一种基于知识库的复杂问题语义解析方法
文献发布时间:2024-04-18 19:58:30
技术领域
本发明涉及自然语言处理、智能问答技术领域,具体涉及一种基于知识库的复杂问题语义解析方法。
背景技术
随着互联网技术的不断发展,问答系统作为辅助人们获取和处理海量信息所使用的工具,已经被应用于生活中的各个方面。随着用户对于信息检索结果有效性要求的不断提高,传统基于检索式的问答系统通过文本关键字匹配等方式返回给用户相关网页,其中往往会包含大量的无关信息,无法满足用户的需求。而基于知识库查询的问答系统可以接受并理解用户所输入的自然语言问题,并在大规模知识库中推理查询获得问题准确的答案,并最终将答案输出给用户。目前知识库问答已经成为智能问答领域中的热门研究方向。
知识库是一种由多个知识三元组组成的数据库,其中三元组的形式为<主语,谓语,宾语>。不同于以非结构化的自由文本为知识载体的网页,知识库可以通过SPARQL等结构化查询语句进行查询检索,使得用户能够更加准确地获取所需的知识。在知识库问答任务的研究中,基于语义解析的方案得到了广泛的关注,其中语义解析指的是对输入的自然语言问题进行语义解析,得到问题在知识库中对应的结构化查询语句,然后通过在知识库中执行查询语句得到答案。实验数据表明,在简单问题上的知识库问答模型效果已经基本超越了人类水平,简单问题指的是只包含一个主题实体并只需要找到一个知识三元组便可以得到答案的问题。与简单问题不同,复杂问题需要通过多个知识三元组进行推理,同时会涉及到集合操作、数值比较、排序等操作,其中的实体、关系、约束多样性会提升对问题进行语义解析的难度。目前针对复杂问题的语义解析任务可以分为实体链接、关系链接和结构化查询生成三个步骤。其中实体链接主要目的是为了检测出问题中的实体提及,并将其链接到知识库中对应的实体。关系链接任务的主要目的是在知识库中找出与问句语义相匹配的关系谓词。结构化查询生成任务的主要目的是结合前两步获得的问题语义特征生成问句对应的结构化查询语句并通过执行得到问题对应的答案。但传统的三阶段语义解析流程中每一个子任务的错误引入都会导致整体模型的效果降低,同时三个子任务独立的解决同一问题中的不同语义解析任务,不符合人类理解问句的思维方式,会导致各个子任务之间缺乏协同调整能力。
发明内容
本发明所要解决的技术问题是:提出一种基于知识库的复杂问题语义解析方法,解决现有技术在处理复杂问题时实体和关系多样性所存在的不足,提升模型对复杂问题的语义理解能力以及回答复杂问题时的准确率。
本发明解决上述技术问题采用的技术方案是:
一种基于知识库的复杂问题语义解析方法,其特征在于,该方法在知识库密集空间中直接检索候选实体和关系集合,将实体消歧和关系分类作为辅助任务与结构化查询生成一同进行多任务学习训练。
具体地,该方法包括以下步骤:
A、训练多任务学习模型:
A1、设定当前知识库问答任务中的背景知识库KB;然后获取训练样本,每个训练样本由自然语言问题以及其对应的SPARQL查询语句组成,其中SPARQL查询语句在知识库中执行的结果为问题对应答案。
A2、候选实体检索:对于输入的自然语言问题,首先识别出问句中包含的实体提及,然后通过映射关系获取候选实体集合。
A3、候选关系检索:从知识库中检索候选关系,最终得到候选关系集合。
A4、通过多任务学习模型生成结构化查询语句:在结构化查询生成的过程中,将实体消歧和关系分类作为辅助任务,构成一个多任务学习模型;其中,实体消歧任务的输入为自然语言问题以及A2中获得的候选实体集合,输出为问题中包含的实体集合;关系分类任务的输入为自然语言问题以及A3中获得的候选关系集合,输出为问题中包含的关系集合;结构化查询生成任务的输入为实体消歧任务的结果和关系分类任务的结果以及自然语言问题,输出为一个结构化查询语句。
