一种基于要素的雷暴大风的识别方法
文献发布时间:2023-06-19 13:26:15
技术领域
本发明涉及一种基于要素的雷暴大风的识别方法,尤其涉及一种使用深度学习构建模型对雷暴大风天气的识别方法。
背景技术
随着经济和技术的不断发展,强对流带来的雷暴大风对于人民的生命财产安全威胁不断加大,而现在的预警技术很难在短时内对雷暴大风这种极端天气做出预警。
发明内容
鉴于目前雷暴大风识别方法存在的上述不足,本发明提供一种基于要素的雷暴大风的识别方法,能够通过建立神经网络模型自动识别雷暴大风。
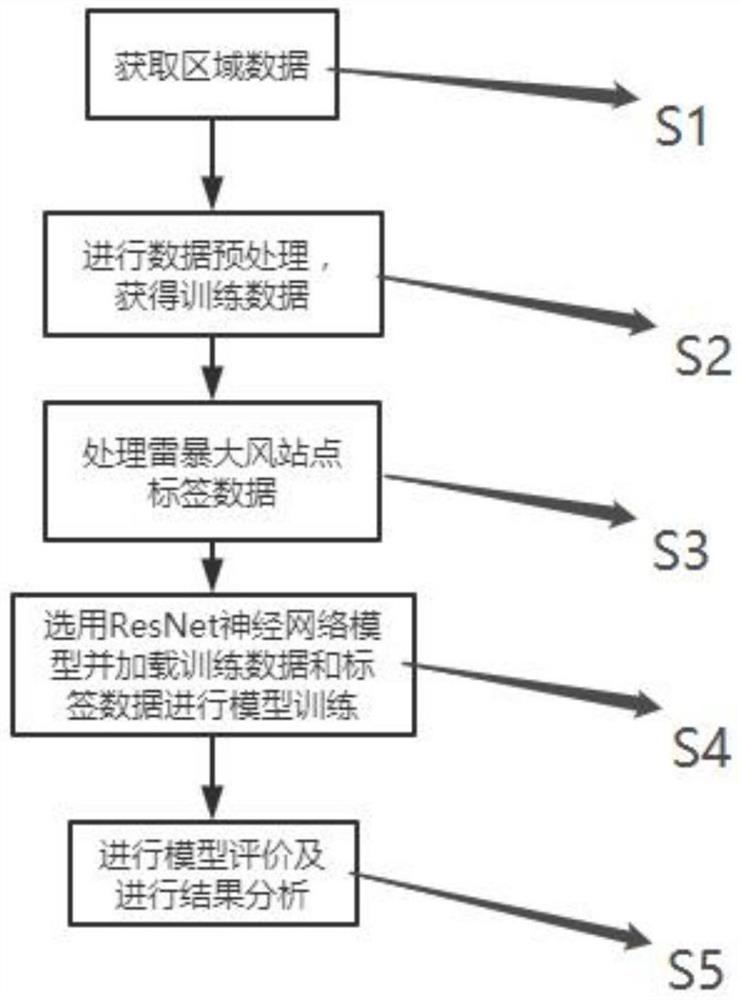
为达到上述目的,本发明的实施例采用如下技术方案:一种基于要素的雷暴大风的识别方法,其特征在于包括以下步骤如图1所示:
获取区域数据;
进行数据预处理,获得训练数据;
处理雷暴大风站点标签数据;
选用ResNet神经网络模型并加载训练数据和标签数据进行模型训练;
进行模型评价及进行结果分析。
依照本发明的一个方面所述一种基于要素的雷暴大风的识别方法,所述获取区域数据数据包括:获取某地区某个时间段内逐时间间隔的GRIB2格式气象数据。
依照本发明的一个方面所述一种基于要素的雷暴大风的识别方法,所述气象数据包括:不同高度下基于特征要素高度场、相对湿度、温度场、风场U分量、风场V分量、累计降水、海平面气压、月份编码和时间编码的数据。
依照本发明的一个方面所述一种基于要素的雷暴大风的识别方法,所述步骤对数据进行预处理包括:
进行区域裁剪;
进行月份和时间编码;
进行数据清洗和采样;
生成CSV文件用于训练。
依照本发明的一个方面所述一种基于要素的雷暴大风的识别方法,所述月份和时间的编码方式借助x
其中month Val、dateVal分别为月份和日期的具体值,Month x和Month y为月份的编码值,Datex和Datey为日期的编码值。
依照本发明的一个方面所述一种基于要素的雷暴大风的识别方法,所述对数据进行采样包括三轮采样,首先对数据进行欠采样,对没有雷暴大风的数据进行采样,对有雷暴大风的数据全部保留不变。然后对数据进行过采样,对有雷暴大风的数据进行复制,增加其数量,对没有雷暴大风的数据不进行操作,最后再加入SMOTE过采样方法进行进一步过采样,SMOTE算法流程如下:
对于少数类中每一个样本x,以欧氏距离为标准计算它到少数类样本集中所有样本的距离,得到其k近邻;
根据样本不平衡比例设置一个采样比例以确定采样倍率N,对于每一个少数类样本x,从其k近邻中随机选择若干个样本,假设选择的近邻为o;
对于每一个随机选出的近邻o,分别与原样本按照公式o(new)=o+rand(0,1)*(x-o)构建新的样本。
依照本发明的一个方面所述一种基于要素的雷暴大风的识别方法,所述标签数据处理为将某段时间内的雷暴大风站点实况作为标签原始数据,对发生过雷暴大风的站点赋值为1,对未发生过雷暴大风的站点赋值为0。
依照本发明的一个方面所述一种基于要素的雷暴大风的识别方法,,所述的选用ResNet神经网络并加载训练数据和标签数据进行模型训练包括:
选用Adam优化器;
损失函数设计;
数据归一化;
训练。
依照本发明的一个方面所述一种基于要素的雷暴大风的识别方法,所述的数据归一化方法采用最大最小数据归一化方法,公式为:
其中value为原始值,newvalue为归一化之后的值,max、min分别为计算的值所在特征中的最大值和最小值。
依照本发明的一个方面所述一种基于要素的雷暴大风的识别方法,所述损失函数设计采用二分类情况下Cross Entropy Loss Function,表达式为:
