基于多维感知和普适计算的智慧教学空间模式构建方法
文献发布时间:2023-06-19 18:32:25
技术领域
本发明涉及智慧教育技术领域,尤其涉及基于多维感知和普适计算的智慧教学空间模式构建方法。
背景技术
当前对于智慧教学空间的现有技术主要是从以下三个方向进行考虑的,1、教学设备的智能智慧化:此方向主要在于教学相关的硬件设备或者辅助系统的智能化,比如智慧课桌,智慧黑板等用于硬件外观或者功能结构的创新设计,重点是通过硬件设备外观或者使用流程的优化来实现教学硬件设备的智能化功能;2、授课过程中的智慧化融合:此方向主要在于授课中授课系统的智慧化提升,比如,一种基于多视窗的智慧教学方法及系统,主要是通过对于课中授课系统的定义,如,视窗的排布方式,功能的展示操作方式,以低成本和简单操作的方式实现多视窗智慧化教学,这类系统只是简单的通过功能窗口的排布和内容的分配来实现辅助老师授课内容的展示;3、教学过程信息的智慧化采集以及汇总:一种基于物联网的远程远端智慧教学系统,重点在于以物联网为基础,通过各种设备的数据采集以及融合部分行为分析,实现对于教学过程信息,比如考勤以及授课反馈等信息的采集和汇总,此类系统的重点在于借助各种物联网终端来完成教学过程信息的记录和总结,未建立各数据的关系模型,学生的反馈通常是通过简单的填表反馈类的收集,无法提供更多客观数据的反馈。
需要说明的是,在上述背景技术部分公开的信息只用于加强对本公开的背景的理解,因此可以包括不构成对本领域普通技术人员已知的现有技术的信息。
发明内容
本发明的目的在于克服现有技术的缺点,提供了一种基于多维感知和普适计算的智慧教学空间模式构建方法,解决了现有智慧教学相关技术存在的不足。
本发明的目的通过以下技术方案来实现:基于多维感知和普适计算的智慧教学空间模式构建方法,所述构建方法包括:
步骤S1、一阶实体维向二阶信息维传输数据,并进行信息汇聚处理服务、媒体流处理服务和媒体文件处理服务;
步骤S2、三阶结构维根据二阶信息维中的信息汇聚处理服务进行信息结构化处理服务,以及根据媒体流处理服务和媒体文件处理服务分别进行视频结构化处理服务、音频结构化处理服务和文本结构化处理服务;
步骤S3、四阶决策维根据三阶结构维中的信息结构化处理服务,以及视频结构化处理服务、音频结构化处理服务和文本结构化处理服务进行内容理解服务;
步骤S4、当四阶决策维中的决策模型管理服务接收到任务触发请求时,五阶虚实融合维中进行视音频图文渲染服务和虚实融合渲染服务;
步骤S5、六阶感知反馈维查看五阶虚实融合维中渲染服务结果,将反馈给三阶结构维中的反馈信息结构化处理服务进行处理,并将处理结果输入到四阶决策维中的决策模型管理服务中,对决策模型进行调整。
所述信息汇聚处理服务包括:用于汇聚智慧教学空间中认证定义的设备定时传送信息,通过MQTT协议将收集的信息按实体维的要素记录到数据库中,并通知到消息队列。
所述媒体流处理服务包括:用于将智慧教学空间中的实时流按照GMT时间处理成视频、音频和文本信息保存到存储器上,同时将元数据信息写入到数据库中,并通知到消息队列中。
所述媒体文件处理服务包括:将智慧教学空间中获取到的媒体文件处理呈抽帧图片、音频和文本信息保存到存储器上,同时将元数据信息写入到数据库中,并通知到消息队列中。
