基于横向联邦学习的大规模建筑能耗预测方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明属于建筑能耗预测技术领域,具体涉及一种基于横向联邦学习的大规模建筑能耗预测方法。
背景技术
现阶段建筑发展要求我们针对建筑能耗精准的预测来优化电网调配,帮助正能建筑更好的决策何时向电网买电卖电等操作。
发明内容
针对建筑能耗精准的预测来优化电网调配的问题,本发明的目的在于提供一种基于横向联邦学习的大规模建筑能耗预测方法。
为了实现以上技术目的,本发明采用如下技术方案:
一种基于横向联邦学习的大规模建筑能耗预测方法,包括以下步骤:
(1)各区域在本地获取建筑群的能耗数据和各种特征变量的每小时读表数据,组成数据集,并在本地进行训练计算不同模型的误差,对每个模型梯度信息进行掩盖,仅上传预测结果的误差信息到服务器;
(2)服务器根据误差大小进行加权平均后再把更新后的模型发送给各个区域;
(3)各区域在收到加权信息后更新各自的模型权值并通过误差损失函数再次评估预测精准度,与旧模型预测的结果进行对比。
进一步地,步骤(1)中针对每个不同的建筑,采集历史每小时用电量数据,按照3:1划分成训练集与测试集。
进一步地,步骤(1)中得到每个模型的误差信息,取每个误差信息的倒数代入如下公式:
进一步地,步骤(2)中所述模型包括先知模型、基于决策树算法的分布式梯度提升框架模型、极限梯度提升算法的组合模型中的一种或多种。
进一步地,所述先知模型为y(t)=g(t)+s(t)+h(t)+∈
式中t为时间;m为偏移量;K为增长率;δ为增长率的变化量;S
式中:p为时间序列的周期长度,N为周期数;a
式中:L为节假日个数,κ
进一步地,所述基于决策树算法的分布式梯度提升框架模型是绑定降低特征向量数量,采用直方图算法将特征变量离散化方便运算;在直方图处理的基础上采用抑制决策树生长深度的策略防止过拟合;接下来用单边梯度采样算法排除小梯度样本,具体为将分裂的特征值取绝对值后从大到小排序,选取最大值x
进一步地,所述的极限梯度提升算法的组合模型通过对弱分类器的集成,不断地拟合残差,优化损失函数和正则化项,提升预测精度。
进一步地,所述的极限梯度提升算法的组合模型是首先定义好损失函数,计算损失函数对每个样本预测值的导数,再根据倒数信息建立新的决策树,利用新的决策树预测样本值,最后循环创造决策树不断迭代拟合残差得到结果。
进一步地,步骤(2)中经过每一个区域该组合模型里各个小模型权值都会进行迭代更新,以适应最新数据。
进一步地,步骤(3)中各个模型的权值的计算方法为:
f
其中f
与现有技术相比,本发明具有以下优点:
(1)本发明解决了楼宇数据安全信息泄露的问题并提高了预测精度。
(2)本发明将集成学习的思路引入到联邦学习当中,避开了针对数据上传到云端的操作,同时缩短了预测时间。
(3)本发明能够高效准确地实现对楼宇的态势感知,对正能建筑和智能电网的调配起到一定的作用和技术支持。
(4)本发明能够对建筑能耗精准的预测来优化电网调配,帮助正能建筑更好的决策何时向电网买电卖电等操作。
附图说明
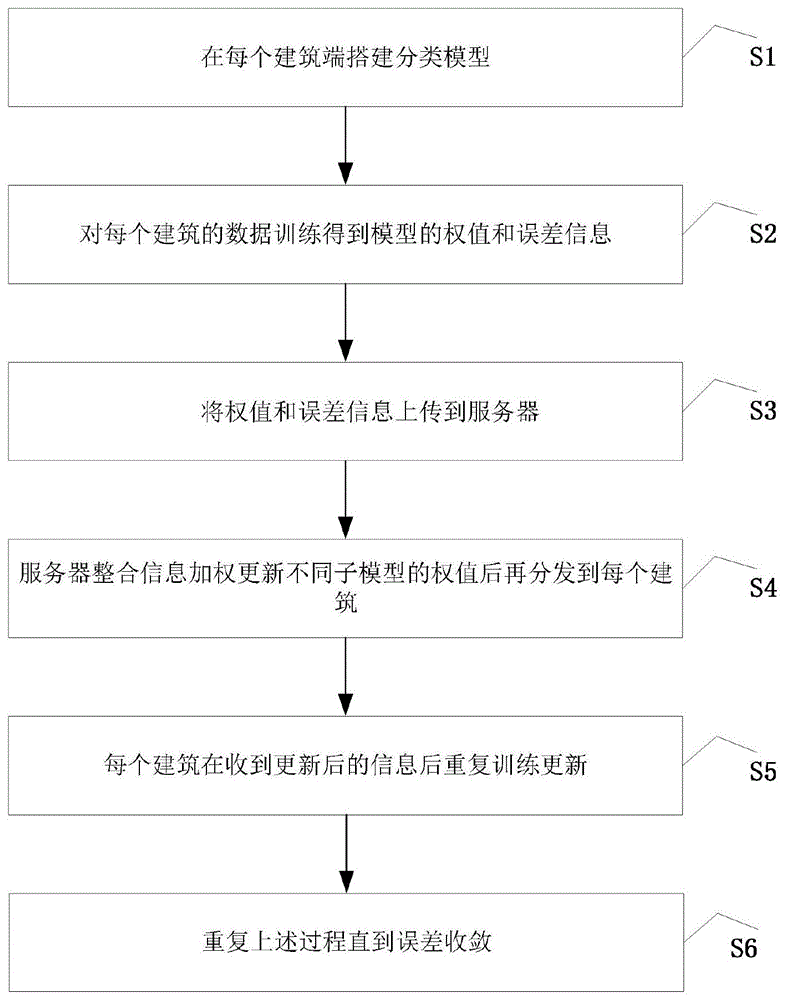
图1为本发明中联邦学习模型预测方法流程图。
图2为本发明中使用联邦学习迭代检测整体区域的归一化均方误差曲线与单个区域最优拟合结果应用到整体区域的方误差曲线对比图。
