挥手检测方法及装置
文献发布时间:2024-04-18 19:52:40
技术领域
本发明涉及挥手检测技术领域,尤其涉及一种挥手检测方法及装置。
背景技术
挥手是人们日常生活中广泛使用的一种交流方式,具有很强的表意功能。随着计算机技术的发展,挥手检测以其操作自然、便捷、非接触等特点逐步被应用于家电控制、互动展示、游戏控制、家用及商用摄像机的拨号、报警以及无人机搜救等场景。
图1为一种挥手检测方法的流程图。参阅图1,视频流序列在视频处理器中被处理为一系列按时间顺序排列的单帧图片,每帧图片按时间顺序依次送入行人检测装置进行行人检测。行人检测装置通过选择方向梯度直方图特征提取方法对正负样本进行特征提取,而后使用SVM分类器进行训练。送入行人检测装置的图片被统一归一化为相同的图像大小(例如大小为108×36像素)进行检测,检测完成的图片按照检测框置信度进行排序,得分大于0.7的检测框作为行人检测框(若图中有多个候选的行人检测框,则取置信度最高的行人检测框作为初次挥手检测的对象)。确定完行人检测框后,在所述行人检测窗的左上方设置一个挥手检测窗口(大小为36×36像素),且所述挥手检测窗和所述行人检测窗的左顶点分别在x、y轴上相差12个像素。将图片中位于所述挥手检测窗外的区域内的所有像素值均置为0。从第n帧图像开始(n≥2),采用3帧差分进行第n帧图像的运动检测,计算公式如下。
D
其中,D
随后,使用大律法将D
然而,上述挥手判断方法是基于历史图像序列进行的,无法对实时视频进行挥手检测。且现有的挥手检测方法仅仅是单纯的进行挥手判断,挥手检测的灵敏度较低且存在误检的风险。微软Kinect体感游戏的挥手检测方法中,采用3D模型作为关键点模型,使预测的关键点更为精准和稳定,存在跳动的情况较少,从而提高了挥手检测的灵敏度。然而3D模型的参数量较大,不适用于硬件端的模型部署。
鉴于此,需要一种方法在实时视频序列中持续性地进行多人挥手检测,并在提高检测灵敏度的同时降低误检率。
发明内容
本发明的目的在于提供一种挥手检测方法及装置,在实时视频序列中持续性地进行多人挥手检测,提高了检测灵敏度,降低了误检率。
为了达到上述目的,本发明提供了一种挥手检测方法,包括:
获取实时视频序列,所述实时视频序列包括连续的多帧待测图像;
逐帧对所述待测图像进行处理,用人形检测框将所述待测图像中的若干个人像分别框选出来;
将前后帧待测图像中的人形检测框进行匹配,使前后帧待测图像中用于表示相同人像的人形检测框相互对应;
获取所述人形检测框中的多个人体关键点,所述人体关键点用于表征人像的姿态;以及,
在连续的设定帧数内的所述待测图像中,根据所选取的人形检测框中人体关键点的位置变化情况判断相应的人像是否存在挥手运动。
可选的,采用简化VGG网络模型逐帧对所述待测图像进行处理,处理过程包括:
经过两层64×3×3的卷积核卷积两次,再经过RELU激活和最大池化层,使图像的输出尺寸变化为224×224×64;
经过三层128×3×3的卷积核卷积三次,再经过RELU激活和最大池化层,使图像的输出尺寸变化为112×112×128;以及,
经过三层512×3×3的卷积核卷积三次,再经过RELU激活和最大池化层,使图像的输出尺寸变化为56×56×512。
