一种面向多任竞争的工人训练报酬确定方法
文献发布时间:2023-06-19 18:29:06
技术领域
本发明属于联邦学习系统中工人训练报酬确定策略技术领域,具体涉及一种面向多任竞争的工人训练报酬确定方法。
背景技术
联邦学习系统的训练效率与其参与训练任务的工人节点在每轮迭代中所更新的本地模型的质量密切相关。然而,工人节点在参与联邦学习任务的过程中会使用计算资源、通信资源等各类资源,造成巨大的成本消耗。同时,恶意的服务器节点可以借助中间梯度推断出重要的数据信息,从而使工人节点隐私数据的安全存在不确定的因素。上述原因均导致工人节点参加联邦学习任务的积极性被极大的削弱。因此,系统中的任务发布者需要设计合适的激励机制以确定工人的报酬,以此来吸引工人节点参与联邦学习任务。
再者,联邦学习系统中存在任务发布者和工人节点之间信息不对称的问题,即每位工人节点的数据质量、计算能力等关键信息对于任务发布者不可见,任务发布者只能通过经验判断工人节点的质量分布,进而推测出每位工人节点属于某一类型的概率。为了解决这一问题,多数研究都利用契约理论将工人节点的质量类型映射成适当的奖励,以此达到吸引更多高质量的工人节点加入联邦学习系统的目的。
目前的研究所支持的场景均为一个任务发布者和多个工人节点的设定,即在系统中由一个任务发布者为多个参与任务的节点设计契约,这种假设在实际应用中是不合理的。
发明内容
本发明的目的在于提供一种面向多任竞争的工人训练报酬确定方法,在多任务发布者竞争场景下以契约理论为基础的工人训练报酬确定策略,达到吸引更多高质量的工人节点加入联邦学习的目的。
一种面向多任竞争的工人训练报酬确定方法,包括以下步骤:
1)联邦学习系统中,多个任务发布者发布训练任务,并将预先设计好的合同提交至区块链中保存;
2)系统中的工人节点通过区块查看多个任务发布者已经提交的不同的任务和合同,选择签署对于自身的最优合同;签署结束后,工人节点使用本地的数据集进行模型训练;
3)工人节点将训练好的模型上传至区块链保存;
4)任务发布者从区块链上获取已更新的模型,并在本地将所有的模型进行聚合;
5)联邦学习任务结束后,任务发布者根据其与工人节点签署的合同支付给工人节点相应的报酬,并将支付记录保存在区块链上。
进一步地,所述步骤2)具体为:
2.1)最优合同中工人节点参与任务的成本包括训练成本和通信成本;
每个工人节点都有属于自己的本地数据集,工人节点在每轮迭代中训练一次本地模型需要消耗计算时间
其中,c
工人节点将更新后的训练模型交付给任务发布者的过程通过无线通信实现,工人节点n每轮迭代过程中需要消耗通信时间
其中,σ为所有工人节点每轮迭代结束后传递模型参数的大小为固定常量;ρ
工人节点n参与一次全局迭代过程的消耗的总时间
工人节点n参与一次全局迭代过程的消耗的总能源
2.2)在联邦学习系统中,收益的所有方分为任务发布者和工人节点两种角色;
对于任务发布者来说,他们能够根据以往经验推测出每个工人节点属于某种类型的概率;假设工人节点的质量分为M类,且按升序排列,表示为θ
由于任务发布者和工人节点之间存在信息不对称的问题,任务发布者i为不同质量类型的工人节点设计特定的合同抽象成
对于一份合同,任务发布者从工人节点n获得的收益函数U
由于联邦学习系统中不同任务发布者之间存在着竞争,且每位任务发布者都争取利益的最大化,引入工人节点选择该任务发布者的概率pc
对于工人节点n签署了任务发布者i提交的合同,其对应收益函数U
则工人节点的总体收益函数
2.3)当信息存在不对称的情况时,任务发布者设计的合同需要同时满足个人理性约束和激励兼容性;
定义1:个人理性约束:每个工人节点同意参与联邦学习任务的条件是完成该任务后收益是非负的,表示如下:
定义2:激励兼容性约束:每个工人节点获得最大收益的条件是选择根据自身质量类型所设计的合同,表示如下:
最优合同的计算首先考虑在没有单调性约束情况下的松弛问题,再检查获得的解是否满足单调性条件;同时工人节点考虑使自己的收益最大化,使用最优的p
s.t.
