基于Inception拓展网络的图像识别方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及基于Inception拓展网络的图像识别方法。
背景技术
卷积神经网络发展历程中,涌现出大量优秀的方法,其中Inception是一系列较为经典的卷积神经网络结构,在分类任务上都获得了较好的成绩。
Inception系列结构
在卷积神经网络发展中,研究者们意识到更深的网络可以获得更高的分类精度,如VGG
除了上述经典方法,近年来也有其它一些对Inception结构进行改进的方法。如Residuals Inception(RI)
轻量化神经网络
轻量化神经网络在保证精度的前提下,大幅度节约了参数量。其节约参数量的重要方法为:使用权重尽可能稀疏的卷积方式代替高密集度连接的传统方式。比如深度可分离卷积
还有就是通过优化轻量化网络的结构来提升分类精度,MobileNeXt
综上,对于Inception,研究者们在卷积核尺寸、卷积方式以及层间连接方式等方面做出了一些改进,但是未发现有对Inception深度和宽度进行拓展,以及拓展结构轻量化的研究。
发明内容
本发明的目的是为了解决经典的Inception基本模块深度及宽度不足而引起的分类精度受限问题,而提出基于Inception拓展网络的图像识别方法。
基于Inception拓展网络的图像识别方法具体过程为:
一、建立Inception拓展网络,基于训练集获得训练好的Inception拓展网络;
二、将待测图像输入训练好的Inception拓展网络,完成对待测图像的分类;
所述Inception拓展网络依次包括输入层、第一卷积单元、第二卷积单元、第三卷积单元、第四卷积单元、第五卷积单元、全局平均池化层、Dropout层、全连接层;
所述第一卷积单元依次包括Inception拓展结构、最大池化层;
所述第二卷积单元依次包括Inception拓展结构、最大池化层;
所述第三卷积单元依次包括Inception拓展结构、最大池化层;
所述第四卷积单元依次包括Inception拓展结构、最大池化层;
所述第五卷积单元依次包括Inception拓展结构、最大池化层;
所述Inception拓展结构包括第一卷积层、第一池化层、第二卷积层、Inception拓展单元;
输入特征依次输入第一卷积层、第一池化层和Inception拓展单元;
第一池化层输出特征输入第二卷积层;
将第一卷积层输出特征、第二卷积层输出特征和Inception拓展单元输出特征进行拼接,获得结构的输出特征。
本发明的有益效果为:
本发明通过对结构改进和应用稀疏连接,实现较低参数量代价拓展Inception结构的深度和宽度以增强其对特征的提取能力,继而提升模型分类精度。
本发明的目的是为了进一步挖掘Inception结构的性能。通过拓展经典的Inception-moduleA的深度和宽度以增强其对特征的提取能力,使模型获得更高的分类精度,但该方法在获得更高分类精度的同时也付出了极大的参数代价;通过对结构改进,并应用逐通道卷积可以在保证分类精度的前提下,大幅度节约参数量。而提出了基于Inception的拓展网络的图像识别方法。
本发明以Inception-moduleA为基础,深入研究了网络深度与宽度对Inception性能的影响,并结合轻量化的思想,提出了三种层层迭代、逐步优化的拓展方法。在本发明中,先对Inception-moduleA进行更深和更宽的拓展,证明这样可以使模型获得更高的分类精度。然而,简单的拓展网络的深度和宽度将伴随巨大的参数量。因此,本发明对结构进行了进一步改进,并结合了网络轻量化的方法,本发明提出了一系列可行的拓展方法。本发明的主要贡献为:
(1)本发明提出了一种基础的拓展方法Inception-e;基于Inception-moduleA结构,首先提出基础的拓展方法,实验结果证明了加大Inception模块的深度和宽度对模型分类精度的提升是有益的。
(2)本发明提出了一种等效的拓展方法Eception。为了解决拓展带来的参数量增加的问题,本发明提出了Eception,该结构拥有等效于Inception-e的感受野及特征提取能力。相较Inception-e,Eception使用了更少的参数量,实现模型分类精度的提升。
(3)本发明提出了一种更轻量的拓展方法Lception。在Eception基础上,通过将Eception的普通卷积层交叉替换为逐通道卷积层,使得该层的权重变得稀疏,进而降低参数量。实验结果表明,Lception能在参数量几乎不变的情况下,有效提升网络的分类精度。
针对近年来,随着卷积神经网络的快速发展,研究者们提出了大量优秀的卷积神经网络方法,其中不乏基于经典方法进行的改进。基于Inception系列方法,Xception使用深度可分离卷积实现了轻量化,Inception-ResNet则引入残差连接提升训练的收敛速度。然而,这些方法均没有考虑扩大网络深度及宽度对Inception的影响这个问题,本发明深入研究了对Inception模块深度及宽度的拓展方法;首先提出第一种拓展方法——Inceptionexpand(Inception-e),该方法通过并联更多、更深的卷积分支来提高分类精度;为降低拓展带来的参数代价,提出了第二种拓展方法——Equivalent Inception-e(Eception),该结构有效减少了冗余的卷积层,在不降低特征提取能力的前提下,降低了拓展带来的参数量;此外,在Eception的基础上,提出了第三种拓展方法——Lightweight Eception(Lception),该结构交叉使用了逐通道卷积与普通卷积,进一步有效的降低了参数量,并提升了模型的分类精度。
