一种基于词典的文本蕴含式生物医学命名实体识别方法
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及生物医学人工智能领域,尤其涉及一种基于词典的文本蕴含式生物医学命名实体识别方法。
背景技术
生物医学命名实体识别(Biomedical Named Entity Recognition,BioNER)是识别基因、蛋白质、疾病和化合物等生物医学实体的一项任务。随着海量的生物医学数据以非结构化文本的形式激增,BioNER在生物医学研究领域引起了极大的关注。一般来说,命名实体识别(NER)是自然语言处理(NLP)中一个基本而重要的任务。它旨在识别给定句子中的命名实体,用于术语归一化和分类。这些抽取出来的命名实体还可以造福于后续的各种NLP任务,比如语法解析、问答和关系抽取等。然而,与一般领域的NER任务不同,BioNER面临着更为严峻的挑战。由于伦理、隐私、以及生物医学领域的高度专业化问题,收集高质量标注的生物医学数据集既昂贵又耗时。加之生物医学领域中存在缩写、同义、同形同音异义、歧义等词句的不规范使用,描述实体的短语的频繁使用以及词典的实体覆盖率低等现象进一步加大了BioNER的实现难度。
近几年,随着深度学习技术的发展,NER在有监督训练的上取得了巨大的进展,一些工作研究了基于神经网络的BioNER方法,这些方法主要是基于序列标注模型设计的。例如,提出将词嵌入、长短期记忆网络(LSTMs)、条件随机场模型(CRFs)结合到一个BioNER的单一框架中。然而,这些方法仍存在以下不足:
(1)任务庞大,既昂贵又耗时,难以实现。这些模型需依赖于大量的token级标注数据来实现不错的性能。
(2)存在严重的噪声标签问题。序列标注模型需要每个文本中的最小单元token的标签,而词典的实体覆盖率有限,加之低质量的生物医学数据,在弱监督下使用序列标注方法是不合适的,因为存在很高的被错误标注的风险。
由此可见,通过像传统的NER模型那样将BioNER制定为序列标注任务,无法轻松缓解噪声标签问题,实现成本大。因此,为BioNER发现一种新的建模方法势在必行。
发明内容
针对上述问题,本发明提出了一种基于词典的文本蕴含式生物医学命名实体识别方法,使用结合动态对比学习的文本蕴含方法(Textual Entailment with DynamicContrastive Learning,TEDC)来解决基于词典的BioNER任务。它采用了迁移学习的方法,通过迁移外部知识来解决BioNER任务;并创新性地将BioNER任务表述为有关文本蕴含问题的工作,文本蕴含方法更适用于对整个序列没有标注的情况,可以较好地解决噪声标签问题;还结合了动态对比学习框架,对比学习同一句话中的实体和非实体,进一步加强模型的辨别能力。
本发明提供一种方法包括以下步骤:
步骤一,构建词典弱监督:
从词典中收集包含实体名称和实体类型的实体词典,作为真实标签,以获得弱监督。
步骤二,构建蕴含对:
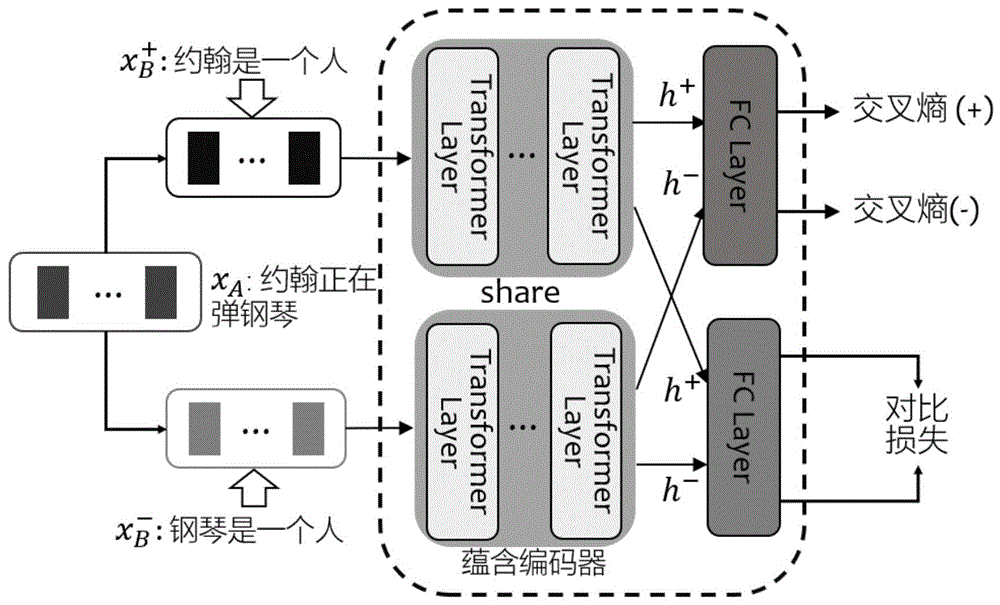
为了将NER任务转换为文本蕴含,需要对输入的句子构建对应的文本蕴含对。它要求模型对于输入的一段文本(称之为前提,Premise)和一些未指明但有限制的知识(如词典或迁移知识),识别另一段文本(称之为假设,Hypothesis)是否为真。而这两段文本(Premise和Hypothesis)被命名为文本蕴含对(Textual Entailment Pair,TEP)。例如,给定一个输入句子“约翰正在弹钢琴”,对于NER任务是识别“约翰”是一个人,这相当于问“约翰是一个人”是否为真。因此,本发明将输入句子充当前提,将“约翰”作为一子序列,从词典中获取“人”这个实体类型,最终形成了“约翰是一个人”的假设。由此,NER任务则转换为了文本蕴含问题,即在给定前提的情况下确定假设是否为真。为了训练蕴含模型,需要根据训练数据集确定子序列最大长度限制m,以限制候选子序列的数量,并且由于负蕴含对的数量往往远大于正例对,因此本发明通过设定负样本例/正样本例的比率r以控制负蕴含对的采样数量。
