一种利用FPGA BRAM的CNN模型卷积运算加速计算方法
文献发布时间:2023-06-19 11:16:08
技术领域
本发明涉及FPGA硬件加速计算领域,特别是涉及一种针对矩阵乘法运算的加速计算方法。
背景技术
卷积神经网络(Convolutional Neural Networks,CNN)模型作为一种典型的深度学习神经网络结构,受到自然视觉认知机制启发而来,在图像识别方面具有出色表现。由于实际应用场景中的数据量大幅度增加,传统的处理器计算方式已难以满足CNN计算性能的需求,现场可编程门阵列(Field Programmable Gate Array,FPGA)具有高性能、低功耗、并行化程度高的特点,适用于作为计算设备完成CNN 模型的加速计算。
CNN模型通常包含卷积、池化和全连接运算,其中卷积运算作为 CNN模型的核心计算单元之一,其计算性能对于整个CNN模型的性能至关重要。目前已有部分基于FPGA的卷积运算加速计算方法,主要是将卷积运算映射为矩阵乘法,然后利用两个矩阵不同行列相乘时运算独立的特点,借助FPGA丰富的逻辑资源,实现矩阵乘法的并行计算。然而此类方法仍然没有完全发挥FPGA的硬件并行优势。
发明内容
本发明的目的在于提供一种利用FPGA BRAM的CNN模型卷积运算加速计算方法,用于解决上述先有技术的问题。
本发明一种利用FPGA BRAM的CNN模型卷积运算加速计算方法,其中,包括:(1)将输入矩阵A和矩阵B存入FPGA的BRAM;假设输入矩阵分别为A(M*N)和B(N*P),输出矩阵为C(M*P);
(2)并行计算矩阵C的元素C
C
(3)将C
根据本发明所述的利用FPGA BRAM的CNN模型卷积运算加速计算方法的一实施例,其中,根据输入矩阵A和B的规模,为矩阵乘法运算分配计算资源。
根据本发明所述的利用FPGA BRAM的CNN模型卷积运算加速计算方法的一实施例,其中,每一个C
根据本发明所述的利用FPGA BRAM的CNN模型卷积运算加速计算方法的一实施例,其中,利用BRAM两个端口,同时写入两个不同的矩阵C的元素。
根据本发明所述的利用FPGA BRAM的CNN模型卷积运算加速计算方法的一实施例,其中,对每一个C
根据本发明所述的利用FPGA BRAM的CNN模型卷积运算加速计算方法的一实施例,其中,步骤(2)依次循环处理完全部M*P个 C
本发明利用FPGA中包含两个端口的BRAM,并行访问内存,进一步提高计算性能。
附图说明
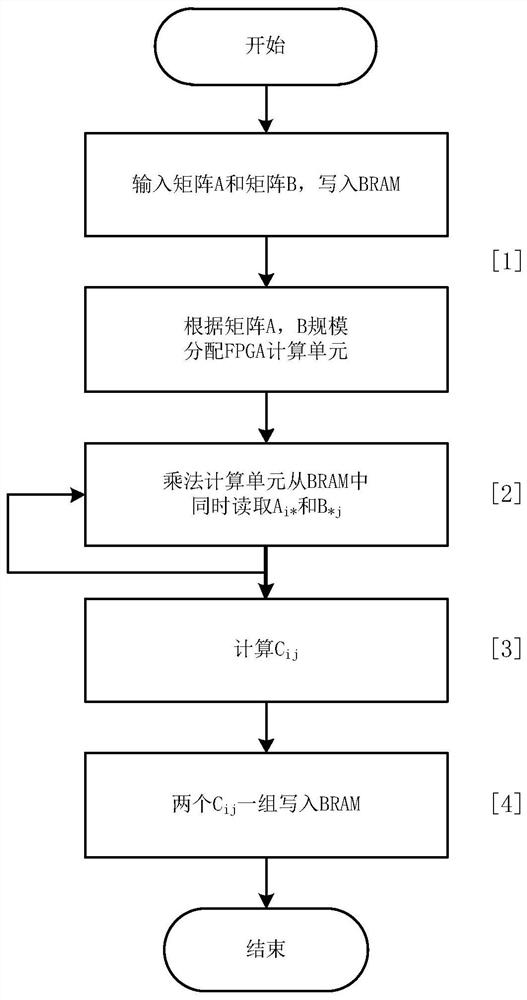
图1一种利用FPGA BRAM的矩阵乘法加速计算方法流程图。
具体实施方式
为使本发明的目的、内容、和优点更加清楚,下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。
本发明一种利用FPGA BRAM的矩阵乘法加速计算方法包括:
(1)将输入矩阵A和矩阵B存入FPGA的BRAM。
一方面BRAM作为FPGA内存读写速度快,可加快计算过程的数据读取速度,另一方面BRAM包含两个读写端口,允许计算过程并行访问内存,提高计算效率。
假设输入矩阵分别为A(M*N)和B(N*P),输出矩阵为C(M*P),如下所示。
(2)并行计算C
首先,由于FPGA具有丰富的计算资源,可根据输入矩阵A、B的规模,为矩阵乘法运算分配计算资源,其中每一个C
其次,针对每一个C
最后,当读取完成后,按照如下公式(1)计算C
C
(3)将C
这一步骤同样利用BRAM两个端口,同时写入两个C
最终得到矩阵乘法的计算结果C(M*P)。
如图1所示,一种利用FPGA BRAM的矩阵乘法加速计算方法, 包括以下步骤:
步骤1:用户输入矩阵A和矩阵B,并将两个矩阵写入FPGA BRAM,同时根据矩阵A和矩阵B的规模,为后续矩阵乘法分配FPGA 计算资源,一个C
步骤2:针对步骤1写入到BRAM中的矩阵A和矩阵B,Cij对应的矩阵乘法计算单元从BRAM两个端口中同时读取Ai*和B*j,依次循环处理完全部M*P个C
步骤3:针对步骤2中的C
步骤4:针对步骤3计算结果,每两个C
相比于目前已有的基于FPGA的矩阵乘法加速计算方法,本发明方法在矩阵乘法的计算过程中,充分利用BRAM的两个读写端口,使得在从BRAM读取输入矩阵数据或是往BRAM写入最终计算结果数据时,读写数据的时间开销仅为传统加速计算方法的一半,提高矩阵乘法整体的计算效率。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
- 一种利用FPGA BRAM的CNN模型卷积运算加速计算方法
- 一种针对CNN卷积层运算的加速阵列设计方法