具体实施方式
以下结合附图和具体实例对本发明做具体的介绍。
在本发明实施例中,所述基于横向联邦学习的大规模建筑能耗预测方法,包括以下步骤:
(1)各区域在本地获取建筑群的能耗数据和各种特征变量(区域编号、建筑编号、区域用途、建筑面积m
(2)服务器根据误差大小进行加权平均后再把更新后的模型发送给各个区域;
(3)各区域在收到加权信息后更新各自的模型权值并通过误差损失函数再次评估预测精准度,与旧模型预测的结果进行对比。
下面通过更具体实施例加以说明。
如图1所示为本发明的一种基于横向联邦学习的大规模建筑能耗预测方法流程图,本发明用于对大规模建筑群的用电量预测。在本发明中,基于横向联邦学习的大规模建筑能耗预测方法包含多个子模型、多个建筑群和云端服务器。
具体而言,基于横向联邦学习的大规模建筑能耗预测方法包含以下步骤:
S1:针对每个不同的建筑,采集历史每小时用电量数据,按照3:1划分成训练集与测试集。针对每个单体建筑进行深度学习模型的训练,所述模型包括先知(prophet)模型、基于决策树算法的分布式梯度提升框架(LightGBM)模型、长短期记忆网络(LSTM)模型、极限梯度提升(XGBoost)算法的组合模型中的一种或多种。经过每一个区域该组合模型里各个小模型权值都会进行迭代更新,以适应最新数据。
所述先知(prophet)模型为y(t)=g(t)+s(t)+h(t)+∈
/>
式中t为时间;m为偏移量;K为增长率;δ为增长率的变化量;S
式中:p为时间序列的周期长度,N为周期数;a
式中:L为节假日个数,κ
所述基于决策树算法的分布式梯度提升框架(LightGBM)模型是绑定降低特征向量数量,采用直方图算法将特征变量离散化方便运算;在直方图处理的基础上采用抑制决策树生长深度的策略防止过拟合;接下来用单边梯度采样算法排除小梯度样本,具体为将分裂的特征值取绝对值后从大到小排序,选取最大值x
所述的极限梯度提升(XGBoost)算法的组合模型通过对弱分类器的集成,不断地拟合残差,优化损失函数和正则化项,提升预测精度。首先定义好损失函数,计算损失函数对每个样本预测值的导数,再根据倒数信息建立新的决策树,利用新的决策树预测样本值,最后循环创造决策树不断迭代拟合残差得到结果。
S2:得到每个模型的误差信息,取每个误差信息的倒数代入如下公式:
S3:每个不同的单体建筑在训练之后将权值信息和误差信息依次上传到云端服务器。
S4:服务器整合不同建筑不同模型的误差与权值信息,通过如下公式:
各个模型的权值的计算方法为:
f
/>
其中f
S5:每个建筑根据新得到的权值数据后重复训练更新。
S6:重复上述过程直到误差收敛,使得最后得到的模型具有更强的泛化能力,以适应不用功能区域的建筑群用电量预测,最终得到预测结果如图2所示,基于横向联邦学习的大规模建筑群用电量预测模型可以高效准确地实现对楼宇的态势感知,对正能建筑和智能电网的调配起到一定的作用和技术支持。
以上显示和描述了本发明的基本原理、主要特征和优点。本行业的技术人员应该了解,上述实施例不以任何形式限制本发明,凡采用等同替换或等效变换的方式所获得的技术方案,均落在本发明的保护范围内。
- 预测方法、纵向联邦学习和横向联邦学习的模型训练方法
- 一种基于横向联邦学习的文本预测方法及装置