基于深度强化学习的车道保持方法
文献发布时间:2023-06-19 13:27:45
技术领域
本发明涉及车辆决策控制技术领域,特别涉及基于深度强化学习的车道保持方法。
背景技术
无人驾驶技术作为新兴技术革命浪潮的开端和人工智能最大规模的落地场景之一,对改善城市交通和环境友好有重要意义;同时,以竞赛实验用小车为无人驾驶技术研究原型大大降低了实验成本和测试周期,在加快相关技术发展过程中具有进步意义。
目前的智能驾驶/辅助技术方案依然是感知-决策-控制的管道流程模块,在这种方案决策块中依然存在着许多不足之处:其一,规则人工设计与制定,虽然精妙但是极其复杂,设计和实现成本高昂;其二,设计的规则策略一般来说难以应付环境的多变性;其三,由于硬件设备的固有复杂性和高昂实验成本,在实际车辆进行改进和实验带来的支出费用高昂。
因此,如何提供一种易于快速实验的基于深度强化学习的车道保持方法是本技术领域内研究人员亟需解决的问题。
发明内容
本发明的目的在于提供基于深度强化学习的车道保持方法,实现了小车车道保持任务的自学习,简化了传统的车道检测-处理-控制流程,实现了端到端的命令输出控制,可以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:
基于深度强化学习的车道保持方法,包括如下步骤:
S1:采集环境-智能体(Env-Agent)状态观测值,包括环境状态数据和车辆状态数据;
S2:先进行模型网络的初始化,然后开始交互,每次交互将数据s馈入神经网络后,得到对应的输出a,然后根据输出选定的动作继续与环境交互,得到一次交互的完整数据<s,a,s',r>,然后以此方法与环境进行多次交互,得到多次交互数据,存入经验缓存池(Replay Buffer,RB);
S3:从RB中采样一批次交互数据,进行一次网络更新;不断重复S2,多次更新网络,直至最终模型收敛,其中Q网络的更新公式为:
式中,s
S4:根据收敛后的模型进行策略控制,其策略为:
其中,π
进一步地,S1具体包括以下步骤:
步骤S101:所述环境状态数据包括车辆相对于预定义原点的世界坐标Position(x,y,z)、车辆的跨轨误差CTE(即在所处车道中车辆距离轨道中心距离)和车辆的碰撞关系Hit(即是否碰撞)。
进一步地,所述车辆状态数据包括车辆的绝对速度Speed、车辆的转向值Steering、车辆的油门值Throttle和车辆正前方摄像头返回的相机图像数据Image,预处理过程为:
将车辆正前方摄像头返回的相机图像数据Image进行裁剪和标准化处理,首先,对每幅图像的像素归一化至[0,1]范围间,然后对图像的尺寸进行裁剪至设定大小,此处为(height=120,width=160),然后基于以上车辆状态数据构建数据存储,其中写入的数据有:
其中,mod表示当前数据来源模式,训练前人为操作采集数据时mod=user,训练中车辆自动采集数据时mod=car;i表示一批的采集数据中当前数据存储id编号。
进一步地,S2具体包括以下步骤:
S201:先进行模型网络的初始化,然后开始交互。其中模型网络的初始化是指让网络得到一个较为合理的初始化权重,减少不必要的无效探索,以加快模型的收敛速度,进而减少训练时间。将步骤11中所述的车辆状态数据经过预处理后的存储数据作为初始化数据对网络进行初始化,输入图像数据(120,160,3)经过5次卷积激活(Convolution2D)-丢弃(Drop)操作后进行展平(Flatten),然后经过两个全连接激活层,最后输出一个长度为2的一维向量,代表输出[steering,throttle]动作向量对应的Q值。所述之开始交互是指车辆在与环境交互过程中的探索策略(Explore Strategy),采用ε-greedy策略进行与环境的交互和探索,根据概率ε执行输出动作向量对应Q值最大的动作,有1-ε概率从动作空间中随机执行一个动作,动作空间为[-1,1]间的21个数值,数值间隔为0.1,映射到实际车辆操控/油门实际数值则乘以相应操控/油门的取值范围。概率ε作为人为设置的超参数,取值初始设置为0.6,在给定训练轮数epoch后,在训练过程中不断增长,线性增长至0.9到最后一轮;
S202:开始交互后,在t时刻(步)将数据s
进一步地,其特征在于,S3具体包括以下步骤:
S301:从RB中采样一批次交互数据,进行一次网络更新,更新公式如公式(1)所述,更新结束后保留1/4奖励最高的交互数据,用于下一轮次更新。直至最终模型收敛。模型收敛的数据上表现为得到的单步奖励和轮次奖励逐渐上升并最终趋于稳定上下微小浮动,实际中表现为车辆可以稳定地保持在车道中行驶,并且可以行驶完一段完整的道路。
进一步地,S4具体包括以下步骤:
S401:根据收敛后的模型进行策略控制是指可以将训练完成的模型后加载至车辆上于训练环境中进行测试,不必存储交互数据和更新网络等;同时,将车辆于新的测试环境中进行测试。
与现有技术相比,本发明的有益效果是:
本发明公开了基于深度强化学习的车道保持方法,包括采集环境-智能体状态观测值,即环境状态数据和车辆状态数据并进行数据的预处理后用以传入网络模型和初始化网络。网络基于交互数据以强化学习的方式学习车道保持这一驾驶任务,期间不断更新网络直至模型收敛,然后基于收敛后的网络进行任务执行的最优策略输出控制。本发明提供的基于深度强化学习的车道保持方法,实现了小车车道保持任务的自学习,简化了传统的车道检测-处理-控制流程,实现了端到端的命令输出控制。
附图说明
图1为完整无十字交叉路口环状道路示意图;
图2为完整无十字交叉路口环状道路车辆可行车道示意图;
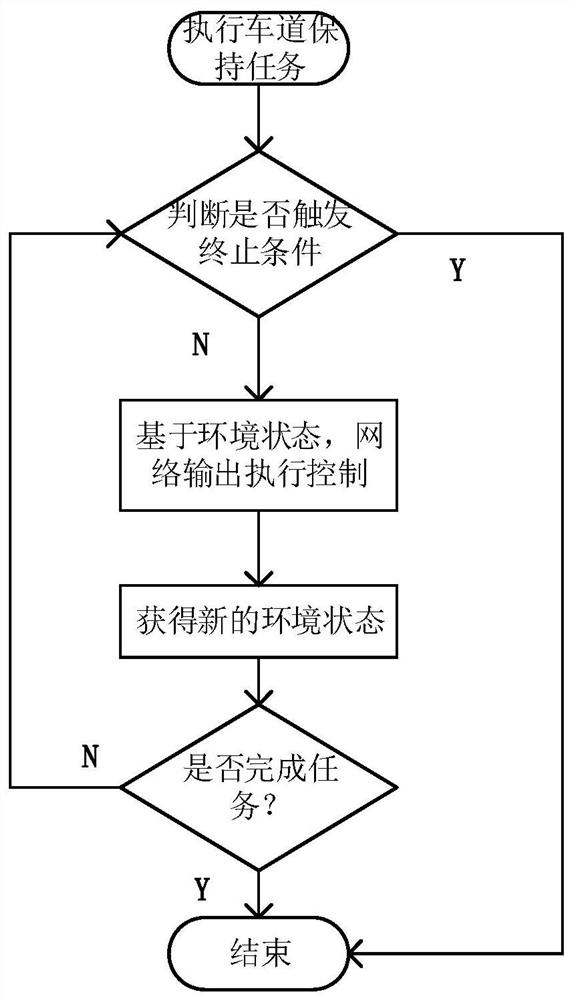
图3为车道保持策略逻辑示意图;
图4为神经网络内部计算过程示意图;
图5为神经网络训练过程示意图;
图6为程序模块交互图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,以模拟环境中一段完整无十字交叉路口道路环状道路为例。假定车辆所在车道为右侧单车道,车辆起始位置即为世界坐标系起始原点位置,同时也是车辆终点位置。
待车辆从起始位置出发后,车辆便开始获得环境状态数据,即包括车辆相对于预定义原点的世界坐标Position(x,y,z)、车辆的跨轨误差CTE(即在所处车道中车辆距离轨道中心距离)和车辆的碰撞关系Hit(即是否碰撞)等以及自身车辆状态数据,包括车辆的绝对速度Speed、车辆的转向值Steering、车辆的油门值Throttle和车辆正前方摄像头返回的相机图像数据Image等,然后将这些数据传给核心处理单元中的模型训练使用,模型根据传输来的数据输出操控命令,进而输出控制动作。