步骤三,构建蕴含编码器:
本发明使用RoBERTa模型对输入的文本蕴含对进行编码,RoBERTa模型的每个Transformer编码器层都包含了横跨整个输入句子的双向注意力。本发明在RoBERTa模型输出的嵌入层上进行了改进,应用一个全连接层(FC Layer)来做二进制文本蕴含分类,以输出文本蕴含对;本发明全连接层输出上额外添加了dropout层,设定dropout率d1,以实
现对神经网络进行正则化,减少过拟合,并提高模型的泛化能力;对于文本蕴含,本发明使用交叉熵损失来训练模型,以提高模型的分类准确性,识别关于某一词段的假设的真假。
步骤四,结合动态对比学习算法进行模型训练:
为了提高模型对实体和非实体的区分能力,本发明将文本蕴含与动态对比学习算法相结合,对零样本BioNER任务进行RoBERTa模型训练。通过添加动态对比学习损失来对比实体和非实体;交叉熵损失用于做二进制分类任务,而对比学习损失试图使正对吸引和负对分离,即正对齐和负分离。本发明将交叉熵损失和对比学习损失加在一起来训练整个模型,通过只使用交叉熵损失初始化训练,然后逐渐引入对比项,使用余弦函数来动态增加对比学习损失的权重,以缓解训练不稳定的问题。
通过RoBERTa模型对Transformer编码器进行初始化后,在文本蕴含数据集上对TEDC进行预训练,以迁移知识。最后经过微调以最小化总损失。
步骤五,模型预测,实体识别:
预测输入的语句时,模型将所有正的文本蕴含对识别为实体,如果有子序列具有多个不同实体类型的正文本蕴含对,则把相似度最高的标签作为最终标签。
本发明的特点在于:提出了一种结合动态对比学习的文本蕴含方法(TEDC),该方法通过词典构建弱监督,用于解决BioNER任务。TEDC是第一个将BioNER任务建模为文本蕴含问题的模型,此方法不仅可以在没有完整标注的情况下缓解噪声标签问题,而且能从预训练的文本蕴含模型中迁移知识。此外,动态对比学习框架还增强了模型区分实体和非实体的能力,能够对命名实体进行精确的识别。
附图说明
图1为本发明提出的TEDC模型的整体框架;
图2展示了本发明实施的BioNER实验在BC5CDR和NCBI-Disease两个数据集上的零样本实体识别性能。
具体实施方式
下面通过具体实施例,并结合附图,对本发明的技术方案作进一步的具体说明。实施例1
本实施例提供了一种基于词典的文本蕴含式生物医学命名实体识别方法,其整体模型框架如图1所示,该方法的实施主要包括以下步骤:
步骤一,构建词典弱监督:
从词典中收集包含实体名称和实体类型的实体词典,作为真实标签,以获得弱监督。本发明使用CTD Chemical and Disease(比较毒理基因组学数据库化学物质和疾病)作为数据集的词典,这些词典包含了17,097个化学物实体和13,061个疾病实体。
为了提高实体的召回率,本发明使用正则表达式扩大了词典,扩大后的词典以三种方式包含实体:(1)词段与原始词典中名称带有一些后缀的实体匹配(2)实体名称的一些前缀;(3)完全匹配。
步骤二,构建蕴含对:
形式上,给定一个输入句子A(包含n个token),表示为x