所述信息结构化处理服务包括:将信息汇聚处理服务记录到数据库中的实体维的要素,基于GMT时间,按照地点、人物、位置、声音和温度这些维度进行结构化整理归类保存到数据库中,并通知到消息队列中。
所述根据媒体流处理服务和媒体文件处理服务分别进行视频结构化处理服务、音频结构化处理服务和文本结构化处理服务包括:
基于人脸识别、表情识别、动作识别和文字识别这些结构化智能算法对视频和图片的结构化进行处理;基于语音识别和声纹识别对音频的结构化进行处理;基于关键词提取、词法分析和情感分析对文本的结构化进行处理;
按照时间、人物、位置、地点和动作这些维度进行结构化整理归类保存到数据库中,并通知到消息队列中。
所述步骤S3具体包括以下内容:
内容理解服务基于智能标签、语义分析和要素权重库算法建立数据库中的数据关系,提取关键词、关键人物、关键地点并映射出音视频内容和设备之间的管理关系。
所述步骤S4具体包括以下内容:
在智慧教学空间中设置多种规则输出决策模型,并通过决策模型管理服务进行管理,通过任务触发接口调用来触发决策模型管理服务输出不同的输出决策模型输出;
当决策模型管理服务接收到任务触发请求后,视音频图像渲染服务以及虚实融合渲染服务输出不同的内容到内容消费者消费。
所述视音频图文渲染服务包括:挑选多视角的实时流进行渲染合并,并将实时的图文数据渲染到视频画面上,最终输出实时流到终端进行播放;
和/或挑选多视角实时流片段,将关联的视频媒体文件、图片片段和输出的文本进行合并,最终生成视频文件到终端进行播放;
所述虚实融合渲染服务包括:挑选多视角的实时流片段,将关联的视频媒体文件片段,与预置的3D模型进行融合,最终生成在终端直接漫游的虚实融合场景。
所述输出决策模型包括:基于叙事维度的模型、基于人物维度的模型、基于课程核心要点维度的模型和基于热度维度模型。
本发明具有以下优点:一种基于多维感知和普适计算的智慧教学空间模式构建方法,通过多阶维度的感知以及普适计算,可以有效还原教学信息传播的场景,为师生带来更具真实感的虚实结合信息互动,同时通过多阶感知及决策反馈可以更好地实现在不同教学参与者的差异化需求,实现千人千面的信息构建。
附图说明
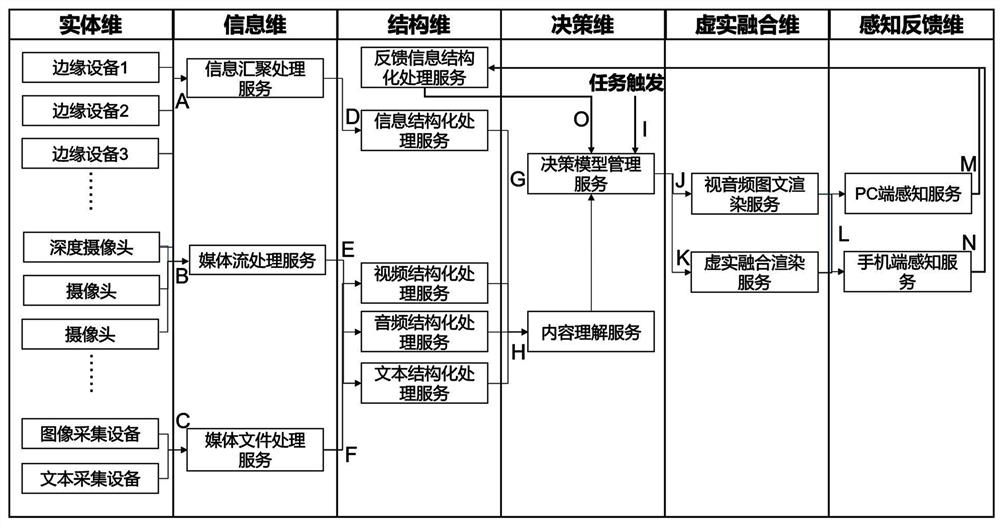
图1 为本发明的流程示意图。
具体实施方式
为使本申请实施例的目的、技术方案和优点更加清楚,下面将结合本申请实施例中附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本申请实施例的组件可以以各种不同的配置来布置和设计。因此,以下结合附图中提供的本申请的实施例的详细描述并非旨在限制要求保护的本申请的保护范围,而是仅仅表示本申请的选定实施例。基于本申请的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本申请保护的范围。下面结合附图对本发明做进一步的描述。
本发明具体涉及一种基于多维感知和普适计算的智慧教学空间模式构建方法,通过空间场内多阶维度的建立;基于深度神经网络实现多维元素的感知;采用普适计算的设计理念,即通过对于场内实体维的任何时间、任何地点、以及多种形式进行信息不间断的感知获取、计算以及反馈处理,寻找场内元素间的复杂关系,完成对于内容的理解;时间维度上形成了“情节”,空间维度上形成了新的“场景”,从而实现智慧空间的内容生产以及当前场映射的“次世代”新场景空间渲染与重建。