本发明实施的优点:通过上述的方案,能使用模型根据数据的气象数据和特征自动完成对雷暴大风天气的识别,加速了对雷暴大风天气预报的速度,提高了预报的水平。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明所述的一种基于要素的雷暴大风的识别方法的流程图;
图2为本发明所述的一种训练数据编码方法的编码函数图像;
图3为本发明所述的一种神经网络模型的ResNet神经网络退化问题示意图;
图4为本发明所述的一种神经网络模型的ResNet残差结构示意图;
图5为本发明所述的一种数据归一化方法的未将数据归一化处理的迭代更新示意图;
图6为本发明所述的一种数据归一化方法的将数据归一化处理过的迭代更新示意图;
图7为本发明所述的一种训练方法的训练结果图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例一:如图1、图2、图3、图4、图5、图6、图7所示,一种基于要素的雷暴大风天气识别方法步骤如下:
步骤S1:获取区域数据:
所述步骤S1获取区域数据具体为:获取某地区某个时间段内逐时间间隔的GRIB2格式气象数据,例如本实施例采用2020年3月到9月GRIB2格式的华南3公里逐小时格点数据来。所述数据包含以下表格所示气象要素和特征:
表1
步骤S2:进行数据预处理,获得训练数据:
步骤S21:数据裁剪:
在本实施例中数据整体区域为华南区域,目标区域为湖南省,所以对数据根据经纬度进行裁剪,裁剪至包含湖南全域的格点数据,格点数为192*192。
步骤S22:月份与时间编码:
月份和时间为连续性散点特征,如果不采用编码,对于像1月与12月或者1点和23点,这类情况,它们的数值差异较大,但是本身代表的背景或意义差距不大。直接放入数值,会影响模型的判断。
如果采用普通的独热编码将会增大无用的特征值,如月份将扩展为12个特征值,使模型较难收敛,所以借助x
将月份与时间的值对应为该函数上的一点,用点的x,y坐标代表它本身的值。这样就可以用两个特征值表示月份或者是时间。具体公式如下:
其中monthVal、dateVal分别为月份和日期的具体值,Monthx和Monthy为月份的编码值,Datex和Datey为日期的编码值。
步骤S23:数据清洗与采样:
数据清洗:对数据整体进行筛选清洗,将包含缺失值、异常值的数据剔除。缺失值数据为步骤S1表1中任意数据缺失即为缺失值数据,也即必须保证数据的完整性。异常值数据为步骤S1表1中任意数据值明显错误即为异常值数据,包括:过大、过小等情况。排除异常数据对模型训练过程的影响。
数据采样:由于正负数据样本的严重不均衡,即有雷暴大风的数据和没有雷暴大风的数据量差距较大,所以对数据采用必要的采样,使数据分布更为均衡,提升模型的稳定性。首先对数据进行欠采样,对没有雷暴大风的数据进行采样,对有雷暴大风的数据全部保留不变。然后对数据进行过采样,对有雷暴大风的数据进行复制,增加其数量,对没有雷暴大风的数据不进行操作。最后由于雷暴大风数据的过于不均衡,以上欠采样和普通过采样之后,再加入SMOTE过采样方法进行进一步过采样。
SMOTE(Synthetic Minority Oversampling Technique),合成少数类过采样技术.它是基于随机过采样算法的一种改进方案,由于随机过采样采取简单复制样本的策略来增加少数类样本,这样容易产生模型过拟合的问题,即使得模型学习到的信息过于特别(Specific)而不够泛化(General),SMOTE算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中,具体如图4所示,算法流程如下:
(1)对于少数类中每一个样本x,以欧氏距离为标准计算它到少数类样本集中所有样本的距离,得到其k近邻。
(2)根据样本不平衡比例设置一个采样比例以确定采样倍率N,对于每一个少数类样本x,从其k近邻中随机选择若干个样本,假设选择的近邻为o。
(3)对于每一个随机选出的近邻o,分别与原样本按照公式o(new)=o+rand(0,1)*(x-o)构建新的样本。
步骤S24:数据生成csv文件用于训练。
步骤S3:处理雷暴大风站点标签数据:
标签原始的数据为2020年雷暴大风站点实况,对于发生雷暴大风的站点标签为1,没有发生雷暴大风的站点标签为0。
步骤S4:选用ResNet神经网络模型并加载训练数据和标签数据来进行模型训练:
步骤S41:数据归一化:
对训练数据和标签数据采用最大最小归一化,归一化能在一定程度提高模型精度,因为大多模型的loss计算,需要假定数据的所有特征都是零均值并且具有同一阶方差的。这样在计算loss时,才能将所有特征属性统一处理。如果样本两个属性的量纲差距过大,则大量纲的属性在距离计算中就占据了主导地位。而现实中,可能恰恰相反。所以,加入归一化,将数据的特征属性scale到统一量纲,可以一定程度解决这个问题。
同时归一化能够提升收敛速度,对于使用梯度下降优化的模型,每次迭代会找到梯度最大的方向迭代更新模型参数。但是,如果模型的特征属性量纲不一,那么我们寻求最优解的特征空间,就可以看作是一个椭圆形的,其中大量纲的属性对应的参数有较长的轴。在更新过程中,可能会出现更新过程不是一直朝向极小点更新的,而是呈现‘Z’字型,如图5所示。使用了归一化对齐量纲之后,更新过程就变成了在近似圆形空间,不断向圆心(极值点)迭代的过程,如图6所示。
在具体实现的时候,为防止分母为0,通常会加一个smooth,公式变成:
步骤S42:选定神经网络模型。
选定ResNet神经网络模型,原因如下:
在ResNet网络中有如下几个亮点:
(1)提出residual结构(残差结构),并搭建超深的网络结构(突破1000层)。
(2)使用Batch Normalization加速训练(丢弃dropout)。
在ResNet神经网络模型提出之前,传统的卷积神经网络都是通过将一系列卷积层与下采样层进行堆叠得到的。但是当堆叠到一定网络深度时,就会出现两个问题:梯度消失或梯度爆炸、退化问题(degradation problem)。
在ResNet神经网络模型通过数据的预处理以及在网络中使用BN(BatchNormalization)层能够解决梯度消失的问题。但是对于退化问题(随着网络层数的加深,效果还会变差,如图3左侧所示)并没有很好的解决办法。
所以ResNet神经网络模型又使用了residual结构(残差结构)来减轻退化问题。图3右侧图是使用残差(residual)结构的卷积网络,可以看到随着网络的不断加深,效果并没有变差,反而变的更好了。
残差的含义:ResNet提出了两种mapping:一种是identity mapping,指的就是图4中“弯弯的曲线”,另一种residual mapping,指的就是图4中除了“弯弯的曲线”那部分,所以最后的输出是y=F(x)+x。顾名思义,就是指本身,也就是公式中的x,而residualmapping指的是“差”,所以残差指的就是F(x)部分。残差结构如附图3所示。
步骤S43:设计损失函数;
