一种基于编码输出的网络高效优化方法
文献发布时间:2023-06-19 12:07:15
技术领域
本发明涉及机器学习领域,尤其是一种网络优化方法。
背景技术
目前,公知的一维输出矩阵的神经网络由于神经节间有一定数目的相互连接的链条,当网络较大时存在链条数目多而导致的计算量大,训练速度慢的问题。因此,为了增加一次训练的计算量,节省网络训练的时间,需要一种更快捷、更有效的优化方法。针对大型的一维输出矩阵的神经网络,一种基于二进制编码的神经网络优化方法提供了一种新的解决思路。
神经网络是机器学习的一个分支,是一种应用类似于大脑神经突触联接的结构进行信息处理的数学模型。神经网络在每一次的学习过程中,网络会根据前向传播的输出结果与输出矩阵的误差后向调整权值和阈值。当网络较大时,存在训练量大、训练时间长的问题。
神经网络根据输出矩阵的维数不同分为一维输出矩阵的神经网络和多维矩阵的神经网络。一维输出矩阵的神经网络因其表示方式简单、易识别等特点被广泛应用于各个工程项目中。输出的一维矩阵经过处理后根据工程的需求不同实现不同的功能,如目标检测、图片分类、语音识别等。
然而,对于一维输出矩阵的神经网络来说,虽然其输出矩阵表示的方式比较简单,但在其调整权值和阈值不断学习的过程中,这种误差的计算和阈值的调整也均是一维的。在输入矩阵不变的情况下,一次迭代的计算量较小。当工程项目中要求的神经网络较大时,存在迭代次数多,迭代时间长的问题。另一方面,由于输出矩阵是一维的,因此在样本测试的环节存在误差较大、错误率较高等问题。在工程项目中有时达不到很好的效果。
发明内容
为了克服现有技术的不足,本发明提供一种基于编码输出的网络高效优化方法。为了节约网络训练时间,减小测试误差。
本发明解决其技术问题所采用的技术方案包括以下步骤:
步骤1:将训练数据集进行特征提取,产生一个输入矩阵,输入矩阵作为训练网络中的输入端;因为不同项目中的数据集有不同,特征提取的算法会有不同,所以输入矩阵的格式也会有差异;
训练数据集有Q组数据,每组数据经过特征提取算法后有P个特征点,生成一个P×Q的特征矩阵A作为输入矩阵,矩阵A为训练网络的训练样本,所述特征提取算法满足每组训练数据的特征最终均可用P个特征点描述,从而生成一个P×Q的特征矩阵A作为输入矩阵;
步骤2:对原神经网络的一维输出矩阵的升维,对一个一维输出矩阵的神经网络进行优化,故此原神经网络是指待优化的输出矩阵为一维的神经网络;
将原神经网络的一维输出矩阵记为T,升维后的多维输出矩阵记为T
原一维输出矩阵是一个一维列向量,将每行的一个元素依照十进制数字与二进制数字的换算关系换算为新的二进制数字,新的二进制数字按照高位到低位的顺序排列成一行,每一位的二进制数字对应一个新的元素,每行的数字由原来的一位十进制数变为了新的多位二进制编码的形式,从而原来的输出矩阵也由一维列向量变成了多维列向量;根据步骤1,输出矩阵的格式与输入矩阵的格式相对应,因此特征矩阵A对应的一维输出矩阵T的格式为1×Q,由于一维输出矩阵T中最大的十进制数字对应的二进制编码的位数是最多的,因此一维矩阵T升维后得到的多维输出矩阵T
步骤3:在新的神经网络结构中对训练样本进行训练;此时的输入矩阵为格式为P×Q的特征矩阵A,输出矩阵为格式为M×Q的M维输出矩阵T