本发明将提出的三种方法在Cifar10数据集和面部表情分类数据集RAF-DB、FERplus(FER+)上分别进行验证。实验结果表明,这些结构均能有效提升分类精度,其中Lception在实现分类精度提升的同时,参数量几乎不变。如在Cifar 10数据集上,Lception(rank=6)的准确率较Inception-module A提升了1.9%、较Inception-module B(n=3)提升了2.1%,Lception(rank=4)的准确率较Inception-moduleA提升了1.6%,且只多付出0.15M的参数量。在FERplus(FER+)数据集上,Eception(rank=6)的准确率较VGG-19提升了3%。这些实验结果充分证明了提出的方法的有效性。
附图说明
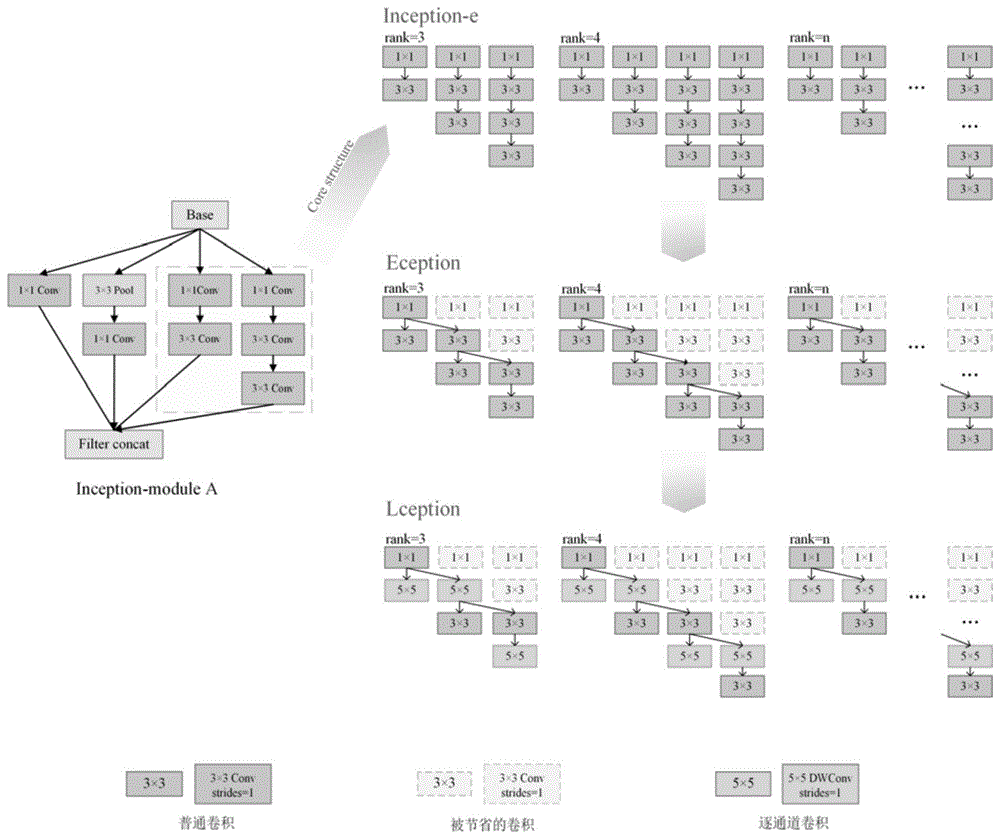
图1为Inception-e、Eception、Lception结构示意图,Base为该模块的结构起点,为本模块输入来自上一结构的输出张量;Filter concat为拼接张量操作,Core Structure为Inception-moduleA中框中部分,即本发明要进行改进的结构;rank为阶数;
图2为并联更多更深的卷积分支可以提取出更丰富的特征图;
图3为Eception对特征的提取能力等效于Inception-e对特征的提取能力的示意图,(a)为Inception-e对特征的提取能力示意图,(b)为Eception对特征的提取能力示意图;
图4为深度可分离卷积与本发明提出方法比较图,(a)深度可分离卷积使用逐点卷积实现通道间通信,(b)为交叉使用逐通道和普通卷积也可以实现通道间通信;
图5为FER+集与RAF-DB集示例图,FER
图6为Inception-e、Eception、Lception的实验结果比较图,(a)为三种方法的分类精度比较,(b)为三种方法的参数量比较,OA为总体准确率(Overall Accuracy,OA),Inception-moduleA为经典结构Inception-moduleA,rank为拓展结构阶数。
图7为RAF-DB数据集中不同类别图像的热力图;
图8为部分经典的Inception模块示意图,(a)为原始Inception-module模块示意图,(b)为Inception-module A模块示意图,(c)为Inception-module B模块示意图,(d)为Inception-module C模块示意图。
具体实施方式
具体实施方式一:本实施方式基于Inception拓展网络的图像识别方法具体过程为:
一、建立Inception拓展网络,基于训练集获得训练好的Inception拓展网络;
所述训练集为采集的带标签的图像;
二、将待测图像输入训练好的Inception拓展网络,完成对待测图像的分类;
所述Inception拓展网络依次包括输入层、第一卷积单元、第二卷积单元、第三卷积单元、第四卷积单元、第五卷积单元、全局平均池化层、Dropout层、全连接层;
所述第一卷积单元依次包括Inception拓展结构、最大池化层;
所述第二卷积单元依次包括Inception拓展结构、最大池化层;
所述第三卷积单元依次包括Inception拓展结构、最大池化层;
所述第四卷积单元依次包括Inception拓展结构、最大池化层;
所述第五卷积单元依次包括Inception拓展结构、最大池化层;
所述Inception拓展结构包括第一卷积层、第一池化层、第二卷积层、Inception拓展单元;
输入特征依次输入第一卷积层、第一池化层和Inception拓展单元;
第一池化层输出特征输入第二卷积层;
将第一卷积层输出特征、第二卷积层输出特征和Inception拓展单元输出特征进行拼接,获得Inception结构输出特征。
具体实施方式二:本实施方式与具体实施方式一不同的是,所述Inception拓展单元为Inception-e模型、Eception模型或Lception模型;
所述Inception-e为基础的拓展方法;
所述Eception为等效的拓展方法;
所述Lception为轻量化的拓展方法。
具体实施方式三:本实施方式与具体实施方式一或二不同的是,所述Inception-e模型阶数rank为n;
rank为1时,Inception-e模型包括第一分支,第一分支依次为1×1卷积层、3×3卷积层;
rank为2时,Inception-e模型包括第一分支、第二分支,第一分支依次为1×1卷积层、3×3卷积层;第二分支依次为1×1卷积层、3×3卷积层、3×3卷积层;
rank为3时,Inception-e模型包括第一分支、第二分支、第三分支,第一分支依次为1×1卷积层、3×3卷积层;第二分支依次为1×1卷积层、3×3卷积层、3×3卷积层;第三分支依次为1×1卷积层、3×3卷积层、3×3卷积层、3×3卷积层;