损失函数采用Cross Entropy Loss Function(交叉熵损失函数)。交叉熵主要是用来判定实际的输出与期望的输出的接近程度,刻画的是实际输出(概率)与期望输出(概率)的距离,也就是交叉熵的值越小,两个概率分布就越接近。在二分的情况下,模型最后需要预测的结果只有两种情况,对于每个类别我们的预测得到的概率为p和1-p,此时表达式为:
步骤S44:选定优化器:
优化器采用Adam优化器,Adam优化器结合AdaGrad和RMSProp两种优化算法的优点。对梯度的一阶矩估计(First Moment Estimation,即梯度的均值)和二阶矩估计(Second Moment Estimation,即梯度的未中心化的方差)进行综合考虑,计算出更新步长。
它具有如下优点:
1:实现简单,计算高效,对内存需求少;
2:参数的更新不受梯度的伸缩变换影响;
3:超参数具有很好的解释性,且通常无需调整或仅需很少的微调;
4:更新的步长能够被限制在大致的范围内(初始学习率);
5:能自然地实现步长退火过程(自动调整学习率);
6:很适合应用于大规模的数据及参数的场景;
7:适用于不稳定目标函数;
8:适用于梯度稀疏或梯度存在很大噪声的问题。
S45:训练:
将归一化之后的训练数据和标签数据,加载ResNet的模型,并在GPU上进行迭代训练。本实施例硬件配置为:GPU为GTX 1080Ti,内存:128G,深度学习框架为PyTorch 1.6,CUDA版本为10.2。除了这些硬件配置还可采用可以运行本实施例的硬件配置,例如GTX2080,内存256G等以上硬件配置仅为例举。训练的学习率为3e-4,batch_size为256,迭代次数为2000。
S5:模型评价和结果分析:
S51:模型评价标准:
首先定义如下概念:
True Positive(TP):预测为正例,实际为正例。
False Positive(FP):预测为正例,实际为负例。
True Negative(TN):预测为负例,实际为负例。
False Negative(FN):预测为负例,实际为正例。
accuracy指的是正确预测的样本数占总预测样本数的比值,它不考虑预测的样本是正例还是负例。而precision指的是正确预测的正样本数占所有预测为正样本的数量的比值,也就是说所有预测为正样本的样本中有多少是真正的正样本。可以看出precision只关注预测为正样本的部分,而accuracy考虑全部样本。
Recall可以称为召回率、查全率,指的是正确预测的正样本数占真实正样本总数的比值,也就是从这些样本中能够正确找出多少个正样本。
F-score相当于precision和recall的调和平均,recall和precision任何一个数值减小,F-score都会减小,反之,亦然。能最好的体现识别的准确度。
模型训练中采用F-score作为评价标准,取F-score最大的时候,保存模型。
S52:训练结果:
训练模型之后预测统计结果如附图7所示。
S53:结果分析:
根据预测的统计结果观察,站点模型对于部分站点的预测准确率很高。在实际情况中加入站点的独特信息特征如站点的海拔高度、平均风速等特征。从而将进一步提高站点模型的预测准确率。
本发明实施的优点:通过上述的方案,能使用模型根据数据的气象数据和特征自动完成对雷暴大风天气的识别,加速了对雷暴大风天气预报的速度,提高了预报的水平。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本领域技术的技术人员在本发明公开的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
- 一种基于要素的雷暴大风的识别方法
- 一种基于地面观测的雷暴大风风暴体标识方法及系统