基于多规则关联分析的网络舆情信息智能处理方法及系统
文献发布时间:2023-06-19 09:29:07
技术领域
本发明涉及一种基于多规则关联分析的网络舆情信息智能处理方法及系统,属于计算机软件技术领域。
背景技术
大数据标签在现阶段数据表现形式中起着重要应用,怎么把传统标签和现在的智能标签结合统一起来在舆情分析中起着重要作用。传统标签主要是数据属性上的一些标签,而大数据标签主要针对的是通过数据挖掘技术所得到的一些特征类型标签,本发明通过建立基于传统标签和智能标签的结合,并对数据智能处理来完成对数据事物的打标。
智能处理部分,由于现在数据挖掘和人工智能发展非常快,舆情需要的功能点各不相同。所以基于用户需求定制的功能系统成为了数据智能处理的迫切需求,本系统综合各个功能,提供用户按需定制功能。
发明内容
本发明的目的在于提供一种基于多规则关联分析的网络舆情信息智能处理方法及系统,针对在舆情信息多元化的现在和复杂的海量数据,构建一套多层级多分支的标签体系。当舆情分析时,提供标签化服务,为舆情分析提供快速优质的数据服务。本发明通过智能处理引擎针对不同种类的标签智能识别打标。
本发明的技术方案为:
一种基于多规则关联分析的网络舆情信息智能处理方法,其步骤包括:
1)为所选对象构建标签体系,所述标签体系为树形结构,其中首先按照标签类型建立多个二级标签节点,每一二级标签节点下面设置若干层节点,第i层节点为相邻第i+1层节点的父节点,第i+1层节点为相邻第i层节点的子节点;每一个标签只属于一种二级标签节点,一个节点有一个或多个子节点,每个子节点有一个或多个父节点;所述标签类型包括概括类标签、智能标签和业务标签;
2)调度器启动时读取配置库中的引擎配置,按照引擎配置为各引擎设置对应所需过滤的数据类型和接收字段,并从标签体系中读取对应标签分配给对应引擎;
3)调度器在接收到消息队列数据后将数据按照各引擎定义的格式发送给对应引擎,各引擎根据所分配的标签对收到的数据进行识别,然后将识别结果返回给调度器;针对有依赖关系的引擎,即引擎i的输入数据为引擎j的识别结果,则监控引擎j的数据任务状态,当引擎j任务完成后将其识别结果发送给引擎i和调度器,然后引擎i将识别结果返回为调度器;
4)调度器根据识别结果为对应的数据设置相应标签,同时统计各引擎的处理信息并将统计信息存入到任务统计库;
5)任务统计库根据统计信息获取当前的网络舆情。
进一步的,调度器根据识别结果为对应的数据设置相应标签以及该标签的上下级标签。
进一步的,所述配置库用来标明所需引擎、引擎之间的关联关系、启动引擎时配置的引擎数量、引擎对应的标签定义、引擎接收的数据类型、接收字段、处理后返回的字段和传输协议。
进一步的,任务统计库根据统计信息获取当前的网络舆情的方法为:根据目标数据的标签以及向下扩展的标签层级,获取到与该目标数据相关联的数据,得到该目标数据的关联数据集;然后根据该关联数据集识别该目标数据对应的事件不同阶段以及舆情传播情况。
进一步的,所述标签类型包括概括类标签、智能标签和业务标签。