2.4)具体迭代过程为:
首先以任务发布者A的合同为定值,利用该定值条件推导出任务发布者B的最优合同;接着以任务发布者B的最优合同为定值,利用该条件重新推导出任务发布者A的最优合同;重复执行上述过程,直至任务发布者A和任务发布者B的最优合同均趋于收敛,此时便可计算出每类质量的工人节点所对应的最优化合同;该均衡条件同时满足了每份合同中的个人理性约束和激励兼容性约束,即多个任务发布者在竞争条件下保证非负收益的同时,还保证了每位工人节点都能选择符合自身条件的最优化合同,获得最优的收益。
本发明的有益效果在于:
本发明基于联邦学习系统中存在多个任务发布者和多个工人节点的情景,在该情景下多个任务发布者之间存在竞争关系。对于任务发布者们而言,为了在竞争中取得优势地位从而吸引更多高质量的工人节点的加入,他们需要提高所支付的报酬。但从自身利益考虑,任务发布者们又要通过降低支付报酬的方式在任务中获得更高的收益。对于工人节点而言,多个任务发布者的出现让他们有选择的最优合同的机会,以保证自己的收益。本发明不仅适用于更符合实际需求的多任务发布者的场景,同时满足个人理性约束和激励兼容性约束,能够平衡任务发布者和工人节点的关系,使系统中的两种角色均能获得预期收益,形成良性发展,达到激励工人节点加入联邦学习系统的目的。
附图说明
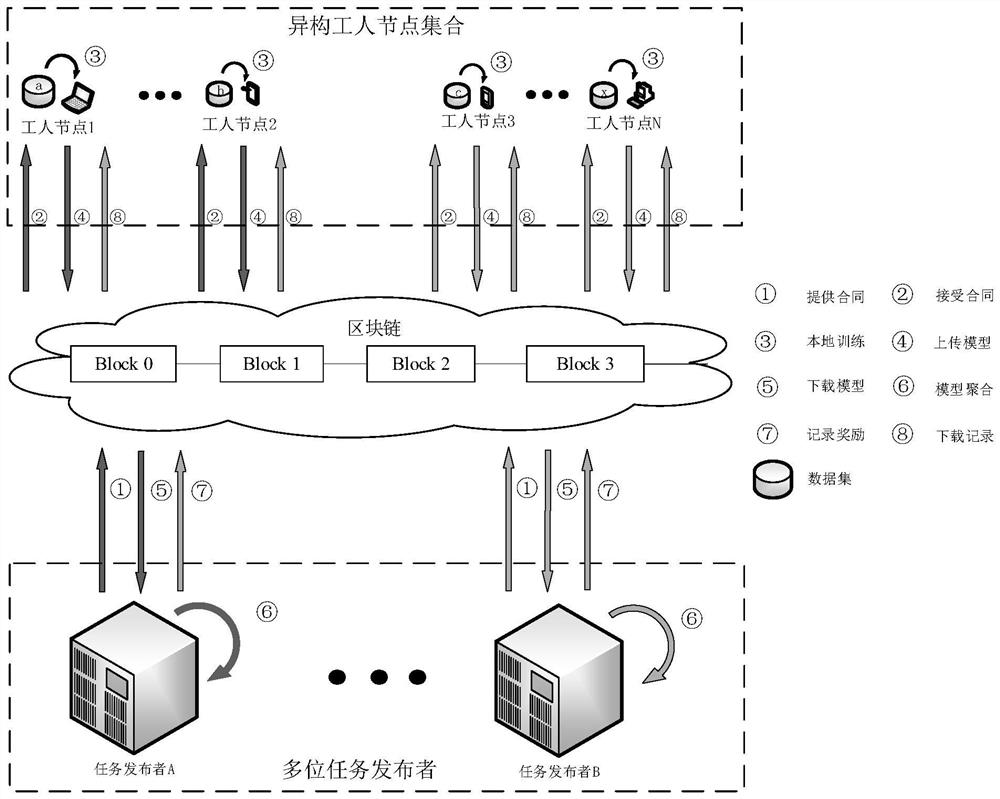
图1为本发明的架构图。
具体实施方式
下面结合附图对本发明做进一步描述。
本发明涉及一种工人训练报酬确定策略,具体为存在多任务发布者的联邦学习系统中以契约理论为基础的一种面向多任竞争的工人训练报酬确定方法。
本发明基于联邦学习系统中存在多个任务发布者和多个工人节点的情景,在该情景下多个任务发布者之间存在竞争关系。对于任务发布者们而言,为了在竞争中取得优势地位从而吸引更多高质量的工人节点的加入,他们需要提高所支付的报酬。但从自身利益考虑,任务发布者们又要通过降低支付报酬的方式在任务中获得更高的收益。对于工人节点而言,多个任务发布者的出现让他们有选择的最优合同的机会,以保证自己的收益。
联邦学习系统由任务发布者、工人和区块链组成。其中存在多名任务发布者和多名工人,工人节点之间是异构的。区块链位于云端,用于存储和计算。并且两种角色之间存在信息不对称问题。因此,在为不同质量类型的工人节点设计合同时,需要计算出工人节点参与联邦学习任务时的成本以及收益函数,进而设计出最优合同。
1)最优合同中工人节点参与任务的成本包括训练成本和通信成本。
每个工人节点都有属于自己的本地数据集,工人节点在每轮迭代中训练一次本地模型需要消耗计算时间
工人节点将更新后的训练模型交付给任务发布者的过程通过无线通信实现,工人节点n每轮迭代过程中需要消耗通信时间
即工人节点n参与一次全局迭代过程的消耗的总时间
工人节点n参与一次全局迭代过程的消耗的总能源
2)在联邦学习系统中,收益的所有方分为任务发布者和工人节点两种角色。