为了训练蕴含模型,需要同时构建正蕴含对和负蕴含对。对于正例,使用词典中的实体作为监督。如果子序列与词典中一个实体的名称完全匹配,则使用它与其实体类型构建正蕴含对。对于负例,则在词典中不存在的所有子序列的集合中采样,由于大多数子序列是非实体,即负例的数量远远大于正例,因此只采样部分负例进行训练,在实验中负/正例率为r,即r=负例数/正例数。
步骤三,构建蕴含编码器:
对输入的语句构建出蕴含对后,将蕴含对中的句子(x
在输入的开头添加一个特殊的序列开始标记([CLS]),并在每个句子的末尾添加一个特殊的序列结束标记([SEP])。由此,整个输入被格式化为
([CLS],ω
本发明使用RoBERTa对输入序列进行编码:
h=RoBERTa(x
其中RoBERTa是一个基于Transformer的预训练语言模型。
RoBERTa的每个Transformer层都包含了横跨整个输入句子的双向注意力,第l个Transformer层的注意力计算为:
其中,d
其中,
本框架在RoBERTa输出的嵌入层上应用一个全连接层(FC Layer)来做二进制文本蕴含分类:
p=softmax(Wh+b)
其中,
对于文本蕴含,本框架使用交叉熵损失(cross-entropy loss)来训练模型,以识别关于词段的假设是真还是假:
其中,N是训练样本的数量,对于第i个样本,y
步骤四,结合动态对比学习方法进行模型训练:
本发明将动态对比学习方法与文本蕴含方法相结合,提出对比学习损失(contrastive loss),以推动正蕴含对的相似度高于负蕴含对。本框架在蕴含嵌入之上使用一个全连接层(FC Layer)来模拟相似度,s
其中,s
本框架将交叉熵损失和对比学习损失加在一起来训练整个模型。为了提供稳定的训练程序,使用余弦函数来动态增加对比学习损失的权重:
L=L
其中,d为动态权重,t为当前训练步骤,T为总训练步骤。随着训练进行,d从0增加到1,通过只使用交叉熵损失初始化训练,然后逐渐引入对比项,可以缓解训练不稳定的问题。
TEDC的训练过程有两个阶段:预训练阶段和微调阶段。
对于预训练,本发明使用RoBERTa来初始化蕴含编码器,并在文本蕴含数据集MNLI(Multi-Genre Natural Language Inference)上对TEDC进行预训练,以迁移知识。在预训练阶段,使用掩码语言建模(MLM)。MLM实现方式是随机掩码输入序列中一定比例的token,这些token由文本分词方法WordPiece tokenization生成,然后通过模型预测这些被掩码的token。在MLM任务中,本发明利用被掩码的token的最终隐藏状态,并使用softmax层从词汇表中选择预测的token。依据RoBERTa的做法,每个序列中随机掩码了15%的token。通过在文本蕴含数据集上进行预训练,可以提高文本蕴含模型衡量两个句子之间是否具有蕴含关系的能力。
在微调过程中,可通过设置负/正例率r、dropout率d1、最大输入长度、批量大小以及Transformer层的隐藏维度d
步骤五,模型预测,实体识别:
对于每个输入,通过对句子伴随每种实体类型的所有可能子序列构建蕴含对,再将构建的所有正蕴含对和负蕴含对送入蕴含模型,以获得结果。模型将所有正的蕴含对识别为实体,如果有子序列具有多个不同实体类型的正蕴含对,则把相似度最高的标签作为最终标签。
本发明通过引入一个结合动态对比学习的文本蕴含方法(TEDC),由词典构建弱监督,用于解决BioNER任务。此方法不仅可以在没有完整标注的情况下缓解噪声标签问题,而且能从预训练的文本蕴含模型中迁移知识。此外,动态对比学习框架还增强了模型区分实体和非实体的能力。