进一步的,所选对象为若干个体或团体。
一种基于多规则关联分析的网络舆情信息智能处理系统,其特征在于,包括标签体系、配置库、任务统计库、调度器和多个引擎;其中,
所述标签体系为树形结构,其中首先按照标签类型建立多个二级标签节点,每一二级标签节点下面设置若干层节点,第i层节点为相邻第i+1层节点的父节点,第i+1层节点为相邻第i层节点的子节点;每一个标签只属于一种二级标签节点,一个节点有一个或多个子节点,每个子节点有一个或多个父节点;所述标签类型包括概括类标签、智能标签和业务标签;
所述调度器,用于启动时读取配置库中的引擎配置,按照引擎配置为各引擎设置对应所需过滤的数据类型和接收字段,并从标签体系中读取对应标签分配给对应引擎;在接收到消息队列数据后将数据按照各引擎定义的格式发送给对应引擎;以及根据引擎的识别结果为对应的数据设置相应标签,同时统计各引擎的处理信息并将统计信息存入到任务统计库;
所述引擎,用于根据所分配的标签对收到的数据进行识别,然后将识别结果返回给调度器;针对有依赖关系的引擎,即引擎i的输入数据为引擎j的识别结果,则监控引擎j的数据任务状态,当引擎j任务完成后将其识别结果发送给引擎i和调度器,然后引擎i将识别结果返回为调度器;
任务统计库,用于存储统计信息并根据统计信息获取当前的网络舆情。
本发明的积极效果
本发明提出的基于标签系统的网络舆情信息智能处理框架,通过标签系统和智能调度系统,能够完美的完成网络舆情大数据的情况下的智能处理。做到所有引擎调度配置,结果数据智能打标,为以后的舆情分析提供高效的数据支撑。
附图说明
图1为标签类型示意图。
图2为标签体系示例图。
图3为数据打标流程示例图。
图4为结果收集示例图。
图5为本发明实施流程图。
具体实施方式
为了使本技术领域的人员更好地理解本发明实施例中的技术方案,并使本发明的目的、特征和优点能够更加明显易懂,下面结合附图对本发明中技术核心作进一步详细的说明。
按照传统标签和大数据标签结合形成标签系统。按照新的标签系统按照功能维度把标签主要定义为概括类标签,智能标签和业务标签三大类型。
概括类标签是一堆有特定智能标签或者特定特征标签的合体,如一个人作为一个概括标签时,他可能有一些特定的属性标签,如他的性别、年龄、身高都是标签,有一些特定的特征标签,如这个人的情感倾向、职业能力评估等等,综合构成了一个人物的画像。当然一个概括类标签还可以包含多个概括类标签。如当一个团队作为一个标签时,他下面可以有多个人的概括类标签。如领导人,财务总管,设计总管等等。
业务标签是针对系统需要自定义的标签以及针对大数据中消息信息属性定义的一些标签,这些标签是辅助业务功能和舆情分析的重要支柱。特别针对大数据中文本内容,关键词组合的标签过滤是舆情分析中重要的信息过滤手段。如关键词过滤标签(A|C)&B等复杂关系表达式。还有一些其他属性标签如数据中包含地域的会有对应的地域标签等等,当然根据业务需求,业务标签也可能是一些业务标签和智能标签的组合,如同时包含地域标签(北京),关键词标签(中关村&北四环)的信息过滤标签。