进一步地,在多任务学习模型中,三个子任务共享同一套编码器参数,同时每个子任务在编码器的基础上设计独立的训练层用于训练对应子任务,最终将生成的结构化查询语句作为多任务学习模型的输出结果。
A5、循环执行步骤A2-A4,对多任务学习模型进行迭代训练,直至达到预设的训练次数或模型已收敛。
B、执行复杂问句的语义解析任务:
将在步骤A中训练好多任务学习模型用于实际的复杂问题语义解析任务;具体地,将自然语言问题作为输入,基于训练好的多任务学习模型获得问题对应的结构化查询语句,并通过在知识库中执行查询语句得到问题的答案,同时输出问题中包含的实体集合和关系集合。
进一步地,步骤A2中,所述候选实体检索,具体包括:
A21、对自然语言问句进行分词操作,并使用Bert编码器得到分词后自然语言问句中每个词对应的嵌入向量。
A22、使用BiLSTM编码器从两个方向对自然语言问句进行编码,得到自然语言问句蕴含上下文信息的隐藏状态向量;然后通过CRF层,使用状态转移矩阵考虑相邻词语的标签约束关系,最终得到最优标注结果,得到问句中的实体提及。
A23、根据字符匹配方式构造实体提及到知识库实体的映射关系,并通过映射关系最终得到大小为K
进一步地,步骤A3中,所述候选关系检索,具体包括:
A31、对自然语言问句q进行预处理,将步骤A22中识别出来的实体提及用[MASK]令牌进行替换,得到处理后的问句T
A32、使用双编码器分别编码问句T
Y
Y
S(q,r)=Y
其中,BERTCLS代表BERT编码过程中[CLS]令牌的输出向量,Y
进一步地,步骤A4中,通过多任务学习模型生成结构化查询语句,具体包括:
A41、完成实体消歧任务:通过对A2中得到的候选实体集合进行二分类来完成实体消歧任务;具体地,首先处理候选实体集合E
然后将自然语言问句q和实体表示
其中,Y
其中,v
A42、完成关系分类任务:通过对A3中得到的候选关系集合R
其中,
其中u
A43、完成结构化查询生成任务:输入为问句q的实体集合E
首先将问句q与E
T
将T
[h
接着使用解码器将得到的编码向量h
其中,p
A44、联合训练A41、A42、A43中的三个子任务,将损失函数按公式(14)设置:
L=L
该损失函数的设置不仅能够监督结构化查询生成任务,还同时监督实体消歧任务和关系分类任务,使得结构化查询生成任务能够从实体消歧任务和关系分类任务两个辅助任务中学习。
本发明的有益效果是:
本方案中考虑了问题语义解析过程中实体链接,关系链接以及结构化查询生成三个子任务之间的协同关系,通过使用多任务学习框架来对模型进行联合训练,克服了传统语义解析方案中存在的各任务相互独立以及存在错误传播的缺陷,提高了结构化查询生成任务的准确率,同时提升了语义解析模型的整体效果。
附图说明
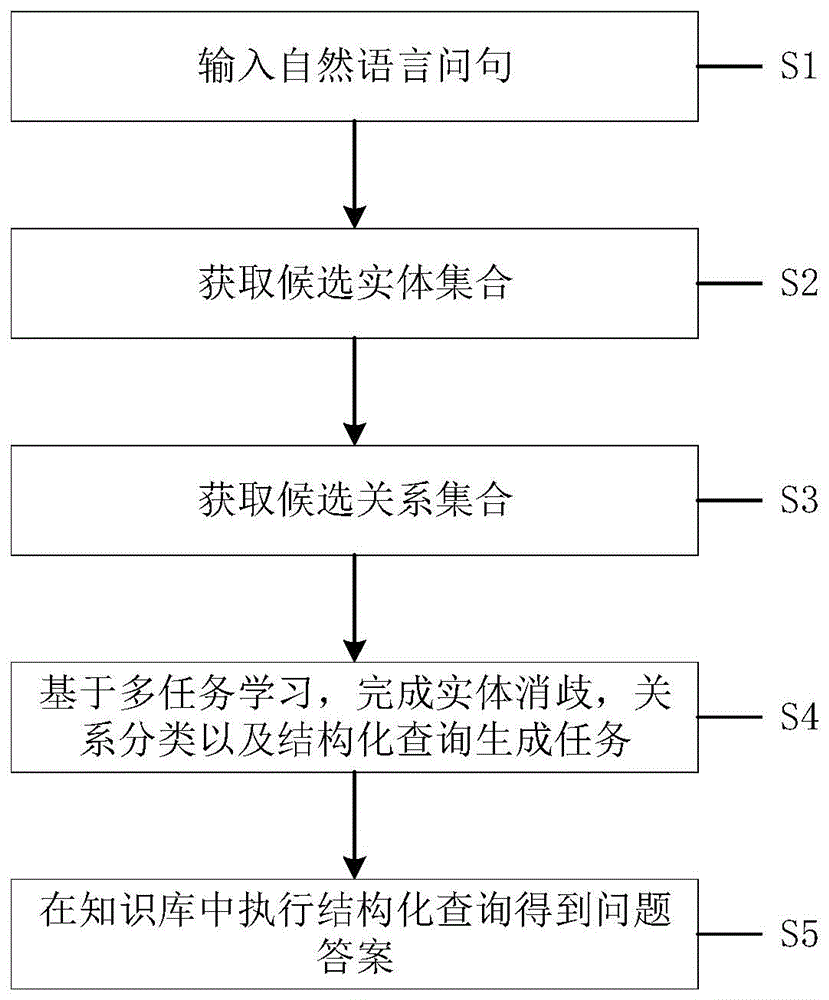
图1为本发明实施例中的流程图。
图2为本发明实施例中所使用的多任务学习模型框架图。
具体实施方式
本发明旨在提出一种基于知识库的复杂问题语义解析方法,克服了传统方案中存在的各任务相互独立以及存在错误传播的缺陷,提高了结构化查询生成任务的准确率,同时提升了语义解析模型的整体效果。其整体实现流程如图1所示,本发明首先设定当前知识库问答任务中的背景知识库KB,接着获取训练数据,每个训练样本由自然语言问题以及其对应的SPARQL查询语句组成,其中SPARQL查询语句在知识库中执行的结果为问题对应答案。接着对于输入的自然语言问题,使用Bert-BiLSTM-CRF模型识别出问句中包含的实体提及,接着使用FACC1项目中的映射关系获取候选实体集合,然后使用双编码器关系检索模型直接从知识库中检索候关系,得到候选关系集合,最后通过多任务学习生成结构化查询语句,将实体消歧和关系分类作为辅助任务,构成一个多任务学习模型。三个子任务共享同一套编码器参数,同时每个子任务在编码器的基础上设计独立的层用于训练对应子任务,最终将生成的结构化查询语句作为模型输出结果,并通过在知识库中执行查询语句得到问题的答案。