rank为4时,Inception-e模型包括第一分支、第二分支、第三分支、第四分支,第一分支依次为1×1卷积层、3×3卷积层;第二分支依次为1×1卷积层、3×3卷积层、3×3卷积层;第三分支依次为1×1卷积层、3×3卷积层、3×3卷积层、3×3卷积层;第四分支依次为1×1卷积层、3×3卷积层、3×3卷积层、3×3卷积层、3×3卷积层;
rank为n时,Inception-e模型包括第一分支至第n分支,第一分支依次为1×1卷积层、3×3卷积层;第n分支依次为1×1卷积层、n个3×3卷积层。
其它步骤及参数与具体实施方式一或二相同。
具体实施方式四:本实施方式与具体实施方式一或二不同的是,所述Eception模型阶数rank为n;
rank为1时,Eception模型包括第一分支,第一分支依次为1×1卷积层、3×3卷积层;
rank为2时,Eception模型包括第一分支、第二分支,第一分支依次为1×1卷积层、3×3卷积层;第二分支依次为1×1卷积层、3×3卷积层、3×3卷积层;
rank为3时,Eception模型包括第一分支、第二分支、第三分支;第一分支依次为1×1卷积层、3×3卷积层;第二分支依次为1×1卷积层、3×3卷积层、3×3卷积层;第三分支依次为1×1卷积层、3×3卷积层、3×3卷积层、3×3卷积层;
rank为4时,Eception模型包括第一分支、第二分支、第三分支、第四分支;第一分支依次为1×1卷积层、3×3卷积层;第二分支依次为1×1卷积层、3×3卷积层、3×3卷积层;第三分支依次为1×1卷积层、3×3卷积层、3×3卷积层、3×3卷积层;第四分支依次为1×1卷积层、3×3卷积层、3×3卷积层、3×3卷积层、3×3卷积层;
rank为n时,Eception模型包括第一分支至第n分支;第一分支依次为1×1卷积层、3×3卷积层;第二分支依次为1×1卷积层、3×3卷积层、3×3卷积层;第三分支依次为1×1卷积层、3×3卷积层、3×3卷积层、3×3卷积层;第四分支依次为1×1卷积层、3×3卷积层、3×3卷积层、3×3卷积层、3×3卷积层;第n分支依次为1×1卷积层、n个3×3卷积层;
Eception模型只保留每个分支的最后两层卷积层而舍弃其余卷积层,每个分支的倒数第二层卷积层则将前一相邻分支上一层卷积的输出张量作为输入。
其它步骤及参数与具体实施方式一或二相同。
具体实施方式五:本实施方式与具体实施方式四不同的是,所述Lception模型为取Eception模型为主体,只保留取Eception模型每个分支的最后两层卷积层而舍弃其余卷积层,每个分支的倒数第二层卷积层则将前一相邻分支上一层卷积的输出张量作为输入,将保留每个分支的最后两层卷积层的3×3卷积层交叉替换为5×5逐通道卷积层,获得Lception模型。
其它步骤及参数与具体实施方式四相同。
具体实施方式六:本实施方式与具体实施方式一至五之一不同的是,所述Lception模型阶数rank为n;
rank为1时,Lception模型包括第一分支,第一分支依次为1×1卷积层、5×5逐通道(depthwise convolution)卷积层;
rank为2时,Lception模型包括第一分支、第二分支,第一分支依次为1×1卷积层、5×5逐通道(depthwise convolution)卷积层;第二分支依次为1×1卷积层、5×5逐通道(depthwise convolution)卷积层、3×3卷积层;
rank为3时,Lception模型包括第一分支、第二分支、第三分支;第一分支依次为1×1卷积层、5×5逐通道(depthwise convolution)卷积层;第二分支依次为1×1卷积层、5×5逐通道(depthwise convolution)卷积层、3×3卷积层;第三分支依次为1×1卷积层、3×3卷积层、3×3卷积层、5×5逐通道(depthwise convolution)卷积层;
rank为4时,Lception模型包括第一分支、第二分支、第三分支、第四分支;第一分支依次为1×1卷积层、5×5逐通道(depthwise convolution)卷积层;第二分支依次为1×1卷积层、5×5逐通道(depthwise convolution)卷积层、3×3卷积层;第三分支依次为1×1卷积层、3×3卷积层、3×3卷积层、5×5逐通道(depthwise convolution)卷积层;第四分支依次为1×1卷积层、3×3卷积层、3×3卷积层、5×5逐通道(depthwise convolution)卷积层、3×3卷积层;
rank为5时,Lception模型包括第一分支、第二分支、第三分支、第四分支、第五分支;第一分支依次为1×1卷积层、5×5逐通道(depthwise convolution)卷积层;第二分支依次为1×1卷积层、5×5逐通道(depthwise convolution)卷积层、3×3卷积层;第三分支依次为1×1卷积层、3×3卷积层、3×3卷积层、5×5逐通道(depthwise convolution)卷积层;第四分支依次为1×1卷积层、3×3卷积层、3×3卷积层、5×5逐通道(depthwiseconvolution)卷积层、3×3卷积层;第五分支依次为1×1卷积层、3×3卷积层、3×3卷积层、3×3卷积层、3×3卷积层、5×5逐通道(depthwise convolution)卷积层;