智能标签是通过数据挖掘和人工智能对数据生成的标签,其中包括文本数据的分类、情感等,包括媒体类型数据的声纹、人脸、场景识别等等。在舆情分析中通过数据挖掘和人工智能识别出的标签,是辅助舆情分析的重要部分,识别的准确度也是决定舆情分析效果的关键。
根据标签的属性维度将标签分为了四类,分别为关键词类标签、普通类型规则、范围类规则、以及组合类规则。
关键词类标签在上面也提到,在网络舆情分析中,信息过滤对于舆情发现和分析起着重要作用;所以针对关键词关系表达式的过滤是主要的一个标签类型,其主要用于用户可以自定义的一些业务标签。
针对关键词过滤有Trie树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。
上面介绍了关键词过滤,在过滤关键词表达式时,会根据表达式首先把关键词表达式拆成关键词,最后根据Trie树比对,匹配到的为1、没有匹配到的为0,根据表达式做位运算最后计算为1的命中标签,0的未命中标签。
普通类型的标签,是针对属性或者通过数据挖掘或人工智能得出的标签,此类标签是直接由数据处理程序直接得出,不包含关键词的规则匹配,也不包含数字的范围。此类标签主要是一些信息的属性标签和数据挖掘和人工智能的智能标签。
范围类型标签的主要也是基于一些属性标签或者基于智能标签上一些可计算范围的业务标签,如在年龄标签基础上可能还会封装成少儿、少年、青年、老年等等。在地域标签上封装的东部、西部、北部、南部等等。
组合类型标签是业务标签的一种类型,此类型的标签是根据业务需求,几个标签一起组合生成的一种复杂表达式标签。
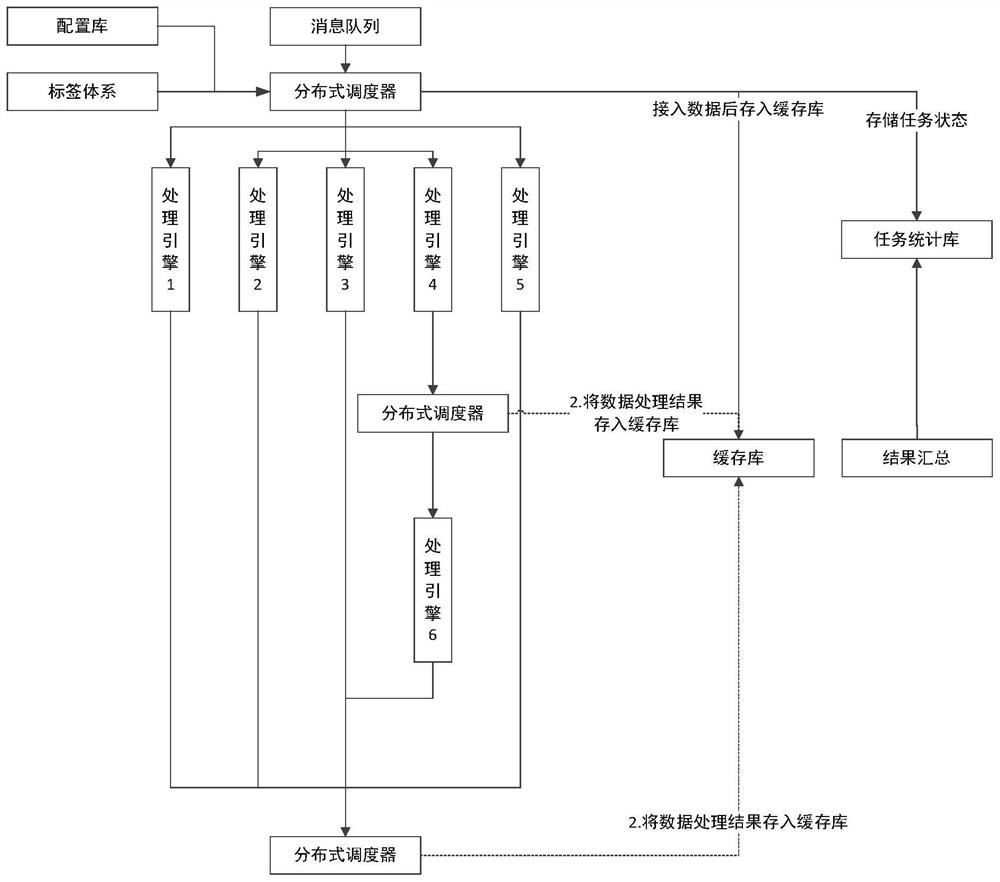
智能处理部分主要分为配置库、标签体系、缓存库、任务状态库、调度器、结果汇聚、引擎六部分组成。
配置库用来标明系统需要那些引擎,那些引擎之间有关联关系、启动引擎时配置的引擎数量、引擎对应的标签定义、以及本身接收那些数据类型、需要那些字段、处理后返回那些字段、传输协议等等。
标签体系是用来对引擎处理结果定义的标签体系,在数据流过引擎后,引擎会生成对应的结果数据,调度器通过结果找到对应标签给数据打标。
标签体系构建过程
标签体系构建分为标签类型构建和标签构建。
标签类型构建,首先标签按分类有概括类标签,智能标签和业务标签三大类型。这三大类在类型体系上,用户可以自己定义标签类型(二级标签类型),用于智能处理服务打标使用,如图1所示。
标签体系构建以树形结构构建,每一个标签只属于一种二级标签类型。一个节点可以有多个子节点,每个子节点可以有多个父节点,在引擎使用时,用户可以查取某一类型的标签,并查看其上面N层父节点,也可以查看其下面N层子节点。以上体系结构用户可以自行定义。示例如图2所示。
缓存库的作用是缓存处理中的数据,针对各个引擎,在完成数据处理后,都会把结果缓存到缓存库,当结果收集将所有引擎都处理完的数据入库后,从缓存库清除。