下面举例说明基于深度强化学习的车道保持方法。假定任务场景如图1-6所示,为一段完整无十字交叉路口道路环状道路。包括以下步骤:
步骤1:采集环境-智能体(Env-Agent)状态观测值,包括环境状态数据和车辆状态数据,作为网络模型的输入。同时,需要对数据进行预处理。数据采集和预处理的具体过程为:车辆相机返回图像数据,将车辆正前方摄像头返回的相机图像数据Image进行裁剪和标准化处理。首先,对每幅图像的像素归一化至[0,1]范围间,然后对图像的尺寸进行裁剪至设定大小,此处为(height=120,width=160)。
然后基于以上车辆状态数据构建数据存储,写入数据为:
其中,mod表示当前数据来源模式,训练前人为操作采集数据时mod=user,训练中车辆自动采集数据时mod=car;i表示一批的采集数据中当前数据存储id编号。
步骤2:车辆命令操控策略由模型网络处理输入数据后输出,记为π
神经网络结构如图3所示,输入图像数据(120,160,3)经过5次卷积激活(Convolution2D)-丢弃(Drop)操作后进行展平(Flatten),然后经过两个全连接激活层,最后输出一个长度为2的一维向量,代表输出动作向量[steering,throttle]对应的Q值。
神经网络模型训练具体过程如下:
步骤21:初始化。为让网络得到一个较为合理的初始化权重,减少不必要的无效探索,以加快模型的收敛速度,进而减少训练时间,将所述的车辆状态数据经过预处理后的存储数据作为初始化数据对网络进行更新,得到初始权值参数。
步骤22:开始交互得到交互数据。所述之开始交互是指车辆在与环境交互过程中的探索策略(Explore Strategy),采用ε-greedy策略进行与环境的交互和探索,根据概率ε执行输出动作向量对应Q值最大的动作,有1-ε概率从动作空间中随机执行一个动作,动作空间为[-1,1]间的21个数值,数值间隔为0.1,映射到实际车辆操控/油门实际数值则乘以相应操控/油门的取值范围。开始交互后,在t时刻(步)将数据s
步骤23:多次单轮更新网络。如步骤22所述,最终可得一轮次的全部交互数据RB。从RB中采样一批次交互数据,进行一次网络更新,更新公式如公式(1)所述。更新结束后保留1/4奖励最高的交互数据,用于下一轮次更新。本轮次结束后不断重复步骤22,多次更新网络,直至最终模型收敛。模型收敛的数据上表现为得到的单步奖励和轮次奖励逐渐上升并最终趋于稳定上下微小浮动,实际中表现为车辆可以稳定地保持在车道中行驶,并且可以行驶完一段完整的道路。
步骤24:最优策略控制测试。根据收敛后的模型进行策略控制,是指可以将训练完成的模型后加载至车辆上于训练环境中进行测试,不必存储交互数据和更新网络等;同时,将车辆于新的测试环境中进行测试。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 基于深度强化学习的车道保持方法
- 一种基于车道保持辅助功能的车道保持方法及系统