可选的,所述简化VGG网络模型的损失函数包括分类损失函数和定位损失函数,其中,所述分类损失函数为:
其中,N代表输入所述简化VGG网络模型的训练样本的个数,y
所述定位损失函数为:
其中,x为一个行向量,x=[Δx,Δy,Δw,Δh],Δx和Δy分别代表所述简化VGG网络模型的训练集中实际的人形检测框的位置坐标和模型预测的人形检测框的位置坐标在不同方向上的差值,Δw代表所述训练集中实际的人形检测框的宽度和模型预测的人形检测框的宽度的差值,Δh代表所述训练集中实际的人形检测框的高度和模型预测的人形检测框的高度的差值。
可选的,根据所述简化VGG网络模型输出的人形检测框的位置与所述人形检测框的实际位置之间的交并比判断所述人形检测框的位置是否准确。
可选的,将前后帧待测图像中的人形检测框进行匹配,使前后帧待测图像中用于表示相同人像的人形检测框相互对应的过程包括:
在当前帧待测图像中选取一人形检测框,根据所选取的所述人形检测框的位置获取下一帧待测图像中所选取的人形检测框的预测位置;
分别获取下一帧待测图像中所有待匹配的人形检测框的实际位置与所述预测位置的交并比,若所有的交并比均小于一关联阈值,则所选取的人形检测框在下一帧待测图像中没有对应的人形检测框,否则,则所述交并比中最大值对应的待匹配的人形检测框与所选取的人形检测框对应同一个人像。
可选的,所述人体关键点包括手肘关键点、手腕关键点、脖子关键点、左肩膀关键点、右肩膀关键点、臀部关键点、膝盖关键点和脚踝关键点中的一种或多种。
可选的,采用改进vovnet网络模型获取所述人形检测框中的多个人体关键点,具体过程包括:
经过两层3×3×64的卷积核卷积两次和一层3×3×128的卷积核卷积两次,再经过最大池化层进行降采样,使图像的输出尺寸变化为112×112×128;
经过五层3×3×64的卷积核卷积五次,每次卷积的结果按照最后一个维度进行拼接,再经过一层1×1×128的卷积核卷积和步长为2的最大池化层输出,使图像的输出尺寸变化为56×56×128;
经过五层3×3×80的卷积核卷积五次,每次卷积的结果按照最后一个维度进行拼接,再经过一层1×1×256的卷积核卷积和步长为2的最大池化层输出,使图像的输出尺寸变化为28×28×256;
经过五层3×3×96的卷积核卷积五次,每次卷积的结果按照最后一个维度进行拼接,再经过一层1×1×384的卷积核卷积和步长为2的最大池化层输出,使图像的输出尺寸变化为14×14×384;
经过五层3×3×112的卷积核卷积五次,每次卷积的结果按照最后一个维度进行拼接,再经过一层1×1×512的卷积核卷积和步长为2的最大池化层输出,使图像的输出尺寸变化为7×7×512;以及,
经过7×7×26的卷积核和7×7×13的卷积核输出所述人体关键点的位置坐标和可见性。
可选的,所述改进vovnet网络模型的损失函数为:
其中,x为一个行向量,包括所述改进vovnet网络模型中所有的所述人体关键点的实际位置坐标与模型预测的位置坐标在不同方向上的差值。
可选的,所述改进vovnet网络模型的预测指标为:
/>
其中,p表示所述待测图像的人形检测框的序号,pi表示所述待测图像中第p个人形检测框中的人体关键点的序号,v