Lception模型只保留每个分支的最后两层卷积层而舍弃其余卷积层,每个分支的倒数第二层卷积层则将前一相邻分支上一层卷积的输出张量作为输入;
将保留每个分支的最后两层卷积层的3×3卷积层交叉替换为5×5逐通道卷积层,获得Lception模型。
其它步骤及参数与具体实施方式一至五之一相同。
具体实施方式七:本实施方式与具体实施方式一至六之一不同的是,所述每个1×1卷积层和3×3卷积层后面接一个RELU激活函数。
其它步骤及参数与具体实施方式一至六之一相同。
具体实施方式八:本实施方式与具体实施方式一至七之一不同的是,所述每个5×5逐通道卷积层后面接一个h-swish激活函数。
其它步骤及参数与具体实施方式一至七之一相同。
具体实施方式九:本实施方式与具体实施方式一至八之一不同的是,所述第一卷积单元依次包括通道数channel=32的Inception拓展结构、最大池化层;
所述第二卷积单元依次包括通道数channel=64的Inception拓展结构、最大池化层;
所述第三卷积单元依次包括通道数channel=96的Inception拓展结构、最大池化层;
所述第四卷积单元依次包括通道数channel=128的Inception拓展结构、最大池化层;
所述第五卷积单元依次包括通道数channel=160的Inception拓展结构、最大池化层;
所述Inception拓展结构包括第一卷积层、第一池化层、第二卷积层、Inception拓展单元;
所述Inception拓展单元为Inception-e模型、Eception模型或Lception模型。
其它步骤及参数与具体实施方式一至八之一相同。
本发明针对Inception的拓展方法进行研究,提出了对网络结构扩展的新思路。通过对网络结构精心地设计,能够以较小的参数代价,换取原本需要极大参数量才能够获得的分类精度的提升。
具体来说,首先提出了通过并联更多、更深的卷积分支来提高分类精度的Inception-e结构。为了解决深度与宽度的提升导致参数量过大的问题,接着提出了一种Eception。然后,在Eception的基础上,通过将Eception结构中的普通卷积交叉替换为逐通道卷积,设计了一种Lception。实验结果表明,扩展后的网络结构能有效提高分类精度。选取提出网络中具有代表性的结构Eception(rank=6)、Lception(rank=6)和Lception(rank=4),与一些主流模型进行了对比,实验结果表明,与经典的Inception模块相比,我们提出的扩展结构可以在增加较少参数量的情况下,获得更高的分类精度。对于提出的Lception(rank=4),改进效果更为明显,可以在获得更高分类精度的同时,仅需要付出很少的参数代价。
本文提出的系列方法具有普适性,这些方法不单可以应用于Inception-moduleA,同样可应用到包括Inception-module B在内的其他类似结构上。本发明从新的角度进行卷积神经网络模型的改进,能够以较少的参数代价,有效提升网络的分类性能,具有较高研究意义和应用价值。
A.基础的拓展方法—Inception-e
在Inception-moduleA基础上并联更多、更深的卷积分支可以提升其对特征的提取能力,从而使模型获得更高的分类精度,拓展结构命名为Inception-e。
Original Inception module对输入张量使用卷积核尺寸不同的卷积层提取全局性不同的特征并融合,其中卷积核尺寸越大的卷积层抽取到越具有全局性(更抽象)的特征。Inception-moduleA则将卷积核尺寸较大的卷积层分解为多层卷积核尺寸较小的卷积层,在不降低结构对特征提取能力的前提下,有效节省参数。我们认为,在Inception-moduleA基础上,并联深度梯次增加的卷积分支,能使结构提取出全局性更丰富的特征。如图2所示,不同深度的卷积分支对特征的提取效果不同,较深的分支可以捕捉到更具有全局性的特征,较浅的分支则提取了更多的细节特征。
如图1所示,提出的方法只对Inception-moduleA的核心结构进行拓展,其它部分保持不变。Inception-e方法即在核心结构的基础上逐步并联深度更深的卷积分支。我们设置结构中的卷积核与池化核步长为1。以分支的阶数命名第n阶拓展结构为Inception-e(rank=n)。该方法提升了结构对特征的提取能力,使模型获得了更高的分类精度。
B.等效的拓展方法—Eception
为了降低拓展带来的参数量,提出Eception结构。该结构能取得等效于Inception-e对特征的提取效果,但节省了大量参数。
如图1所示,不同于Inception-e的卷积层以所在分支的上一层卷积层输出张量作为输入,Eception只保留分支的最后两层卷积层而舍弃其余卷积层,倒数第二层卷积层则将相邻分支上一层卷积的输出张量作为输入。此方法有效提升了卷积层的利用效率,减少了冗余的卷积层,从而抑制了拓展带来的参数量的暴涨。当核心结构输出张量的尺寸为W×H×(C×rank)时,设Incption-e的3×3卷积核数量为N
表1Inception-e和Eception使用的3×3卷积核数量比较
显然当rank≥3时,相较Inception-e,Eception可以有效节约参数量,且阶数越高节省比例越大。