任务状态库当调度器从队列取出数据后,会把每批数据作为一个任务发送到各个引擎,故每个引擎的处理能力统计和完成状态都会存到任务状态库中。供前端展示和结果收集使用。
调度器在接收到消息队列数据后将数据分发到各个引擎,等待引擎返回结果,引擎返回结果后按照事先定义好的标签体系,对数据映射打标。并将结果存入到缓存库。同时统计各个引擎的性能和结果数据存入到任务状态统计库。数据打标示例如图3所示。
当调度器调度人脸引擎时,可以根据二级标签类型,获取到XXX人脸标签,在媒体数据流过人脸识别引擎时,会把匹配到的人脸标号返回给调度器,调度器把匹配到XXX的数据,打上对应XXX的标签。当然在获取标签时可以获取到其上N级标签,或者下N级标签,此时可以决定是否对其关联的上级标签或者下级标签打标。
引擎是用来对数据进行处理的程序,在数据流入后处理流入数据生成由程序生成的字段返回给调度器。
结果收集使用来监控各个任务状态,当有任务完成时,将引擎处理完的结果集存入到数据库,针对有失败的引擎,重新发送数据给引擎处理。在结果收集中可配置的决定将数据按类型,按过滤条件分配到不同的数据源。
结果收集程序读取到已完成的任务,在缓存库读取已完成处理的数据,清除完成数据,读取分流配置,将数据分配到不同数据源。数据分流是指不同的业务需求方,可以对数据字段(包括标签字段)设定过滤条件,来得到想要的数据内容,在不设置过滤条件时,代表全部数据,同时可以设置只接收固定那些字段,以使存储资源用到最少。
总处理流程如图5所示。
调度器启动时读取配置库,读取引擎配置,按照引擎配置为引擎过滤对应引擎需要的数据类型和引擎接收的字段,按引擎配置从标签系统中读取标签,初始化完成后。将数据按照引擎定义的格式发送给引擎,等待引擎处理结果,当引擎返回结果后将引擎结果和定义的标签映射获取对应的数据标签为数据打标,同时统计各个引擎的处理信息存入到任务统计库。
在做舆情分析时,用户可以配置标签以及向下扩展的标签层级,获取到相关联的数据。这样在舆情分析时,能够获取到最相近的数据集。对于舆情的引发期、酝酿期、发生期、发展期、高潮期、处理期、平息期和反馈期等不同阶段能够做到更精准判断,同时对舆情的传播情况做到更细,对于舆情分析的准确度提供有力的数据支撑。
针对有依赖的引擎,需要监控数据任务状态,当依赖引擎完成后才能继续完成依赖引擎的调度。
结果汇总监控任务统计库,当有完成的任务把缓存结果存入到数据库。当有任务失败时,将失败的任务按处理失败的引擎重新发送。
尽管为说明目的公开了本发明的具体内容、实施算法以及附图,其目的在于帮助理解本发明的内容并据以实施,但是本领域的技术人员可以理解:在不脱离本发明及所附的权利要求的精神和范围内,各种替换、变化和修改都是可能的。本发明不应局限于本说明书最佳实施例和附图所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
- 基于多规则关联分析的网络舆情信息智能处理方法及系统
- 基于多规则关联分析的网络舆情信息智能处理方法及系统