可选的,在连续的设定帧数内的所述待测图像中,根据所选取的人形检测框中人体关键点的位置变化情况判断相应的人像是否存在挥手运动的判断条件包括三个,其中,第一个判断条件为所述手腕关键点在竖直方向上是否持续性地高于所述手肘关键点;第二个判断条件为所述手腕关键点、所述手肘关键点以及所述左肩膀关键点(或所述右肩膀关键点)所形成的靠近人像身体内测的夹角是否在设定角度阈值内;第三个判断条件为所述手肘关键点和所述手腕关键点在水平方向上的位置是否随着时间的变化呈周期性运动;若三个所述判断条件均为是,则连续的设定帧数内的所述待测图像中存在挥手运动。
可选的,在采用所述判断条件进行判断之前,还包括,根据所选取的人形检测框中包含的人体关键点的种类和数量判断相对应的人像与摄像头的距离,并根据所述人像与摄像头的距离设置所述设定角度阈值。
相应地,本发明还提供一种挥手检测装置,采用所述挥手检测方法进行检测,包括:
人形检测模块,用于在输入的待测图像中的人形上设置人形检测框;
人形跟踪模块,包括运动估计单元、数据关联单元和跟踪目标的建立与销毁单元,其中,所述运动估计单元用于根据当前帧待测图像中所选取的人形检测框位置获取下一帧待测图像中所选取的人形检测框的预测位置,所述数据关联单元用于将所述预测位置与下一帧待测图像中所有待匹配的人形检测框的实际位置进行匹配,使前后帧待测图像中用于表示相同人像的人形检测框相互对应,所述跟踪目标的建立与销毁单元用于对出现在待测图像中的人像进行标记,以及将离开所述待测图像中的人像对应的标记销毁;
关键点检测模块,用于获取所述人形检测框中的人体关键点的位置坐标和可见性;
挥手检测模块,用于根据所选取的人形检测框中人体关键点的位置变化情况判断相应的人像是否存在挥手运动。
综上所述,本发明提供一种挥手检测方法及装置,对包含连续多帧待测图像的实时视频序列进行逐帧处理,用人形检测框将所述待测图像中的若干个人像分别框选出来;将前后帧待测图像中的人形检测框进行匹配,使前后帧待测图像中用于表示相同人像的人形检测框相互对应;获取所述人形检测框中的多个人体关键点,所述人体关键点用于表征人像的姿态;以及,在连续的设定帧数内的所述待测图像中,根据所选取的人形检测框中人体关键点的位置变化情况判断相应的人像是否存在挥手运动。本发明通过将同一人像在连续多帧待测图像中对应的多个人形检测框对应起来,实现了实时视频序列中持续性地多人挥手检测,提高了检测灵敏度,同时降低了误检率。
附图说明
图1为一种挥手检测方法的流程图;
图2为本发明一实施例提供的挥手检测方法的流程图;
图3为本发明一实施例提供的挥手检测方法中简化VGG网络模型的结构示意图;
图4为本发明一实施例提供的挥手检测方法中进行人形检测框的匹配过程示意图;
图5为本发明一实施例提供的挥手检测方法中改进vovnet网络模型的结构示意图;
图6为本发明一实施例提供的挥手检测方法中判断是否存在挥手运动的示意图;
图7为本发明一实施例提供的人脸检测装置的示意图;
其中,附图标记如下:
1-挥手检测装置;11-人形检测模块;12-人形跟踪模块;13-关键点检测模块;14-挥手检测模块。
具体实施方式
下面将结合示意图对本发明的具体实施方式进行更详细的描述。根据下列描述,本发明的优点和特征将更清楚。需说明的是,附图均采用非常简化的形式且均使用非精准的比例,仅用以方便、明晰地辅助说明本发明实施例的目的。