在节约参数量的同时,Eception相较Inception-e结构上的改变,并不影响结构对特征的提取能力。如图3所示,以阶数为4时为例,当输入张量为X
X
X'
其中F为卷积操作,s为等效的感受野尺寸,//表示对张量进行拼接。文献[3]中提出一层卷积核尺寸较大的卷积层可以分解为多层卷积核尺寸较小的卷积层,因为分解前后的结构的感受野等效。例如两层卷积核尺寸为3×3卷积层与一层卷积核尺寸为5×5卷积层的感受野等效。s即依此原理获得,例如F
C.轻量化的拓展方法------Lception
交叉替换Eception中的普通卷积为逐通道卷积可以更进一步减少参数量,该结构我们称之为Lception。Lception以较少的参数量获得了非常接近Inception-e和Eception的分类精度。
如图1,本发明通过将Eception中的普通卷积层交叉替换为卷积核尺寸为5×5的逐通道卷积层,即获得了Lception。使用逐通道卷积使得该结构在Eception基础上进一步减少了参数量。引入h-swish
如图4所示,深度可分离卷积通过逐点卷积实现各通道的特征之间的通信;而本发明的方法,通过逐通道卷积与普通卷积交叉使用也同样实现了各通道的特征之间的通信,且由于保留了普通卷积,使得每单元该结构对特征的提取能力较深度可分离卷积更强。
采用以下实施例验证本发明的有益效果:
实施例一:
A.实验数据集
我们使用了三个数据集进行实验,包括Cifar10数据集,以及两个面部表情分类数据集RAF-DB
为验证所提模型的性能,主要采用Cifar 10进行验证实验。在Cifar10数据集中,训练集包括50000幅图像,测试集包括10000幅图像,共10类60000张32×32的彩色图像。为便于实验,将训练集与测试集图像均放大为96×96大小并归一化,并只对训练集做了数据增强。
FER+数据集,它在FER2013
RAF-DB数据集,包括单标签和双标签共29672幅图像,本文使用单标签数据,包括训练集12271幅与测试集3069幅,共7类15340幅100×100的彩色图像,这7类包括:1-惊奇,2-恐惧,3-厌恶,4-快乐,5-悲伤,6-愤怒,7-自然。为便于实验,将训练集与测试集图像均裁剪为96×96大小并归一化,并只对训练集做了数据增强。
B.实验网络模型及实验条件
如表2是使用Cifar 10集进行实验的网络模型。在分类器上,首先使用全局池化展平张量,然后进行Dropout正则化
表2使用Cifar 10集时的总体实验模型结构
关于实验条件,在Cifar 10集上:
优化器:SGD
训练批量:32
动量:0.9
正则化:对所有卷积层的权重做L2正则化。
在RAF-DB、FER+集上:
未使用动量加速。考虑到数据集较小,所以延长训练轮次。其余条件同上。
为了保证公平地进行比较,对在相同数据集上的实验,采用完全相同的训练条件。
C.对三种拓展方法的验证
为验证以上三种拓展方法,进行了一些实验。总体准确率(OverallAccuracy,OA)被采用作为模型分类精度的衡量标准,OA可表示为:
其中TP表示将正类预测为正类的数量,FN表示将正类预测为负类的数量,FP表示将负类预测为正类的数量,TN表示将负类预测为负类的数量。
在本部分中,采用Cifar 10数据集进行实验。图6给出了提出的三种方法在各阶下的分类精度、参数量的实验结果。
关于Inception-e结构。如图6中(a)可见,并联更多更深的卷积分支确实可以提升网络的分类精度。当Inception-e(rank=6)时,分类精度最高,准确率达到90.4%,较Inception-moduleA提升了2.1%。如图6中(b)可见,Inception-e结构能有效提升分类精度,但这种拓展伴随了巨大的参数量,且阶数越大参数量上涨越快,当阶数为6时甚至高达13.4M。
关于Eception结构。由图6中(a)可见,Eception的对特征的提取能力与Inception-e等效,Eception的分类精度伴随阶数的提升而提升。在阶数为6时,Eception的分类精度最高,准确率达到了90.2%,较Inception-moduleA提升了1.8%、较Inception-e最高准确率Inception-e(rank=6)仅低0.2%。由图6中(b)可见,与Inception-e相比,Eception有效降低了拓展增加的参数量。Eception(rank=6)的参数量为6.6M,为同阶的Inception-e(rank=6)的49%。
关于Lception结构。如图6中(a)可见,Lception的分类精度比其它两种方法的分类精度相近。Lception(rank=6)的准确率达到了90.2%,较Inception-moduleA提升了1.9%、较Inception-e(rank=6)仅低0.2%、较Eception(rank=6)基本一致。如图6中(b)可见,Lception的参数量更小。Lception(rank=6)的参数量为3.6M,仅为Inception-e(rank=6)的27%、Eception(rank=6)的55%。Lception(rank=4)较Inception-moduleA仅付出0.15M参数量就换取了1.5%的准确率提升。