具体实例如下:
表1为本发明在BC5CDR和NCBI-Disease数据集上基于词典的BioNER任务的实验结果。
表1
本发明在两个真实世界的数据集(BC5CDR和NCBI-Disease)上进行了零样本生物实体识别(BioNER)任务的实验。数据集BC5CDR包含了1500篇PubMed(美国国家医学图书馆在线数据库)文章,其中包含12852个疾病(Disease)实体和15935个化学物(Chemical)实体;数据集NCBI-Disease在疾病名称识别方面是在提及级别上进行了完全注释的,它包含了793个PubMed摘要,其中包含了6892个疾病实体。由于两个数据集的大多数实体小于或等于3个token,因此实验选择实体子序列最大截取长度m为3。本实验采用CTD Chemical andDisease作为这两个数据集的词典,通过正则表达式扩大后的词典达到能够覆盖两个数据集中近50%的实体。为了验证本发明方法的有效性,将TEDC与以下7个基线进行比较:①Dictionary Match:一种识别实体提及的方法;②NN
本发明使用词典来获取伪标签以训练基线模型,所有基线均使用原论文提供的推荐参数。对于TEDC,实验中使用学习率为1e-5的Adam(一种优化算法)优化器;设置负/正蕴含对比率r为20,在一个批次中输入1个正蕴含对和20个负蕴含对,因此批次大小为21;dropout率d1设为0.2,最大输入长度设为512;使用具有12个Transformer层的RoBERTa-base模型(RoBERTa模型的基础版本),在Transformer层中d
如表1所示,本发明提出的TEDC模型在两个数据集上表现优于其他所有基准模型。那些表现较好的基准模型包括AutoNER、Fuzzy-LSTM-CRF和BOND,它们尝试从词典中转移知识,但可能会受到噪声标注数据的影响,因为它们仍然采用序列标注的框架。本发明提出的TEDC通过将BioNER任务建模为文本蕴含缓解了这个问题。对比Roberta和Roberta-CRF,TEDC的改进表明性能的提升来自文本蕴含框架,而不仅仅是预训练的Roberta模型。
此外,动态对比学习框架提高了模型区分实体和非实体的能力。总体而言,TEDC能够有效地从数据层面和模型层面转移知识,并在BC5CDR和NCBI-Disease数据集上分别取得了显著的性能提升。这些改进表明TEDC不仅从强大的预训练模型中受益,还学会了有效地识别实体。因此,当我们没有完整的序列注释时,文本蕴含建模是一种更合适的方式来建模BioNER任务。
如图2所示,上一行展示BC5CDR的结果;下一行展示NCBI-Disease的结果,与基准模型相比,TEDC模型在这些未知实体上的优越性更加显著,这证明了TEDC模型识别未知实体的能力。TEDC模型在两个数据集上均有效地提高了所有设置的召回率,其中对于BC5CDR实体的召回率R提升最大,从53.69%提高到60.47%;对于精确度,TEDC模型与最佳基准模型相当。实际上,提高召回率指标更为重要,因为它是零样本BioNER任务的瓶颈。例如,对于强基准模型,即Fuzzy-LSTM-CRF和BOND,在精确度P上达到60%以上,而召回率仅约为50%。这一结果表明TEDC模型更适用于零样本场景,它受益于文本蕴含的形式化,有助于将词典中的外部知识转移到识别未知实体的过程中。
以上结合附图对本发明进行了示例性描述,显然,本发明具体实现并不受上述方式的限制,凡是采用了本发明的方法构思和技术方案进行的各种非实质性的改进;或者未经改进、等同替换,将本发明的上述构思和技术方案直接应用于其他场合的,均在本发明的保护范围之内。