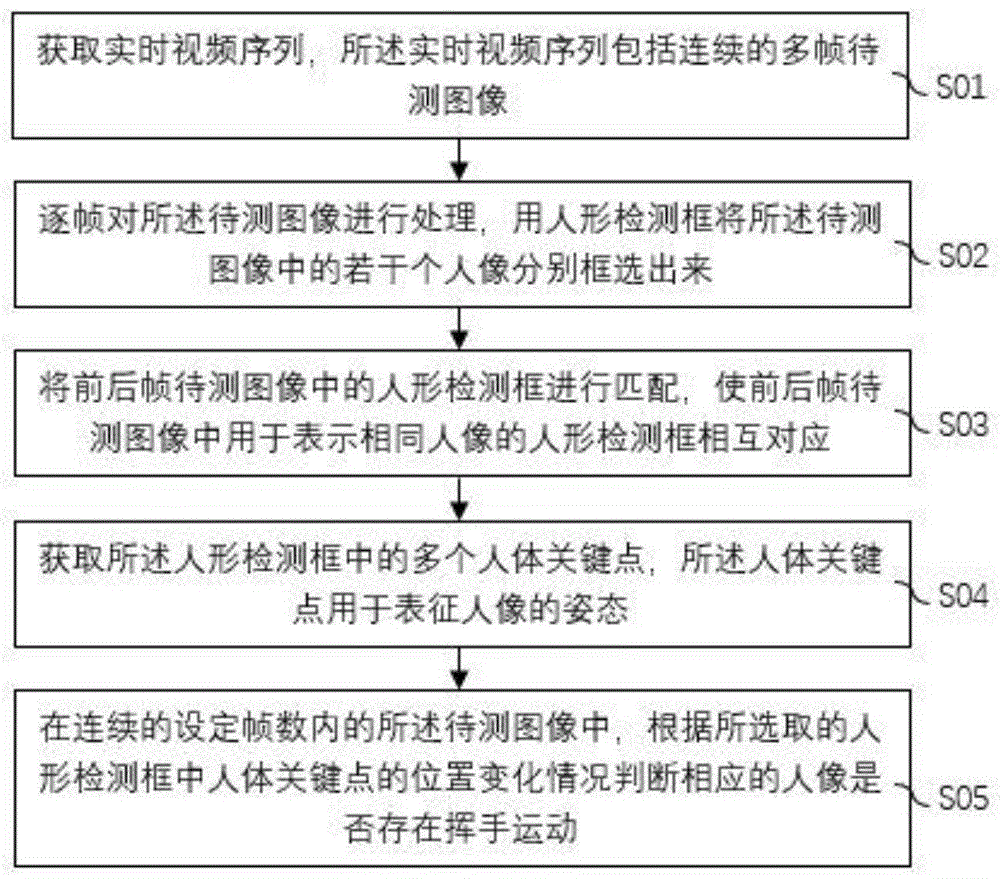
图2为本发明一实施例提供的挥手检测方法的流程图。参阅图2,本实施例所述的挥手检测方法包括:
步骤S01:获取实时视频序列,所述实时视频序列包括连续的多帧待测图像;
步骤S02:逐帧对所述待测图像进行处理,用人形检测框将所述待测图像中的若干个人像分别框选出来;
步骤S03:将前后帧待测图像中的人形检测框进行匹配,使前后帧待测图像中用于表示相同人像的人形检测框相互对应;
步骤S04:获取所述人形检测框中的多个人体关键点,所述人体关键点用于表征人像的姿态;以及,
步骤S05:在连续的设定帧数内的所述待测图像中,根据所选取的人形检测框中人体关键点的位置变化情况判断相应的人像是否存在挥手运动。
图3至图6为本发明一实施例提供的挥手检测方法中各个步骤对应的方法或示意图。下面结合图3至图6详细说明本实施例所述的挥手检测方法。
首先,执行步骤S01,获取实时视频序列,所述实时视频序列包括连续的多帧待测图像。本实施例中,所述待测图像为448×448×3的RGB图像,在本发明的其他实施例中,所述待测图像的尺寸可以根据实际情况进行调整,本发明对此不作限制。
接着,参阅图3,执行步骤S02,逐帧对所述待测图像进行处理,用人形检测框将所述待测图像中的若干个人像分别框选出来。
具体的,采用人形检测模型(即简化VGG网络模型)逐帧对所述待测图像进行处理,处理过程包括:经过两层64×3×3的卷积核卷积两次,再经过RELU激活和最大池化层降采样,使图像的输出尺寸变化为224×224×64;经过三层128×3×3的卷积核卷积三次,再经过RELU激活和最大池化层降采样,使图像的输出尺寸变化为112×112×128;以及,经过三层512×3×3的卷积核卷积三次,再经过RELU激活和最大池化层降采样,使图像的输出尺寸变化为56×56×512。需要说明的是,每次降采样后都会提升特征的通道数,最后整个网络结构会抽取出三层特征层用于后续人形检测框的生成,所述简化VGG网络模型最终输出一系列的大于一设定尺寸阈值的人像检测框的位置坐标(所述位置坐标为人形检测框的左上角点的位置坐标)和所述人形检测框的宽度和高度。
可选的,在采用所述简化VGG网络模型处理所述待测图像之前,还包括:输入448×448×3的RGB训练图像,经过所述简化VGG网络模型输出为一系列大于所述设定尺寸阈值的人形检测框的位置坐标(和所述人形检测框的宽度和高度。其中,所述训练图片是从大型图像处理数据集(例如Microsoft coco)中裁剪所得,通过对所述训练图像进行随机旋转、随机裁剪、随机遮挡及高斯模糊方法进行数据增广,增强了所述简化VGG网络模型的鲁棒性。
本实施例中,所述简化VGG网络模型的损失函数包括分类损失函数和定位损失函数,其中,所述分类损失函数为常见的交叉熵损失函数,即:
其中,N代表输入所述简化VGG网络模型的训练样本的个数,y
所述定位损失函数为:
其中,x为一个行向量,x=[Δx,Δy,Δw,Δh],Δx和Δy分别代表所述简化VGG网络模型的训练集中实际的人形检测框的位置坐标和模型预测的人形检测框的位置坐标在不同方向上的差值,Δw代表所述训练集中实际的人形检测框的宽度和模型预测的人形检测框的宽度的差值,Δh代表所述训练集中实际的人形检测框的高度和模型预测的人形检测框的高度的差值。
本实施例中,所述简化VGG网络模型的预测指标采用的是交并比(Interactionover Union,IoU)计算,根据所述简化VGG网络模型输出的人形检测框的位置与所述人形检测框的实际位置之间的交并比判断所述人形检测框的位置是否准确。例如,若所述简化VGG网络模型输出的人形检测框的位置与所述人形检测框的实际位置之间的交并比大于一交并比阈值(例如为0.7),则判断若所述简化VGG网络模型输出的人形检测框的位置准确。
随后,参阅图4,执行步骤S03,将前后帧待测图像中的人形检测框进行匹配,使前后帧待测图像中用于表示相同人像的人形检测框相互对应。
具体的,首先在当前帧待测图像中选取一人形检测框,根据所选取的所述人形检测框的位置获取下一帧待测图像中所选取的人形检测框的预测位置,此时,所述待测图像中每个人形检测框的状态为:
其中,u和v代表当前帧待测图像中人形检测框的中心位置坐标,s表示所述人形检测框的面积,r表示所述人形检测框的和长宽比,
需要说明的是,所述人形检测框(Bounding Box)用于更新其对应的人像的状态,其中的速度分量使用卡尔曼滤波器进行求解。若下一帧待测图像中没有和所述人像相关联的人形检测框,则可以使用线性的预测模型获取实时人形检测框的预测中心位置而不需要进行修正。
接着,分别获取下一帧待测图像中所有待匹配的人形检测框的实际位置(即所述实际中心位置)与所述预测位置(即所述预测中心位置)的交并比,若所有的交并比均小于一关联阈值,则所选取的人形检测框在下一帧待测图像中没有对应的人形检测框,否则,则所述交并比中最大值对应的待匹配的人形检测框与所选取的人形检测框对应同一个人像。可选的,通过计算分配代价矩阵获取下一帧待测图像中所有待匹配的人形检测框的实际位置与所述预测位置的交并比,并采用匈牙利算法将下一帧待测图像中所有待匹配的人形检测框的实际位置与所述预测位置进行多目标匹配。
需要说明的是,当一个人像第一次出现在所述待测图像中时,需要对所述新出现的人像进行标记,以便获取所述人像在多帧待测图像中对应的人形检测框,而当所述人像离开所述待测图像中时,则需要销毁所述人像的标记。可选的,若销毁所述人像之后所述待测图像内不存在人形检测框,则还需要对所有交并比小于所述关联阈值的人形检测框重新检测,以避免所述待测图像中还存在没有被跟踪到的人像。
随后,参阅图5,执行步骤S04,获取所述人形检测框中的多个人体关键点,所述人体关键点用于表征人像的姿态。本实施例中,所述人体关键点包括手肘关键点、手腕关键点、脖子关键点、左肩膀关键点、右肩膀关键点、臀部关键点、膝盖关键点和脚踝关键点中的一种或多种。