综上所述,与经典的Inception-moduleA相比,提出的Inception-e,Eception,Lception,在分类精度上均具有明显优势。其中Eception通过结构的改进,有效降低了参数量,且获得了较高的总体准确率。Lception通过将Eception中的普通卷积交叉替换为逐通道卷积,大大减少了参数量,使网络更加轻量。此外,Lception通过增加卷积核尺寸,以提升结构对图像的感受野,更有效的利用了区域内的相关性,获得了更有区分度的图像特征,进而克服了因替换逐通道卷积层带来的卷积核数量减少而引起的分类精度的下降。
对于所提出的三种模型结构,在Cifar 10集上进行的验证实验。实验结果表明,三种方法均有效提升了分类精度,所提出的Lception能在参数量最小的情况下,获得近似于Inception-e和Eception的分类精度,这充分证明了该方法的有效性。
D.Grad-CAM可视化分析
为了更直观的说明不同拓展方式对网络性能的影响,我们在RAF-DB中选取了7类7幅图像,采用Grad-CAM
热力图颜色反映了网络对该区域的关注程度,颜色越深则表示神经网络对该区域越关注。由可视化结果可见,与Inception-moduleA经典结构相比,我们提出的三种拓展方法关注到了更大的范围和更丰富的特征。这进一步证明了提出的扩展方法的有效性。
E.与更多方法的比较
为进一步验证拓展结构的性能,选取Lception(rank=4)、Lception(rank=6)和Eception(rank=6)与部分经典网络结构、轻量化网络,以及其它面部表情分类方法进行对比,实验比较结果见表3。
表3对比实验结果(a)Cifar10数据集的实验结果
表3中的*表示该结果由我们进行实验得出,是在与本文提出的方法相同的实验环境下进行的。为了更严谨地比较这些方法,对于Original Inception module、Inception-module A和Inception-module B,在Cifar10集上的实验,我们将它们作为如表2所示总体结构中的Classical Inception module模块进行实验。在FER+上的实验结构类似表2,在其基础上做了适应于数据集的改变。需要说明,我们的实验均使用了批量归一化操作。同时,引用参考文献[31]的复现结果,来比较一些经典网络和轻量级网络在FER+数据集上的性能。
由表3中(a)可见,在Cifar10数据集上,Lception(rank=4)的总体准确率为89.9%、Lception(rank=6)的总体准确率为90.2%。相比于Original Inception module,两个模型分别提高了1.4%、1.7%;相比于Inception-module A,分别提高了1.6%、1.9%;相比于Inception-module B(n=3),分别提高了1.8%、2.1%。其中,相较OriginalInception module、Inception-moduleA和Inception-module B(n=3),Lception(rank=4)只付出了较少的参数量代价就获得了较大的分类精度提升。
由表3中(b)可见,在FER+数据集上,Lception(rank=4)的总体准确率为86.7%、Eception(rank=6)的总体准确率为87.4%。相比Original Inception module、Inception-module A、Inception-module B(n=3)有不同程度的提升。相比于其它经典结构VGG-13、VGG-19,Lception(rank=4)、Eception(rank=6)使用更少的参数量获得了更高的分类精度。比如在FER+集上,Lception(rank=4)的参数量仅是VGG-19的6.5%,但准确率高2.3%,优势显著。相比于轻量化网络Mobilenet v1
与其它基于神经网络的面部表情分类方法相比,本发明提出的Eception和Lception方法也表现出了优势。SHCNN
综上,与Original Inception module、Inception-moduleA、Inception-module B的对比,证明了本发明提出的拓展方法,能有效提升Inception结构的性能,同时只付出较少的参数代价。相比于一些经典结构、轻量级结构以及其它方法,提出的Eception与Lception结构可以在分类任务上获得更高的分类性能。
参考文献
[1]K.Simonyan andA.Zisserman,“Very deep convolutional networksforlarge-scale imagerecognition,”arXiv,
Apr.10,2015.Accessed:Sep.20,2022.[Online].Available:http://arxiv.org/abs/1409.1556
[2]C.Szegedy et al.,“Going deeper with convolutions,”in 2015IEEEConference on Computer Vision andPatternRecognition(CVPR),Boston,MA,USA,Jun.2015,pp.1–9.doi:10.1109/CVPR.2015.7298594.