新神经网络的输出矩阵由1维变为了M维,导致输入测试样本以后,输出了一个M维的二进制数字为元素的输出矩阵,由于需要用一个一维输出矩阵使得结果显示得更加清楚,因此还要对输出的M维矩阵进行降维,即测试段的处理;
步骤4:测试数据集经特征提取后生成测试输入矩阵A
测试数据集有Q
步骤5:在新的网络结构中进行样本测试;
经过新的网络测试后,输出矩阵的维数与新的训练网络的多维输出矩阵维数相同,均为M维,列数与测试输入矩阵A
步骤6:将M维输出矩阵取整;
输入测试样本后生成的M维输出矩阵T
步骤7:二进制编码进行译码,将生成的不含小数的M维输出矩阵T
所述特征提取算法采用局部二值模式(Local Binary Pattern,LBP)或尺度不变特征变换(Scale-invariant feature transform,SIFT)。
所述译码的过程与编码的过程相反,将M位的二进制编码按照二进制与十进制的数学换算关系换算为一位的十进制整数,用得到的一位十进制整数代替原多维矩阵中M位二进制编码,由此得到一个格式为1×Qt的一维输出矩阵Tt,一维输出矩阵Tt为经过新的网络优化后经译码而得到的最终输出结果,输出的矩阵根据需求不同实现不同的功能,如目标检测、图片分类、语音识别。
本发明的有益效果在于采用了基于二进制编码的优化手段,具有如下两个优点:
第一个是网络训练时有效减少训练时间。构建网络的时候将原1维十进制输出矩阵变为一个M维的二进制编码矩阵,使得误差的计算和对应后项阈值调整的维数均由传统的1维拓展成了M维。由此,优化后的网络使得在每次的训练历程中实际值与理想值的M维同步误差逼近与传统的1维同步逼近相比更加有效。从理论上分析,在硬件条件相同的情况下,训练速度是原来的M倍,训练时间会减少到原来的1/M倍。且随着输出矩阵维数的增加,速度提升得也会越显著。
第二个是测试过程中可以有效减少误差,提高正确率。在实际进行样本测试的过程中,将原十进制误差由传统的1位依二进制各位上分配的权值均分到M位上。从追求正确率的角度上说,在输入同样数量的测试样本后,正确率会比传统的1位误差高。
附图说明
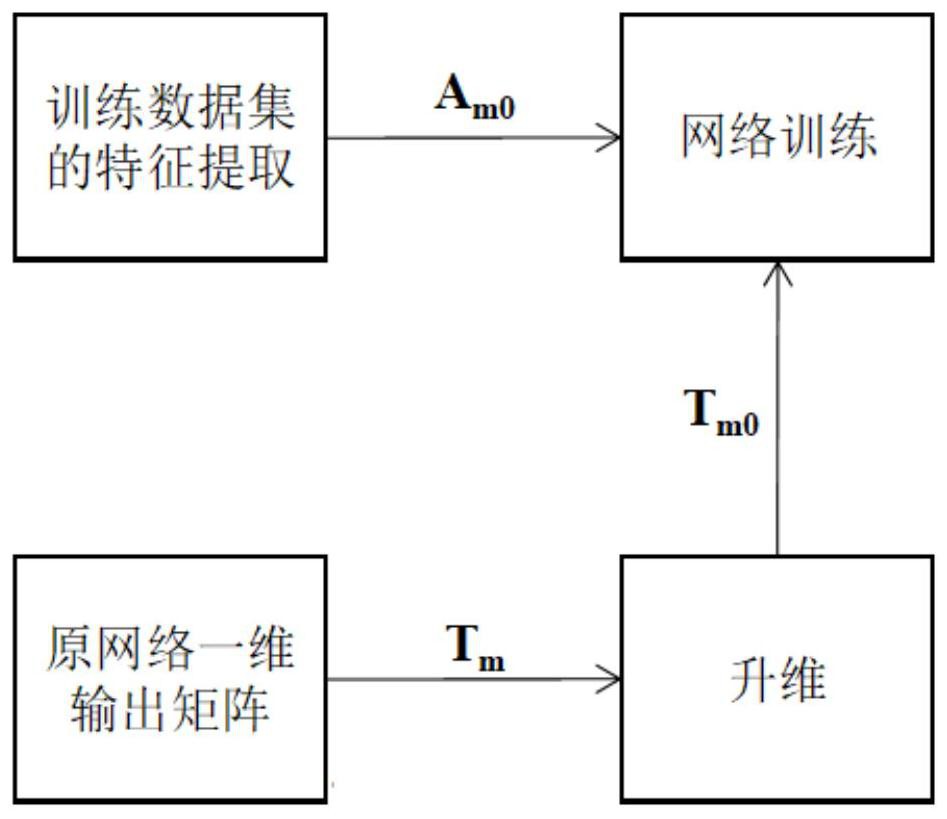
图1是本发明训练网络端框图。
图2是本发明测试端框图。
具体实施方式
下面结合附图和实施例对本发明进一步说明。
根据本发明所述针对一维输出神经网络优化方法,假设实际项目中经过特征提取后得到的输入矩阵向量维数P
再假设实际项目中未经优化前给定的一维输出矩阵T
训练网络端如图1所示,具体包括以下步骤:
步骤1:将训练样本进行特征提取,提取后生成一个P
步骤2:对原一维输出矩阵的拓维,设此网络的输出矩阵为T
步骤3:在新的多维输出矩阵神经网络结构中进行网络训练,输入矩阵为格式为P
测试端的处理如图2所示,具体包括以下步骤:
步骤1:假设实际项目中的测试数据集的数据组数Q
步骤2:在新的多维输出网络结构中进行样本测试。经过新的网络测试后,输出矩阵的维数与新的训练网络的多维输出矩阵维数相同,均为4维。列数与输入矩阵A
步骤3:将得到的4维输出矩阵T
步骤4:二进制编码的译码,将生成的不含小数的4维输出矩阵T
- 一种基于编码输出的网络高效优化方法
- 一种基于编码-解码卷积神经网络低照度图像优化方法