具体的,参阅图5,采用改进vovnet网络模型获取所述人形检测框中的多个人体关键点,所述改进vovnet网络模型包括四个OSA(One-Shot Aggregation)模块,其具体过程包括:经过两层3×3×64的卷积核卷积两次和一层3×3×128的卷积核卷积两次,再经过最大池化层进行降采样,使图像的输出尺寸变化为112×112×128;经过五层3×3×64的卷积核卷积五次,每次卷积的结果按照最后一个维度进行拼接,再经过一层1×1×128的卷积核卷积和步长为2的最大池化层输出,使图像的输出尺寸变化为56×56×128;经过五层3×3×80的卷积核卷积五次,每次卷积的结果按照最后一个维度进行拼接,再经过一层1×1×256的卷积核卷积和步长为2的最大池化层输出,使图像的输出尺寸变化为28×28×256;经过五层3×3×96的卷积核卷积五次,每次卷积的结果按照最后一个维度进行拼接,再经过一层1×1×384的卷积核卷积和步长为2的最大池化层输出,使图像的输出尺寸变化为14×14×384;经过五层3×3×112的卷积核卷积五次,每次卷积的结果按照最后一个维度进行拼接,再经过一层1×1×512的卷积核卷积和步长为2的最大池化层输出,使图像的输出尺寸变化为7×7×512;以及,经过7×7×26的卷积核和7×7×13的卷积核输出所述人体关键点的位置坐标和可见性。
可选的,在采用所述改进vovnet网络模型获取所述人形检测框中的多个人体关键点之前,还包括:输入224×224×3的RGB训练图像,经过所述改进vovnet网络模型输出所述训练图片中包含的人体关键点并判断所述人体关键点是否可见。其中,所述训练图片是从大型图像处理数据集(例如MPII、LSP和AI Challenger)中裁剪所得,通过对所述训练图像进行随机旋转、随机裁剪、随机遮挡及高斯模糊方法进行数据增广,增强了所述改进vovnet网络模型的鲁棒性。
本实施例中,所述改进vovnet网络模型的损失函数为:
其中,x为一个行向量,包括所述改进vovnet网络模型中所有的所述人体关键点的实际位置坐标与模型预测的位置坐标在不同方向上的差值。
可选的,所述改进vovnet网络模型的预测指标为:
其中,p表示所述待测图像的人形检测框的序号,pi表示所述待测图像中第p个人形检测框中的人体关键点的序号,v
需要说明的是,所述归一化因子σ
随后,参阅图6,执行步骤S05,在连续的设定帧数内的所述待测图像中,根据所选取的人形检测框中人体关键点的位置变化情况判断相应的人像是否存在挥手运动。
本实施例中,主要通过三个判断条件判断连续的设定帧数内的所述待测图像中是否存在挥手运动。首先,若手腕关键点的高度高于手肘关键点的高度,则说明相对于的人像的胳膊处于举起状态,而在做挥手运动时,人像的胳膊始终是处于举起状态的。因此,第一个判断条件为所述手腕关键点在竖直方向上是否持续性地高于所述手肘关键点。
接着,在连续的设定帧数内的所述待测图像中,当手腕关键点在水平方向上移动至距离人像身体最近处时,所述手腕关键点、手肘关键点及左肩膀关键点(或右肩膀关键点)所形成的靠近身体内侧的夹角需要在设定角度阈值(例如为180度±15度)的范围内,而当手腕关键点在水平方向上移动至距离人像身体最远处时,所述手腕关键点、手肘关键点及左肩膀关键点(或右肩膀关键点)所形成的靠近身体内侧的夹角需要另一设定角度阈值(例如为90度±15度)的范围内。因此,第二个判断条件为所述手腕关键点、所述手肘关键点以及所述左肩膀关键点(或所述右肩膀关键点)所形成的靠近人像身体内测的夹角是否在设定角度阈值内。