[3]C.Szegedy,V.Vanhoucke,S.Ioffe,J.Shlens,and Z.Wojna,“Rethinking theinception architecture forcomputervision,”in2016IEEE Conference on ComputerVision andPatternRecognition(CVPR),LasVegas,
NV,USA,Jun.2016,pp.2818–2826.doi:10.1109/CVPR.2016.308.
[4]S.Ioffe and C.Szegedy,“Batch normalization:Accelerating deepnetwork training by reducing internalcovariate shift,”arXiv,Mar.02,2015.Accessed:Sep.20,2022.[Online].Available:
http://arxiv.org/abs/1502.03167
[5]C.Szegedy,S.Ioffe,V.Vanhoucke,and A.A.Alemi,“Inception-v4,inception-resnet and the impact ofresidual connections on learning,”inThirty-firstAAAIconference on artificial intelligence,NewYork,2017,
pp.4278–4284.
[6]K.He,X.Zhang,S.Ren and J.Sun,“Deep Residual Learning for ImageRecognition,”in 2016IEEEConference on Computer Vision and Pattern Recognition(CVPR),2016,pp.770-778,doi:
10.1109/CVPR.2016.90.
[7]X.Zhang,S.Huang,X.Zhang,W.Wang,Q.Wang and D.Yang,“ResidualInception:A New ModuleCombining Modified Residual with Inception to ImproveNetwork Performance,”in 201825th IEEEInternational Conference on ImageProcessing(ICIP),2018,pp.3039-3043,doi:
10.1109/ICIP.2018.8451515.
[8]M.Z.Alom,M.Hasan,C.Yakopcic,and T.M.Taha,“Inception recurrentconvolutional neural network forobjectrecognition,”arXivpreprintarXiv:1704.07709,2017.doi:10.48550/arXiv.1704.07709.
[9]L.Xie and C.Huang,“AResidualNetwork ofWater SceneRecognitionBasedonOptimized InceptionModuleand Convolutional Block AttentionModule,”in 20196th International Conference on Systems andInformatics(ICSAI),2019,pp.1174-1178,doi:10.1109/ICSAI48974.2019.9010503.
[10]S.Woo,J.Park,J.-Y.Lee,and I.S.Kweon,“CBAM:Convolutional blockattention module,”in Proc.Eur.
Conf.Comput.Vision(ECCV2018),Springer,Munich,Germany,2018,pp.3-19.
[11]F.Chen,J.Wei,B.Xue,and M.Zhang,“Feature fusion and kernelselective in Inception-v4 network,”Appl.
Soft Comput.,vol.119,pp.108582,2022.doi:10.1016/j.asoc.2022.108582.
[12]X.Li,W.Wang,X.Hu,and J.Yang,“Selective kernel networks,”in 2019IEEE/CVF Conference onComputer Vision andPattern Recognition(CVPR),IEEE,LongBeach,CA,
[13]A.Krizhevsky,I.Sutskever,and G.E.Hinton,“Imagenet classificationwith deep convolutional neuralnetworks,”Communications oftheACM,vol.60,no.6,pp.84–90,2017.
[14]X.Zhang,X.Zhou,M.Lin,and J.Sun,“ShuffleNet:An extremely efficientconvolutional neural network formobile devices,”in 2018 IEEE/CVF Conferenceon Computer Vision and Pattern Recognition(CVPR),SaltLake City,UT,Jun.2018,pp.6848–6856.doi:10.1109/CVPR.2018.00716.
[15]F.Chollet,“Xception:Deep learning with depthwise separableconvolutions,”in 2017 IEEE Conference onComputer Vision and PatternRecognition(CVPR),Honolulu,HI,Jul.2017,pp.1800–1807.doi:
10.1109/CVPR.2017.195.