其中,定义的多阶维度包括:一阶实体维:场内可触及设备,如电子签到设备、电子手环、环境状态检测设备、定位设备等;二阶信息维:从实体化进阶为场内各信息化文件和流(媒体流);三阶结构维:将非结构化数据转换成结构化数据;四阶决策维:基于模型理解结构化数据的关系建立管理产生内容生成的决策;五阶虚实融合维:构建新的虚实结合的次世代空间(元宇宙);六阶感知反馈维:通过虚实多端的感知,实现数据反馈以及模型调整。
普适计算是一种设计理念,即计算无处不在,场内的实体维的各种输入,不管是流还是设备的输入的信息都在无时无刻不停的获取,而这些信息通过后续流程的计算输出,会最终实现不同的智慧空间内容的生成,举例如下:如教学空间内,当感知到老师通过边缘设备选取了2名同学进行辩论沟通,同时摄像头采集到对应的2名同学视频画面,通过以人物为维度的决策模型决策,最终会输出2个同学视频画面渲染到一个视频窗口里面,同时2个同学辩论的语音会通过语音识别实时转换成文字渲染到视频窗口里面。
如图1所示,具体包括以下内容:
步骤S1、首先并行进行A、B和C流程步骤;
步骤S2、其次并行进行D、E和F流程步骤;
步骤S3、然后并行进行G和H流程步骤;
步骤S4、当流程步骤I被触发时,则并行进行J和K流程步骤;
步骤S5、最后在并行进行M和N流程步骤后,触发进行O流程步骤。
进一步地,A流程步骤包括:信息汇聚处理服务主要用于汇聚智慧教学空间中的认证定义的设备定时传送信息,比如电子签到设备可提供每个教学空间参与者的签到信息(时间、地点、人物等);如定位设备可提供每个教学空间参与者的位置信息、时间信息等;如环境状态检测设备可提供教学空间的温度、湿度、环境声的变化。通过MQTT协议,信息汇聚服务收集信息,按实体维的要素记录到mysql数据库中,并通知到Kafka消息队列中。
B流程步骤包括:信息汇聚处理服务主要用于汇聚智慧教学空间中的认证定义的设备定时传送信息,比如电子签到设备可提供每个教学空间参与者的签到信息(时间、地点、人物等);如定位设备可提供每个教学空间参与者的位置信息、时间信息等;如环境状态检测设备可提供教学空间的温度、湿度、环境声的变化。通过MQTT协议,信息汇聚服务收集信息,按实体维的要素记录到mysql数据库中,并通知到Kafka消息队列中。
C流程步骤包括:媒体文件处理服务主要用于智慧教学空间中的媒体文件处理,其包括媒体文件输入端子,解封装模块、解码模块、抽帧模块、音频提取模块。可将智慧教学空间中获取到的媒体文件处理成抽帧图片、音频、文本信息保存到存储上同时将元数据信息写入到mysql数据库中,并通知到Kafka消息队列中。
D流程步骤包括:信息结构化处理服务将信息汇聚处理服务记录到mysql中的实体维的要素,基于GMT时间,按地点、人物(含陌生人)、位置、声音、温度等维度进行结构化整理归类保存到mysql数据库中,并通知到Kafka消息队列中。