随后,在连续的设定帧数内的所述待测图像中,由于挥手动作可归属于周期性运动,所以手腕关键点和手肘关键点的水平坐标值在时域上属于类正弦函数,若手腕关键点和手肘关键点的水平坐标值在时域方向上的运动可以在一定程度上匹配上正弦波函数的部分曲线,则可将此动作判断为挥手。因此,第三个判断条件为所述手肘关键点和所述手腕关键点在水平方向上的位置是否随着时间的变化呈周期性运动,即,挥手动作帧序列是否属于类正弦函数。挥手动作帧序列的待测图像所取的点的个数即为设定帧的个数,同时在正弦函数上也平均选取相同的点数,两个曲线中的点两两之间互相匹配去计算欧式距离,所有点的欧式距离进行加和,加和小于设定阈值则判断当前挥手动作帧序列属于类正弦函数。
若所述三个判断条件的结果均为是,则连续的设定帧数内的所述待测图像中存在挥手运动,否则,则连续的设定帧数内的所述待测图像中不存在挥手运动。
可选的,在采用所述判断条件进行判断之前,还包括,根据所选取的人形检测框中包含的人体关键点的种类和数量判断相对应的人像与摄像头的距离,并根据所述人像与摄像头的距离设置相应的设定角度阈值。
示例性的,当所述人像基本平视摄像头时,若所述人像与所述摄像头的距离小于0.5米,则所述人像检测框中臀部关键点及在竖直方向上低于所述臀部关键点的其他关键点均不可见;若所述人像与所述摄像头的距离在0.5米至1米内,则所述人像检测框中膝盖关键点及在竖直方向上低于所述膝盖关键点的其他关键点均不可见;若所述人像与所述摄像头的距离在1米至2米内,则所述人像检测框中只有脚踝关键点不可见;若所述人像与所述摄像头的距离大于2米,则所述人像检测框中所有的人体关键点都可见。随着人像与所述摄像头的距离变化,上述三个判断条件的判断阈值也会进行调整,通过设置不同的参数(例如所述设定角度阈值),从而尽量减小检测距离对挥手检测结果的负面影响。
相应地,参阅图7,本发明还提供一种挥手检测装置1,采用所述挥手检测方法进行检测,包括:
人形检测模块11,用于在输入的待测图像中的人形上设置人形检测框;
人形跟踪模块12,包括运动估计单元、数据关联单元和跟踪目标的建立与销毁单元,其中,所述运动估计单元用于根据当前帧待测图像中所选取的人形检测框位置获取下一帧待测图像中所选取的人形检测框的预测位置,所述数据关联单元用于将所述预测位置与下一帧待测图像中所有待匹配的人形检测框的实际位置进行匹配,使前后帧待测图像中用于表示相同人像的人形检测框相互对应,所述跟踪目标的建立与销毁单元用于对出现在待测图像中的人像进行标记,以及将离开所述待测图像中的人像对应的标记销毁;
关键点检测模块13,用于获取所述人形检测框中的人体关键点的位置坐标和可见性;
挥手检测模块14,用于根据所选取的人形检测框中人体关键点的位置变化情况判断相应的人像是否存在挥手运动。
本实施例中,所述人像检测模块11将实时视频序列的连续多帧图片(例如输入尺寸为448×448×3的RGB图片)按照时间顺序依次输入到人形检测模型(即所述简化VGG网络模型)中,并输出高于所述设定尺寸阈值的所有人形检测框的位置坐标(x,y)及所述人形检测框的宽度和高度。