[16]K.Han,Y.Wang,Q.Tian,J.Guo,C.Xu and C.Xu,“GhostNet:More FeaturesFrom Cheap Operations,”in
2020IEEE/CVF Conference on Computer Vision andPattern Recognition(CVPR),2020,pp.1577-1586,doi:
10.1109/CVPR42600.2020.00165.
[17]D.Zhou,Q.Hou,Y.Chen,J.Feng,and S.Yan,“Rethinking bottleneckstructure for efficient mobile networkdesign,”in Proc.Eur.Conf.Comput.Vision(ECCV2020),Springer,Glasgow,UK,2020,pp.680-697.
[18]M.Sandler,A.Howard,M.Zhu,A.Zhmoginov,and L.C.Chen,“MobileNetV2:Inverted residuals and linearbottlenecks.”arXiv,Mar.21,2019.Accessed:Sep.20,2022.[Online].Available:
http://arxiv.org/abs/1801.04381
[19]N.Ma,X.Zhang,J.Huang,and J.Sun,“Weightnet:Revisiting the designspace ofweight networks,”in Proc.
Eur.Conf.Comput.Vision(ECCV2020),Springer,Glasgow,UK,2020,pp.776-792.
[20]J.Hu,L.Shen,S.Albanie,G.Sun and E.Wu,“Squeeze-and-ExcitationNetworks,”in IEEE Transactions onPattern Analysis and Machine Intelligence,vol.42,no.8,pp.2011-2023,1 Aug.2020,doi:
10.1109/TPAMI.2019.2913372.
[21]M.Tan,and Q.Le,“Efficientnet:Rethinking model scaling forconvolutional neural networks,”in Proc.36thInt.Conf.Mach.Learn.,PMLR,2019,pp.6105-6114.
[22]A Howard,M Sandler et al,“Searching for mobilenetv3,”in IEEE/CVFInternational Conference on ComputerVision(ICCV),2019,pp.1314-1324
[23]S.Li and W.Deng,“Reliable crowdsourcing and deep locality-preserving learning for unconstrained facialexpression recognition,”IEEETrans Image Process,vol.28,no.1,pp.356–370,Jan.2019,doi:
10.1109/TIP.2018.2868382.
[24]E.Barsoum,C.Zhang,C.C.Ferrer,and Z.Zhang,“Training deep networksfor facial expression recognitionwith crowd-sourced label distribution,”inProceedings of the 18th ACM International Conference onMultimodalInteraction,Tokyo Japan,Oct.2016,pp.279–283.doi:10.1145/2993148.2993165.
[25]I.J.Goodfellow et al.,“Challenges in representation learning:Areport on three machine learning contests,”inInternational conference onneural informationprocessing,New York,2013,pp.117–124.
[26]N.Srivastava,G.Hinton,A.Krizhevsky,I.Sutskever,andR.Salakhutdinov,“Dropout:a simple way toprevent neural networks fromoverfitting,”J.Mach.Learn.Res.,vol.15,pp.1929-1958,2014.
[27]L.Bottou,"Stochastic gradient descent tricks",in Neural Networks:Tricks ofthe Trade,Montavon,G.,Orr,
G.B.,and Müller,K.R.,Ed.Berlin,Heidelberg:Springer,2012,pp.421-436.
[28]R.R.Selvaraju,M.Cogswell,A.Das,R.Vedantam,D.Parikh,and D.Batra,“Grad-CAM:visualexplanations from deep networks via gradient-basedlocalization,”in 2017IEEEInternational Conference onComputer Vision(ICCV),Venice,Oct.2017,pp.618–626.doi:10.1109/ICCV.2017.74.
[29]A.G.Howard,M.Zhu,B.Chen,D.Kalenichenko,W.Wang,et al.,“Mobilenets:Efficient convolutionalneural networks for mobile vision applications,”arXivpreprint arXiv:1704.04861,2017.
doi:10.48550/arXiv.1704.04861.
[30]N.Ma,X.Zhang,H.-T.Zheng,and J.Sun,“ShuffleNet V2:Practicalguidelines for efficient cnn architecturedesign,”in Computer Vision–ECCV2018,vol.11218,V.Ferrari,M.Hebert,C.Sminchisescu,andY.Weiss,
Eds.Cham:Springer International Publishing,2018,pp.122–138.doi:10.1007/978-3-030-01264-9_8.
[31]G.Zhao,H.Yang,and M.Yu,“Expression recognition method based on alightweight convolutional neuralnetwork,”IEEEAccess,vol.8,pp.38528–38537,2020.
[32]S.Miao,H.Xu,Z.Han,and Y.Zhu,“Recognizing facial expressions usinga shallow convolutional neuralnetwork,”IEEEAccess,vol.7,pp.78000–78011,2019.
[33]H.Siqueira,S.Magg,and S.Wermter,“Efficient facial featurelearning with wide ensemble-basedconvolutional neural networks,”AAAI,vol.34,no.4,pp.5800–5809,Apr.2020,doi:
10.1609/aaai.v34i04.6037.
本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
- 一种基于Inception模型的深度卷积神经网络图像去噪方法
- 一种基于Inception神经网络模型的掌静脉图像识别方法、装置及存储介质
- 一种改进Inception-v3网络的手势图像识别方法