E/F流程步骤包括:视频结构化处理服务基于人脸识别、表情识别、动作识别、文字识别等结构化智能算法实现对于视频和图片的结构化处理。音频结构化处理服务基于语音识别、声纹识别等结构化智能算法实现对于音频的结构化处理。文本结构化处理服务基于关键词提取、词法分析、情感分析等算法实现对于文本的结构化处理,按照时间、人物(含陌生人)、位置、地点、动作等维度行结构化整理归类保存到mysql数据库中,并通知到Kafka消息队列中。
G/H流程步骤包括:内容理解服务,基于智能标签、语义分析、要素权重库等算法实现对于mysql数据库中的数据关系建立,提取关键词、关键人物、关键地点并映射出音视频内容、设备之间的关联关系。
在D/E/F流程步骤中,信息结构化处理服务和视音频文本结构化处理服务已经对数据进行了结构化处理,基于智能标签和语义分析(含专业词库),比如这堂课是讲微积分的,内容理解服务汇聚提取出关键词“极限”,那么以“极限”为核心点,会在数据库中反推并记录,“极限”来源于结构维的哪些数据中出现了,再反推出来源于信息维中的哪些音视频数据以及对应的实体维的哪些设备,同时还能建立“极限”这个关键词由哪些人物在哪些时间点进行了讲述和讨论。
I/J/K流程步骤包括:在EISDMF智慧教学空间模式平台定义了多种规则输出决策模型,这些模型是由决策模型管理服务来进行管理的,输出决策模型包括:基于叙事维度的模型、基于人物维度的模型、基于课程核心要点维度的模型、基于热度维度模型。EISDMF智慧教学空间模式平台提供了任务触发接口,可通过接口调用来触发不同的输出决策模型输出,当收到任务触发后,视音频图文渲染服务以及虚实融合渲染服务可输出不同的内容来供空间的内容消费者消费;输出内容包括:
(1)、视音频图文渲染服务:挑选多视角的实时流进行渲染合并,并将一些实时的图文数据渲染到视频画面上最终输出实时流可供端来进行播放;
挑选多视角的实时流片段,关联的视频媒体文件、图片片段和输出的文本进行合并,最终生成视频文件可供端进行播放。
(2)、虚实融合渲染服务:挑选多视角的实时流片段,关联的视频媒体文件片段,与预置的3D模型进行融合,最终生成一个可供终端直接漫游的虚实融合场景。
L/M/N/O流程步骤包括:空间的内容消费者不仅是消费者,也是内容决策的贡献者。通过消费过程中视音频图片内容查看记录,时长以及虚实融合空间的驻留位置等信息,可收集反馈由反馈信息结构化处理服务进行处理,并作为输入因子加权给输出决策模型,比如通过消费者在播放点击情况来加权基于课程核心要点维度的模型中的核心要素库等。
本发明可实现各种物联网终端来完成教学过程信息采集,同时还将空间内容的各种音视频图文数据进行了采集,并建立了关系,通过本模型方法,使智慧教学空间由单一的教与学的空间提升为教学内容的智能内容创造空间;通过教学空间消费者在消费过程中的数据采集来调整或者加权输出决策模型,师生由简单的授课者与学习方变成教学内容的提炼、汇总、关联的贡献方。
以上所述仅是本发明的优选实施方式,应当理解本发明并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文所述构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本发明的精神和范围,则都应在本发明所附权利要求的保护范围内。
- 一种基于抽象格结构的异步普适计算环境感知方法
- 一种基于抽象格结构的异步普适计算环境感知方法