在所述人形跟踪模块12中,输入当前帧待测图像和下一帧待测图像的所有人形检测框信息,将当前帧待测图像中的人形检测框和下一帧待测图像中的所有人形检测框进行一一配对。若两个人形检测框的交并比大于或等于所述关联阈值,则配对成功,给两帧待测图像中的两个所述人形检测框分配同样的ID;若两个人形检测框的交并比小于所述关联阈值,则在当前帧待测图像中剩余的人形检测框中选取一个再次进行配对。若下一帧待测图像中的其中一个人形检测框与当前帧所有的人形检测框的交并比都小于所述关联阈值,则为下一帧待测图像中的所述人形检测检测框分配一个新的ID。若有当前帧待测图像的人形检测框在下一帧待测图像存在未匹配到相应的人形检测框,则销毁当前的人形检测框ID。
在所述关键点检测模块13中,输入经过处理的待测图像(即输入尺寸为224×224×3的RGB图片),所述待测图像中包含为经过跟踪的人形检测框,随后,输出所述人形检测框中包含的多个(例如为13个)人体关键点坐标及所述人体关键点坐标是否可见的判断。
在对于挥手检测模块14,输入连续的设定帧待测图像中人形检测框的人体关键点坐标及其可见性,根据所述人体关键点坐标进行相应的挥手判断的计算。具体的,首先确定所述人形检测框对应的人像与摄像机的大致距离,根据距离对接下来的判断条件选取不同的阈值参数,若三个判断条件均满足,则判定所述连续的设定帧待测图像中存在挥手情况。
与现有的挥手检测方法相比,本实施例所述的挥手检测方法及装置通过对连续的设定帧数的待测图像进行检测,将同一人像在连续多帧待测图像中对应的多个人形检测框对应起来,实现了实时视频序列中持续性地多人挥手检测,提高了检测灵敏度,同时降低了误检率。此外,本实施例所述的挥手检测方法通过所选取的人形检测框中包含的人体关键点的种类和数量判断相对应的人像与摄像头的距离,减小了距离因素对于挥手检测结果的影响,提高了所述挥手检测方法对于不同环境的适应性。
综上所述,本发明提供一种挥手检测方法及装置,对包含连续多帧待测图像的实时视频序列进行逐帧处理,用人形检测框将所述待测图像中的若干个人像分别框选出来;将前后帧待测图像中的人形检测框进行匹配,使前后帧待测图像中用于表示相同人像的人形检测框相互对应;获取所述人形检测框中的多个人体关键点,所述人体关键点用于表征人像的姿态;以及,在连续的设定帧数内的所述待测图像中,根据所选取的人形检测框中人体关键点的位置变化情况判断相应的人像是否存在挥手运动。本发明通过将同一人像在连续多帧待测图像中对应的多个人形检测框对应起来,实现了实时视频序列中持续性地多人挥手检测,提高了检测灵敏度,同时降低了误检率。
上述仅为本发明的优选实施例而已,并不对本发明起到任何限制作用。任何所属技术领域的技术人员,在不脱离本发明的技术方案的范围内,对本发明揭露的技术方案和技术内容做任何形式的等同替换或修改等变动,均属未脱离本发明的技术方案的内容,仍属于本发明的保护范围之内。
- 移动体检测装置及检测方法、移动体学习装置及学习方法、移动体检测系统以及程序
- 用于检测爆管检测装置的压降速率检测装置及检测方法
- 一种欺诈检测模型训练方法和装置及欺诈检测方法和装置
- 辐射检测装置、辐射检测系统、以及用于制造辐射检测装置的方法
- 一种用于焦距检测的双刀口差分检测装置、检测方法及数据处理方法
- 利用光敏传感器检测挥手动作的方法、系统及移动终端静音方法、系统
- 一种基于运动历史图像的挥手检测方法