实施例:
本实施例中基于知识库的复杂问题语义解析方法主要包括训练复杂问题语义解析模型以及利用训练好的模型进行问答任务,整个问答流程参见图1,其具体包括以下实施步骤:
S1、设定知识库KB作为问答任务中所使用的知识来源,接着输入需要解答的自然语言问题。
S2、对于每个自然语言问题,获取其在知识库中对应的候选实体集合。
在本步骤中,对于输入的自然语言问题,使用Bert-BiLSTM-CRF模型识别出问句中包含的实体提及,接着使用FACC1项目中的映射关系获取候选实体集合。
具体而言,包括以下步骤:
S21、对自然语言问句进行分词操作,通过使用预训练语言模型Bert编码器得到分词后问句中每个词对应的嵌入向量。
S22、选择使用BiLSTM编码器分别从左到右以及从右到左两个方向对问句进行编码,得到问句蕴含上下文信息的隐藏状态向量,同时对于隐藏状态使用状态转移矩阵来考虑相邻词语的标签约束关系,最终得到最优标注结果,得到问句中的实体提及。
S23、根据字符匹配方式构造实体提及到知识库实体的映射词典,并通过映射最终得到大小为K
S3、对于每个自然语言问题,获取其在知识库中对应的候选关系集合。
在本步骤中,设计一个结合双编码器关系检索模型直接从知识库中检索候关系,得到问句对应的候选关系集合,其具体步骤如下:
S31、对问句q进行预处理,将前一步骤中识别出来的实体提及使用[MASK]令牌进行替换,得到处理后的问句T
S32、使用预训练语言模型BERT便分别对问句T
Y
Y
S(q,r)=Y
根据计算结果,选择相关性最高的前K
S4、生成结构化查询语句,在结构化查询生成的过程中,将实体消歧和关系分类作为辅助任务,构成一个多任务学习模型,其模型框架如图2所示。
具体而言,实体消歧任务的输入为自然语言问题以及候选实体集合,输出为问题中包含的实体集合;关系分类的输入为自然语言问题以及候选关系集合,输出为问题包含的关系集合;而结构化查询语句生成的输入为实体消歧的结果和关系分类的结果以及自然语言问题,输出为一个结构化查询语句。
S41、获得问题对应实体集合,通过对在S2中得到的候选实体集合进行二分类来完成实体消歧任务,首先处理候选实体集E
接着将问题q和实体表示
在模型训练的过程中,选择使用交叉熵作为损失函数,公式如下:
其中,v
S42、获得问题对应关系集合,通过对S3中得到的候选关系集合进行二分类来完成关系分类任务,将问题q和关系r
其中u
S43、结构化查询生成任务的输入为问题实体集合E
T
将T
[h
接着使用解码器将得到的编码向量h
其中,p
S45、联合训练A41、A42、A43中的三个子任务,将损失函数按公式(14)设置:
L=L
该损失函数的设置不仅能够监督结构化查询生成任务,还同时监督实体消歧任务和关系分类任务,使得结构化查询生成任务能够从实体消歧任务和关系分类任务两个辅助任务中学习。
S5、在通过解码器得到结构化查询语句后,通过在知识库中执行查询语句得到问题的答案,同时输出问题中包含的实体集合和关系集合,共同作为输入问题的语义解析结果。
尽管这里参照本发明的实施例对本发明进行了描述,上述实施例仅为本发明较佳的实施方式,本发明的实施方式并不受上述实施例的限制,应该理解,本领域技术人员可以设计出很多其他的修改和实施方式,这些修改和实施方式将落在本申请公开的原则范围和精神之内。
- 基于深度语义解析的复杂知识库问答方法与系统
- 一种基于知识图谱的复杂问题语义理解方法