对于任务发布者来说,他们能够根据以往经验推测出每个工人节点属于某种类型的概率。假设工人节点的质量分为M类,且按升序排列,表示为θ
由于任务发布者和工人节点之间存在信息不对称的问题,任务发布者i为不同质量类型的工人节点设计特定的合同可以抽象成
对于一份合同,任务发布者从工人节点n获得的收益函数为U
由于联邦学习系统中不同任务发布者之间存在着竞争,且每位任务发布者都争取利益的最大化,因此基于公式(7),引入工人节点选择该任务发布者的概率pc
对于工人节点n签署了任务发布者i提交的合同,其对应收益函数U
则工人节点的总体收益函数
3)当信息存在不对称的情况时,任务发布者设计的合同需要同时满足个人理性约束和激励兼容性。
定义1:个人理性约束:每个工人节点同意参与联邦学习任务的条件是完成该任务后收益是非负的,表示如下:
定义2:激励兼容性约束:每个工人节点获得最大收益的条件是选择根据自身质量类型所设计的合同,表示如下:
最优合同的计算首先考虑在没有单调性约束情况下的松弛问题,再检查获得的解是否满足单调性条件。同时工人节点考虑使自己的收益最大化,使用最优的p
s.t.
4)具体迭代过程如下:
首先以任务发布者A的合同为定值,利用该定值条件推导出任务发布者B的最优合同;接着以任务发布者B的最优合同为定值,利用该条件重新推导出任务发布者A的最优合同;重复执行上述过程,直至任务发布者A和任务发布者B的最优合同均趋于收敛,此时便可计算出每类质量的工人节点所对应的最优化合同。该均衡条件同时满足了每份合同中的个人理性约束和激励兼容性约束,即多个任务发布者在竞争条件下保证非负收益的同时,还保证了每位工人节点都能选择符合自身条件的最优化合同,获得最优的收益。
本发明提出的合同不仅适用于更符合实际需求的多任务发布者的场景,同时满足个人理性约束和激励兼容性约束,能够平衡任务发布者和工人节点的关系,使系统中的两种角色均能获得预期收益,形成良性发展,达到激励工人节点加入联邦学习系统的目的。
(1)联邦学习系统中,多个任务发布者发布训练任务,并将预先设计好的合同提交至区块链中保存。
(2)系统中的工人节点通过区块查看多个任务发布者已经提交的不同的任务和合同,选择签署对于自身的最优合同。
(3)签署结束后,工人节点使用本地的数据集进行模型训练。
(4)工人节点将训练好的模型上传至区块链保存。
(5)任务发布者从区块链上获取已更新的模型,并在本地将所有的模型进行聚合。
(6)联邦学习任务结束后,任务发布者根据其与工人节点签署的合同支付给工人节点相应的报酬,并将支付记录保存在区块链上。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种神经网络模型训练方法及装置、文本标签确定方法及装置
- 面向多核处理器确定性重演的优化分段式内存竞争记录系统及其方法
- 面向多核处理器确定性重演的优化分段式内存竞争记录系统及其方法