第二阶段和第三阶段的任务,此处引入了多项选择头作为模型的决策层。方案如下:
表示形式C
C
其中N是SCT任务中选项的数量,本专利中,N为2。
第三阶段:目标领域监督训练
对于目标任务SCT,将四句故事(上下文)视为句子A,将每个候选作为sent.B结尾。最终概率分布如下:
P
其中:RM代表第二阶段自监督学习任务预训练的BERT模型和多选头(公式1)。每个候选结尾都标有SCT数据集中的"错误结尾"或"正确结尾"。这样,就可以将一般语义知识和同领域中的故事知识转移到SCT任务中。
训练模型的损失函数为交叉熵损失(见公式4):
本文选用Adam优化器对模型进行训练。
基于Adam的训练算法:
输入:batch-size个样例(句对X,标签Y),
经过二阶段训练之后BERT的词向量,
经过二阶段训练之后BERT的模型参数θ
输出:模型参数θ更新;
1.利用X和θ,在模型中计算得到预测的标签
2.利用Y、
3.利用Adam优化器计算更新模型参数θ;
4.Until当验证集上的准确率连续三轮低于之前的最大值。
实施例1:
实验使用ROCStories作为第二阶段自监督预训练的语料,这个语料库收集了98,162个众包完整的五句话故事。每个故事以一个主题,跟随一个角色通过一系列事件得出一个符合常识和逻辑的结尾。
本文根据标记数据SCT-v1.0和SCT-v1.5评估三阶段故事阅读理解训练框架。SCT-v1.0是包括3,742个故事,其中包含一个四句情节和两个候选人结尾。正确的结局自然以连贯和有意义的方式结束故事,错误的结局完全不可能成为故事的自然结局。此外,所有结尾应至少分享故事的一个角色。SCT-v1.5包含1,571个四句故事上下文,以及验证和盲测试数据集中正确的结尾和错误的结局。
在第三个阶段,本文微调了SCT验证集上生成的模型,以选择正确的结束。本文随机拆分80%的故事,将SCT-v1.0评估集中的两个考生结尾作为培训集(1,479个案例),将SCT-v1.0评估集中的20%的故事作为验证集(374个案例)。此外,使用SCT-v1.0测试集作为测试集(1,871个案例)。对于SCT-v1.5,使用1,871SCT-v1.0测试数据集用于训练目的,并在SCT-v1.5验证集中进行测试。
表1所用数据集详细信息
参数设置如下表:
表2参数设置
优化器使用的是Adam。
为了全面地验证比较本发明的实验效果,将本发明与强基线系统BERT large进行效果比较。
表3在SCT数据集上的实验效果
通过分析表3,可以清楚的看到,三阶段故事阅读理解训练框架达到了最优的效果,在不使用其他有监督数据的情况下,只使用同领域的ROCStories进行预训练,可以帮助目标领域的SCT任务达到很好的效果。
表4在SCT数据集上的实验效果
从表4的结果可以看出,本发明在去除人类偏置的升级版本SCT-v1.5上也有很好的表现,已经超过了基线系统,达到最好的效果。综上,本发明具有很好的泛化能力,有效地提升BERT在NLP下游任务上的效果。
- 一种基于自监督的三阶段故事阅读理解训练方法
- 一种基于自监督学习的无监督机器阅读理解训练方法